Download as pdf or txt
You might also like
- Lab 5 - Atmospheric RetentionDocument11 pagesLab 5 - Atmospheric RetentionCailey Crum100% (2)
- ERD AirlinesDocument24 pagesERD Airlinesapi-3706009100% (3)
- Greedy Algorithms 3Document36 pagesGreedy Algorithms 3Aakansh ShrivastavaNo ratings yet
- Efficiency of A Good But Not Linear Set Union Algorithm. TarjanDocument11 pagesEfficiency of A Good But Not Linear Set Union Algorithm. TarjanRyan CookNo ratings yet
- 06 2 Disjoint Sets 1 NaiveDocument58 pages06 2 Disjoint Sets 1 NaiveFichDich InDemArschNo ratings yet
- Pairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Document14 pagesPairing Heaps Are Sub-Optimal: DIMACS Technical Report 97-52 September 1997Hoang Van MinhNo ratings yet
- Graph AlgorithmsDocument45 pagesGraph AlgorithmsSrinivas ANo ratings yet
- 2IL50 Data Structures: 2018-19 Q3 Lecture 11: Minimum Spanning TreesDocument30 pages2IL50 Data Structures: 2018-19 Q3 Lecture 11: Minimum Spanning TreesJhonNo ratings yet
- Union-Find and Amortized AnalysisDocument5 pagesUnion-Find and Amortized AnalysisJohnNo ratings yet
- Lec7 Dynamictrees 1Document5 pagesLec7 Dynamictrees 1Chandra MouliNo ratings yet
- Dynamic TreesDocument6 pagesDynamic TreesPIPALIYA NISARGNo ratings yet
- Recursion ProblemsDocument7 pagesRecursion ProblemsTejasNo ratings yet
- Recursion ProblemsDocument7 pagesRecursion ProblemsZulqarnaynNo ratings yet
- Recursion ProblemsDocument7 pagesRecursion ProblemsWonderweiss MargelaNo ratings yet
- Recursion ProblemsDocument7 pagesRecursion ProblemsTejasNo ratings yet
- Advances in Applied Mathematics: Carolyn Chun, Dillon Mayhew, James OxleyDocument30 pagesAdvances in Applied Mathematics: Carolyn Chun, Dillon Mayhew, James OxleyLili MéndezNo ratings yet
- Project Report: University of WinnipegDocument28 pagesProject Report: University of WinnipegHarmeet SinghNo ratings yet
- Fib On 1Document5 pagesFib On 1shanthisecNo ratings yet
- CS168: The Modern Algorithmic Toolbox Lecture #3: Similarity Metrics and Kd-TreesDocument6 pagesCS168: The Modern Algorithmic Toolbox Lecture #3: Similarity Metrics and Kd-TreesPrathmeshNo ratings yet
- Soda14 Disjoint Set UnionDocument13 pagesSoda14 Disjoint Set UnionPrateek SharmaNo ratings yet
- Ps 5 SolDocument5 pagesPs 5 SolRandom SwagNo ratings yet
- Chap 8Document36 pagesChap 8avid_reader_newNo ratings yet
- Partition Algorithms: Ralph Freese March 4, 1997Document3 pagesPartition Algorithms: Ralph Freese March 4, 1997Kanishka DilshanNo ratings yet
- Futures: Carl L. DevitoDocument3 pagesFutures: Carl L. DevitoSantos TreviñoNo ratings yet
- Data Structures SampleDocument8 pagesData Structures SampleHebrew JohnsonNo ratings yet
- Dynamic Connectivity: 1.1 AlgorithmDocument4 pagesDynamic Connectivity: 1.1 AlgorithmAndrew LeeNo ratings yet
- COMP 482: Design and Analysis of Algorithms: Spring 2013Document34 pagesCOMP 482: Design and Analysis of Algorithms: Spring 2013shiv kumarNo ratings yet
- Unit 7: Disjoint Sets: Course ContentsDocument8 pagesUnit 7: Disjoint Sets: Course ContentshrsliNo ratings yet
- lecture15Document40 pageslecture15L A ANo ratings yet
- Jason PDFDocument14 pagesJason PDFrahulmnnit_csNo ratings yet
- Model For Social Network FormationDocument18 pagesModel For Social Network FormationRarawilisNo ratings yet
- 07 LinkcutDocument7 pages07 LinkcutPaulo Cezar Pereira CostaNo ratings yet
- PercolationDocument17 pagesPercolationAbdul Karim KhanNo ratings yet
- Disjoint Sets Data Structure: Example. Consider A System of Three Sets (1, 3, 5), (2, 6), (4, 7, 8)Document8 pagesDisjoint Sets Data Structure: Example. Consider A System of Three Sets (1, 3, 5), (2, 6), (4, 7, 8)vivekNo ratings yet
- FibonacciDocument10 pagesFibonaccisudrsneNo ratings yet
- Data Structures and Algorithms: (CS210/ESO207/ESO211)Document31 pagesData Structures and Algorithms: (CS210/ESO207/ESO211)Moazzam HussainNo ratings yet
- Matroidsknown PDFDocument16 pagesMatroidsknown PDFAlfredo UrreaNo ratings yet
- Union-Find Algorithms: Network Connectivity Quick Find Quick Union Improvements ApplicationsDocument40 pagesUnion-Find Algorithms: Network Connectivity Quick Find Quick Union Improvements ApplicationsprintesoiNo ratings yet
- Interconnection Networks: Crossbar Switch, Which Can Simultaneously Connect Any Set ofDocument11 pagesInterconnection Networks: Crossbar Switch, Which Can Simultaneously Connect Any Set ofLalith NarenNo ratings yet
- Generalized Stokes' Theorem: Colin M. Weller June 5 2020Document13 pagesGeneralized Stokes' Theorem: Colin M. Weller June 5 2020stephen kangereNo ratings yet
- ECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadaDocument23 pagesECE750 Lecture 6: Binary Relations and Graph Algorithms: Electrical & Computer Engineering University of Waterloo CanadatveldhuiNo ratings yet
- Mathematics: Group Degree Centrality and Centralization in NetworksDocument11 pagesMathematics: Group Degree Centrality and Centralization in NetworksJuliet Karapuz'No ratings yet
- UNIT - 1: Disjoint SETS: Equivalence RelationsDocument11 pagesUNIT - 1: Disjoint SETS: Equivalence RelationsGuna ShekarNo ratings yet
- 1 Uncertainty RelationDocument7 pages1 Uncertainty Relationranjana senguptaNo ratings yet
- Fcalc03 PPT 07Document90 pagesFcalc03 PPT 07Zeinab ElkholyNo ratings yet
- A Sandpile?: What I S - .Document4 pagesA Sandpile?: What I S - .Latoria BoyerNo ratings yet
- Lecture 19: Swinging From Up-Trees To Graphs: Today's AgendaDocument24 pagesLecture 19: Swinging From Up-Trees To Graphs: Today's AgendaSakura2709No ratings yet
- K-Means Clustering and Related Algorithms: Ryan P. AdamsDocument16 pagesK-Means Clustering and Related Algorithms: Ryan P. AdamsNafi SiamNo ratings yet
- 10Document4 pages10atikNo ratings yet
- Graphs: Slides by Kevin Wayne. All Rights ReservedDocument44 pagesGraphs: Slides by Kevin Wayne. All Rights Reservedalex tylerNo ratings yet
- Session7 8 GraphsDocument44 pagesSession7 8 Graphsalex tylerNo ratings yet
- Binary Search TreeDocument32 pagesBinary Search TreesenthilswamyNo ratings yet
- Ferraro Et Al (2019) - Fclust. An R Package For Fuzzy ClusteringDocument19 pagesFerraro Et Al (2019) - Fclust. An R Package For Fuzzy ClusteringLuciano BorgoglioNo ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document12 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- Parallel Union Find ReportDocument4 pagesParallel Union Find Reportlokesh guruNo ratings yet
- Generating Random Regular Graphs: J. H. Kim V. H. Vu August 9, 2006Document22 pagesGenerating Random Regular Graphs: J. H. Kim V. H. Vu August 9, 2006Feng Bill ShiNo ratings yet
- Neutron Transport EquationDocument9 pagesNeutron Transport EquationKhangBomNo ratings yet
- Graphs: 3.1 Basic Definitions and ApplicationsDocument12 pagesGraphs: 3.1 Basic Definitions and Applicationsanarki417No ratings yet
- Analyzing The K-Core Entropy of Word Co-Occurrence Networks: Applications To Cross-Linguistic ComparisonsDocument13 pagesAnalyzing The K-Core Entropy of Word Co-Occurrence Networks: Applications To Cross-Linguistic ComparisonsMaría Francisca Bórquez SiegelNo ratings yet
- Itamar Landau, Lionel Levine and Yuval Peres - Chip-Firing and Rotor-Routing On Z D and On TreesDocument12 pagesItamar Landau, Lionel Levine and Yuval Peres - Chip-Firing and Rotor-Routing On Z D and On TreesHemAO1No ratings yet
- Analysis of Algorithms: Algorithm Input OutputDocument44 pagesAnalysis of Algorithms: Algorithm Input OutputKeita AmanoNo ratings yet
- Hash Tables: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Document27 pagesHash Tables: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Keita AmanoNo ratings yet
- Heaps: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Document22 pagesHeaps: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Keita AmanoNo ratings yet
- AVL Trees: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Document14 pagesAVL Trees: Presentation For Use With The Textbook, by M. T. Goodrich and R. Tamassia, Wiley, 2015Keita AmanoNo ratings yet
- Nanomagnetism Principles, Nanostructures, and Biomedical ApplicationsDocument8 pagesNanomagnetism Principles, Nanostructures, and Biomedical ApplicationsHaposan YogaNo ratings yet
- MP3 DFPlayer Mini Module ENGDocument36 pagesMP3 DFPlayer Mini Module ENGmariguanixNo ratings yet
- T.Y.B.a. Economics (Credits) FinalDocument16 pagesT.Y.B.a. Economics (Credits) FinalsmitaNo ratings yet
- 1610-1620 SpecsDocument97 pages1610-1620 SpecsWilliam da Silva MarquesNo ratings yet
- B.tech (IT)Document57 pagesB.tech (IT)coolvar90No ratings yet
- DLL Grade 9 Math Q1 Week 5Document3 pagesDLL Grade 9 Math Q1 Week 5Cris JanNo ratings yet
- Rothoblaas - Alumidi Bracket With Holes - Item Specification - enDocument4 pagesRothoblaas - Alumidi Bracket With Holes - Item Specification - enAndrei GheorghicaNo ratings yet
- En Standards Protective ClothingDocument25 pagesEn Standards Protective Clothinglthyagu100% (1)
- N13072012 2Document85 pagesN13072012 2Ng Hock HengNo ratings yet
- Web Page Development Using HTMLDocument126 pagesWeb Page Development Using HTMLHussien MekonnenNo ratings yet
- Resume Nikhil DikshitDocument1 pageResume Nikhil DikshitNikhil DikshitNo ratings yet
- Steel GradesDocument8 pagesSteel GradesSanket Arun MoreNo ratings yet
- 4.fluid DynamicsDocument73 pages4.fluid Dynamicskrueg3rNo ratings yet
- Brake Friction MaterialsDocument2 pagesBrake Friction MaterialsAnoj pahathkumburaNo ratings yet
- CSE Curriculum - IIIT HyderabadDocument20 pagesCSE Curriculum - IIIT HyderabadSuperdudeGauravNo ratings yet
- Microchip - 125 KHZ RFID System Design Guide - 51115fDocument210 pagesMicrochip - 125 KHZ RFID System Design Guide - 51115fAnonymous 60esBJZIjNo ratings yet
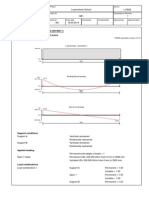
- RC Beam Analysis & Design (En1992-1) in Accordance With UK National AnnexDocument7 pagesRC Beam Analysis & Design (En1992-1) in Accordance With UK National Annexmishu_cojoNo ratings yet
- One Identity Manager Installation GuideDocument189 pagesOne Identity Manager Installation GuideUsman JavaidNo ratings yet
- Brosur Pipa JackingDocument1 pageBrosur Pipa JackingDavid SiburianNo ratings yet
- Seminar Report On ZigbeeDocument17 pagesSeminar Report On ZigbeeMansoor ChowdhuryNo ratings yet
- Three Moment Equation PaperDocument9 pagesThree Moment Equation PaperAkash SoodNo ratings yet
- Auto Drain ValveDocument2 pagesAuto Drain ValveRoopa MahtoNo ratings yet
- Log Gamma RayDocument6 pagesLog Gamma RayMuhammad Reza PahleviNo ratings yet
- Soft-Soil Const ModelDocument6 pagesSoft-Soil Const ModelicabullangueroNo ratings yet
- Lecture 4 Linear Programming Problem (Simplex Method)Document15 pagesLecture 4 Linear Programming Problem (Simplex Method)Akhilesh sagaNo ratings yet
- P6Document2 pagesP6Dimitri SaundersNo ratings yet
- Popl18 p202Document34 pagesPopl18 p202Obelix1789No ratings yet
- Practical Inorganic II EditedDocument163 pagesPractical Inorganic II EditedMosisa DugasaNo ratings yet