
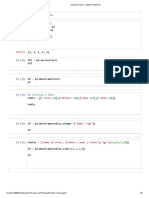
Pandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List Labels
Pandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List Labels
You might also like
- Intermediate Algebra Within Reach 6th Edition Larson Solutions ManualDocument17 pagesIntermediate Algebra Within Reach 6th Edition Larson Solutions Manualjacquelineglennwqyioeptsc100% (19)
- FGC Team Greece Eng Book v3Document28 pagesFGC Team Greece Eng Book v3api-656115276No ratings yet
- MCB of Acdb Test ReportDocument1 pageMCB of Acdb Test Reportganeshapec8No ratings yet
- O Level Computer Studies Notes - ZIMSEC Syllabus PDFDocument98 pagesO Level Computer Studies Notes - ZIMSEC Syllabus PDFkeith magaka71% (89)
- Chemical Composition of Wood Pettersen 1984Document70 pagesChemical Composition of Wood Pettersen 1984mchaves93No ratings yet
- Pandas Basics PracticeDocument1 pagePandas Basics PracticeTayub khan.ANo ratings yet
- Solutions To Pandas Basic QuestionsDocument1 pageSolutions To Pandas Basic QuestionsJason ShaxNo ratings yet
- 2 Pandas Basics Practice 2 PDFDocument1 page2 Pandas Basics Practice 2 PDFShubham TagalpallewarNo ratings yet
- Pandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List LabelsDocument7 pagesPandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List LabelsABCNo ratings yet
- Pandas Day 1Document3 pagesPandas Day 1Ali KhokharNo ratings yet
- Kamaljeet Singh (19103052) : DF Datasets IrisDocument5 pagesKamaljeet Singh (19103052) : DF Datasets IrisJagrit SharmaNo ratings yet
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- 3a Data Frame - Jupyter NotebookDocument5 pages3a Data Frame - Jupyter Notebookvenkatesh mNo ratings yet
- Data Cleaning and Pre Processing 2Document27 pagesData Cleaning and Pre Processing 2NipuniNo ratings yet
- BDA pr2Document2 pagesBDA pr2Dev PathakNo ratings yet
- Pandas Day 4Document7 pagesPandas Day 4Ali KhokharNo ratings yet
- Sessional QP-TaTDocument5 pagesSessional QP-TaTADITYA THAKURNo ratings yet
- ML#07Document21 pagesML#07Kiki NhabindeNo ratings yet
- Using R For Data Preprocessing, Exploratory Analysis, VisualizationDocument7 pagesUsing R For Data Preprocessing, Exploratory Analysis, VisualizationNikita DesaiNo ratings yet
- Columbia Seaborn TutorialDocument12 pagesColumbia Seaborn TutorialPatri ZioNo ratings yet
- Assignment 1Document6 pagesAssignment 1Akshata ChopadeNo ratings yet
- Module 2 Iris Data SetDocument1 pageModule 2 Iris Data SetRachell Ann UsonNo ratings yet
- University Institute of Engineering Department of Computer Science & EngineeringDocument18 pagesUniversity Institute of Engineering Department of Computer Science & EngineeringAnkit SiNghNo ratings yet
- Assignment No - 10Document3 pagesAssignment No - 10Sid ChabukswarNo ratings yet
- Experiment - 2 Misc.Document4 pagesExperiment - 2 Misc.Siffatjot SinghNo ratings yet
- Full Download Intermediate Algebra Within Reach 6th Edition Larson Solutions ManualDocument35 pagesFull Download Intermediate Algebra Within Reach 6th Edition Larson Solutions Manualkrossenflorrie355100% (39)
- Dwnload Full Intermediate Algebra Within Reach 6th Edition Larson Solutions Manual PDFDocument35 pagesDwnload Full Intermediate Algebra Within Reach 6th Edition Larson Solutions Manual PDFsimcockkalystaz100% (13)
- b21 DSBDA Assignment No 10Document1 pageb21 DSBDA Assignment No 10PrachiNo ratings yet
- Data Exploration and Visualisation With R: Yanchang ZhaoDocument45 pagesData Exploration and Visualisation With R: Yanchang ZhaoAnish KumarNo ratings yet
- Week 5-MathsDocument16 pagesWeek 5-Mathsrithika.rajkumar2009No ratings yet
- Babd End-TermDocument43 pagesBabd End-TermTARUN SAININo ratings yet
- ML 1Document4 pagesML 1yefigoh133No ratings yet
- PracticalDocument28 pagesPracticalDhruti PatelNo ratings yet
- 05 NumpyDocument2 pages05 NumpyDivyanshu SumanNo ratings yet
- SC Assignment Q2Document7 pagesSC Assignment Q2RAGHUVAMSHI -2019BCSIIITKNo ratings yet
- Linear Functions Practice Quiz: Name: Class: Date: Id: ADocument11 pagesLinear Functions Practice Quiz: Name: Class: Date: Id: AJOHN-REY MANZANONo ratings yet
- NumpyDocument40 pagesNumpyxhittu2No ratings yet
- B 4 TipsDocument10 pagesB 4 TipsSuhani ShindeNo ratings yet
- 1.1 Objective: 2. Data Preparation and Exploratory AnalysisDocument11 pages1.1 Objective: 2. Data Preparation and Exploratory Analysisk767No ratings yet
- Exemplar_Perform Feature EngineeringDocument14 pagesExemplar_Perform Feature EngineeringTrần Hoàng Thuý VyNo ratings yet
- Stastistics and Probability With R Programming Language: Lab ReportDocument44 pagesStastistics and Probability With R Programming Language: Lab ReportAyush Anand Sagar50% (2)
- Unit 3 - CH 2. ArraysDocument35 pagesUnit 3 - CH 2. ArraysManjunatha H RNo ratings yet
- Assignment 2Document13 pagesAssignment 2tzeloNo ratings yet
- Python Chap 3 - Strings, List, MapsDocument24 pagesPython Chap 3 - Strings, List, MapsSasithra SockalingamNo ratings yet
- 8HL Linear Relations Revision J JW SJDocument3 pages8HL Linear Relations Revision J JW SJAaron THE24No ratings yet
- Breadth First Search: # List For Visited Nodes. #Initialize A Queue #Function For BFSDocument31 pagesBreadth First Search: # List For Visited Nodes. #Initialize A Queue #Function For BFSdhruv kumarNo ratings yet
- Assignment 1 (R Programming)Document24 pagesAssignment 1 (R Programming)Priya kambleNo ratings yet
- Decision TreeDocument4 pagesDecision TreeHrithik MishraNo ratings yet
- CSE 109 Computer Programming: Arrays and StringsDocument42 pagesCSE 109 Computer Programming: Arrays and StringsFarhanNo ratings yet
- Data Manipulation Assign.Document7 pagesData Manipulation Assign.shravanNo ratings yet
- MyChap3-Classification - Part 1Document21 pagesMyChap3-Classification - Part 1phhq6n4hsrNo ratings yet
- Prac 10Document6 pagesPrac 1003rajput.kiNo ratings yet
- Tabletop Game IdeasDocument5 pagesTabletop Game IdeasTyler HermanNo ratings yet
- Assignment 10Document9 pagesAssignment 10SHREYANSHU KODILKARNo ratings yet
- Year End Review 2021Document22 pagesYear End Review 2021alscd24No ratings yet
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- Expt. No. Basic Math DateDocument24 pagesExpt. No. Basic Math DateArun PeethambaranNo ratings yet
- Dsbda 10Document3 pagesDsbda 10monaliauti2No ratings yet
- Pandas - Jupyter NotebookDocument32 pagesPandas - Jupyter NotebookLahari BanalaNo ratings yet
- Heart Attacks AnalysisDocument10 pagesHeart Attacks AnalysisNarasimhaNo ratings yet
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
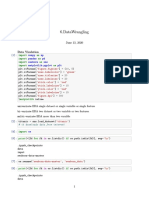
- 6.datawrangling: Data VisulationDocument27 pages6.datawrangling: Data VisulationAnish pandeyNo ratings yet
- Jumpstarters for Algebra, Grades 7 - 8: Short Daily Warm-ups for the ClassroomFrom EverandJumpstarters for Algebra, Grades 7 - 8: Short Daily Warm-ups for the ClassroomNo ratings yet
- Grade 4 DLL Quarter 2 Week 4 (Sir Bien Cruz)Document42 pagesGrade 4 DLL Quarter 2 Week 4 (Sir Bien Cruz)FayeNo ratings yet
- OPzV Solar PowerDocument2 pagesOPzV Solar PowerSINES FranceNo ratings yet
- SPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDocument15 pagesSPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDonald WolcottNo ratings yet
- UNIT1Document37 pagesUNIT1Azliana Mohd Taib0% (1)
- bullion-HT003 PCIe Adapter Firmware Updatev2Document14 pagesbullion-HT003 PCIe Adapter Firmware Updatev2Fabrice PLATELNo ratings yet
- Extended Abstract Pankaj AroraLKKHIDocument10 pagesExtended Abstract Pankaj AroraLKKHIAidiaiem KhawaijNo ratings yet
- Heat Transfer, Incopera 977 988Document12 pagesHeat Transfer, Incopera 977 988Rayhan HakimNo ratings yet
- Bilimeter OP ManualDocument16 pagesBilimeter OP ManualargonaiseNo ratings yet
- Space ExplorerDocument126 pagesSpace ExplorerJohn Vivian Prashant jp7vivianNo ratings yet
- SAP GST India - Master - Notes DetailsDocument7 pagesSAP GST India - Master - Notes DetailsBalaji_SAPNo ratings yet
- The Design of Small Slot ArraysDocument6 pagesThe Design of Small Slot ArraysRoberto B. Di RennaNo ratings yet
- Siemens Power Engineering Guide 7E 83Document1 pageSiemens Power Engineering Guide 7E 83mydearteacherNo ratings yet
- Cantilever SlabDocument3 pagesCantilever SlabMatumbi NaitoNo ratings yet
- 6.01 Exploratory Data AnalysisDocument3 pages6.01 Exploratory Data Analysisjayant khanvilkarNo ratings yet
- Cambridge Ordinary LevelDocument20 pagesCambridge Ordinary Levelqsqt78jq6yNo ratings yet
- System Resources On PC (IRQ, DMA, I-OAddress)Document4 pagesSystem Resources On PC (IRQ, DMA, I-OAddress)guilhangNo ratings yet
- SubgradfDocument21 pagesSubgradfsharvan10No ratings yet
- Dell Wireless 1390 WLAN Mini Card SpecificationsDocument1 pageDell Wireless 1390 WLAN Mini Card SpecificationsWiseUtopianNo ratings yet
- Questions For JavaScriptDocument4 pagesQuestions For JavaScriptNikolaiNo ratings yet
- 16 P11 SEch 05Document30 pages16 P11 SEch 05ZIMO WANG (Student)No ratings yet
- Lesson 1 - IntroductionDocument10 pagesLesson 1 - IntroductionMelvyn DarauayNo ratings yet
- Astrological Charts of People, Events, and Locations.: August 2021Document4 pagesAstrological Charts of People, Events, and Locations.: August 2021Maneesh MisraNo ratings yet
- Piezo Concept Strain GaugeDocument22 pagesPiezo Concept Strain GaugeAndika Surya HadiwinataNo ratings yet
- LCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. MooreDocument6 pagesLCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. Mooreinher1tanceNo ratings yet
- Hysteretic Response of RC Infilled Frames - Altin 1992Document18 pagesHysteretic Response of RC Infilled Frames - Altin 1992Nefeli ChatzatoglouNo ratings yet
- Photosynthesis Review QuestionsDocument4 pagesPhotosynthesis Review Questionsdee eeNo ratings yet
























































































Download as pdf or txt
You might also like
- Intermediate Algebra Within Reach 6th Edition Larson Solutions ManualDocument17 pagesIntermediate Algebra Within Reach 6th Edition Larson Solutions Manualjacquelineglennwqyioeptsc100% (19)
- FGC Team Greece Eng Book v3Document28 pagesFGC Team Greece Eng Book v3api-656115276No ratings yet
- MCB of Acdb Test ReportDocument1 pageMCB of Acdb Test Reportganeshapec8No ratings yet
- O Level Computer Studies Notes - ZIMSEC Syllabus PDFDocument98 pagesO Level Computer Studies Notes - ZIMSEC Syllabus PDFkeith magaka71% (89)
- Chemical Composition of Wood Pettersen 1984Document70 pagesChemical Composition of Wood Pettersen 1984mchaves93No ratings yet
- Pandas Basics PracticeDocument1 pagePandas Basics PracticeTayub khan.ANo ratings yet
- Solutions To Pandas Basic QuestionsDocument1 pageSolutions To Pandas Basic QuestionsJason ShaxNo ratings yet
- 2 Pandas Basics Practice 2 PDFDocument1 page2 Pandas Basics Practice 2 PDFShubham TagalpallewarNo ratings yet
- Pandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List LabelsDocument7 pagesPandas - Basics - Practice: Consider The Following Python Dictionary Data and Python List LabelsABCNo ratings yet
- Pandas Day 1Document3 pagesPandas Day 1Ali KhokharNo ratings yet
- Kamaljeet Singh (19103052) : DF Datasets IrisDocument5 pagesKamaljeet Singh (19103052) : DF Datasets IrisJagrit SharmaNo ratings yet
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- 3a Data Frame - Jupyter NotebookDocument5 pages3a Data Frame - Jupyter Notebookvenkatesh mNo ratings yet
- Data Cleaning and Pre Processing 2Document27 pagesData Cleaning and Pre Processing 2NipuniNo ratings yet
- BDA pr2Document2 pagesBDA pr2Dev PathakNo ratings yet
- Pandas Day 4Document7 pagesPandas Day 4Ali KhokharNo ratings yet
- Sessional QP-TaTDocument5 pagesSessional QP-TaTADITYA THAKURNo ratings yet
- ML#07Document21 pagesML#07Kiki NhabindeNo ratings yet
- Using R For Data Preprocessing, Exploratory Analysis, VisualizationDocument7 pagesUsing R For Data Preprocessing, Exploratory Analysis, VisualizationNikita DesaiNo ratings yet
- Columbia Seaborn TutorialDocument12 pagesColumbia Seaborn TutorialPatri ZioNo ratings yet
- Assignment 1Document6 pagesAssignment 1Akshata ChopadeNo ratings yet
- Module 2 Iris Data SetDocument1 pageModule 2 Iris Data SetRachell Ann UsonNo ratings yet
- University Institute of Engineering Department of Computer Science & EngineeringDocument18 pagesUniversity Institute of Engineering Department of Computer Science & EngineeringAnkit SiNghNo ratings yet
- Assignment No - 10Document3 pagesAssignment No - 10Sid ChabukswarNo ratings yet
- Experiment - 2 Misc.Document4 pagesExperiment - 2 Misc.Siffatjot SinghNo ratings yet
- Full Download Intermediate Algebra Within Reach 6th Edition Larson Solutions ManualDocument35 pagesFull Download Intermediate Algebra Within Reach 6th Edition Larson Solutions Manualkrossenflorrie355100% (39)
- Dwnload Full Intermediate Algebra Within Reach 6th Edition Larson Solutions Manual PDFDocument35 pagesDwnload Full Intermediate Algebra Within Reach 6th Edition Larson Solutions Manual PDFsimcockkalystaz100% (13)
- b21 DSBDA Assignment No 10Document1 pageb21 DSBDA Assignment No 10PrachiNo ratings yet
- Data Exploration and Visualisation With R: Yanchang ZhaoDocument45 pagesData Exploration and Visualisation With R: Yanchang ZhaoAnish KumarNo ratings yet
- Week 5-MathsDocument16 pagesWeek 5-Mathsrithika.rajkumar2009No ratings yet
- Babd End-TermDocument43 pagesBabd End-TermTARUN SAININo ratings yet
- ML 1Document4 pagesML 1yefigoh133No ratings yet
- PracticalDocument28 pagesPracticalDhruti PatelNo ratings yet
- 05 NumpyDocument2 pages05 NumpyDivyanshu SumanNo ratings yet
- SC Assignment Q2Document7 pagesSC Assignment Q2RAGHUVAMSHI -2019BCSIIITKNo ratings yet
- Linear Functions Practice Quiz: Name: Class: Date: Id: ADocument11 pagesLinear Functions Practice Quiz: Name: Class: Date: Id: AJOHN-REY MANZANONo ratings yet
- NumpyDocument40 pagesNumpyxhittu2No ratings yet
- B 4 TipsDocument10 pagesB 4 TipsSuhani ShindeNo ratings yet
- 1.1 Objective: 2. Data Preparation and Exploratory AnalysisDocument11 pages1.1 Objective: 2. Data Preparation and Exploratory Analysisk767No ratings yet
- Exemplar_Perform Feature EngineeringDocument14 pagesExemplar_Perform Feature EngineeringTrần Hoàng Thuý VyNo ratings yet
- Stastistics and Probability With R Programming Language: Lab ReportDocument44 pagesStastistics and Probability With R Programming Language: Lab ReportAyush Anand Sagar50% (2)
- Unit 3 - CH 2. ArraysDocument35 pagesUnit 3 - CH 2. ArraysManjunatha H RNo ratings yet
- Assignment 2Document13 pagesAssignment 2tzeloNo ratings yet
- Python Chap 3 - Strings, List, MapsDocument24 pagesPython Chap 3 - Strings, List, MapsSasithra SockalingamNo ratings yet
- 8HL Linear Relations Revision J JW SJDocument3 pages8HL Linear Relations Revision J JW SJAaron THE24No ratings yet
- Breadth First Search: # List For Visited Nodes. #Initialize A Queue #Function For BFSDocument31 pagesBreadth First Search: # List For Visited Nodes. #Initialize A Queue #Function For BFSdhruv kumarNo ratings yet
- Assignment 1 (R Programming)Document24 pagesAssignment 1 (R Programming)Priya kambleNo ratings yet
- Decision TreeDocument4 pagesDecision TreeHrithik MishraNo ratings yet
- CSE 109 Computer Programming: Arrays and StringsDocument42 pagesCSE 109 Computer Programming: Arrays and StringsFarhanNo ratings yet
- Data Manipulation Assign.Document7 pagesData Manipulation Assign.shravanNo ratings yet
- MyChap3-Classification - Part 1Document21 pagesMyChap3-Classification - Part 1phhq6n4hsrNo ratings yet
- Prac 10Document6 pagesPrac 1003rajput.kiNo ratings yet
- Tabletop Game IdeasDocument5 pagesTabletop Game IdeasTyler HermanNo ratings yet
- Assignment 10Document9 pagesAssignment 10SHREYANSHU KODILKARNo ratings yet
- Year End Review 2021Document22 pagesYear End Review 2021alscd24No ratings yet
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- Expt. No. Basic Math DateDocument24 pagesExpt. No. Basic Math DateArun PeethambaranNo ratings yet
- Dsbda 10Document3 pagesDsbda 10monaliauti2No ratings yet
- Pandas - Jupyter NotebookDocument32 pagesPandas - Jupyter NotebookLahari BanalaNo ratings yet
- Heart Attacks AnalysisDocument10 pagesHeart Attacks AnalysisNarasimhaNo ratings yet
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- 6.datawrangling: Data VisulationDocument27 pages6.datawrangling: Data VisulationAnish pandeyNo ratings yet
- Jumpstarters for Algebra, Grades 7 - 8: Short Daily Warm-ups for the ClassroomFrom EverandJumpstarters for Algebra, Grades 7 - 8: Short Daily Warm-ups for the ClassroomNo ratings yet
- Grade 4 DLL Quarter 2 Week 4 (Sir Bien Cruz)Document42 pagesGrade 4 DLL Quarter 2 Week 4 (Sir Bien Cruz)FayeNo ratings yet
- OPzV Solar PowerDocument2 pagesOPzV Solar PowerSINES FranceNo ratings yet
- SPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDocument15 pagesSPE-196769-MS - Burdakov, Wolcott - WAG Pilot Design and ResultsDonald WolcottNo ratings yet
- UNIT1Document37 pagesUNIT1Azliana Mohd Taib0% (1)
- bullion-HT003 PCIe Adapter Firmware Updatev2Document14 pagesbullion-HT003 PCIe Adapter Firmware Updatev2Fabrice PLATELNo ratings yet
- Extended Abstract Pankaj AroraLKKHIDocument10 pagesExtended Abstract Pankaj AroraLKKHIAidiaiem KhawaijNo ratings yet
- Heat Transfer, Incopera 977 988Document12 pagesHeat Transfer, Incopera 977 988Rayhan HakimNo ratings yet
- Bilimeter OP ManualDocument16 pagesBilimeter OP ManualargonaiseNo ratings yet
- Space ExplorerDocument126 pagesSpace ExplorerJohn Vivian Prashant jp7vivianNo ratings yet
- SAP GST India - Master - Notes DetailsDocument7 pagesSAP GST India - Master - Notes DetailsBalaji_SAPNo ratings yet
- The Design of Small Slot ArraysDocument6 pagesThe Design of Small Slot ArraysRoberto B. Di RennaNo ratings yet
- Siemens Power Engineering Guide 7E 83Document1 pageSiemens Power Engineering Guide 7E 83mydearteacherNo ratings yet
- Cantilever SlabDocument3 pagesCantilever SlabMatumbi NaitoNo ratings yet
- 6.01 Exploratory Data AnalysisDocument3 pages6.01 Exploratory Data Analysisjayant khanvilkarNo ratings yet
- Cambridge Ordinary LevelDocument20 pagesCambridge Ordinary Levelqsqt78jq6yNo ratings yet
- System Resources On PC (IRQ, DMA, I-OAddress)Document4 pagesSystem Resources On PC (IRQ, DMA, I-OAddress)guilhangNo ratings yet
- SubgradfDocument21 pagesSubgradfsharvan10No ratings yet
- Dell Wireless 1390 WLAN Mini Card SpecificationsDocument1 pageDell Wireless 1390 WLAN Mini Card SpecificationsWiseUtopianNo ratings yet
- Questions For JavaScriptDocument4 pagesQuestions For JavaScriptNikolaiNo ratings yet
- 16 P11 SEch 05Document30 pages16 P11 SEch 05ZIMO WANG (Student)No ratings yet
- Lesson 1 - IntroductionDocument10 pagesLesson 1 - IntroductionMelvyn DarauayNo ratings yet
- Astrological Charts of People, Events, and Locations.: August 2021Document4 pagesAstrological Charts of People, Events, and Locations.: August 2021Maneesh MisraNo ratings yet
- Piezo Concept Strain GaugeDocument22 pagesPiezo Concept Strain GaugeAndika Surya HadiwinataNo ratings yet
- LCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. MooreDocument6 pagesLCM: Lightweight Communications and Marshalling: Albert S. Huang, Edwin Olson, David C. Mooreinher1tanceNo ratings yet
- Hysteretic Response of RC Infilled Frames - Altin 1992Document18 pagesHysteretic Response of RC Infilled Frames - Altin 1992Nefeli ChatzatoglouNo ratings yet
- Photosynthesis Review QuestionsDocument4 pagesPhotosynthesis Review Questionsdee eeNo ratings yet