Download as pdf or txt
You might also like
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVZohaib Imam88% (16)
- Bike Sharing AssignmentDocument7 pagesBike Sharing Assignmentmudassar shaik100% (6)
- Automatic Control Systems Solutions ManualDocument11 pagesAutomatic Control Systems Solutions ManualSmijeet KurupNo ratings yet
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- Yarn EvennessDocument30 pagesYarn EvennessMd Ahasan HabibNo ratings yet
- Creation of A Wealth Index - 1Document26 pagesCreation of A Wealth Index - 1Gemechu NegesaNo ratings yet
- Data Analytics Homework 1-3Document34 pagesData Analytics Homework 1-3ArtisTaylorNo ratings yet
- ReportDocument12 pagesReportNishant Kumar BakshiNo ratings yet
- PredictionDocument10 pagesPredictionendriasmit_469556062100% (1)
- Bmjopen 2019 July 9 7 Inline Supplementary Material 1Document7 pagesBmjopen 2019 July 9 7 Inline Supplementary Material 1Gemechu NegesaNo ratings yet
- English (US) Home Community Submit A Request: Help Center Sign inDocument14 pagesEnglish (US) Home Community Submit A Request: Help Center Sign inAkram Abbas KhalafNo ratings yet
- LN Formation Representation: 2.1. Integer Number SystemsDocument37 pagesLN Formation Representation: 2.1. Integer Number SystemsBlazsNo ratings yet
- Lab 7 Spatial Selection APDocument13 pagesLab 7 Spatial Selection APacwriters123No ratings yet
- Techniques To Replace or Supplement Breaks: Deborah L. LenningtonDocument13 pagesTechniques To Replace or Supplement Breaks: Deborah L. Lenningtonjanardhan_sapboNo ratings yet
- My JMP Steps Document For FA Dec 3, 2023Document5 pagesMy JMP Steps Document For FA Dec 3, 202399.nawzirxNo ratings yet
- Assignment AI-MLDocument13 pagesAssignment AI-MLShelly SharmaNo ratings yet
- l8 SpatialselectmoretablesarcproDocument13 pagesl8 SpatialselectmoretablesarcproNabaraj NegiNo ratings yet
- A257-1 2023Document4 pagesA257-1 2023Emma ChenNo ratings yet
- 116 - Monte Carlo With Data TablesDocument704 pages116 - Monte Carlo With Data TablesMarcelo BuchNo ratings yet
- Step 4: Exploring Data: 6.1 A First Glimpse at The DataDocument17 pagesStep 4: Exploring Data: 6.1 A First Glimpse at The DatadanielNo ratings yet
- Step 4 Exploring DataDocument17 pagesStep 4 Exploring DataMR MinayaNo ratings yet
- An Analytical Detective - Week 1 Assignment - 15Document16 pagesAn Analytical Detective - Week 1 Assignment - 15Charu Mall100% (1)
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Data Analysis For Accountants Assessment 2Document13 pagesData Analysis For Accountants Assessment 2gatunemosesNo ratings yet
- Analyze Descriptive Statistics Frequencies: SPSS PC Version 10: Frequency Distributions and CrosstabsDocument3 pagesAnalyze Descriptive Statistics Frequencies: SPSS PC Version 10: Frequency Distributions and CrosstabsSalman ButtNo ratings yet
- Principal Component AnalysisDocument4 pagesPrincipal Component AnalysisDeepak PadiyarNo ratings yet
- Paper Final SentDocument20 pagesPaper Final SentdkiaryNo ratings yet
- Data Analysis Notes 25 - 11Document5 pagesData Analysis Notes 25 - 11Ghabri FidaNo ratings yet
- A Financial Modelling Supplementary Questions1Document10 pagesA Financial Modelling Supplementary Questions1VarunNo ratings yet
- AsadDocument140 pagesAsadHaseeb Malik100% (1)
- Local Spatial Autocorrelation - Geographic Data Science With PythonDocument24 pagesLocal Spatial Autocorrelation - Geographic Data Science With PythonВильсон ЛевNo ratings yet
- Machine Learning Project - Predicting Boston House Prices With Regression - by Victor Roman - Towards Data ScienceDocument20 pagesMachine Learning Project - Predicting Boston House Prices With Regression - by Victor Roman - Towards Data ScienceGhifari RakaNo ratings yet
- Determining The Rate Law of A Reaction Using The TI-83Plus Graphing CalculatorDocument4 pagesDetermining The Rate Law of A Reaction Using The TI-83Plus Graphing Calculatoranand singhNo ratings yet
- Remote Sensing AssignmentDocument10 pagesRemote Sensing AssignmentKio MeowNo ratings yet
- Principal Component AnalysisDocument9 pagesPrincipal Component AnalysisGeethakshaya100% (1)
- Chapter IDocument41 pagesChapter Ihien05No ratings yet
- Chapter 20 Modul DSSDocument20 pagesChapter 20 Modul DSSVici Syahril ChairaniNo ratings yet
- FRA Milestone 1Document33 pagesFRA Milestone 1Nitya BalakrishnanNo ratings yet
- Chapter 6: Summarizing DataDocument5 pagesChapter 6: Summarizing DataDessiren De GuzmanNo ratings yet
- Using R For Basic Statistical AnalysisDocument11 pagesUsing R For Basic Statistical AnalysisNile SethNo ratings yet
- Ch4 PTUDTTDocument102 pagesCh4 PTUDTTtrandinhloi99No ratings yet
- CH 6Document38 pagesCH 6Gulleds IbrahimNo ratings yet
- Great Learning DATA MINING PROJECTDocument15 pagesGreat Learning DATA MINING PROJECTrameshj16708No ratings yet
- Dsa AlgorithmsDocument6 pagesDsa AlgorithmsElevator EducationNo ratings yet
- Chapter 1Document24 pagesChapter 1fikrutafesse08No ratings yet
- Curve FittingDocument18 pagesCurve FittingManoj ThapaNo ratings yet
- Practical Guide To Principal Component N RDocument43 pagesPractical Guide To Principal Component N RJuan Esteban Perez CardozoNo ratings yet
- Principal Component AnalysisDocument13 pagesPrincipal Component AnalysisShil ShambharkarNo ratings yet
- Eviews6a KartsDocument3 pagesEviews6a Kartssarvary117No ratings yet
- Graded ProjectDocument36 pagesGraded ProjectUmendra Pratap Singh SolankiNo ratings yet
- Aggregation Can Be of The Following TypeDocument3 pagesAggregation Can Be of The Following TypeAbhilasha ModekarNo ratings yet
- Rahulsharma - 03 12 23Document26 pagesRahulsharma - 03 12 23Rahul GautamNo ratings yet
- 11.1 Introduction To State Machines: Chapter ElevenDocument24 pages11.1 Introduction To State Machines: Chapter ElevenReham MuzzamilNo ratings yet
- Pca TutorialDocument11 pagesPca TutorialpreethihpNo ratings yet
- Lec11 12Document35 pagesLec11 12zaforNo ratings yet
- Dimension ReductionDocument78 pagesDimension ReductionGuneetNo ratings yet
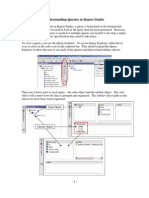
- Understanding Queries in Report StudioDocument4 pagesUnderstanding Queries in Report StudioRanjith JosephNo ratings yet
- 5EC3-01: Computer Architecture: UNIT-2Document17 pages5EC3-01: Computer Architecture: UNIT-2Himanshi SainiNo ratings yet
- CH 1Document28 pagesCH 1zinabuhaddis21No ratings yet
- Append Merge CollapseDocument16 pagesAppend Merge Collapserafael.sebastianNo ratings yet
- Health Insurance Determines Antenatal, Delivery and Postnatal Care Utilisation: Evidence From The Ghana Demographic and Health Surveillance DataDocument6 pagesHealth Insurance Determines Antenatal, Delivery and Postnatal Care Utilisation: Evidence From The Ghana Demographic and Health Surveillance DataGemechu NegesaNo ratings yet
- Community-Based Health Insurance and Healthcare Service Utilisation, North-West, Ethiopia: A Comparative, Cross - Sectional StudyDocument6 pagesCommunity-Based Health Insurance and Healthcare Service Utilisation, North-West, Ethiopia: A Comparative, Cross - Sectional StudyGemechu NegesaNo ratings yet
- Catastrophic Health Expenditure: A Comparative Analysis of Empty-Nest and Non-Empty-Nest Households With Seniors in Shandong, ChinaDocument8 pagesCatastrophic Health Expenditure: A Comparative Analysis of Empty-Nest and Non-Empty-Nest Households With Seniors in Shandong, ChinaGemechu NegesaNo ratings yet
- Emerging Themes inDocument14 pagesEmerging Themes inGemechu NegesaNo ratings yet
- WFP 0000107668Document31 pagesWFP 0000107668Gemechu NegesaNo ratings yet
- Bmjopen 2019 July 9 7 Inline Supplementary Material 1Document7 pagesBmjopen 2019 July 9 7 Inline Supplementary Material 1Gemechu NegesaNo ratings yet
- Sumitomo Chemical Alumina (ENG)Document16 pagesSumitomo Chemical Alumina (ENG)Lawrence LauNo ratings yet
- Test Erm T The Second:: MarkDocument2 pagesTest Erm T The Second:: Markkaimero changNo ratings yet
- Qday7: CastorDocument1 pageQday7: CastorLiteratura esotericaNo ratings yet
- Graduation ProjectredaDocument36 pagesGraduation ProjectredaRuchit JainNo ratings yet
- GEP 2 Speaking (Sep 2021 Updated)Document2 pagesGEP 2 Speaking (Sep 2021 Updated)Nguyễn HoàngNo ratings yet
- QTMS Final Assessment (Spring 2020) PDFDocument6 pagesQTMS Final Assessment (Spring 2020) PDFAbdul RafayNo ratings yet
- A Review of Passive Micromixers With A ComparativeDocument25 pagesA Review of Passive Micromixers With A ComparativeSadia SiddiqaNo ratings yet
- Moral Sensitivity and The Limits of Artificial Moral Agents: Joris GraffDocument12 pagesMoral Sensitivity and The Limits of Artificial Moral Agents: Joris Graffcarbet_vrilNo ratings yet
- HSE Calendar 2023 - 221230 - 112723Document13 pagesHSE Calendar 2023 - 221230 - 112723Mkd OfficialNo ratings yet
- General Geology of RomaniaDocument27 pagesGeneral Geology of RomaniaDana PrisacNo ratings yet
- Chapter 1 Digital Systems and Binary NumbersDocument100 pagesChapter 1 Digital Systems and Binary NumbersVandana JoshiNo ratings yet
- KTG UpdatedDocument5 pagesKTG Updateddeejam123No ratings yet
- Decision Involving Alternative ChoicesDocument11 pagesDecision Involving Alternative Choicesadixitanuj6No ratings yet
- Learning Material XDocument18 pagesLearning Material XYuki IndayantiNo ratings yet
- Clases 09 Avian EncephalomyelitisDocument31 pagesClases 09 Avian EncephalomyelitisMijael ChoqueNo ratings yet
- PosterDocument1 pagePosterTalha HanifNo ratings yet
- About The Job Smelter Operation ReadinessDocument4 pagesAbout The Job Smelter Operation Readinessmuhammad ridwanNo ratings yet
- 1lmd Eng 1Document15 pages1lmd Eng 1Yassine HamdiaNo ratings yet
- UG Syllabus B.tech 1stDocument12 pagesUG Syllabus B.tech 1stRaunak GuptaNo ratings yet
- Metacognitive Reading Report 2Document3 pagesMetacognitive Reading Report 2wahahahhasiafiadgNo ratings yet
- Modified Co Requisite FormDocument2 pagesModified Co Requisite FormMiguel BungalonNo ratings yet
- EPP E2 Activity 2Document2 pagesEPP E2 Activity 2Hannah Nore TalingtingNo ratings yet
- Chapter 06Document43 pagesChapter 06benjaminblakkNo ratings yet
- Sop Guidelines OpcenDocument17 pagesSop Guidelines OpcenJessie Bhong Legarto100% (1)
- Cultura y El Estado SteinmetzDocument51 pagesCultura y El Estado SteinmetzJose U Dzib CanNo ratings yet
- AMC12A - Đề Thi TA-TV-ĐA-2023Document15 pagesAMC12A - Đề Thi TA-TV-ĐA-2023TranhylapNo ratings yet
- The Minimum Mean Dominating Energy of GraphsDocument5 pagesThe Minimum Mean Dominating Energy of GraphsiirNo ratings yet
- Environmental LawDocument46 pagesEnvironmental LawRohit100% (1)