Download as txt, pdf, or txt
You might also like
- OOP SyllabusDocument5 pagesOOP SyllabusRomeo Duque Lobaton Jr.No ratings yet
- Drymax 100 + PDC @ENDocument38 pagesDrymax 100 + PDC @ENMarcelo Rodriguez OspinaNo ratings yet
- Tribhuvan University Institute of Engineering Pulchowk, Lalipur A Lab Report On Embedded SystemDocument22 pagesTribhuvan University Institute of Engineering Pulchowk, Lalipur A Lab Report On Embedded SystemSaroj KatwalNo ratings yet
- ML Assignment 01 CodeDocument21 pagesML Assignment 01 CodeAwais KhanNo ratings yet
- Formulario - EADocument6 pagesFormulario - EAMARLENE FRANCISCA MARIA FUENTES ROANo ratings yet
- ArimaDocument6 pagesArimaCesar AliagaNo ratings yet
- Stocs PredictDocument2 pagesStocs PredictSanjay ReddyNo ratings yet
- Ex No 6Document3 pagesEx No 6kpramya19No ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- Formulario - EADocument7 pagesFormulario - EAMARLENE FRANCISCA MARIA FUENTES ROANo ratings yet
- New Text DocumentDocument1 pageNew Text DocumentAbdullah ShatnawiNo ratings yet
- MLRecordDocument24 pagesMLRecordranadheer5221No ratings yet
- Lab 3Document2 pagesLab 3zenkaevaaiymNo ratings yet
- Untitled DocumentDocument19 pagesUntitled Documents14utkarsh2111019No ratings yet
- Practicle6 (Code)Document4 pagesPracticle6 (Code)Pallavi GaikwadNo ratings yet
- Fds SlipsDocument6 pagesFds Slipskaranka103No ratings yet
- Python CodesDocument17 pagesPython CodesAkhilNo ratings yet
- Practical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?Document17 pagesPractical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?AHMED NAEEM 2No ratings yet
- Urmi ML Practical FileDocument37 pagesUrmi ML Practical Filebekar kaNo ratings yet
- Data Exploration and Regression in Python With HBAT DatasetDocument4 pagesData Exploration and Regression in Python With HBAT DatasetmaniNo ratings yet
- Trabajo BussinesDocument19 pagesTrabajo BussinesJorge CaceresNo ratings yet
- Proyecto Final ModelDocument13 pagesProyecto Final Modelluis fuentesNo ratings yet
- DS Slips Solutions Sem 5Document23 pagesDS Slips Solutions Sem 5yashm4071No ratings yet
- PRJ Car Price Prediction For Data ScienceDocument10 pagesPRJ Car Price Prediction For Data Scienceshivaybhargava33No ratings yet
- AI Medical Diagnosis Week 01Document5 pagesAI Medical Diagnosis Week 01San RajNo ratings yet
- Final Code 2Document3 pagesFinal Code 2incomemining.biNo ratings yet
- DF PD - Read - Excel ('Sample - Superstore - XLS') : Anjaliassignmnet - Ipy NBDocument23 pagesDF PD - Read - Excel ('Sample - Superstore - XLS') : Anjaliassignmnet - Ipy NBsumaira khanNo ratings yet
- EDA Plots CodeDocument13 pagesEDA Plots Codeprashant yadavNo ratings yet
- ProductDocument3 pagesProductsoumya.satapathy24No ratings yet
- FakeNewsDetection StudentDocument7 pagesFakeNewsDetection StudentnehailaNo ratings yet
- Face Recognition Using Facenet3Document4 pagesFace Recognition Using Facenet3Harini MurugananthamNo ratings yet
- CodeDocument6 pagesCodeKeerti GulatiNo ratings yet
- Da ProgramDocument18 pagesDa Programalishacalista238No ratings yet
- IP Assgn 3Document12 pagesIP Assgn 3Siérra GreenNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Python SlipsDocument9 pagesPython Slipsemmamusk061No ratings yet
- Python GTU Study Material E-Notes 3 16012021061619AMDocument36 pagesPython GTU Study Material E-Notes 3 16012021061619AMZainab KhatriNo ratings yet
- Sheet 5 PandasDocument13 pagesSheet 5 PandasIrene GabrielNo ratings yet
- Siemplify - QradarDocument24 pagesSiemplify - QradarJohanNo ratings yet
- New Opendocument TextDocument7 pagesNew Opendocument Textapi-635142331No ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Appendix PDFDocument5 pagesAppendix PDFRamaNo ratings yet
- AI Salary Expt 9Document1 pageAI Salary Expt 9004Prasanna TayareNo ratings yet
- Comff 1Document10 pagesComff 1Ansh bNo ratings yet
- Heart Disease Prediction Using Neural NetworksDocument6 pagesHeart Disease Prediction Using Neural NetworksLusi YantiNo ratings yet
- Stock PredDocument2 pagesStock PredSrijeeta SenNo ratings yet
- File 1Document2 pagesFile 1sameeruddin409No ratings yet
- PandaDocument33 pagesPandakrNo ratings yet
- CodeDocument2 pagesCodekarthikeyanmlopsNo ratings yet
- An Introduction To SeabornDocument42 pagesAn Introduction To SeabornMohammad BangeeNo ratings yet
- DS Lab-5 GP-Anirudh 180905452 B2 59Document27 pagesDS Lab-5 GP-Anirudh 180905452 B2 59Üdây KìrâñNo ratings yet
- Python Data Analysation and VisualisationDocument4 pagesPython Data Analysation and VisualisationJagmohanNo ratings yet
- Assignment 3Document7 pagesAssignment 3Haisam AbbasNo ratings yet
- Import Numpy As NPDocument6 pagesImport Numpy As NPMaciej WiśniewskiNo ratings yet
- Abhiml ML FileDocument74 pagesAbhiml ML FileBhawna ChandlaNo ratings yet
- Python 2Document28 pagesPython 2lisha MNo ratings yet
- ML FileDocument37 pagesML File25532aayushi.2020No ratings yet
- Pandas Dataframe Assignment No 3 - AnswerkeyDocument10 pagesPandas Dataframe Assignment No 3 - AnswerkeyAnni KumarNo ratings yet
- Machine FileDocument27 pagesMachine FileJyoti GodaraNo ratings yet
- Basic Series Analysis - Gold - MonthlyDocument2 pagesBasic Series Analysis - Gold - Monthlypragyaparik16No ratings yet
- Angelriya 3 ADocument4 pagesAngelriya 3 ASatish JadhavNo ratings yet
- Coursera EF8GCN8YJV5UDocument1 pageCoursera EF8GCN8YJV5UKarloNo ratings yet
- Bokkisam Rohit: Course CertificateDocument15 pagesBokkisam Rohit: Course CertificateKarlo0% (1)
- Coursera TEQ3K5PDXM4GDocument1 pageCoursera TEQ3K5PDXM4GKarloNo ratings yet
- Coursera AK4D86VHN2NTDocument1 pageCoursera AK4D86VHN2NTKarloNo ratings yet
- MySQL PDF InterviewbitDocument18 pagesMySQL PDF InterviewbitaditiNo ratings yet
- Stats Prob Week 1Document13 pagesStats Prob Week 1nsnoivqNo ratings yet
- Cse 8 Sem Natural Language Processing 3698 Summer 2019Document2 pagesCse 8 Sem Natural Language Processing 3698 Summer 2019Sushant VyasNo ratings yet
- Quectel BG96 MQTT Application Note V1.1Document32 pagesQuectel BG96 MQTT Application Note V1.1LaloNo ratings yet
- Blood Bank Management System: Guided byDocument27 pagesBlood Bank Management System: Guided byPRATIKKUMARNo ratings yet
- User Manual For Filing JPT 201Document12 pagesUser Manual For Filing JPT 201Dalwinder SinghNo ratings yet
- A Machine Learning Approach For Digital WatermarkingDocument12 pagesA Machine Learning Approach For Digital Watermarkingfebaxag385No ratings yet
- Imb 150Document2 pagesImb 150DanielNo ratings yet
- A Meta-Analysis On Educational Technology in English Language TeachingDocument20 pagesA Meta-Analysis On Educational Technology in English Language TeachingChristelle AbaoNo ratings yet
- SquidFaq - CompilingSquid - Squid Web Proxy WikiDocument7 pagesSquidFaq - CompilingSquid - Squid Web Proxy WikiJavierNo ratings yet
- Quiz Bee ScoreboardDocument6 pagesQuiz Bee ScoreboardLeah Ibita DulayNo ratings yet
- FastRawViewer ManualDocument253 pagesFastRawViewer ManualYuventa EroNo ratings yet
- Specification FOR Approval: Title 17.3" FHD TFT LCDDocument31 pagesSpecification FOR Approval: Title 17.3" FHD TFT LCDRecep TOSUNNo ratings yet
- Numerical Machines - NotesDocument23 pagesNumerical Machines - NotesPethurajNo ratings yet
- Tq-Eapp .1Document5 pagesTq-Eapp .1Marydel DagaNo ratings yet
- 0-By CPU - ELBRUS - 06-02-2021-20-41-47Document2 pages0-By CPU - ELBRUS - 06-02-2021-20-41-47alejandroccNo ratings yet
- How To Connect Non Compliant IED With Profinet S2Document9 pagesHow To Connect Non Compliant IED With Profinet S2Clear MindNo ratings yet
- Computer Integrated Manufacturing : Lecturer: VU VAN PHONGDocument47 pagesComputer Integrated Manufacturing : Lecturer: VU VAN PHONGToy and MeNo ratings yet
- Multimedia Presentation RubricDocument3 pagesMultimedia Presentation RubricMIKKIENNANo ratings yet
- A Handbook of Mathematical Mode - Dr. Ranja SarkerDocument232 pagesA Handbook of Mathematical Mode - Dr. Ranja SarkerJohn100% (1)
- DiagramaDocument10 pagesDiagramaJorge Luis Cervantes Carrillo100% (1)
- Beginners Guide To Internet Riches PDFDocument67 pagesBeginners Guide To Internet Riches PDFRomy ysNo ratings yet
- Prediction of Risk Delay in Construction Projects UsingDocument15 pagesPrediction of Risk Delay in Construction Projects UsingJuan BrugadaNo ratings yet
- Installation Steps For Installing AIX 5.3Document3 pagesInstallation Steps For Installing AIX 5.3Deepak KumarNo ratings yet
- Reporte Creditienda 10 Agosto 2023Document82 pagesReporte Creditienda 10 Agosto 2023Paola Janette Quintero CastroNo ratings yet
- Your Logo: It Policy TemplateDocument8 pagesYour Logo: It Policy TemplateKavya GopakumarNo ratings yet
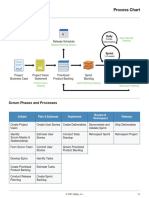
- Scrum Flow: Process ChartDocument2 pagesScrum Flow: Process ChartJean BazanNo ratings yet