
吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎
吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎
You might also like
- labuladong的算法秘籍V2 4Document705 pageslabuladong的算法秘籍V2 4jiaweizhao2012No ratings yet
- 基于深度学习的音乐旋律生成算法的研究与实现Document68 pages基于深度学习的音乐旋律生成算法的研究与实现jlj kjdfNo ratings yet
- labuladong的刷题笔记V2 6Document521 pageslabuladong的刷题笔记V2 6zhnd100% (1)
- 前沿课·吴军讲GPTDocument102 pages前沿课·吴军讲GPT李三No ratings yet
- 嵌入式系統入門 An Embedded Software PrimerDocument70 pages嵌入式系統入門 An Embedded Software PrimerSTM WorksNo ratings yet
- TensorFlow深度学习(带目录)Document404 pagesTensorFlow深度学习(带目录)杨奕航No ratings yet
- 【《TensorFlow深度学习》】Document404 pages【《TensorFlow深度学习》】SmallHHHNo ratings yet
- 机器学习 Machine Learning (Chinese Edition) (Zhou Zhihua 周志华)Document441 pages机器学习 Machine Learning (Chinese Edition) (Zhou Zhihua 周志华)liangnia KaiserNo ratings yet
- Spring Cloud微服务实战Document442 pagesSpring Cloud微服务实战prateekgupta21590No ratings yet
- 23种设计模式知识要点Document25 pages23种设计模式知识要点gary huNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 手把手带你实战TransformersDocument103 pages手把手带你实战Transformersxiao maiNo ratings yet
- 小程序开发实践@Document57 pages小程序开发实践@lucasllinNo ratings yet
- 明新資料科學深度學習研習 1 2Document57 pages明新資料科學深度學習研習 1 2Polly ShengNo ratings yet
- Spring Boot實戰 (圖靈程式設計叢書) -已解鎖 PDFDocument253 pagesSpring Boot實戰 (圖靈程式設計叢書) -已解鎖 PDF陳育昇No ratings yet
- Kotlin从入门到进阶实战Document411 pagesKotlin从入门到进阶实战Mark LeeNo ratings yet
- Linux操作系统下C语言编程入门Document104 pagesLinux操作系统下C语言编程入门Weiyi LuNo ratings yet
- (NEW) Linux Shell核心编程指南 - 丁明一Document613 pages(NEW) Linux Shell核心编程指南 - 丁明一David ZhangNo ratings yet
- 重构 改善既有代码的设计 (高清版) PDFDocument454 pages重构 改善既有代码的设计 (高清版) PDFMYNo ratings yet
- 算法详解 卷2 图算法和数据结构 ( (美) 蒂姆·拉夫加登(Tim Roughgarden))Document207 pages算法详解 卷2 图算法和数据结构 ( (美) 蒂姆·拉夫加登(Tim Roughgarden))Jeffery XNo ratings yet
- Java 8实战 PDFDocument359 pagesJava 8实战 PDF杨舒宁No ratings yet
- PostgreSQL开发指南Document223 pagesPostgreSQL开发指南Kevin ShiNo ratings yet
- 学习JavaScript数据结构与算法(第3版)@Document314 pages学习JavaScript数据结构与算法(第3版)@孙晓明No ratings yet
- (图灵程序设计丛书) Android基础教程 第4版Document194 pages(图灵程序设计丛书) Android基础教程 第4版瞿康No ratings yet
- Android入门到精通详解Document210 pagesAndroid入门到精通详解Average JoeNo ratings yet
- Python 数据挖掘入门与实践 (第2版)Document270 pagesPython 数据挖掘入门与实践 (第2版)hickey moonNo ratings yet
- Python3程序开发指南 (第二版)Document535 pagesPython3程序开发指南 (第二版)彭彥碩No ratings yet
- (可爱的Python) 哲思社区 插图版,文字版Document420 pages(可爱的Python) 哲思社区 插图版,文字版朱威No ratings yet
- Go 语言问题集 (Go Questions)Document435 pagesGo 语言问题集 (Go Questions)Alvin ZhangNo ratings yet
- 精通Linux内核必会的75个绝技Document136 pages精通Linux内核必会的75个绝技神战四野No ratings yet
- PyTorch深度学习Document212 pagesPyTorch深度学习Mark Lee100% (1)
- 程序员的SQL金典 (完整)Document312 pages程序员的SQL金典 (完整)Mq SfsNo ratings yet
- Python 黑魔法指南 v3.0Document267 pagesPython 黑魔法指南 v3.0zhiyang jiaNo ratings yet
- Flutter闲鱼最佳实践Document170 pagesFlutter闲鱼最佳实践dingyu wangNo ratings yet
- Flink内核原理与实现Document544 pagesFlink内核原理与实现Joe HKNo ratings yet
- 手把手打開Python資料分析大門Document218 pages手把手打開Python資料分析大門莊凱軒100% (1)
- VBA程式語言 Class05-Variable & StringDocument39 pagesVBA程式語言 Class05-Variable & String洪東凱100% (1)
- 精通LinuxDocument498 pages精通LinuxKingNo ratings yet
- Rust 程序设计语言 简体中文版Document545 pagesRust 程序设计语言 简体中文版杨子松No ratings yet
- 深度学习入门:基于Python的理论与实现Document419 pages深度学习入门:基于Python的理论与实现jenniferNo ratings yet
- (图灵程序设计丛书) .Linux Shell脚本攻略.第3版Document413 pages(图灵程序设计丛书) .Linux Shell脚本攻略.第3版瞿康No ratings yet
- 微服务:从设计到部署中文完整版Document73 pages微服务:从设计到部署中文完整版Chen ShangNo ratings yet
- 0 0-《Python语言程序设计基础 (第2版) 》全答案v3Document79 pages0 0-《Python语言程序设计基础 (第2版) 》全答案v3蔡柏慶No ratings yet
- C语言程序设计 QfDocument147 pagesC语言程序设计 Qf王昱No ratings yet
- Go Web 编程Document473 pagesGo Web 编程Alvin ZhangNo ratings yet
- 机器学习实战Document336 pages机器学习实战Wang MarkNo ratings yet
- Head First Servlets and JSP 中文版 第2版Document910 pagesHead First Servlets and JSP 中文版 第2版acfunNo ratings yet
- 02 ChatGPT项目实战 PDFDocument63 pages02 ChatGPT项目实战 PDFwb c (cwbzjh)No ratings yet
- Vue js前端开发快速入门与专业应用Document205 pagesVue js前端开发快速入门与专业应用Shi QiaoNo ratings yet
- Python视觉实战项目52讲Document483 pagesPython视觉实战项目52讲杨奕航No ratings yet
- Chap01 3Document2 pagesChap01 3qy dingNo ratings yet
- Excel Excel Excel Excel 高级教程Document87 pagesExcel Excel Excel Excel 高级教程Max YanNo ratings yet
- 10万字总结Java面试题和答案 阿里内部资料 (266页)Document266 pages10万字总结Java面试题和答案 阿里内部资料 (266页)lucifer270901801No ratings yet
- python基础新Document92 pagespython基础新Json ChiNo ratings yet
- gdb调试 PDFDocument4 pagesgdb调试 PDFhao zhangNo ratings yet
- VB高级编程Document837 pagesVB高级编程Jiang CodeNo ratings yet
- Python数据分析入门:从数据获取到可视化 PDFDocument338 pagesPython数据分析入门:从数据获取到可视化 PDFShaoFei DuNo ratings yet
- 線性代數與應用 Linear Algebra and ApplicationsDocument29 pages線性代數與應用 Linear Algebra and ApplicationsSTM WorksNo ratings yet
- 20阿里字节一套高效的iOS面试题2020年2月Document47 pages20阿里字节一套高效的iOS面试题2020年2月以少年之名No ratings yet
- Leetcode 题解Document126 pagesLeetcode 题解Samsung TabletNo ratings yet
- C陷阱与缺陷 C+Traps+and+Pitfalls高清pdf版Document181 pagesC陷阱与缺陷 C+Traps+and+Pitfalls高清pdf版Yu TanNo ratings yet
- 如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Document5 pages如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Yang CaoNo ratings yet
- 如何自己从零实现一个神经网络 - - 知乎Document18 pages如何自己从零实现一个神经网络 - - 知乎Yang CaoNo ratings yet
- 格林公式的几何意义是什么? - 知乎Document19 pages格林公式的几何意义是什么? - 知乎Yang CaoNo ratings yet
- 如何记住所有的三角函数公式? - 知乎Document8 pages如何记住所有的三角函数公式? - 知乎Yang CaoNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 深度学习中的优化算法 - 知乎Document7 pages深度学习中的优化算法 - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第二节 制作led呼吸灯 - 知乎Document14 pages树莓派项目实战 第二节 制作led呼吸灯 - 知乎Yang CaoNo ratings yet
- Pandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Document21 pagesPandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第一节 点亮LED灯 - 知乎Document16 pages树莓派项目实战 第一节 点亮LED灯 - 知乎Yang CaoNo ratings yet
- 活用拉格朗日中值,吊打复杂极限难题! - 知乎Document7 pages活用拉格朗日中值,吊打复杂极限难题! - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 奇异值与特征值辨析 - 知乎Document8 pages奇异值与特征值辨析 - 知乎Yang CaoNo ratings yet
- 奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Document8 pages奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Document9 pages为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Document9 pages为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 从认知脑的计算模拟到类脑人工智能Document13 pages从认知脑的计算模拟到类脑人工智能Lynn PolyxenaNo ratings yet
- 【高层主打】华为智慧森林防火监测预警解决方案高层主打材料V1 0Document36 pages【高层主打】华为智慧森林防火监测预警解决方案高层主打材料V1 0vizardNo ratings yet
- 骆润玫 王卫星 2021 基于卷积神经网络的植物病虫害识别研究综述Document10 pages骆润玫 王卫星 2021 基于卷积神经网络的植物病虫害识别研究综述bigliang98No ratings yet
- 一本书读懂ChatGPT、AIGC和元宇宙Document129 pages一本书读懂ChatGPT、AIGC和元宇宙skydrivers1001No ratings yet
- 1667443167822973203Document62 pages1667443167822973203lincolndairyNo ratings yet
- AI生成時代Document234 pagesAI生成時代sssssssc42No ratings yet
- 20240126 海通证券 选股因子系列研究(九十三):深度学习因子的"模型动物园"Document19 pages20240126 海通证券 选股因子系列研究(九十三):深度学习因子的"模型动物园"zhaoqc418No ratings yet
- 高盛人工智能报告中文版 PDFDocument45 pages高盛人工智能报告中文版 PDFJJamesranNo ratings yet
- 2018 年网络和分布式系统安全 (NDSS) 研讨会 2018 年 2 月 18 日至 21 日, 美国加利Document15 pages2018 年网络和分布式系统安全 (NDSS) 研讨会 2018 年 2 月 18 日至 21 日, 美国加利LEENo ratings yet
- 中科院 2019年人工智能发展白皮书Document48 pages中科院 2019年人工智能发展白皮书AA AANo ratings yet
- UntitledDocument364 pagesUntitled翁坤仁No ratings yet
- 欢迎来到真实的电影评分网站Document11 pages欢迎来到真实的电影评分网站h682rdn6No ratings yet
- 24 《家人的使用说明书》黑川伊保子Document157 pages24 《家人的使用说明书》黑川伊保子IRene ReNeNo ratings yet
- 西南证券 向量数据库:AI时代的技术基座 230621Document36 pages西南证券 向量数据库:AI时代的技术基座 230621andywli0425No ratings yet
- 《所罗门的密码》 (德) 奥拉夫·格罗思, (美) 马克·尼兹伯格Document370 pages《所罗门的密码》 (德) 奥拉夫·格罗思, (美) 马克·尼兹伯格李栋No ratings yet
- AI伦理治理三大难题与哲学的诠释 王小红Document7 pagesAI伦理治理三大难题与哲学的诠释 王小红Lynn PolyxenaNo ratings yet
- 高中生活AI大智慧 1228Document133 pages高中生活AI大智慧 1228Marconi JiangNo ratings yet
- 基于无人机航拍的交通检测及流量统计算法研究 常亚楠Document69 pages基于无人机航拍的交通检测及流量统计算法研究 常亚楠mesba HoqueNo ratings yet
- 2023SCEM 審稿結果公告 0626Document16 pages2023SCEM 審稿結果公告 0626HandyNo ratings yet
- 人工智能在土木工程领域的应用研究现状及展望 刘红波Document21 pages人工智能在土木工程领域的应用研究现状及展望 刘红波hu yuexinNo ratings yet
- 基于深度学习的服务区危化品车辆识别算法研究Document4 pages基于深度学习的服务区危化品车辆识别算法研究Charles O'ConnorNo ratings yet
- 基于深度学习的风电场孤岛检测策略的研究 朱凌Document4 pages基于深度学习的风电场孤岛检测策略的研究 朱凌Fatima HaiderNo ratings yet
- 19 11 2020学习笔记Document5 pages19 11 2020学习笔记lisha yangNo ratings yet
- 基于深度学习的机翼载荷计算方法研究 刘佳玮Document65 pages基于深度学习的机翼载荷计算方法研究 刘佳玮qhylovezjyNo ratings yet
- 2023年中国数字人行业发展专题报告Document44 pages2023年中国数字人行业发展专题报告letian940No ratings yet


































































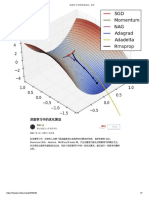







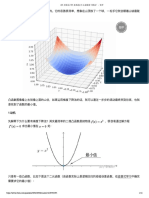


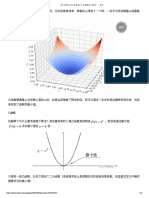

























Download as pdf or txt
You might also like
- labuladong的算法秘籍V2 4Document705 pageslabuladong的算法秘籍V2 4jiaweizhao2012No ratings yet
- 基于深度学习的音乐旋律生成算法的研究与实现Document68 pages基于深度学习的音乐旋律生成算法的研究与实现jlj kjdfNo ratings yet
- labuladong的刷题笔记V2 6Document521 pageslabuladong的刷题笔记V2 6zhnd100% (1)
- 前沿课·吴军讲GPTDocument102 pages前沿课·吴军讲GPT李三No ratings yet
- 嵌入式系統入門 An Embedded Software PrimerDocument70 pages嵌入式系統入門 An Embedded Software PrimerSTM WorksNo ratings yet
- TensorFlow深度学习(带目录)Document404 pagesTensorFlow深度学习(带目录)杨奕航No ratings yet
- 【《TensorFlow深度学习》】Document404 pages【《TensorFlow深度学习》】SmallHHHNo ratings yet
- 机器学习 Machine Learning (Chinese Edition) (Zhou Zhihua 周志华)Document441 pages机器学习 Machine Learning (Chinese Edition) (Zhou Zhihua 周志华)liangnia KaiserNo ratings yet
- Spring Cloud微服务实战Document442 pagesSpring Cloud微服务实战prateekgupta21590No ratings yet
- 23种设计模式知识要点Document25 pages23种设计模式知识要点gary huNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 手把手带你实战TransformersDocument103 pages手把手带你实战Transformersxiao maiNo ratings yet
- 小程序开发实践@Document57 pages小程序开发实践@lucasllinNo ratings yet
- 明新資料科學深度學習研習 1 2Document57 pages明新資料科學深度學習研習 1 2Polly ShengNo ratings yet
- Spring Boot實戰 (圖靈程式設計叢書) -已解鎖 PDFDocument253 pagesSpring Boot實戰 (圖靈程式設計叢書) -已解鎖 PDF陳育昇No ratings yet
- Kotlin从入门到进阶实战Document411 pagesKotlin从入门到进阶实战Mark LeeNo ratings yet
- Linux操作系统下C语言编程入门Document104 pagesLinux操作系统下C语言编程入门Weiyi LuNo ratings yet
- (NEW) Linux Shell核心编程指南 - 丁明一Document613 pages(NEW) Linux Shell核心编程指南 - 丁明一David ZhangNo ratings yet
- 重构 改善既有代码的设计 (高清版) PDFDocument454 pages重构 改善既有代码的设计 (高清版) PDFMYNo ratings yet
- 算法详解 卷2 图算法和数据结构 ( (美) 蒂姆·拉夫加登(Tim Roughgarden))Document207 pages算法详解 卷2 图算法和数据结构 ( (美) 蒂姆·拉夫加登(Tim Roughgarden))Jeffery XNo ratings yet
- Java 8实战 PDFDocument359 pagesJava 8实战 PDF杨舒宁No ratings yet
- PostgreSQL开发指南Document223 pagesPostgreSQL开发指南Kevin ShiNo ratings yet
- 学习JavaScript数据结构与算法(第3版)@Document314 pages学习JavaScript数据结构与算法(第3版)@孙晓明No ratings yet
- (图灵程序设计丛书) Android基础教程 第4版Document194 pages(图灵程序设计丛书) Android基础教程 第4版瞿康No ratings yet
- Android入门到精通详解Document210 pagesAndroid入门到精通详解Average JoeNo ratings yet
- Python 数据挖掘入门与实践 (第2版)Document270 pagesPython 数据挖掘入门与实践 (第2版)hickey moonNo ratings yet
- Python3程序开发指南 (第二版)Document535 pagesPython3程序开发指南 (第二版)彭彥碩No ratings yet
- (可爱的Python) 哲思社区 插图版,文字版Document420 pages(可爱的Python) 哲思社区 插图版,文字版朱威No ratings yet
- Go 语言问题集 (Go Questions)Document435 pagesGo 语言问题集 (Go Questions)Alvin ZhangNo ratings yet
- 精通Linux内核必会的75个绝技Document136 pages精通Linux内核必会的75个绝技神战四野No ratings yet
- PyTorch深度学习Document212 pagesPyTorch深度学习Mark Lee100% (1)
- 程序员的SQL金典 (完整)Document312 pages程序员的SQL金典 (完整)Mq SfsNo ratings yet
- Python 黑魔法指南 v3.0Document267 pagesPython 黑魔法指南 v3.0zhiyang jiaNo ratings yet
- Flutter闲鱼最佳实践Document170 pagesFlutter闲鱼最佳实践dingyu wangNo ratings yet
- Flink内核原理与实现Document544 pagesFlink内核原理与实现Joe HKNo ratings yet
- 手把手打開Python資料分析大門Document218 pages手把手打開Python資料分析大門莊凱軒100% (1)
- VBA程式語言 Class05-Variable & StringDocument39 pagesVBA程式語言 Class05-Variable & String洪東凱100% (1)
- 精通LinuxDocument498 pages精通LinuxKingNo ratings yet
- Rust 程序设计语言 简体中文版Document545 pagesRust 程序设计语言 简体中文版杨子松No ratings yet
- 深度学习入门:基于Python的理论与实现Document419 pages深度学习入门:基于Python的理论与实现jenniferNo ratings yet
- (图灵程序设计丛书) .Linux Shell脚本攻略.第3版Document413 pages(图灵程序设计丛书) .Linux Shell脚本攻略.第3版瞿康No ratings yet
- 微服务:从设计到部署中文完整版Document73 pages微服务:从设计到部署中文完整版Chen ShangNo ratings yet
- 0 0-《Python语言程序设计基础 (第2版) 》全答案v3Document79 pages0 0-《Python语言程序设计基础 (第2版) 》全答案v3蔡柏慶No ratings yet
- C语言程序设计 QfDocument147 pagesC语言程序设计 Qf王昱No ratings yet
- Go Web 编程Document473 pagesGo Web 编程Alvin ZhangNo ratings yet
- 机器学习实战Document336 pages机器学习实战Wang MarkNo ratings yet
- Head First Servlets and JSP 中文版 第2版Document910 pagesHead First Servlets and JSP 中文版 第2版acfunNo ratings yet
- 02 ChatGPT项目实战 PDFDocument63 pages02 ChatGPT项目实战 PDFwb c (cwbzjh)No ratings yet
- Vue js前端开发快速入门与专业应用Document205 pagesVue js前端开发快速入门与专业应用Shi QiaoNo ratings yet
- Python视觉实战项目52讲Document483 pagesPython视觉实战项目52讲杨奕航No ratings yet
- Chap01 3Document2 pagesChap01 3qy dingNo ratings yet
- Excel Excel Excel Excel 高级教程Document87 pagesExcel Excel Excel Excel 高级教程Max YanNo ratings yet
- 10万字总结Java面试题和答案 阿里内部资料 (266页)Document266 pages10万字总结Java面试题和答案 阿里内部资料 (266页)lucifer270901801No ratings yet
- python基础新Document92 pagespython基础新Json ChiNo ratings yet
- gdb调试 PDFDocument4 pagesgdb调试 PDFhao zhangNo ratings yet
- VB高级编程Document837 pagesVB高级编程Jiang CodeNo ratings yet
- Python数据分析入门:从数据获取到可视化 PDFDocument338 pagesPython数据分析入门:从数据获取到可视化 PDFShaoFei DuNo ratings yet
- 線性代數與應用 Linear Algebra and ApplicationsDocument29 pages線性代數與應用 Linear Algebra and ApplicationsSTM WorksNo ratings yet
- 20阿里字节一套高效的iOS面试题2020年2月Document47 pages20阿里字节一套高效的iOS面试题2020年2月以少年之名No ratings yet
- Leetcode 题解Document126 pagesLeetcode 题解Samsung TabletNo ratings yet
- C陷阱与缺陷 C+Traps+and+Pitfalls高清pdf版Document181 pagesC陷阱与缺陷 C+Traps+and+Pitfalls高清pdf版Yu TanNo ratings yet
- 如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Document5 pages如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Yang CaoNo ratings yet
- 如何自己从零实现一个神经网络 - - 知乎Document18 pages如何自己从零实现一个神经网络 - - 知乎Yang CaoNo ratings yet
- 格林公式的几何意义是什么? - 知乎Document19 pages格林公式的几何意义是什么? - 知乎Yang CaoNo ratings yet
- 如何记住所有的三角函数公式? - 知乎Document8 pages如何记住所有的三角函数公式? - 知乎Yang CaoNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 深度学习中的优化算法 - 知乎Document7 pages深度学习中的优化算法 - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第二节 制作led呼吸灯 - 知乎Document14 pages树莓派项目实战 第二节 制作led呼吸灯 - 知乎Yang CaoNo ratings yet
- Pandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Document21 pagesPandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第一节 点亮LED灯 - 知乎Document16 pages树莓派项目实战 第一节 点亮LED灯 - 知乎Yang CaoNo ratings yet
- 活用拉格朗日中值,吊打复杂极限难题! - 知乎Document7 pages活用拉格朗日中值,吊打复杂极限难题! - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 奇异值与特征值辨析 - 知乎Document8 pages奇异值与特征值辨析 - 知乎Yang CaoNo ratings yet
- 奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Document8 pages奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Document9 pages为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Document9 pages为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 从认知脑的计算模拟到类脑人工智能Document13 pages从认知脑的计算模拟到类脑人工智能Lynn PolyxenaNo ratings yet
- 【高层主打】华为智慧森林防火监测预警解决方案高层主打材料V1 0Document36 pages【高层主打】华为智慧森林防火监测预警解决方案高层主打材料V1 0vizardNo ratings yet
- 骆润玫 王卫星 2021 基于卷积神经网络的植物病虫害识别研究综述Document10 pages骆润玫 王卫星 2021 基于卷积神经网络的植物病虫害识别研究综述bigliang98No ratings yet
- 一本书读懂ChatGPT、AIGC和元宇宙Document129 pages一本书读懂ChatGPT、AIGC和元宇宙skydrivers1001No ratings yet
- 1667443167822973203Document62 pages1667443167822973203lincolndairyNo ratings yet
- AI生成時代Document234 pagesAI生成時代sssssssc42No ratings yet
- 20240126 海通证券 选股因子系列研究(九十三):深度学习因子的"模型动物园"Document19 pages20240126 海通证券 选股因子系列研究(九十三):深度学习因子的"模型动物园"zhaoqc418No ratings yet
- 高盛人工智能报告中文版 PDFDocument45 pages高盛人工智能报告中文版 PDFJJamesranNo ratings yet
- 2018 年网络和分布式系统安全 (NDSS) 研讨会 2018 年 2 月 18 日至 21 日, 美国加利Document15 pages2018 年网络和分布式系统安全 (NDSS) 研讨会 2018 年 2 月 18 日至 21 日, 美国加利LEENo ratings yet
- 中科院 2019年人工智能发展白皮书Document48 pages中科院 2019年人工智能发展白皮书AA AANo ratings yet
- UntitledDocument364 pagesUntitled翁坤仁No ratings yet
- 欢迎来到真实的电影评分网站Document11 pages欢迎来到真实的电影评分网站h682rdn6No ratings yet
- 24 《家人的使用说明书》黑川伊保子Document157 pages24 《家人的使用说明书》黑川伊保子IRene ReNeNo ratings yet
- 西南证券 向量数据库:AI时代的技术基座 230621Document36 pages西南证券 向量数据库:AI时代的技术基座 230621andywli0425No ratings yet
- 《所罗门的密码》 (德) 奥拉夫·格罗思, (美) 马克·尼兹伯格Document370 pages《所罗门的密码》 (德) 奥拉夫·格罗思, (美) 马克·尼兹伯格李栋No ratings yet
- AI伦理治理三大难题与哲学的诠释 王小红Document7 pagesAI伦理治理三大难题与哲学的诠释 王小红Lynn PolyxenaNo ratings yet
- 高中生活AI大智慧 1228Document133 pages高中生活AI大智慧 1228Marconi JiangNo ratings yet
- 基于无人机航拍的交通检测及流量统计算法研究 常亚楠Document69 pages基于无人机航拍的交通检测及流量统计算法研究 常亚楠mesba HoqueNo ratings yet
- 2023SCEM 審稿結果公告 0626Document16 pages2023SCEM 審稿結果公告 0626HandyNo ratings yet
- 人工智能在土木工程领域的应用研究现状及展望 刘红波Document21 pages人工智能在土木工程领域的应用研究现状及展望 刘红波hu yuexinNo ratings yet
- 基于深度学习的服务区危化品车辆识别算法研究Document4 pages基于深度学习的服务区危化品车辆识别算法研究Charles O'ConnorNo ratings yet
- 基于深度学习的风电场孤岛检测策略的研究 朱凌Document4 pages基于深度学习的风电场孤岛检测策略的研究 朱凌Fatima HaiderNo ratings yet
- 19 11 2020学习笔记Document5 pages19 11 2020学习笔记lisha yangNo ratings yet
- 基于深度学习的机翼载荷计算方法研究 刘佳玮Document65 pages基于深度学习的机翼载荷计算方法研究 刘佳玮qhylovezjyNo ratings yet
- 2023年中国数字人行业发展专题报告Document44 pages2023年中国数字人行业发展专题报告letian940No ratings yet