Download as pdf or txt
You might also like
- Robert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDocument254 pagesRobert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDang Dinh DongNo ratings yet
- MATH 10 - Q4 - WEEK 1 - MODULE 1 - Illustrating-The-Measures-Of-Position-Quartiles-Deciles-And-PercentilesDocument23 pagesMATH 10 - Q4 - WEEK 1 - MODULE 1 - Illustrating-The-Measures-Of-Position-Quartiles-Deciles-And-PercentilesLyle Isaac L. Illaga67% (27)
- Galaxy at War - Star Wars SagaDocument225 pagesGalaxy at War - Star Wars SagaSebastián Rigoni100% (7)
- Lesson Plan in SwotDocument7 pagesLesson Plan in SwotFlorentina Visto100% (2)
- Mathematics: Quarter 4 - Module 1: Measures of PositionDocument10 pagesMathematics: Quarter 4 - Module 1: Measures of PositionVera Sol100% (1)
- Statistics Lab 10-4Document11 pagesStatistics Lab 10-4Andie CoxNo ratings yet
- InstrManual SCO1-1Document29 pagesInstrManual SCO1-1Juan Felipe AlvarezNo ratings yet
- Jsa R B 6 ForkliftDocument3 pagesJsa R B 6 ForkliftsinghajitbNo ratings yet
- 4Q Wk1 D3 Quartiles For Ungrouped DataDocument26 pages4Q Wk1 D3 Quartiles For Ungrouped DataRichZacheryNo ratings yet
- Module Lesson 4 - MPDocument8 pagesModule Lesson 4 - MPJacobNo ratings yet
- Calculating Measures of Position: Grade 10Document10 pagesCalculating Measures of Position: Grade 10jacqueline deeNo ratings yet
- Measures of PositionDocument36 pagesMeasures of Positionjinxtapperhat07No ratings yet
- Q4 Week-1Document34 pagesQ4 Week-1milabskateNo ratings yet
- Measures of Relative StandingDocument59 pagesMeasures of Relative StandingGracean MaslogNo ratings yet
- Lesson 8 - Measure of Relative PositionDocument6 pagesLesson 8 - Measure of Relative PositionriniNo ratings yet
- STATISTICS Grade 12Document22 pagesSTATISTICS Grade 12Paula Fana100% (2)
- Math Lecture 4.3Document2 pagesMath Lecture 4.3Raven MayoNo ratings yet
- Lecture 3Document26 pagesLecture 3lihaylihayjeanloveNo ratings yet
- Measure of PositionDocument13 pagesMeasure of PositionTrisha Park100% (2)
- Quartiles, Percentiles, DecilesDocument26 pagesQuartiles, Percentiles, Decilesvalorantdedication2No ratings yet
- Measure of Other Positions Quartile Percentile Decile Percentile RankDocument49 pagesMeasure of Other Positions Quartile Percentile Decile Percentile RankLovely Dianne Montaño DillaNo ratings yet
- 6 - Measures of LocationDocument40 pages6 - Measures of LocationALLYSON BURAGANo ratings yet
- Math10 Q4 W1Document8 pagesMath10 Q4 W1Ereca Mae PapongNo ratings yet
- FINAL DEMO MathDocument25 pagesFINAL DEMO MathJasper KiethNo ratings yet
- Ungrouped DataDocument5 pagesUngrouped DataLairepmi EmjaneNo ratings yet
- Q4 Wk-No.1 LAS Math10 FinalDocument8 pagesQ4 Wk-No.1 LAS Math10 FinalAronnah Jewel SimnacoNo ratings yet
- Measure of PositionDocument11 pagesMeasure of PositionJoanne Dela CruzNo ratings yet
- Share Share 4. Problem Solving With PatternsDocument48 pagesShare Share 4. Problem Solving With PatternsMaddea Oliveros (Maddy)No ratings yet
- Measures of Central Tendencies NotesDocument1 pageMeasures of Central Tendencies Notesaila grace octivaNo ratings yet
- April 15 Grade 10 Measures of Position For UNGROUPED DATADocument20 pagesApril 15 Grade 10 Measures of Position For UNGROUPED DATAshinpoumayoNo ratings yet
- Statistics: Measures of Central TendencyDocument8 pagesStatistics: Measures of Central TendencyPreslyn Coronacion PamilacanNo ratings yet
- SAT/ ACT/ Accuplacer Math ReviewDocument40 pagesSAT/ ACT/ Accuplacer Math Reviewaehsgo2college100% (1)
- CO2 Math10Document54 pagesCO2 Math10An ObinaNo ratings yet
- Measures of Relative PositionDocument18 pagesMeasures of Relative PositionEdesa Jarabejo100% (1)
- Measures of Relative PositionDocument54 pagesMeasures of Relative PositionazraelNo ratings yet
- Describing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Document4 pagesDescribing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Shane LambertNo ratings yet
- Q4 Week12 Minilesson Math 10 LASWHLPDocument9 pagesQ4 Week12 Minilesson Math 10 LASWHLPlofyshupiNo ratings yet
- I. Measures of Location: XX N XX NDocument24 pagesI. Measures of Location: XX N XX NTrixie ReynoNo ratings yet
- Measures of Position Ungrouped DataDocument61 pagesMeasures of Position Ungrouped Data9dqrdfvpjvNo ratings yet
- Math10 - Q4 - Week2 - Module2 - Calculates A Specified Measures of Position - For ReproductionDocument26 pagesMath10 - Q4 - Week2 - Module2 - Calculates A Specified Measures of Position - For ReproductionPabora KennethNo ratings yet
- Saemrue Fo Nectral Cendency: Measure of Central TendencyDocument23 pagesSaemrue Fo Nectral Cendency: Measure of Central TendencyMariel Jane MagalonaNo ratings yet
- Sample Module OutlineDocument14 pagesSample Module OutlineGemver Baula BalbasNo ratings yet
- Frequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationDocument4 pagesFrequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationJmazingNo ratings yet
- Definition of Statistics: Solved Example On StatisticsDocument10 pagesDefinition of Statistics: Solved Example On StatisticsMary Grace MoralNo ratings yet
- Math GR10 Qtr4-Module-1Document24 pagesMath GR10 Qtr4-Module-1Synonymous100% (1)
- PDF Measures of Dispersion Slide No 34 To 52Document69 pagesPDF Measures of Dispersion Slide No 34 To 52Vidhi SewaniNo ratings yet
- Measures of PositionDocument49 pagesMeasures of PositionMay MedranoNo ratings yet
- Quantiles FinalDocument34 pagesQuantiles Finalkereysha daradalNo ratings yet
- Topic 2.-Topic 2 - Mathematics As A Tool Part 1-01Document63 pagesTopic 2.-Topic 2 - Mathematics As A Tool Part 1-01hmkjhyf6qhNo ratings yet
- Measures of Central TendencyDocument14 pagesMeasures of Central TendencyNeil SumagandayNo ratings yet
- Script Week1Document11 pagesScript Week1Cathline AustriaNo ratings yet
- Exercise 3.2: NCERT Solutions For Class 7 Maths Chapter 3 Data HandlingDocument4 pagesExercise 3.2: NCERT Solutions For Class 7 Maths Chapter 3 Data HandlingHIMNISH SHARMANo ratings yet
- Collection of DataDocument16 pagesCollection of DataTriscia Joy NocilladoNo ratings yet
- Measure of Central TendencyDocument22 pagesMeasure of Central TendencyNONILYNNo ratings yet
- Measures of Relative MotionDocument20 pagesMeasures of Relative MotionBam Bam0% (1)
- Final Compilation of Act Sheets 1-55Document122 pagesFinal Compilation of Act Sheets 1-55Vevencio T. BiabeNo ratings yet
- Mathematics As A Tool: Part 1: Data ManagementDocument34 pagesMathematics As A Tool: Part 1: Data ManagementArjhay GironellaNo ratings yet
- Measures of Position JEH GJSGDocument38 pagesMeasures of Position JEH GJSGChristian GebañaNo ratings yet
- Math StatsDocument6 pagesMath StatsPein MwaNo ratings yet
- Unit III - PROBLEM SOLVING AND REASONINGDocument13 pagesUnit III - PROBLEM SOLVING AND REASONINGJewel BerbanoNo ratings yet
- MeasuresDocument15 pagesMeasuresAdy BelmonteNo ratings yet
- Statistics and ProbabilityDocument6 pagesStatistics and ProbabilityShirelyNo ratings yet
- Mother Tongue DLPDocument10 pagesMother Tongue DLPmaricrispigangNo ratings yet
- Overview of The Real Estate Industry - Evolution and Trends - SAP Flexible Real Estate Management - InglesDocument5 pagesOverview of The Real Estate Industry - Evolution and Trends - SAP Flexible Real Estate Management - InglesAdriano MesadriNo ratings yet
- The Importance of Work-Life Balance On Employee Performance Millennial Generation in IndonesiaDocument6 pagesThe Importance of Work-Life Balance On Employee Performance Millennial Generation in IndonesiaChristianWiradendiNo ratings yet
- Edited - GROUP GAMES - COURSE SYLLABUS 1st Sem AY2023 2024Document7 pagesEdited - GROUP GAMES - COURSE SYLLABUS 1st Sem AY2023 2024B09 Kurt Benedict HillNo ratings yet
- CH 4 Determinants Worksheet 1Document2 pagesCH 4 Determinants Worksheet 1khushi GoyalNo ratings yet
- Chapter 7Document6 pagesChapter 7Glace AbellanaNo ratings yet
- SSR UW DNIP 0003 ESC XXXX 001 00 Signed PDFDocument12 pagesSSR UW DNIP 0003 ESC XXXX 001 00 Signed PDFKrishna KnsNo ratings yet
- Political FactorsDocument4 pagesPolitical FactorsThùyy DunggNo ratings yet
- How To Get On A TrainDocument4 pagesHow To Get On A TrainreuenNo ratings yet
- Instruction Manual of PLC WS3U-B Series: For The Following Models: WS3U-14MR-K-B WS3U-14MT-K-B WS3U-14MRT-K-BDocument17 pagesInstruction Manual of PLC WS3U-B Series: For The Following Models: WS3U-14MR-K-B WS3U-14MT-K-B WS3U-14MRT-K-BLegendNo ratings yet
- Aliens Is Anybody Out There (A2)Document27 pagesAliens Is Anybody Out There (A2)AnyaNo ratings yet
- 2013 Rotary Index Drives Manual1Document16 pages2013 Rotary Index Drives Manual1Manoj TiwariNo ratings yet
- Saic-Q-1066 Rev 1 (Final)Document3 pagesSaic-Q-1066 Rev 1 (Final)ryann mananquilNo ratings yet
- Ardunio Based Home Kitchen Air Monitoring Systm: Presented byDocument25 pagesArdunio Based Home Kitchen Air Monitoring Systm: Presented byManik SharmaNo ratings yet
- E38 DSC System PDFDocument32 pagesE38 DSC System PDFjoker63000No ratings yet
- Test Bank For Maternity Nursing An Introductory Text 11th Edition LeiferDocument36 pagesTest Bank For Maternity Nursing An Introductory Text 11th Edition Leiferwillynabitbw3yh98% (51)
- IV Eee 18 QT Sem-I Eed Lab External Attendence SheetDocument3 pagesIV Eee 18 QT Sem-I Eed Lab External Attendence SheetKLRCET ELECATRICAL ENGINEERSNo ratings yet
- Kaeser - Service TechnicianDocument3 pagesKaeser - Service TechnicianpunujcNo ratings yet
- A Study On Marketing Strategies of LIC Agents With Special Reference To Branches in Madurai DivisionDocument14 pagesA Study On Marketing Strategies of LIC Agents With Special Reference To Branches in Madurai DivisionAjanta BearingNo ratings yet
- CCS D5293Document9 pagesCCS D5293Sofia Fasolo CunhaNo ratings yet
- Guide Card: Casa Del Niño Montessori School Guinatan, City of Ilagan, IsabelaDocument5 pagesGuide Card: Casa Del Niño Montessori School Guinatan, City of Ilagan, IsabelaManAsseh EustaceNo ratings yet
- BS 410Document22 pagesBS 410RajaKuppan100% (2)
- Evaluation of Alternative Solvents in Common Amide Coupling Reactions: Replacement of Dichloromethane and N, N-Dimethylformamide 'Document102 pagesEvaluation of Alternative Solvents in Common Amide Coupling Reactions: Replacement of Dichloromethane and N, N-Dimethylformamide 'Vaibhav DafaleNo ratings yet
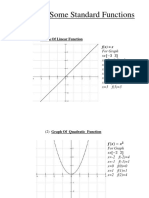
- Lecture 2 Graphs of Some Standard Functions, Shifting of GraphsDocument12 pagesLecture 2 Graphs of Some Standard Functions, Shifting of Graphsghazi membersNo ratings yet
- Pondoc Kee Jay Work 5Document5 pagesPondoc Kee Jay Work 5Spring IrishNo ratings yet