Download as pdf or txt
You might also like
- Depth Prediction Single ImageDocument8 pagesDepth Prediction Single ImageDiksha MeghwalNo ratings yet
- Atapour-Abarghouei Real-Time Monocular Depth CVPR 2018 Paper PDFDocument11 pagesAtapour-Abarghouei Real-Time Monocular Depth CVPR 2018 Paper PDFRob ZelNo ratings yet
- JournalPaper ASC UpdatedDocument16 pagesJournalPaper ASC UpdatedAdeeba AliNo ratings yet
- RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth EstimationDocument17 pagesRA-Depth: Resolution Adaptive Self-Supervised Monocular Depth EstimationPengZai ZhongNo ratings yet
- Zamir 2022 Mirnetv2Document15 pagesZamir 2022 Mirnetv2navya.cogni21No ratings yet
- Scancomplete: Large-Scale Scene Completion and Semantic Segmentation For 3D ScansDocument15 pagesScancomplete: Large-Scale Scene Completion and Semantic Segmentation For 3D ScansIgnacio VizzoNo ratings yet
- SPINPaper3 Final EdittedDocument10 pagesSPINPaper3 Final EdittedAdeeba AliNo ratings yet
- Context-Guided Multi-View Stereo With Depth Back-ProjectionDocument12 pagesContext-Guided Multi-View Stereo With Depth Back-Projectionwang elleryNo ratings yet
- DFANet Deep Feature Aggregation For Real-Time Semantic SegmentationDocument10 pagesDFANet Deep Feature Aggregation For Real-Time Semantic Segmentationprajna acharyaNo ratings yet
- Rombach High-Resolution Image Synthesis With Latent Diffusion Models CVPR 2022 Paper-2Document12 pagesRombach High-Resolution Image Synthesis With Latent Diffusion Models CVPR 2022 Paper-2Dinuo LiaoNo ratings yet
- EdgeConnect Structure Guided Image Inpainting Using Edge PredictionDocument10 pagesEdgeConnect Structure Guided Image Inpainting Using Edge Predictiontthod37No ratings yet
- SuperResolution 1702.00783 PDFDocument21 pagesSuperResolution 1702.00783 PDFPJFNo ratings yet
- Atapour-Abarghouei Veritatem Dies Aperit - Temporally Consistent Depth Prediction Enabled by CVPR 2019 Paper PDFDocument12 pagesAtapour-Abarghouei Veritatem Dies Aperit - Temporally Consistent Depth Prediction Enabled by CVPR 2019 Paper PDFRob ZelNo ratings yet
- Liu A Data-Centric Solution To NonHomogeneous Dehazing Via Vision Transformer CVPRW 2023 PaperDocument10 pagesLiu A Data-Centric Solution To NonHomogeneous Dehazing Via Vision Transformer CVPRW 2023 Paperlohithinfinite154No ratings yet
- Learning Non-Volumetric Depth Fusion Using Successive ReprojectionsDocument10 pagesLearning Non-Volumetric Depth Fusion Using Successive ReprojectionsIgnacio VizzoNo ratings yet
- Nazeri EdgeConnect Structure Guided Image Inpainting Using Edge Prediction ICCVW 2019 PaperDocument10 pagesNazeri EdgeConnect Structure Guided Image Inpainting Using Edge Prediction ICCVW 2019 PaperLuis Dominguez LeitonNo ratings yet
- 4K-NeRF High Fidelity Neural Radiance Fields at Ultra High ResolutionsDocument16 pages4K-NeRF High Fidelity Neural Radiance Fields at Ultra High Resolutions854694704No ratings yet
- Depth Estimation From Single Image Using CNN-Residual NetworkDocument8 pagesDepth Estimation From Single Image Using CNN-Residual NetworkBora CobanogluNo ratings yet
- Li Depth and Surface 2015 CVPR PaperDocument9 pagesLi Depth and Surface 2015 CVPR PaperMNo ratings yet
- Deep Monocular Depth Estimation Via Integration of Global and Local PredictionsDocument2 pagesDeep Monocular Depth Estimation Via Integration of Global and Local Predictionsbvkarthik2711No ratings yet
- Point Based Rendering Enhancement Via Deep Learning: December 16, 2018Document13 pagesPoint Based Rendering Enhancement Via Deep Learning: December 16, 2018ArmandoNo ratings yet
- Hierarchical Multi EscalaDocument11 pagesHierarchical Multi EscalaFabian GuisaoNo ratings yet
- 2021-Depth From Defocus With Learned Optics For Imaging and Occlusion-Aware Depth EstimationDocument12 pages2021-Depth From Defocus With Learned Optics For Imaging and Occlusion-Aware Depth Estimationcynorr rainNo ratings yet
- 1 s2.0 S0167739X20330259 MainDocument9 pages1 s2.0 S0167739X20330259 Mainzhujin1121No ratings yet
- Alleviating Distortion in Image Generation Via Multi-Resolution Diffusion ModelsDocument22 pagesAlleviating Distortion in Image Generation Via Multi-Resolution Diffusion Modelssumedhgirish.ronaldo7No ratings yet
- Stable DiffusionDocument23 pagesStable Diffusionyz-zhao20No ratings yet
- High-Resolution Image Synthesis With Latent Diffusion ModelsDocument45 pagesHigh-Resolution Image Synthesis With Latent Diffusion ModelsMike KawasakiNo ratings yet
- Yu Generative Image Inpainting CVPR 2018 PaperDocument10 pagesYu Generative Image Inpainting CVPR 2018 PaperAqpDevs AqpNo ratings yet
- Montefloor: Extending Mcts For Reconstructing Accurate Large-Scale Floor PlansDocument16 pagesMontefloor: Extending Mcts For Reconstructing Accurate Large-Scale Floor Plansgorav sharmaNo ratings yet
- Sensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkDocument20 pagesSensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkKratika VarshneyNo ratings yet
- Development of Image Super-Resolution FrameworkDocument5 pagesDevelopment of Image Super-Resolution FrameworkIAES International Journal of Robotics and AutomationNo ratings yet
- Deep Koalarization: Image Colorization Using Cnns and Inception-Resnet-V2Document12 pagesDeep Koalarization: Image Colorization Using Cnns and Inception-Resnet-V2Aditya TiwariNo ratings yet
- CVPR2019 Residual Regression With Semantic Prior For Crowd CountingDocument10 pagesCVPR2019 Residual Regression With Semantic Prior For Crowd CountingvenjynNo ratings yet
- 2019-Deep Optics For Monocular Depth Estimation and 3D Object DetectionDocument10 pages2019-Deep Optics For Monocular Depth Estimation and 3D Object Detectioncynorr rainNo ratings yet
- 2024 - PointInfinity Resolution-Invariant Point Diffusion Models - Huang Et AlDocument11 pages2024 - PointInfinity Resolution-Invariant Point Diffusion Models - Huang Et AllinkzdNo ratings yet
- AdaStereo (2021)Document18 pagesAdaStereo (2021)Elizabeth MartinezNo ratings yet
- High-Fidelity Pluralistic Image Completion With TransformersDocument10 pagesHigh-Fidelity Pluralistic Image Completion With TransformersTCOC33T Shivani RaoNo ratings yet
- Mobilepotrait c&g19Document10 pagesMobilepotrait c&g19yueyue19991013No ratings yet
- Luo Etal Cvpr16Document9 pagesLuo Etal Cvpr16Chulbul PandeyNo ratings yet
- Learning Enriched Features For Real Image Restoration and EnhancementDocument20 pagesLearning Enriched Features For Real Image Restoration and Enhancementnavya.cogni21No ratings yet
- Real-Time Semantic Segmentation With Fast AttentionDocument7 pagesReal-Time Semantic Segmentation With Fast Attentiontest testNo ratings yet
- Generative - Adversarial - Networks - For - Extreme - Learned - Image - CompressionDocument11 pagesGenerative - Adversarial - Networks - For - Extreme - Learned - Image - CompressionThe ProphecyNo ratings yet
- G H F I S P N M U: Enerating IGH Idelity Mages With Ubscale Ixel Etworks AND Ultidimensional PscalingDocument14 pagesG H F I S P N M U: Enerating IGH Idelity Mages With Ubscale Ixel Etworks AND Ultidimensional PscalingyyscribdNo ratings yet
- CSENMT A Deep Image Compressed Sensing Encryption Net - 2024 - Expert Systems WDocument20 pagesCSENMT A Deep Image Compressed Sensing Encryption Net - 2024 - Expert Systems WPhi MaiNo ratings yet
- Deep Collaborative Learning Approach Over Object RecognitionDocument5 pagesDeep Collaborative Learning Approach Over Object RecognitionIjsrnet EditorialNo ratings yet
- Unsupervised Pixel-Level Domain Adaptation With Generative Adversarial NetworksDocument15 pagesUnsupervised Pixel-Level Domain Adaptation With Generative Adversarial NetworksqweasdzxcNo ratings yet
- Image Restoration Using Deep LearningDocument12 pagesImage Restoration Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Enhanced Deep Residual Networks For Single Image Super-ResolutionDocument9 pagesEnhanced Deep Residual Networks For Single Image Super-ResolutionDenis ChikiBrikiNo ratings yet
- Rocco Convolutional Neural Network CVPR 2017 PaperDocument10 pagesRocco Convolutional Neural Network CVPR 2017 PaperAkshay PratapNo ratings yet
- Real-Time Salient Object Detection With A Minimum Spanning TreeDocument9 pagesReal-Time Salient Object Detection With A Minimum Spanning TreeSaeideh OraeiNo ratings yet
- Real Image Denoising With Feature AttentionDocument10 pagesReal Image Denoising With Feature AttentionWENTING XUNo ratings yet
- Colorizing Images Using CNN in Machine LearningDocument6 pagesColorizing Images Using CNN in Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Gu Cascade Cost Volume For High-Resolution Multi-View Stereo and Stereo Matching CVPR 2020 PaperDocument10 pagesGu Cascade Cost Volume For High-Resolution Multi-View Stereo and Stereo Matching CVPR 2020 Paper7knhfwr87wNo ratings yet
- NeuralFusion Online Depth Fusion in Latent Space CVPRDocument11 pagesNeuralFusion Online Depth Fusion in Latent Space CVPRHarre Bams Ayma ArandaNo ratings yet
- Pixelsynth: Generating A 3D-Consistent Experience From A Single ImageDocument19 pagesPixelsynth: Generating A 3D-Consistent Experience From A Single ImageHonza FerbrNo ratings yet
- Reversible Watermarking Based On Sorting Prediction SchemeDocument4 pagesReversible Watermarking Based On Sorting Prediction Schemeangki_angNo ratings yet
- Artificial Intelligence (A Modern Approach)Document22 pagesArtificial Intelligence (A Modern Approach)Laure KamalanduaNo ratings yet
- Bidirectional Attention Network For Monocular Depth EstimationDocument7 pagesBidirectional Attention Network For Monocular Depth Estimation徐啸宇No ratings yet
- Raychem Molded PartsDocument28 pagesRaychem Molded PartsAMNo ratings yet
- Peavey Xr8000 SCHDocument12 pagesPeavey Xr8000 SCHLisandro Orrego SalvadorNo ratings yet
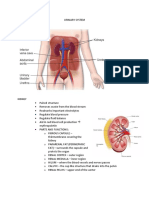
- Urinary SystemDocument9 pagesUrinary SystemMary Joyce RamosNo ratings yet
- Min Pin Sweater Paradise - Autumn Stripes Crochet Min Pin SweaterDocument6 pagesMin Pin Sweater Paradise - Autumn Stripes Crochet Min Pin SweaterNathalyaNo ratings yet
- Fan Heater - B-011 - Data SheetsDocument9 pagesFan Heater - B-011 - Data SheetsNadim Ahmad SiddiqueNo ratings yet
- Quadratic Factorization AssignmentDocument4 pagesQuadratic Factorization Assignmentsaim sohailNo ratings yet
- Essay Types Character Analysis EssayDocument7 pagesEssay Types Character Analysis EssayFatihNo ratings yet
- Scale: 1:5 (1:2) : R TYP 5Document1 pageScale: 1:5 (1:2) : R TYP 5Prateek AnandNo ratings yet
- Music Therapy When Death Is Imminent - A Phenomenological InquiryDocument32 pagesMusic Therapy When Death Is Imminent - A Phenomenological InquiryJuan Luis Köstner MartinoNo ratings yet
- AC-825 - Datasheet - ENDocument2 pagesAC-825 - Datasheet - ENkalkumarmNo ratings yet
- Bending Stresses in BeamsDocument25 pagesBending Stresses in Beamsrajatapc12007No ratings yet
- Asus T12C (X51C) Motherboard Schematic DiagramDocument94 pagesAsus T12C (X51C) Motherboard Schematic DiagramYblis100% (1)
- Sonia Thakker 184 Jignesh Bhatt 105 Rekha Wachkawde 188 Shailendra Singh 178 Pravin Nayak 147 Jibu James 128Document44 pagesSonia Thakker 184 Jignesh Bhatt 105 Rekha Wachkawde 188 Shailendra Singh 178 Pravin Nayak 147 Jibu James 128treakoNo ratings yet
- Progressive Utilisation Prospects of Coal Fly Ash A ReviewDocument36 pagesProgressive Utilisation Prospects of Coal Fly Ash A ReviewDivakar SaiNo ratings yet
- Eurocode Conference 2023 Pluijm Van Der Eurocode 6Document14 pagesEurocode Conference 2023 Pluijm Van Der Eurocode 6Rodolfo BlanchiettiNo ratings yet
- PPP-Eclipse-E05 Module 05 IDUsDocument11 pagesPPP-Eclipse-E05 Module 05 IDUsJervy SegarraNo ratings yet
- Biology Form 5: 5.1: MENDEL'S ExperimentDocument29 pagesBiology Form 5: 5.1: MENDEL'S Experimentveronica francisNo ratings yet
- Turbodrain EnglDocument8 pagesTurbodrain EnglIonut BuzescuNo ratings yet
- Research On Sustainable Development of Textile Industrial Clusters in The Process of GlobalizationDocument5 pagesResearch On Sustainable Development of Textile Industrial Clusters in The Process of GlobalizationSam AbdulNo ratings yet
- An0002 Efm32 Hardware Design ConsiderationsDocument16 pagesAn0002 Efm32 Hardware Design ConsiderationsRam SakthiNo ratings yet
- Campbeltown's Kilkerran Gun BatteryDocument2 pagesCampbeltown's Kilkerran Gun BatteryKintyre On RecordNo ratings yet
- Maya Under Water LightingDocument12 pagesMaya Under Water LightingKombiah RkNo ratings yet
- Pathway - Skoliosis GROUPDocument12 pagesPathway - Skoliosis GROUPAnonymous NZTQVgjaNo ratings yet
- 132kv, 1200sqmm UNDER GROUND CABLE WORKSDocument4 pages132kv, 1200sqmm UNDER GROUND CABLE WORKSBadhur ZamanNo ratings yet
- Full Download Strategies For Teaching Learners With Special Needs 11th Edition Polloway Test BankDocument36 pagesFull Download Strategies For Teaching Learners With Special Needs 11th Edition Polloway Test Banklevidelpnrr100% (31)
- Ingersoll Rand Ingersoll Rand Compressor 39880984 Interstage Pressure SwitchDocument1 pageIngersoll Rand Ingersoll Rand Compressor 39880984 Interstage Pressure Switchbara putranta fahdliNo ratings yet
- P&Z Electronic (Dongguan) Co.,LtdDocument3 pagesP&Z Electronic (Dongguan) Co.,LtdTRMNo ratings yet
- RFIDDocument18 pagesRFIDKulavardan ThalapulaNo ratings yet
- Product Data: Order Tracking Analyzer - Type 2145Document8 pagesProduct Data: Order Tracking Analyzer - Type 2145jhon vargasNo ratings yet
- Travel Tourism in Bangladesh: A Study On Regent Tours & TravelDocument72 pagesTravel Tourism in Bangladesh: A Study On Regent Tours & TravelNahidNo ratings yet