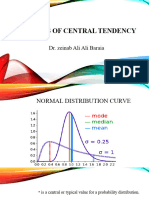
Download as pdf or txt
You might also like
- STAT 1520 NotesDocument61 pagesSTAT 1520 NotesnojnfoNo ratings yet
- Statistics NotesDocument17 pagesStatistics Notesanon_673298142No ratings yet
- Reading - Exploratory Data AnalysisDocument33 pagesReading - Exploratory Data Analysisvaibhavpardeshi55No ratings yet
- Notas EstadisticaDocument20 pagesNotas EstadisticaCristian CanazaNo ratings yet
- Math in The Modern World Stat LectureDocument3 pagesMath in The Modern World Stat LectureGylene GardonNo ratings yet
- Basic Statistics Terms and CalculationsDocument4 pagesBasic Statistics Terms and CalculationsSagir Musa SaniNo ratings yet
- M-1 CH-3 Descriptive StatistcsDocument27 pagesM-1 CH-3 Descriptive StatistcsyoginibeautyparlourNo ratings yet
- Probability MC3020Document28 pagesProbability MC3020S Dinuka MadhushanNo ratings yet
- MMW-FINALS-REVIEWER - EtcDocument4 pagesMMW-FINALS-REVIEWER - EtcRunce Louise FuentesNo ratings yet
- Biostatistics Notes Introductory ChapterDocument21 pagesBiostatistics Notes Introductory ChapterJoseph MbamboNo ratings yet
- Data-Management MMWDocument22 pagesData-Management MMWJH Garciano PosaNo ratings yet
- Choosing Appropriate Descriptive Statistics, Graphs and Statistical TestsDocument47 pagesChoosing Appropriate Descriptive Statistics, Graphs and Statistical Testsmanthan pandyaNo ratings yet
- Gtu 302 Biostatistics: Descriptive StatisticsDocument57 pagesGtu 302 Biostatistics: Descriptive StatisticsLimYiNo ratings yet
- 0826 Statistics (Class Notes) (Vanessa 2022)Document43 pages0826 Statistics (Class Notes) (Vanessa 2022)Vienne Yuen Wing YanNo ratings yet
- Presenting and Interpreting Research Data: Kim Charies L. OkitDocument34 pagesPresenting and Interpreting Research Data: Kim Charies L. OkitDodoy TacnaNo ratings yet
- MMW FinalsDocument6 pagesMMW FinalsJomarie BualNo ratings yet
- NotesDocument12 pagesNotesVinayNo ratings yet
- Descriptive Statistics 1Document63 pagesDescriptive Statistics 1Dr EngineerNo ratings yet
- Stat Review NotesDocument8 pagesStat Review Notes안지연No ratings yet
- Statistics: A Branch of Mathematics That Deals With: Planning Collecting Organizing Presenting Analyzing InterpretingDocument43 pagesStatistics: A Branch of Mathematics That Deals With: Planning Collecting Organizing Presenting Analyzing InterpretingVan DuranNo ratings yet
- Module For R-3Document14 pagesModule For R-3Amber EbayaNo ratings yet
- 8Document6 pages8ameerel3tma77No ratings yet
- Lesson 6c, 7, 8Document46 pagesLesson 6c, 7, 8Fevee Joy BalberonaNo ratings yet
- Types of Biological Data 2. Summary Descriptive StatisticsDocument23 pagesTypes of Biological Data 2. Summary Descriptive StatisticsAshutoshNo ratings yet
- Bioe211 - Week 3 - MeasuresDocument4 pagesBioe211 - Week 3 - MeasuresFormosa G.No ratings yet
- It0089 FinalreviewerDocument143 pagesIt0089 FinalreviewerKarl Erol PasionNo ratings yet
- It0089 FinalreviewerDocument143 pagesIt0089 FinalreviewerKarl Erol Pasion100% (1)
- Chapter 2 STDDocument19 pagesChapter 2 STDHƯƠNG NGUYỄN LÊ NGỌCNo ratings yet
- StatisticsDocument12 pagesStatisticsRaymond ArifiantoNo ratings yet
- MMW 6 Data Management Part 3 Central Location Variability PDFDocument5 pagesMMW 6 Data Management Part 3 Central Location Variability PDFJhuliane RalphNo ratings yet
- Topic IIIDocument27 pagesTopic IIIEmmarehBucolNo ratings yet
- Unit 4 AssessmentDocument34 pagesUnit 4 AssessmentdaisylodorNo ratings yet
- Assignment 1-Math 112EDocument13 pagesAssignment 1-Math 112EAshley DestrizaNo ratings yet
- EDA - Lesson 3 - FinalDocument4 pagesEDA - Lesson 3 - FinalJimlyn Grace GarciaNo ratings yet
- Chapter 4 StatisticsDocument16 pagesChapter 4 StatisticsGerckey RasonabeNo ratings yet
- Eda 2022 04 11 09352244Document35 pagesEda 2022 04 11 09352244NGuyen thi Kim TuyenNo ratings yet
- 3 Measures of Central Tendency (Mean, Median)Document32 pages3 Measures of Central Tendency (Mean, Median)Mohamed FathyNo ratings yet
- Excel NotesDocument13 pagesExcel NotesChaitanya SundaramNo ratings yet
- Math 7 q4 w7 Measures of VariabilityDocument22 pagesMath 7 q4 w7 Measures of VariabilitySJ Kusain0% (1)
- 2021 EDA-Module 2 DESCRIBING DATA - Oct. 22cDocument70 pages2021 EDA-Module 2 DESCRIBING DATA - Oct. 22cTest QuizNo ratings yet
- Lecture5 Stat104 Fall2017 V1 6upDocument13 pagesLecture5 Stat104 Fall2017 V1 6uphwangj3No ratings yet
- CH 4Document14 pagesCH 4Beke derejeNo ratings yet
- Gned 03 Reviewer FinalsDocument4 pagesGned 03 Reviewer FinalsKARYL MAJBRITT NUELANNo ratings yet
- 09 - Data Analysis - Descriptive StatisticsDocument23 pages09 - Data Analysis - Descriptive StatisticsNdaliNo ratings yet
- Statistics NotesDocument32 pagesStatistics Notesxujamin90No ratings yet
- Stats BasicsDocument58 pagesStats BasicsRavi goelNo ratings yet
- 1 Review of StatisticsDocument24 pages1 Review of StatisticsJay RaelNo ratings yet
- Math Majorship StatisticsDocument9 pagesMath Majorship StatisticsMark ReyesNo ratings yet
- Math Majorship Statistics PDFDocument9 pagesMath Majorship Statistics PDFRoberto Esteller Jr.No ratings yet
- Main Title: Planning Data Analysis Using Statistical DataDocument40 pagesMain Title: Planning Data Analysis Using Statistical DataRuffa L100% (1)
- IMS 504-Week 4&5 NewDocument40 pagesIMS 504-Week 4&5 NewAhmad ShahirNo ratings yet
- Measures of Central TendencyDocument15 pagesMeasures of Central TendencyAmit Gurav100% (15)
- 2 Measures of Location - DispersionDocument61 pages2 Measures of Location - DispersionShreeram IyerNo ratings yet
- Probability and Statistics Lecture NotesDocument9 pagesProbability and Statistics Lecture NotesKristine Almarez100% (1)
- Tech Seminar Sem 2Document35 pagesTech Seminar Sem 2Athira SajeevNo ratings yet
- Biostatistics and EpidemiologyDocument14 pagesBiostatistics and EpidemiologyJaneth Louie ManatadNo ratings yet
- Handout-2 1Document9 pagesHandout-2 1actdesquitadoNo ratings yet
- CH - 4Document71 pagesCH - 4PIYUSH MANGILAL SONINo ratings yet
- Data Notes For IN3Document66 pagesData Notes For IN3Lyse NdifoNo ratings yet
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignFrom EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo ratings yet
- 04 Firewall TechnologiesDocument8 pages04 Firewall TechnologiesAftab AhmadNo ratings yet
- 05 Introduction WAFDocument2 pages05 Introduction WAFAftab AhmadNo ratings yet
- Forces and Newton's Laws of Motion: ContinuedDocument34 pagesForces and Newton's Laws of Motion: ContinuedAftab AhmadNo ratings yet
- IELTS - Booking WizardDocument3 pagesIELTS - Booking WizardAftab AhmadNo ratings yet
- 6.business Tools For Service ManagerDocument53 pages6.business Tools For Service ManagerAftab AhmadNo ratings yet
- 03 Malicious SoftwareDocument10 pages03 Malicious SoftwareAftab AhmadNo ratings yet
- Log Questions AnswersDocument11 pagesLog Questions AnswersAftab AhmadNo ratings yet
- CAT Business AcumenDocument13 pagesCAT Business AcumenAftab AhmadNo ratings yet
- Customer Service Excellence in Field Service-2Document13 pagesCustomer Service Excellence in Field Service-2Aftab AhmadNo ratings yet
- Topic 20 Past Paper QuestionsDocument33 pagesTopic 20 Past Paper QuestionsAftab Ahmad0% (1)
- Asbulla - Ministry of Foreign AffairDocument1 pageAsbulla - Ministry of Foreign AffairAftab AhmadNo ratings yet
- MIS300 Week 2 (Online Version) Part 3: Cloud ComputingDocument4 pagesMIS300 Week 2 (Online Version) Part 3: Cloud ComputingAftab AhmadNo ratings yet
- Topic 24 Past Paper QuestionsDocument50 pagesTopic 24 Past Paper QuestionsAftab AhmadNo ratings yet
- SymmetryDocument34 pagesSymmetryAftab AhmadNo ratings yet
- Discovery CatalogueDocument124 pagesDiscovery CatalogueAftab AhmadNo ratings yet
- Risk and ReturnDocument3 pagesRisk and ReturnBunny HanNo ratings yet
- Chp2 - Practice 2 - Ans-1Document5 pagesChp2 - Practice 2 - Ans-1Nur AthirahNo ratings yet
- MC 103 Statistics For Business Decisions 61011104Document4 pagesMC 103 Statistics For Business Decisions 61011104Subhankar BiswasNo ratings yet
- Independent Sample T Test PDFDocument2 pagesIndependent Sample T Test PDFalfanNo ratings yet
- Assignment #3Document9 pagesAssignment #3Imen KsouriNo ratings yet
- Jamovi 1Document2 pagesJamovi 1Habib AhmadNo ratings yet
- Case Processing SummaryDocument6 pagesCase Processing Summaryal ghaisaniNo ratings yet
- 11/27/2020 1 Measures of Central TendencyDocument43 pages11/27/2020 1 Measures of Central TendencyImran KhanNo ratings yet
- Module 5 HW AnswersDocument4 pagesModule 5 HW AnswersGuerdy FaustinNo ratings yet
- Distribution in StatisticsDocument49 pagesDistribution in StatisticsAhmad MakhloufNo ratings yet
- Statistische Auswertung WiederfindungsfunktionDocument7 pagesStatistische Auswertung WiederfindungsfunktionMichael HuberNo ratings yet
- Stat Prob 11 q3 SLM Wk2Document10 pagesStat Prob 11 q3 SLM Wk2rico.odalNo ratings yet
- STAT 100 - Data Science IDocument2 pagesSTAT 100 - Data Science IRaj TiwariNo ratings yet
- Use of Transformed Auxiliary Variable in Estimating The Finite Population MeanDocument10 pagesUse of Transformed Auxiliary Variable in Estimating The Finite Population MeanGilang Al GhozaliNo ratings yet
- HW 2 Soln PDFDocument8 pagesHW 2 Soln PDFthis hihiNo ratings yet
- Latihan UtsDocument3 pagesLatihan UtsAlfiandri AdinNo ratings yet
- Unit 3 - BA - July 2022Document94 pagesUnit 3 - BA - July 2022PRAGASM PROGNo ratings yet
- Statistics Part IDocument38 pagesStatistics Part IMichelle AlejandrinoNo ratings yet
- X MF Ʃ N: The Mean Is 26.8Document6 pagesX MF Ʃ N: The Mean Is 26.8Jane PadillaNo ratings yet
- Fortnite 4STATDocument274 pagesFortnite 4STATsesori4560No ratings yet
- 10th Science Ex 6 1 Amir ShehzadDocument4 pages10th Science Ex 6 1 Amir ShehzadAbdullah NazirNo ratings yet
- Exercise 1 (Chapter 1)Document1 pageExercise 1 (Chapter 1)tsh1003No ratings yet
- Kherstie C. Deocampo Filamer Christian University Indayagan Maayon Capiz Graduate School Mat - S0C. Sci. Student 2 SEMESTER, A.Y. 2020 - 2021Document2 pagesKherstie C. Deocampo Filamer Christian University Indayagan Maayon Capiz Graduate School Mat - S0C. Sci. Student 2 SEMESTER, A.Y. 2020 - 2021Kherstie ViannetteNo ratings yet
- Adel SpssDocument15 pagesAdel SpssDeevano YoulandaNo ratings yet
- MODULE 14 Confidence IntervalsDocument26 pagesMODULE 14 Confidence IntervalsSajath SabryNo ratings yet
- Lab RecordDocument59 pagesLab RecordRuban KumarNo ratings yet
- Ie 212 Statistics: Week 2: Frequency Table and Histogram, Measures of Central Tendency and LocationDocument30 pagesIe 212 Statistics: Week 2: Frequency Table and Histogram, Measures of Central Tendency and Locationerdinç solmazNo ratings yet
- Univariate Time Series Models - Cropped PDFDocument54 pagesUnivariate Time Series Models - Cropped PDFadrianaNo ratings yet
- Skewness, Moments and KurtosisDocument23 pagesSkewness, Moments and KurtosisMeet PatelNo ratings yet
- Chapter 8 HeteroskedasticityDocument52 pagesChapter 8 HeteroskedasticitytanNo ratings yet