
Introduction To Google Cloud Big Data Platform: Lecturer: Phd. Tran Minh Quang Data Engineering - Group 12
Introduction To Google Cloud Big Data Platform: Lecturer: Phd. Tran Minh Quang Data Engineering - Group 12
You might also like
- Full Stack FastAPI, React, and MongoDB Build Python Web Applications With The FARM Stack PDFDocument336 pagesFull Stack FastAPI, React, and MongoDB Build Python Web Applications With The FARM Stack PDFGéza Nagy100% (3)
- FREE ALGOs EzOscillatorv.4Document6 pagesFREE ALGOs EzOscillatorv.4AbidNo ratings yet
- Odata Interview QuestionsDocument98 pagesOdata Interview Questions125diptiNo ratings yet
- American National Standard Ansi/Isa: Enterprise-Part 6: Messaging Service ModelDocument66 pagesAmerican National Standard Ansi/Isa: Enterprise-Part 6: Messaging Service Modelamir1077No ratings yet
- Volume 6 - 4th Edition - Chemical Engineering Design (Solutions Manual)Document97 pagesVolume 6 - 4th Edition - Chemical Engineering Design (Solutions Manual)Kieron Ivan M. Gutierrez100% (1)
- Customizing An Open Source Erpnext SystemDocument86 pagesCustomizing An Open Source Erpnext SystemVinod J Prakash100% (2)
- MIT CISRwp416 BNY-Mellon RossSebastianBeath PDFDocument16 pagesMIT CISRwp416 BNY-Mellon RossSebastianBeath PDFAJNo ratings yet
- Oracle Actualtests 1z0-434 v2015-11-05 PDFDocument31 pagesOracle Actualtests 1z0-434 v2015-11-05 PDFdarkfox145No ratings yet
- Coding IntroductionDocument46 pagesCoding Introductionlijiayi2023666No ratings yet
- Idl Features 2. Basics of IDL 3. 1D & 2D Display 4. Fits I/O in Idl 5. Image ProcessingDocument50 pagesIdl Features 2. Basics of IDL 3. 1D & 2D Display 4. Fits I/O in Idl 5. Image ProcessingjulietajujuNo ratings yet
- DAA Unit 4Document24 pagesDAA Unit 4hari karanNo ratings yet
- Gr.2 Miniproject Cse4th CompilerDDocument28 pagesGr.2 Miniproject Cse4th CompilerDSUTANDRA CHATTOPADHYAYNo ratings yet
- AI Lab FileDocument17 pagesAI Lab FileRythmNo ratings yet
- FIT1029: Tutorial 5 Solutions Semester 1, 2014: Activity 1Document6 pagesFIT1029: Tutorial 5 Solutions Semester 1, 2014: Activity 1Ali AlabidNo ratings yet
- Sleek TemplateDocument15 pagesSleek TemplateZERO XNo ratings yet
- Case StudyDocument20 pagesCase StudyShivani SharmaNo ratings yet
- Solr 3.1 and BeyondDocument33 pagesSolr 3.1 and BeyondErvin MillerNo ratings yet
- Maxima by Example2plotfitDocument25 pagesMaxima by Example2plotfitjgbarrNo ratings yet
- If IdentificadorDeMatrizDocument45 pagesIf IdentificadorDeMatrizDaniel MendozaNo ratings yet
- MongoDB Cheat SheetDocument9 pagesMongoDB Cheat SheetÉnomis DouyouNo ratings yet
- Lecture 2 - Intro To SQLDocument55 pagesLecture 2 - Intro To SQLUnknown userNo ratings yet
- Analysis of Algorithms: Abhilash Bhandari Ghanshyam.S.MaluDocument19 pagesAnalysis of Algorithms: Abhilash Bhandari Ghanshyam.S.MaluAndrew OfoeNo ratings yet
- EstadísticaDocument2 pagesEstadísticaJohann Boris DíazNo ratings yet
- Weight Converter (GUI) Using TKinterDocument7 pagesWeight Converter (GUI) Using TKinterAmey shringareNo ratings yet
- Apache Spark TutorialsDocument9 pagesApache Spark Tutorialsronics123No ratings yet
- The "Reduced" Distribution Looks Like For A Particular "Degree of Freedom."Document3 pagesThe "Reduced" Distribution Looks Like For A Particular "Degree of Freedom."Jose Taco Jr.No ratings yet
- Fundamentals of AutoLISPDocument14 pagesFundamentals of AutoLISPVladimir Balzary LapcevicNo ratings yet
- Types Type Table of With KEY Data Type Ref To Create Data NEW NEWDocument11 pagesTypes Type Table of With KEY Data Type Ref To Create Data NEW NEWKishore Babu100% (1)
- Dbms Lab First PagesDocument15 pagesDbms Lab First PagesCʜocoɭʌtƴ ƁoƴNo ratings yet
- Library Management VB Project ReportDocument21 pagesLibrary Management VB Project ReportkapilNo ratings yet
- RintroDocument33 pagesRintroFranco CalleNo ratings yet
- Help For All .Net DeveloperDocument4 pagesHelp For All .Net Developerkhalid.husainNo ratings yet
- Btrees and HeapsDocument35 pagesBtrees and HeapsAbdurezak ShifaNo ratings yet
- Artificial Intelligence Lab FileDocument20 pagesArtificial Intelligence Lab FileYogesh BaranwalNo ratings yet
- Finite Elements Using Flex PdeDocument12 pagesFinite Elements Using Flex PdeJose Rene Salinas CantonNo ratings yet
- The Ring Programming Language Version 1.5.4 Book - Part 25 of 185Document10 pagesThe Ring Programming Language Version 1.5.4 Book - Part 25 of 185Mahmoud Samir FayedNo ratings yet
- G8-HBase 2Document100 pagesG8-HBase 2Nhan NguyenNo ratings yet
- A Lifting of The Dieudonné Determinant and Applications Concerning The Multiplicative Group of A Skew Field Peter DraxlDocument41 pagesA Lifting of The Dieudonné Determinant and Applications Concerning The Multiplicative Group of A Skew Field Peter Draxlnicole.morton395100% (19)
- Graph 1Document4 pagesGraph 1Rakesh M BNo ratings yet
- GraphDocument4 pagesGraphRakesh M BNo ratings yet
- Cs 50Document5 pagesCs 50bobNo ratings yet
- CA ch2 PDFDocument14 pagesCA ch2 PDFdeepak kumarNo ratings yet
- Overriding - CS2030S Programming Methodology IIDocument4 pagesOverriding - CS2030S Programming Methodology IIlukilukiNo ratings yet
- Introduction To MapReduceDocument43 pagesIntroduction To MapReduceAshwin AjmeraNo ratings yet
- 7 Sample - Notebook - With - Code - CellsDocument5 pages7 Sample - Notebook - With - Code - CellsMarisnelvys CabrejaNo ratings yet
- LAB Manual: Course: CSC241-Object Oriented ProgrammingDocument6 pagesLAB Manual: Course: CSC241-Object Oriented Programmingsaif habibNo ratings yet
- A Third Dimension To Rough Sets: Ron Kohavi Computer Science Dept. Stanford University Stanford, CA 94305Document8 pagesA Third Dimension To Rough Sets: Ron Kohavi Computer Science Dept. Stanford University Stanford, CA 94305Jeniffel LugoNo ratings yet
- Mongo DB Documentation-2922'11Document21 pagesMongo DB Documentation-2922'11harshithyv02No ratings yet
- Map Reduce PDFDocument29 pagesMap Reduce PDFMahalakshmi GNo ratings yet
- Lecture Notes Map ReduceDocument24 pagesLecture Notes Map ReduceYuvaraj V, Assistant Professor, BCANo ratings yet
- 10.6 Dictionaries - Jupyter NotebookDocument11 pages10.6 Dictionaries - Jupyter Notebookbharathms525No ratings yet
- Computer Science: Project FileDocument29 pagesComputer Science: Project FileNishit RaiNo ratings yet
- Lecture #4 Komnum - OptimizationDocument49 pagesLecture #4 Komnum - OptimizationNata SunardiNo ratings yet
- RRR Nifty LevelsDocument5 pagesRRR Nifty LevelsRaj GoudNo ratings yet
- MapReduce and HDFSDocument65 pagesMapReduce and HDFSjeremiahteeeNo ratings yet
- Exam Cheatsheet For R Langauge CodingDocument2 pagesExam Cheatsheet For R Langauge CodingamirNo ratings yet
- Chap2. Public Goods and Private GoodsDocument18 pagesChap2. Public Goods and Private GoodsCitio LogosNo ratings yet
- 'Esta Función Ordena Los Datos de Menor A MayorDocument4 pages'Esta Función Ordena Los Datos de Menor A Mayorجوس جوسNo ratings yet
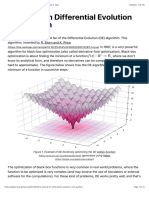
- A Tutorial On Differential Evolution With Python - Pablo R. MierDocument21 pagesA Tutorial On Differential Evolution With Python - Pablo R. MierNeel GhoshNo ratings yet
- SQL Labrecord Questions 16to20Document5 pagesSQL Labrecord Questions 16to20kentNo ratings yet
- Running OkDocument2 pagesRunning OkVitthal DevakateNo ratings yet
- ABAP 7.4 SyntaxDocument18 pagesABAP 7.4 Syntaxjavier_petit5No ratings yet
- Conexión: Imports ImportsDocument4 pagesConexión: Imports ImportsJOSENo ratings yet
- The Ring Programming Language Version 1.6 Book - Part 16 of 189Document10 pagesThe Ring Programming Language Version 1.6 Book - Part 16 of 189Mahmoud Samir FayedNo ratings yet
- IVeri WebAPI Developers GuideDocument18 pagesIVeri WebAPI Developers GuidedefamaNo ratings yet
- Consuming REST Web Service (With Parameters) In..Document4 pagesConsuming REST Web Service (With Parameters) In..Pallavi KoppulaNo ratings yet
- Release NotesDocument28 pagesRelease NotesKanchan ChakrabortyNo ratings yet
- SDADocument37 pagesSDAMuhammad Ammar ZahidNo ratings yet
- Shobhit Jain: Thapar Institute of Engineering and TechnologyDocument2 pagesShobhit Jain: Thapar Institute of Engineering and TechnologyKunal NagNo ratings yet
- MarkCarlson Cloud Data Management CDMI PDFDocument29 pagesMarkCarlson Cloud Data Management CDMI PDFSNEHA RAMKRISHNA HAWALDARNo ratings yet
- CE303 Lecture 5Document43 pagesCE303 Lecture 5bob.rice04No ratings yet
- HeavyDocument293 pagesHeavyPower BangNo ratings yet
- Blexr - Full Stack Engineer (React - Next.Node) - 1Document4 pagesBlexr - Full Stack Engineer (React - Next.Node) - 1Josep VidalNo ratings yet
- MDM 1010 BusinessEntityServicesGuide enDocument111 pagesMDM 1010 BusinessEntityServicesGuide enluctor@gmail.comNo ratings yet
- Baba Borra Java ResumeDocument5 pagesBaba Borra Java ResumeChandra Babu NookalaNo ratings yet
- Multi Protocol Gateway Developers GuideDocument416 pagesMulti Protocol Gateway Developers Guidenaveen25417313No ratings yet
- System Design Interview Prep Master Doc: Compiled by - Pooja BiswasDocument24 pagesSystem Design Interview Prep Master Doc: Compiled by - Pooja BiswasAlekhNo ratings yet
- Resume CK LatestDocument2 pagesResume CK LatestSales TeamNo ratings yet
- Syllabus Java Full StackDocument10 pagesSyllabus Java Full StackranjnenduNo ratings yet
- Sandeep Sunchu ResumeDocument2 pagesSandeep Sunchu Resumeapi-302956565No ratings yet
- WSN 41 2016 1 3159Document316 pagesWSN 41 2016 1 3159ProgyNo ratings yet
- The Difference Between API Gateways and Service MeshDocument26 pagesThe Difference Between API Gateways and Service MeshchmorenorNo ratings yet
- RESTFul Aras APIs Testing With PostmanDocument7 pagesRESTFul Aras APIs Testing With PostmanHernan GiagnorioNo ratings yet
- Nikhil Java ResumeDocument5 pagesNikhil Java ResumeVenkatNo ratings yet
- Sample Cracking Microservices InterviewsDocument32 pagesSample Cracking Microservices InterviewsSuhas SettyNo ratings yet
- Sessions 2Document82 pagesSessions 2Murali JillellamudiNo ratings yet
- TeamViewer API DocumentationDocument60 pagesTeamViewer API DocumentationReza Irsyadul AnamNo ratings yet
- ForceLearn Interview QuestionsDocument33 pagesForceLearn Interview Questionsphani1259No ratings yet
























































































Download as pdf or txt
You might also like
- Full Stack FastAPI, React, and MongoDB Build Python Web Applications With The FARM Stack PDFDocument336 pagesFull Stack FastAPI, React, and MongoDB Build Python Web Applications With The FARM Stack PDFGéza Nagy100% (3)
- FREE ALGOs EzOscillatorv.4Document6 pagesFREE ALGOs EzOscillatorv.4AbidNo ratings yet
- Odata Interview QuestionsDocument98 pagesOdata Interview Questions125diptiNo ratings yet
- American National Standard Ansi/Isa: Enterprise-Part 6: Messaging Service ModelDocument66 pagesAmerican National Standard Ansi/Isa: Enterprise-Part 6: Messaging Service Modelamir1077No ratings yet
- Volume 6 - 4th Edition - Chemical Engineering Design (Solutions Manual)Document97 pagesVolume 6 - 4th Edition - Chemical Engineering Design (Solutions Manual)Kieron Ivan M. Gutierrez100% (1)
- Customizing An Open Source Erpnext SystemDocument86 pagesCustomizing An Open Source Erpnext SystemVinod J Prakash100% (2)
- MIT CISRwp416 BNY-Mellon RossSebastianBeath PDFDocument16 pagesMIT CISRwp416 BNY-Mellon RossSebastianBeath PDFAJNo ratings yet
- Oracle Actualtests 1z0-434 v2015-11-05 PDFDocument31 pagesOracle Actualtests 1z0-434 v2015-11-05 PDFdarkfox145No ratings yet
- Coding IntroductionDocument46 pagesCoding Introductionlijiayi2023666No ratings yet
- Idl Features 2. Basics of IDL 3. 1D & 2D Display 4. Fits I/O in Idl 5. Image ProcessingDocument50 pagesIdl Features 2. Basics of IDL 3. 1D & 2D Display 4. Fits I/O in Idl 5. Image ProcessingjulietajujuNo ratings yet
- DAA Unit 4Document24 pagesDAA Unit 4hari karanNo ratings yet
- Gr.2 Miniproject Cse4th CompilerDDocument28 pagesGr.2 Miniproject Cse4th CompilerDSUTANDRA CHATTOPADHYAYNo ratings yet
- AI Lab FileDocument17 pagesAI Lab FileRythmNo ratings yet
- FIT1029: Tutorial 5 Solutions Semester 1, 2014: Activity 1Document6 pagesFIT1029: Tutorial 5 Solutions Semester 1, 2014: Activity 1Ali AlabidNo ratings yet
- Sleek TemplateDocument15 pagesSleek TemplateZERO XNo ratings yet
- Case StudyDocument20 pagesCase StudyShivani SharmaNo ratings yet
- Solr 3.1 and BeyondDocument33 pagesSolr 3.1 and BeyondErvin MillerNo ratings yet
- Maxima by Example2plotfitDocument25 pagesMaxima by Example2plotfitjgbarrNo ratings yet
- If IdentificadorDeMatrizDocument45 pagesIf IdentificadorDeMatrizDaniel MendozaNo ratings yet
- MongoDB Cheat SheetDocument9 pagesMongoDB Cheat SheetÉnomis DouyouNo ratings yet
- Lecture 2 - Intro To SQLDocument55 pagesLecture 2 - Intro To SQLUnknown userNo ratings yet
- Analysis of Algorithms: Abhilash Bhandari Ghanshyam.S.MaluDocument19 pagesAnalysis of Algorithms: Abhilash Bhandari Ghanshyam.S.MaluAndrew OfoeNo ratings yet
- EstadísticaDocument2 pagesEstadísticaJohann Boris DíazNo ratings yet
- Weight Converter (GUI) Using TKinterDocument7 pagesWeight Converter (GUI) Using TKinterAmey shringareNo ratings yet
- Apache Spark TutorialsDocument9 pagesApache Spark Tutorialsronics123No ratings yet
- The "Reduced" Distribution Looks Like For A Particular "Degree of Freedom."Document3 pagesThe "Reduced" Distribution Looks Like For A Particular "Degree of Freedom."Jose Taco Jr.No ratings yet
- Fundamentals of AutoLISPDocument14 pagesFundamentals of AutoLISPVladimir Balzary LapcevicNo ratings yet
- Types Type Table of With KEY Data Type Ref To Create Data NEW NEWDocument11 pagesTypes Type Table of With KEY Data Type Ref To Create Data NEW NEWKishore Babu100% (1)
- Dbms Lab First PagesDocument15 pagesDbms Lab First PagesCʜocoɭʌtƴ ƁoƴNo ratings yet
- Library Management VB Project ReportDocument21 pagesLibrary Management VB Project ReportkapilNo ratings yet
- RintroDocument33 pagesRintroFranco CalleNo ratings yet
- Help For All .Net DeveloperDocument4 pagesHelp For All .Net Developerkhalid.husainNo ratings yet
- Btrees and HeapsDocument35 pagesBtrees and HeapsAbdurezak ShifaNo ratings yet
- Artificial Intelligence Lab FileDocument20 pagesArtificial Intelligence Lab FileYogesh BaranwalNo ratings yet
- Finite Elements Using Flex PdeDocument12 pagesFinite Elements Using Flex PdeJose Rene Salinas CantonNo ratings yet
- The Ring Programming Language Version 1.5.4 Book - Part 25 of 185Document10 pagesThe Ring Programming Language Version 1.5.4 Book - Part 25 of 185Mahmoud Samir FayedNo ratings yet
- G8-HBase 2Document100 pagesG8-HBase 2Nhan NguyenNo ratings yet
- A Lifting of The Dieudonné Determinant and Applications Concerning The Multiplicative Group of A Skew Field Peter DraxlDocument41 pagesA Lifting of The Dieudonné Determinant and Applications Concerning The Multiplicative Group of A Skew Field Peter Draxlnicole.morton395100% (19)
- Graph 1Document4 pagesGraph 1Rakesh M BNo ratings yet
- GraphDocument4 pagesGraphRakesh M BNo ratings yet
- Cs 50Document5 pagesCs 50bobNo ratings yet
- CA ch2 PDFDocument14 pagesCA ch2 PDFdeepak kumarNo ratings yet
- Overriding - CS2030S Programming Methodology IIDocument4 pagesOverriding - CS2030S Programming Methodology IIlukilukiNo ratings yet
- Introduction To MapReduceDocument43 pagesIntroduction To MapReduceAshwin AjmeraNo ratings yet
- 7 Sample - Notebook - With - Code - CellsDocument5 pages7 Sample - Notebook - With - Code - CellsMarisnelvys CabrejaNo ratings yet
- LAB Manual: Course: CSC241-Object Oriented ProgrammingDocument6 pagesLAB Manual: Course: CSC241-Object Oriented Programmingsaif habibNo ratings yet
- A Third Dimension To Rough Sets: Ron Kohavi Computer Science Dept. Stanford University Stanford, CA 94305Document8 pagesA Third Dimension To Rough Sets: Ron Kohavi Computer Science Dept. Stanford University Stanford, CA 94305Jeniffel LugoNo ratings yet
- Mongo DB Documentation-2922'11Document21 pagesMongo DB Documentation-2922'11harshithyv02No ratings yet
- Map Reduce PDFDocument29 pagesMap Reduce PDFMahalakshmi GNo ratings yet
- Lecture Notes Map ReduceDocument24 pagesLecture Notes Map ReduceYuvaraj V, Assistant Professor, BCANo ratings yet
- 10.6 Dictionaries - Jupyter NotebookDocument11 pages10.6 Dictionaries - Jupyter Notebookbharathms525No ratings yet
- Computer Science: Project FileDocument29 pagesComputer Science: Project FileNishit RaiNo ratings yet
- Lecture #4 Komnum - OptimizationDocument49 pagesLecture #4 Komnum - OptimizationNata SunardiNo ratings yet
- RRR Nifty LevelsDocument5 pagesRRR Nifty LevelsRaj GoudNo ratings yet
- MapReduce and HDFSDocument65 pagesMapReduce and HDFSjeremiahteeeNo ratings yet
- Exam Cheatsheet For R Langauge CodingDocument2 pagesExam Cheatsheet For R Langauge CodingamirNo ratings yet
- Chap2. Public Goods and Private GoodsDocument18 pagesChap2. Public Goods and Private GoodsCitio LogosNo ratings yet
- 'Esta Función Ordena Los Datos de Menor A MayorDocument4 pages'Esta Función Ordena Los Datos de Menor A Mayorجوس جوسNo ratings yet
- A Tutorial On Differential Evolution With Python - Pablo R. MierDocument21 pagesA Tutorial On Differential Evolution With Python - Pablo R. MierNeel GhoshNo ratings yet
- SQL Labrecord Questions 16to20Document5 pagesSQL Labrecord Questions 16to20kentNo ratings yet
- Running OkDocument2 pagesRunning OkVitthal DevakateNo ratings yet
- ABAP 7.4 SyntaxDocument18 pagesABAP 7.4 Syntaxjavier_petit5No ratings yet
- Conexión: Imports ImportsDocument4 pagesConexión: Imports ImportsJOSENo ratings yet
- The Ring Programming Language Version 1.6 Book - Part 16 of 189Document10 pagesThe Ring Programming Language Version 1.6 Book - Part 16 of 189Mahmoud Samir FayedNo ratings yet
- IVeri WebAPI Developers GuideDocument18 pagesIVeri WebAPI Developers GuidedefamaNo ratings yet
- Consuming REST Web Service (With Parameters) In..Document4 pagesConsuming REST Web Service (With Parameters) In..Pallavi KoppulaNo ratings yet
- Release NotesDocument28 pagesRelease NotesKanchan ChakrabortyNo ratings yet
- SDADocument37 pagesSDAMuhammad Ammar ZahidNo ratings yet
- Shobhit Jain: Thapar Institute of Engineering and TechnologyDocument2 pagesShobhit Jain: Thapar Institute of Engineering and TechnologyKunal NagNo ratings yet
- MarkCarlson Cloud Data Management CDMI PDFDocument29 pagesMarkCarlson Cloud Data Management CDMI PDFSNEHA RAMKRISHNA HAWALDARNo ratings yet
- CE303 Lecture 5Document43 pagesCE303 Lecture 5bob.rice04No ratings yet
- HeavyDocument293 pagesHeavyPower BangNo ratings yet
- Blexr - Full Stack Engineer (React - Next.Node) - 1Document4 pagesBlexr - Full Stack Engineer (React - Next.Node) - 1Josep VidalNo ratings yet
- MDM 1010 BusinessEntityServicesGuide enDocument111 pagesMDM 1010 BusinessEntityServicesGuide enluctor@gmail.comNo ratings yet
- Baba Borra Java ResumeDocument5 pagesBaba Borra Java ResumeChandra Babu NookalaNo ratings yet
- Multi Protocol Gateway Developers GuideDocument416 pagesMulti Protocol Gateway Developers Guidenaveen25417313No ratings yet
- System Design Interview Prep Master Doc: Compiled by - Pooja BiswasDocument24 pagesSystem Design Interview Prep Master Doc: Compiled by - Pooja BiswasAlekhNo ratings yet
- Resume CK LatestDocument2 pagesResume CK LatestSales TeamNo ratings yet
- Syllabus Java Full StackDocument10 pagesSyllabus Java Full StackranjnenduNo ratings yet
- Sandeep Sunchu ResumeDocument2 pagesSandeep Sunchu Resumeapi-302956565No ratings yet
- WSN 41 2016 1 3159Document316 pagesWSN 41 2016 1 3159ProgyNo ratings yet
- The Difference Between API Gateways and Service MeshDocument26 pagesThe Difference Between API Gateways and Service MeshchmorenorNo ratings yet
- RESTFul Aras APIs Testing With PostmanDocument7 pagesRESTFul Aras APIs Testing With PostmanHernan GiagnorioNo ratings yet
- Nikhil Java ResumeDocument5 pagesNikhil Java ResumeVenkatNo ratings yet
- Sample Cracking Microservices InterviewsDocument32 pagesSample Cracking Microservices InterviewsSuhas SettyNo ratings yet
- Sessions 2Document82 pagesSessions 2Murali JillellamudiNo ratings yet
- TeamViewer API DocumentationDocument60 pagesTeamViewer API DocumentationReza Irsyadul AnamNo ratings yet
- ForceLearn Interview QuestionsDocument33 pagesForceLearn Interview Questionsphani1259No ratings yet