Download as pdf or txt
You might also like
- Dynamic ProgrammingDocument3,020 pagesDynamic ProgrammingTarun Dhamor0% (1)
- The Original Area Mazes, Volume 2: 100 More Addictive Puzzles to Solve with Simple Math—and Clever Logic!From EverandThe Original Area Mazes, Volume 2: 100 More Addictive Puzzles to Solve with Simple Math—and Clever Logic!No ratings yet
- 44 Dynamic ProgrammingDocument20 pages44 Dynamic ProgrammingTushar ChauhanNo ratings yet
- 44 Dynamic ProgrammingDocument20 pages44 Dynamic Programmingrosev15No ratings yet
- 44 Dynamic ProgrammingDocument20 pages44 Dynamic ProgrammingErika AlmeidaNo ratings yet
- Dynamic ProgrammingDocument69 pagesDynamic ProgrammingZeseya SharminNo ratings yet
- DynamicProgramming NotesDocument13 pagesDynamicProgramming Notesps1406051No ratings yet
- Optimization: Dynamic ProgrammingDocument49 pagesOptimization: Dynamic ProgrammingMatthewNo ratings yet
- C 10 GreedyDocument16 pagesC 10 GreedySasi.b. KumarNo ratings yet
- NumberTheory Complete PDFDocument23 pagesNumberTheory Complete PDFArka SenguptaNo ratings yet
- NumberTheory Complete PDFDocument23 pagesNumberTheory Complete PDFMaria Cleofa CatuizaNo ratings yet
- NP-Complete Problems: Khaled W. MahmoudDocument35 pagesNP-Complete Problems: Khaled W. MahmoudRAGHAD ALSHDIFATNo ratings yet
- Greedy AlgorithmsDocument39 pagesGreedy AlgorithmsHarsh SoniNo ratings yet
- Dynamic Programming: We'd Like To Have "Generic" Algorithmic Paradigms For Solving ProblemsDocument9 pagesDynamic Programming: We'd Like To Have "Generic" Algorithmic Paradigms For Solving Problemskamalesh123No ratings yet
- Theory of Numbers - Lecture 6Document3 pagesTheory of Numbers - Lecture 6ANDHIKA NUGROHONo ratings yet
- Topic 2 Lecture NotesDocument36 pagesTopic 2 Lecture NoteskellyNo ratings yet
- Unit-4 (Dynamic Programming)Document96 pagesUnit-4 (Dynamic Programming)HACKER SPACENo ratings yet
- Practice Final COMP251 With Answers W2017Document5 pagesPractice Final COMP251 With Answers W2017AVIRAL PRATAP SINGH CHAWDANo ratings yet
- Prime and Composite Numbers: 10.1. Counting DivisorsDocument3 pagesPrime and Composite Numbers: 10.1. Counting DivisorscacaNo ratings yet
- Winter Camp 2009 Number Theory Tips and Tricks: David ArthurDocument8 pagesWinter Camp 2009 Number Theory Tips and Tricks: David ArthurAlldica BezeloNo ratings yet
- L9 Greedy Algorithms IntroductionDocument19 pagesL9 Greedy Algorithms IntroductionShivansh RagNo ratings yet
- Dynamic ProgrammingDocument35 pagesDynamic ProgrammingMuhammad JunaidNo ratings yet
- Greedy AlgorithmDocument11 pagesGreedy AlgorithmAsish PatraNo ratings yet
- Chapter-3: Prime NumbersDocument18 pagesChapter-3: Prime NumbersAhamed ZubairNo ratings yet
- 15.053 Thursday, May 3: Cutting Plane Techniques For Getting Improved BoundsDocument46 pages15.053 Thursday, May 3: Cutting Plane Techniques For Getting Improved BoundsEhsan SpencerNo ratings yet
- Comp106 NumbertheoryDocument99 pagesComp106 NumbertheoryAOne ThreeONineNo ratings yet
- DAA Lecture 3Document28 pagesDAA Lecture 3AqsaNo ratings yet
- Greedy AlgosDocument102 pagesGreedy AlgosHafeezNo ratings yet
- 4 - Divide-and-Conquer AlgorithmsDocument15 pages4 - Divide-and-Conquer AlgorithmsOrhan KaplanNo ratings yet
- MTH SlidesDocument116 pagesMTH Slidesshank5No ratings yet
- D&C MergesortDocument34 pagesD&C Mergesorttera baapNo ratings yet
- Lecture 6Document18 pagesLecture 6Mstafa MhamadNo ratings yet
- Equations. For Example, 3x - 1 5 and 3x 6 Are EquivalentDocument13 pagesEquations. For Example, 3x - 1 5 and 3x 6 Are EquivalenttehyuanyingNo ratings yet
- GreedyDocument12 pagesGreedyHusnain MahmoodNo ratings yet
- CSC 344 - Algorithms and ComplexityDocument37 pagesCSC 344 - Algorithms and ComplexityArvin HipolitoNo ratings yet
- Algo Lec7Document73 pagesAlgo Lec7ahmedtarek86519623No ratings yet
- Limit (Lec # 6)Document42 pagesLimit (Lec # 6)Hamid RajpootNo ratings yet
- 27-Greedy 2Document19 pages27-Greedy 2Hira AftabNo ratings yet
- Chapter 4 - NotesDocument13 pagesChapter 4 - NotesHussain ShafiqueNo ratings yet
- Mathematical Induction (Discrete Math)Document41 pagesMathematical Induction (Discrete Math)api-33642484No ratings yet
- Topic 1 2324 Am015 StudentDocument48 pagesTopic 1 2324 Am015 StudentAARON HANTON A/L ANTHONY EDWARD MoeNo ratings yet
- Trigonometry - AoPS PrecalcDocument4 pagesTrigonometry - AoPS PrecalcMichael Zhao100% (1)
- Algorithms - Lecture 5 (Dynamic Programming 1)Document47 pagesAlgorithms - Lecture 5 (Dynamic Programming 1)nagui.mostafaNo ratings yet
- Crypto Maths - Part 1Document21 pagesCrypto Maths - Part 1abhishek reddyNo ratings yet
- ARML 2003-2004 Number TheoryDocument4 pagesARML 2003-2004 Number TheoryCris DeVid GamerNo ratings yet
- Lect - 04 ch04Document41 pagesLect - 04 ch04Amro AbosaifNo ratings yet
- MCS 031Document15 pagesMCS 031Bageesh M BoseNo ratings yet
- Ch03i3341 AlgoDesign2 Greedy enDocument39 pagesCh03i3341 AlgoDesign2 Greedy enElias KhouryNo ratings yet
- C4 Simplex MethodDocument65 pagesC4 Simplex MethodĐăng TranNo ratings yet
- 2020 Square Free Fermat Numbers - ProofDocument5 pages2020 Square Free Fermat Numbers - ProofastenNo ratings yet
- Chapter17 - Dynamic Programming PDFDocument3 pagesChapter17 - Dynamic Programming PDFVinicius TorresNo ratings yet
- Lecture 5bis - Divide and ConquerDocument20 pagesLecture 5bis - Divide and Conquerhao05500550No ratings yet
- Review of Number System ZDocument22 pagesReview of Number System ZDev KumarNo ratings yet
- Euclidean Algorithm: by Prof. Dr. Safaa AminDocument40 pagesEuclidean Algorithm: by Prof. Dr. Safaa Aminyoussef safeyNo ratings yet
- GM Week2 Day2Document5 pagesGM Week2 Day2Good vouNo ratings yet
- CSE 221 - Lec04 - DP2 - F23Document67 pagesCSE 221 - Lec04 - DP2 - F23Mohammed ZaitounNo ratings yet
- Chapter ThreeDocument43 pagesChapter Threehagosabate9No ratings yet
- Chapter 03Document31 pagesChapter 03aaamouNo ratings yet
- Dynamic Programming: 17.1. The Coin Changing ProblemDocument3 pagesDynamic Programming: 17.1. The Coin Changing ProblemcacaNo ratings yet
- Union Find SetsDocument28 pagesUnion Find SetsHarsh SoniNo ratings yet
- Fibonacci HeapDocument65 pagesFibonacci HeapHarsh SoniNo ratings yet
- Greedy AlgorithmsDocument39 pagesGreedy AlgorithmsHarsh SoniNo ratings yet
- Dynamic Order StatisticsDocument22 pagesDynamic Order StatisticsHarsh SoniNo ratings yet
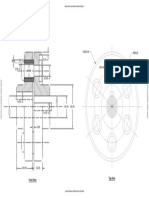
- Name - Rishi Harsh Soni Roll No. - 1801774: Front View Top ViewDocument1 pageName - Rishi Harsh Soni Roll No. - 1801774: Front View Top ViewHarsh SoniNo ratings yet
- EEM 201 - Computer Concepts and C Programming and C ProgrammingDocument97 pagesEEM 201 - Computer Concepts and C Programming and C ProgrammingHarsh SoniNo ratings yet
- Defence DFG Analysis 2019-20Document8 pagesDefence DFG Analysis 2019-20Harsh SoniNo ratings yet
- Design and Analysis of AlgotihmsDocument8 pagesDesign and Analysis of AlgotihmsBONALA HEMANTH KUMAR CSE-J-2020 BATCHNo ratings yet
- 6 DPDocument119 pages6 DPRyan DolmNo ratings yet
- Intro To Dynamic ProgrammingDocument7 pagesIntro To Dynamic ProgrammingUtkarsh PatelNo ratings yet
- ADA Previous Year PapersDocument12 pagesADA Previous Year PaperspiloxaNo ratings yet
- Dynamic ProgrammingDocument50 pagesDynamic ProgrammingAkash RaviNo ratings yet
- Acpc 2013Document19 pagesAcpc 2013Moncef MhasniNo ratings yet
- Data Structures and Algorithms Problems Techie Delight PDFDocument21 pagesData Structures and Algorithms Problems Techie Delight PDFCheer You upNo ratings yet
- A Comprehensive Dialect Conversion Approach From Chittagonian To Standard BanglaDocument5 pagesA Comprehensive Dialect Conversion Approach From Chittagonian To Standard BanglaZaima Sartaj TaheriNo ratings yet
- CS 332: AlgorithmsDocument21 pagesCS 332: AlgorithmsDevin JeffreyNo ratings yet
- Solutions Practice Set DP GreedyDocument6 pagesSolutions Practice Set DP GreedyNancy QNo ratings yet
- Dynamic Programming Questions PDFDocument10 pagesDynamic Programming Questions PDFSaurav AgarwalNo ratings yet
- Striver's CP List (Solely For Preparing For Coding Rounds of Top Prod Based Companies and To Do Well in Coding Sites and Competitions)Document30 pagesStriver's CP List (Solely For Preparing For Coding Rounds of Top Prod Based Companies and To Do Well in Coding Sites and Competitions)Harsh AgrawalNo ratings yet
- Sem 4 AoADocument90 pagesSem 4 AoAGayatri JethaniNo ratings yet
- CSE408 Longest Common Sub Sequence: Lecture # 25Document31 pagesCSE408 Longest Common Sub Sequence: Lecture # 25avinashNo ratings yet
- f22 hw2 SolDocument9 pagesf22 hw2 SolPeter RosenbergNo ratings yet
- Dynamic ProgrammingDocument424 pagesDynamic ProgrammingAsafAhmad100% (3)
- Vol2 Endc PDFDocument272 pagesVol2 Endc PDFMajjari vijayaRaghavaNo ratings yet
- Brute Force Approach in AlgotihmDocument10 pagesBrute Force Approach in AlgotihmAswin T KNo ratings yet
- Dynamic ProgrammingDocument36 pagesDynamic Programmingfatma-taherNo ratings yet
- Algoritm Design - Curs UT ClujDocument16 pagesAlgoritm Design - Curs UT Clujionutz_67No ratings yet
- FINAL450.xlsx - Sheet1Document13 pagesFINAL450.xlsx - Sheet1Prashantcool1999No ratings yet
- Longest Common Subsequence Using Dynamic Programming: Submitted By: Submitted ToDocument30 pagesLongest Common Subsequence Using Dynamic Programming: Submitted By: Submitted ToRabin ShresthaNo ratings yet
- An Analysis On Three Influential DNA Sequencing AlgorithmsDocument8 pagesAn Analysis On Three Influential DNA Sequencing AlgorithmsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- ROUGE Working Note v1.3.1Document6 pagesROUGE Working Note v1.3.1Chu Gia KhôiNo ratings yet
- Data Preprocessing of Esport Game Records - Counter-Strike: Global OffensiveDocument9 pagesData Preprocessing of Esport Game Records - Counter-Strike: Global OffensiveWarner LlaveNo ratings yet
- Algorithm Report PDFDocument6 pagesAlgorithm Report PDFWaleed KhanNo ratings yet
- Unit Iii Greedy and Dynamic ProgrammingDocument120 pagesUnit Iii Greedy and Dynamic ProgrammingAnkit SinghNo ratings yet