
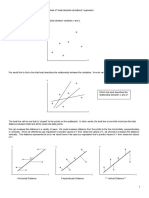
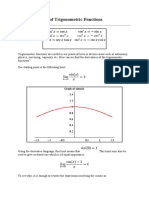
Linear Regression: Method of Least Squares
Linear Regression: Method of Least Squares
You might also like
- Pset 6 - Fall2019 - Solutions PDFDocument33 pagesPset 6 - Fall2019 - Solutions PDFjoshua arnett100% (3)
- Part 1: Predicting Stock Returns.: Data DescriptionDocument8 pagesPart 1: Predicting Stock Returns.: Data DescriptionRizza L. Macarandan0% (1)
- MPC 006 DDocument12 pagesMPC 006 DankushNo ratings yet
- World Happiness ReportDocument7 pagesWorld Happiness ReportMuriloMonteiroNo ratings yet
- Hypothesis RoadmapDocument1 pageHypothesis RoadmapJames Head100% (4)
- 2 - 11 - Lecture 4B - Correlation (10-41)Document5 pages2 - 11 - Lecture 4B - Correlation (10-41)bablinayakiNo ratings yet
- ML CourseraDocument10 pagesML CourseraShaheer KhanNo ratings yet
- ML Lecture - 3Document47 pagesML Lecture - 3ARTS -أرطسNo ratings yet
- KL TransformDocument22 pagesKL TransformPrasanna Kumar Kottakota100% (1)
- A Nonmonotonic ExampleDocument3 pagesA Nonmonotonic Exampledekku gordeNo ratings yet
- Lec1 3Document29 pagesLec1 3vkagarwaNo ratings yet
- 19 - Correlation and RegressionDocument7 pages19 - Correlation and Regressionzahoor80No ratings yet
- Verilog LectureDocument17 pagesVerilog LectureRam Janam YadavNo ratings yet
- Correlation:: (Bálint Tóth, Pázmány Péter Catholic University:, Do Not Share Without Author's Permission)Document9 pagesCorrelation:: (Bálint Tóth, Pázmány Péter Catholic University:, Do Not Share Without Author's Permission)Bálint L'Obasso TóthNo ratings yet
- On Using These Lecture NotesDocument6 pagesOn Using These Lecture Noteskfoster5126No ratings yet
- UC Berkeley Econ 140 Section 10Document8 pagesUC Berkeley Econ 140 Section 10AkhilNo ratings yet
- Probability Handout PART3Document9 pagesProbability Handout PART3Scarlet leeNo ratings yet
- Chapter 13 Quick Overview of Correlation and Linear RegressionDocument17 pagesChapter 13 Quick Overview of Correlation and Linear RegressionJayzie LiNo ratings yet
- ML: Introduction 1. What Is Machine Learning?Document38 pagesML: Introduction 1. What Is Machine Learning?rohitNo ratings yet
- Approximating Sinusoidal Functions With PolynomialsDocument14 pagesApproximating Sinusoidal Functions With PolynomialsEdward ConalNo ratings yet
- Linear Regression - Module 3Document16 pagesLinear Regression - Module 3Arjun Singh ANo ratings yet
- The Simple Linear Regression Model and CorrelationDocument64 pagesThe Simple Linear Regression Model and CorrelationRajesh DwivediNo ratings yet
- What Is Differentiation?: Rate of Change of The Distance Compared To The Time. The Slope Is Positive All TheDocument14 pagesWhat Is Differentiation?: Rate of Change of The Distance Compared To The Time. The Slope Is Positive All TheWuey MeiiNo ratings yet
- To Print - RandomnumberDocument29 pagesTo Print - RandomnumberfterasawmyNo ratings yet
- Functional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurDocument15 pagesFunctional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurKofi Appiah-DanquahNo ratings yet
- Dimension ReductionDocument78 pagesDimension ReductionGuneetNo ratings yet
- UntitledDocument6 pagesUntitledkajNo ratings yet
- The Simple Regression ModelDocument41 pagesThe Simple Regression ModelDeniz Senturk OzcanNo ratings yet
- All LectureNotesDocument155 pagesAll LectureNotesSrinivas NemaniNo ratings yet
- 1 - The Multiple Linear Regession Model (MLR)Document26 pages1 - The Multiple Linear Regession Model (MLR)Eduardo MuñozNo ratings yet
- UntitledDocument85 pagesUntitledfgbdNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument5 pagesML:Introduction: Week 1 Lecture NotesAKNo ratings yet
- Introduction To Calculus/LimitsDocument16 pagesIntroduction To Calculus/LimitsLJ UretaNo ratings yet
- Regression With A Binary Dependent VariableDocument63 pagesRegression With A Binary Dependent VariableDavid EdemNo ratings yet
- Regression Test Lesson Notes (Optional Download)Document5 pagesRegression Test Lesson Notes (Optional Download)Chuyên Mai TấtNo ratings yet
- Activity in English III CourtDocument3 pagesActivity in English III Courtmaria alejandra pinzon murciaNo ratings yet
- Module 1 SHAREDocument19 pagesModule 1 SHAREtadeusNo ratings yet
- Wickham StatiDocument12 pagesWickham StatiJitendra K JhaNo ratings yet
- Factor AnalysisDocument57 pagesFactor AnalysisRajendra KumarNo ratings yet
- Basic Probability Reference Sheet: February 27, 2001Document8 pagesBasic Probability Reference Sheet: February 27, 2001Ibrahim TakounaNo ratings yet
- MITOCW - MIT18 - 01SCF10Rec - 26 - 300k: Christine BreinerDocument3 pagesMITOCW - MIT18 - 01SCF10Rec - 26 - 300k: Christine BreinerVinayak JhaNo ratings yet
- Ols PDFDocument8 pagesOls PDFChandupraveen GudiNo ratings yet
- Solutions Manual To Mathematical Analysis by Tom Apostol - Second Edition-Chapter OneDocument67 pagesSolutions Manual To Mathematical Analysis by Tom Apostol - Second Edition-Chapter Oneayesha dollNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument10 pagesML:Introduction: Week 1 Lecture NotesShubhamNo ratings yet
- Lec 3Document28 pagesLec 3abimanaNo ratings yet
- 1.1 FunctionsDocument11 pages1.1 FunctionsOfficial-site suuNo ratings yet
- Maths For FinanceDocument22 pagesMaths For FinanceWonde BiruNo ratings yet
- Finite Element Method Mod-1 Lec-3Document28 pagesFinite Element Method Mod-1 Lec-3PSINGH02No ratings yet
- U IUI IUI: A Model ofDocument5 pagesU IUI IUI: A Model ofRosalieSKeddisNo ratings yet
- Lecture 12: The Simplex Algorithm: Proof of CorrectnessDocument2 pagesLecture 12: The Simplex Algorithm: Proof of Correctnesschutia_userNo ratings yet
- Machine Learning - Home - Week 1 - Notes - CourseraDocument7 pagesMachine Learning - Home - Week 1 - Notes - CourseracopsamostoNo ratings yet
- HANDOUT Rvu Maths For BusinessDocument80 pagesHANDOUT Rvu Maths For BusinessGUDATA ABARANo ratings yet
- Session-Classical AssumptionDocument26 pagesSession-Classical Assumptionhilmiazis15No ratings yet
- TB RH 71 BMJVWDocument4 pagesTB RH 71 BMJVWariaNo ratings yet
- Chapter 1 Simple Linear RegressionDocument17 pagesChapter 1 Simple Linear RegressionBoutaina AzNo ratings yet
- Special DistributionsDocument52 pagesSpecial DistributionsUmair AnsariNo ratings yet
- E Pii: Why Is - 1?Document5 pagesE Pii: Why Is - 1?EinsteinJr1No ratings yet
- Lec24 PDFDocument24 pagesLec24 PDFVanitha ShahNo ratings yet
- Visualizing L Hopitals RuleDocument7 pagesVisualizing L Hopitals RuleAlain-Philippe FortinNo ratings yet
- Boolean AlgebraDocument5 pagesBoolean AlgebraSyste DesigNo ratings yet
- The Magic of XORDocument4 pagesThe Magic of XORmps125No ratings yet
- Naveen MathDocument14 pagesNaveen MathMohammad AlyNo ratings yet
- The Derivatives of Trigonometric FunctionsDocument29 pagesThe Derivatives of Trigonometric FunctionsM Arifin RasdhakimNo ratings yet
- Sequence of FucntionsDocument15 pagesSequence of Fucntionskishalay sarkarNo ratings yet
- Probability Theory Review 2Document13 pagesProbability Theory Review 2Erik LampeNo ratings yet
- Probability Theory Review: Example: Couple With 2 KidsDocument7 pagesProbability Theory Review: Example: Couple With 2 KidsErik LampeNo ratings yet
- First Rule - Major RuleDocument3 pagesFirst Rule - Major RuleErik LampeNo ratings yet
- Naive Bayes Model: Example - DiscreteDocument4 pagesNaive Bayes Model: Example - DiscreteErik LampeNo ratings yet
- A Strange FireDocument23 pagesA Strange FireErik LampeNo ratings yet
- Exercise Sem 2 20162017 - Past YearDocument5 pagesExercise Sem 2 20162017 - Past Yearsyakirah-mustaphaNo ratings yet
- Semc 3 QDocument9 pagesSemc 3 QshelygandhiNo ratings yet
- Topic 6. Two-Way Designs: Randomized Complete Block DesignDocument18 pagesTopic 6. Two-Way Designs: Randomized Complete Block DesignmaleticjNo ratings yet
- Hypothesis Testing For One PopulationDocument57 pagesHypothesis Testing For One PopulationFarah CakeyNo ratings yet
- Foundation Program - Decision Analysis - Dr. Shweta DixitDocument85 pagesFoundation Program - Decision Analysis - Dr. Shweta DixitNeha MittalNo ratings yet
- Chapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Document27 pagesChapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Hannah SyNo ratings yet
- Multivariate Analysis of Variance (MANOVA) II: Practical Guide To ANOVA and MANOVA For SAS Terminology For ANOVADocument33 pagesMultivariate Analysis of Variance (MANOVA) II: Practical Guide To ANOVA and MANOVA For SAS Terminology For ANOVAf1r3br4nd9427No ratings yet
- 10 Bio 106 Chi-Square Test of IndependenceDocument22 pages10 Bio 106 Chi-Square Test of IndependenceShewanism TvNo ratings yet
- Statistics For Business and Economics: Inferences Based On Two Samples: Confidence Intervals & Tests of HypothesesDocument112 pagesStatistics For Business and Economics: Inferences Based On Two Samples: Confidence Intervals & Tests of HypothesesThảo Phương Nguyễn LêNo ratings yet
- DLL BudgetedDocument9 pagesDLL BudgetedAbigail Vale?No ratings yet
- Sunil Testing HypothesisDocument39 pagesSunil Testing Hypothesisprayag DasNo ratings yet
- Chapter 12Document36 pagesChapter 12Alban BogdaniNo ratings yet
- Community Project: Checking Normality in ExcelDocument4 pagesCommunity Project: Checking Normality in ExcelZvonko TNo ratings yet
- OPMATQM Unit 2 Activity PART 2 Assignment - Agner, Jam Althea O.Document5 pagesOPMATQM Unit 2 Activity PART 2 Assignment - Agner, Jam Althea O.JAM ALTHEA AGNERNo ratings yet
- Chi-Square Test: Advance StatisticsDocument26 pagesChi-Square Test: Advance StatisticsRobert Carl GarciaNo ratings yet
- Time Series Analysis With R - Part IDocument23 pagesTime Series Analysis With R - Part Ithcm2011No ratings yet
- MAS-01 Cost Behavior AnalysisDocument6 pagesMAS-01 Cost Behavior AnalysisPaupauNo ratings yet
- Ebook Business Statistics For Contemporary Decision Making 9Th Edition Black Test Bank Full Chapter PDFDocument54 pagesEbook Business Statistics For Contemporary Decision Making 9Th Edition Black Test Bank Full Chapter PDFreunitetuquekf100% (16)
- Endogeneity Test Stata 14 PDFDocument18 pagesEndogeneity Test Stata 14 PDFUNLV234No ratings yet
- Bab 4 ForecastingDocument16 pagesBab 4 ForecastingEGA NOVRI ANDININo ratings yet
- Lab 3 - Write UpDocument3 pagesLab 3 - Write UpSaurabh JadhavNo ratings yet
- Introduction To Econometric Views: N.Nilgün ÇokçaDocument50 pagesIntroduction To Econometric Views: N.Nilgün ÇokçaMarkWeberNo ratings yet
- Introduction To R ProgrammingDocument23 pagesIntroduction To R Programmingtapstaps902No ratings yet
- Econometric Project - Linear Regression ModelDocument17 pagesEconometric Project - Linear Regression ModelDiana RoșcaNo ratings yet
- Z Test and T TestDocument28 pagesZ Test and T TestDr. POONAM KAUSHALNo ratings yet





























































































Download as pdf or txt
You might also like
- Pset 6 - Fall2019 - Solutions PDFDocument33 pagesPset 6 - Fall2019 - Solutions PDFjoshua arnett100% (3)
- Part 1: Predicting Stock Returns.: Data DescriptionDocument8 pagesPart 1: Predicting Stock Returns.: Data DescriptionRizza L. Macarandan0% (1)
- MPC 006 DDocument12 pagesMPC 006 DankushNo ratings yet
- World Happiness ReportDocument7 pagesWorld Happiness ReportMuriloMonteiroNo ratings yet
- Hypothesis RoadmapDocument1 pageHypothesis RoadmapJames Head100% (4)
- 2 - 11 - Lecture 4B - Correlation (10-41)Document5 pages2 - 11 - Lecture 4B - Correlation (10-41)bablinayakiNo ratings yet
- ML CourseraDocument10 pagesML CourseraShaheer KhanNo ratings yet
- ML Lecture - 3Document47 pagesML Lecture - 3ARTS -أرطسNo ratings yet
- KL TransformDocument22 pagesKL TransformPrasanna Kumar Kottakota100% (1)
- A Nonmonotonic ExampleDocument3 pagesA Nonmonotonic Exampledekku gordeNo ratings yet
- Lec1 3Document29 pagesLec1 3vkagarwaNo ratings yet
- 19 - Correlation and RegressionDocument7 pages19 - Correlation and Regressionzahoor80No ratings yet
- Verilog LectureDocument17 pagesVerilog LectureRam Janam YadavNo ratings yet
- Correlation:: (Bálint Tóth, Pázmány Péter Catholic University:, Do Not Share Without Author's Permission)Document9 pagesCorrelation:: (Bálint Tóth, Pázmány Péter Catholic University:, Do Not Share Without Author's Permission)Bálint L'Obasso TóthNo ratings yet
- On Using These Lecture NotesDocument6 pagesOn Using These Lecture Noteskfoster5126No ratings yet
- UC Berkeley Econ 140 Section 10Document8 pagesUC Berkeley Econ 140 Section 10AkhilNo ratings yet
- Probability Handout PART3Document9 pagesProbability Handout PART3Scarlet leeNo ratings yet
- Chapter 13 Quick Overview of Correlation and Linear RegressionDocument17 pagesChapter 13 Quick Overview of Correlation and Linear RegressionJayzie LiNo ratings yet
- ML: Introduction 1. What Is Machine Learning?Document38 pagesML: Introduction 1. What Is Machine Learning?rohitNo ratings yet
- Approximating Sinusoidal Functions With PolynomialsDocument14 pagesApproximating Sinusoidal Functions With PolynomialsEdward ConalNo ratings yet
- Linear Regression - Module 3Document16 pagesLinear Regression - Module 3Arjun Singh ANo ratings yet
- The Simple Linear Regression Model and CorrelationDocument64 pagesThe Simple Linear Regression Model and CorrelationRajesh DwivediNo ratings yet
- What Is Differentiation?: Rate of Change of The Distance Compared To The Time. The Slope Is Positive All TheDocument14 pagesWhat Is Differentiation?: Rate of Change of The Distance Compared To The Time. The Slope Is Positive All TheWuey MeiiNo ratings yet
- To Print - RandomnumberDocument29 pagesTo Print - RandomnumberfterasawmyNo ratings yet
- Functional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurDocument15 pagesFunctional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurKofi Appiah-DanquahNo ratings yet
- Dimension ReductionDocument78 pagesDimension ReductionGuneetNo ratings yet
- UntitledDocument6 pagesUntitledkajNo ratings yet
- The Simple Regression ModelDocument41 pagesThe Simple Regression ModelDeniz Senturk OzcanNo ratings yet
- All LectureNotesDocument155 pagesAll LectureNotesSrinivas NemaniNo ratings yet
- 1 - The Multiple Linear Regession Model (MLR)Document26 pages1 - The Multiple Linear Regession Model (MLR)Eduardo MuñozNo ratings yet
- UntitledDocument85 pagesUntitledfgbdNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument5 pagesML:Introduction: Week 1 Lecture NotesAKNo ratings yet
- Introduction To Calculus/LimitsDocument16 pagesIntroduction To Calculus/LimitsLJ UretaNo ratings yet
- Regression With A Binary Dependent VariableDocument63 pagesRegression With A Binary Dependent VariableDavid EdemNo ratings yet
- Regression Test Lesson Notes (Optional Download)Document5 pagesRegression Test Lesson Notes (Optional Download)Chuyên Mai TấtNo ratings yet
- Activity in English III CourtDocument3 pagesActivity in English III Courtmaria alejandra pinzon murciaNo ratings yet
- Module 1 SHAREDocument19 pagesModule 1 SHAREtadeusNo ratings yet
- Wickham StatiDocument12 pagesWickham StatiJitendra K JhaNo ratings yet
- Factor AnalysisDocument57 pagesFactor AnalysisRajendra KumarNo ratings yet
- Basic Probability Reference Sheet: February 27, 2001Document8 pagesBasic Probability Reference Sheet: February 27, 2001Ibrahim TakounaNo ratings yet
- MITOCW - MIT18 - 01SCF10Rec - 26 - 300k: Christine BreinerDocument3 pagesMITOCW - MIT18 - 01SCF10Rec - 26 - 300k: Christine BreinerVinayak JhaNo ratings yet
- Ols PDFDocument8 pagesOls PDFChandupraveen GudiNo ratings yet
- Solutions Manual To Mathematical Analysis by Tom Apostol - Second Edition-Chapter OneDocument67 pagesSolutions Manual To Mathematical Analysis by Tom Apostol - Second Edition-Chapter Oneayesha dollNo ratings yet
- ML:Introduction: Week 1 Lecture NotesDocument10 pagesML:Introduction: Week 1 Lecture NotesShubhamNo ratings yet
- Lec 3Document28 pagesLec 3abimanaNo ratings yet
- 1.1 FunctionsDocument11 pages1.1 FunctionsOfficial-site suuNo ratings yet
- Maths For FinanceDocument22 pagesMaths For FinanceWonde BiruNo ratings yet
- Finite Element Method Mod-1 Lec-3Document28 pagesFinite Element Method Mod-1 Lec-3PSINGH02No ratings yet
- U IUI IUI: A Model ofDocument5 pagesU IUI IUI: A Model ofRosalieSKeddisNo ratings yet
- Lecture 12: The Simplex Algorithm: Proof of CorrectnessDocument2 pagesLecture 12: The Simplex Algorithm: Proof of Correctnesschutia_userNo ratings yet
- Machine Learning - Home - Week 1 - Notes - CourseraDocument7 pagesMachine Learning - Home - Week 1 - Notes - CourseracopsamostoNo ratings yet
- HANDOUT Rvu Maths For BusinessDocument80 pagesHANDOUT Rvu Maths For BusinessGUDATA ABARANo ratings yet
- Session-Classical AssumptionDocument26 pagesSession-Classical Assumptionhilmiazis15No ratings yet
- TB RH 71 BMJVWDocument4 pagesTB RH 71 BMJVWariaNo ratings yet
- Chapter 1 Simple Linear RegressionDocument17 pagesChapter 1 Simple Linear RegressionBoutaina AzNo ratings yet
- Special DistributionsDocument52 pagesSpecial DistributionsUmair AnsariNo ratings yet
- E Pii: Why Is - 1?Document5 pagesE Pii: Why Is - 1?EinsteinJr1No ratings yet
- Lec24 PDFDocument24 pagesLec24 PDFVanitha ShahNo ratings yet
- Visualizing L Hopitals RuleDocument7 pagesVisualizing L Hopitals RuleAlain-Philippe FortinNo ratings yet
- Boolean AlgebraDocument5 pagesBoolean AlgebraSyste DesigNo ratings yet
- The Magic of XORDocument4 pagesThe Magic of XORmps125No ratings yet
- Naveen MathDocument14 pagesNaveen MathMohammad AlyNo ratings yet
- The Derivatives of Trigonometric FunctionsDocument29 pagesThe Derivatives of Trigonometric FunctionsM Arifin RasdhakimNo ratings yet
- Sequence of FucntionsDocument15 pagesSequence of Fucntionskishalay sarkarNo ratings yet
- Probability Theory Review 2Document13 pagesProbability Theory Review 2Erik LampeNo ratings yet
- Probability Theory Review: Example: Couple With 2 KidsDocument7 pagesProbability Theory Review: Example: Couple With 2 KidsErik LampeNo ratings yet
- First Rule - Major RuleDocument3 pagesFirst Rule - Major RuleErik LampeNo ratings yet
- Naive Bayes Model: Example - DiscreteDocument4 pagesNaive Bayes Model: Example - DiscreteErik LampeNo ratings yet
- A Strange FireDocument23 pagesA Strange FireErik LampeNo ratings yet
- Exercise Sem 2 20162017 - Past YearDocument5 pagesExercise Sem 2 20162017 - Past Yearsyakirah-mustaphaNo ratings yet
- Semc 3 QDocument9 pagesSemc 3 QshelygandhiNo ratings yet
- Topic 6. Two-Way Designs: Randomized Complete Block DesignDocument18 pagesTopic 6. Two-Way Designs: Randomized Complete Block DesignmaleticjNo ratings yet
- Hypothesis Testing For One PopulationDocument57 pagesHypothesis Testing For One PopulationFarah CakeyNo ratings yet
- Foundation Program - Decision Analysis - Dr. Shweta DixitDocument85 pagesFoundation Program - Decision Analysis - Dr. Shweta DixitNeha MittalNo ratings yet
- Chapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Document27 pagesChapter 4 Regression Models: Quantitative Analysis For Management, 11e (Render)Hannah SyNo ratings yet
- Multivariate Analysis of Variance (MANOVA) II: Practical Guide To ANOVA and MANOVA For SAS Terminology For ANOVADocument33 pagesMultivariate Analysis of Variance (MANOVA) II: Practical Guide To ANOVA and MANOVA For SAS Terminology For ANOVAf1r3br4nd9427No ratings yet
- 10 Bio 106 Chi-Square Test of IndependenceDocument22 pages10 Bio 106 Chi-Square Test of IndependenceShewanism TvNo ratings yet
- Statistics For Business and Economics: Inferences Based On Two Samples: Confidence Intervals & Tests of HypothesesDocument112 pagesStatistics For Business and Economics: Inferences Based On Two Samples: Confidence Intervals & Tests of HypothesesThảo Phương Nguyễn LêNo ratings yet
- DLL BudgetedDocument9 pagesDLL BudgetedAbigail Vale?No ratings yet
- Sunil Testing HypothesisDocument39 pagesSunil Testing Hypothesisprayag DasNo ratings yet
- Chapter 12Document36 pagesChapter 12Alban BogdaniNo ratings yet
- Community Project: Checking Normality in ExcelDocument4 pagesCommunity Project: Checking Normality in ExcelZvonko TNo ratings yet
- OPMATQM Unit 2 Activity PART 2 Assignment - Agner, Jam Althea O.Document5 pagesOPMATQM Unit 2 Activity PART 2 Assignment - Agner, Jam Althea O.JAM ALTHEA AGNERNo ratings yet
- Chi-Square Test: Advance StatisticsDocument26 pagesChi-Square Test: Advance StatisticsRobert Carl GarciaNo ratings yet
- Time Series Analysis With R - Part IDocument23 pagesTime Series Analysis With R - Part Ithcm2011No ratings yet
- MAS-01 Cost Behavior AnalysisDocument6 pagesMAS-01 Cost Behavior AnalysisPaupauNo ratings yet
- Ebook Business Statistics For Contemporary Decision Making 9Th Edition Black Test Bank Full Chapter PDFDocument54 pagesEbook Business Statistics For Contemporary Decision Making 9Th Edition Black Test Bank Full Chapter PDFreunitetuquekf100% (16)
- Endogeneity Test Stata 14 PDFDocument18 pagesEndogeneity Test Stata 14 PDFUNLV234No ratings yet
- Bab 4 ForecastingDocument16 pagesBab 4 ForecastingEGA NOVRI ANDININo ratings yet
- Lab 3 - Write UpDocument3 pagesLab 3 - Write UpSaurabh JadhavNo ratings yet
- Introduction To Econometric Views: N.Nilgün ÇokçaDocument50 pagesIntroduction To Econometric Views: N.Nilgün ÇokçaMarkWeberNo ratings yet
- Introduction To R ProgrammingDocument23 pagesIntroduction To R Programmingtapstaps902No ratings yet
- Econometric Project - Linear Regression ModelDocument17 pagesEconometric Project - Linear Regression ModelDiana RoșcaNo ratings yet
- Z Test and T TestDocument28 pagesZ Test and T TestDr. POONAM KAUSHALNo ratings yet