
Data Warehousing: Lecturer: Dr. Nguyen Thi Ngoc Anh
Data Warehousing: Lecturer: Dr. Nguyen Thi Ngoc Anh
You might also like
- Test Bank For Database Systems Introduction To Databases and Data Warehouses Nenad Jukic Susan Vrbsky Svetlozar NestorovDocument18 pagesTest Bank For Database Systems Introduction To Databases and Data Warehouses Nenad Jukic Susan Vrbsky Svetlozar Nestorovloriandersonbzrqxwnfym100% (32)
- Illustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions ManualDocument10 pagesIllustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions Manualfizzexponeo04xv0100% (26)
- Ivan Bayross Book PDFDocument39 pagesIvan Bayross Book PDFVivek Sharma21% (14)
- Data Mining: Concepts and Techniques: - Chapter 2Document62 pagesData Mining: Concepts and Techniques: - Chapter 2Jay ShahNo ratings yet
- 02datawarehousing For DMDocument38 pages02datawarehousing For DMhawariya abelNo ratings yet
- Data Warehousing and OLAP TechnologyDocument48 pagesData Warehousing and OLAP Technologyjrleriche9364100% (1)
- 04 Data WarehousingDocument32 pages04 Data WarehousingNashrah AnsariNo ratings yet
- Data Warehousing and OLAP TechnologyDocument49 pagesData Warehousing and OLAP TechnologyNitin ShelkeNo ratings yet
- What Is A Data Warehouse?Document58 pagesWhat Is A Data Warehouse?Maha LakshmiNo ratings yet
- 04OLAPDocument48 pages04OLAPnadirakhalid143No ratings yet
- What Is Data Warehouse?Document26 pagesWhat Is Data Warehouse?GODDU NAVVEN BABUNo ratings yet
- Concepts and Techniques: Data MiningDocument24 pagesConcepts and Techniques: Data MiningRahaf AhmadNo ratings yet
- Data Warehouse and OLAPDocument55 pagesData Warehouse and OLAProdrigolgnNo ratings yet
- DWM Unit-IVDocument27 pagesDWM Unit-IVnageshNo ratings yet
- Data Warehousing and OLAP TechnologyDocument51 pagesData Warehousing and OLAP Technologyanagha2982No ratings yet
- Datawarehouse NotesDocument39 pagesDatawarehouse Notescekexog892No ratings yet
- Slides For Textbook - Chapter 2Document64 pagesSlides For Textbook - Chapter 2de_ep_anNo ratings yet
- Unit - 3 Data Warehousing and OLAP TechnologyDocument20 pagesUnit - 3 Data Warehousing and OLAP TechnologyPagoti JyothirmayeNo ratings yet
- 04DWH & OlapDocument50 pages04DWH & Olaprm23082001No ratings yet
- Csb4318 DWDM Unit - 1 RevisedDocument68 pagesCsb4318 DWDM Unit - 1 RevisedDr. M. Kathiravan Assistant Professor III - CSENo ratings yet
- Chapter TwoDocument59 pagesChapter Twoaddis alemayhuNo ratings yet
- Chapter04 (DataWareHousing) - UpdatedDocument46 pagesChapter04 (DataWareHousing) - Updatedjozef jostarNo ratings yet
- Concepts and Techniques: Data MiningDocument66 pagesConcepts and Techniques: Data MiningHasibur Rahman PoragNo ratings yet
- Data Mining: Concepts and TechniquesDocument70 pagesData Mining: Concepts and TechniquessunnynnusNo ratings yet
- Data Mining:: Concepts and TechniquesDocument48 pagesData Mining:: Concepts and TechniquesVrushali Vilas BorleNo ratings yet
- 04OLAPDocument58 pages04OLAPSagar Chauhan100% (1)
- Concepts and Techniques: - Chapter 3Document73 pagesConcepts and Techniques: - Chapter 3mahendiranaNo ratings yet
- Data WarehouseDocument174 pagesData WarehouseDishant kumar yadav mhakhariyaNo ratings yet
- Concepts and Techniques: - Chapter 4Document58 pagesConcepts and Techniques: - Chapter 4shyamNo ratings yet
- 04OLAPDocument66 pages04OLAPgondaliyakinnari2906No ratings yet
- An Overview of Data Warehousing and OLAP Technology: Presented by Manish DesaiDocument17 pagesAn Overview of Data Warehousing and OLAP Technology: Presented by Manish Desaisaiteja1989No ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningXhy KatNo ratings yet
- DMChapter 2 - ForclassDocument58 pagesDMChapter 2 - ForclassPrasanna Kumar pandaNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data Miningchandrasekhar yerragandhulaNo ratings yet
- CS423 Data Warehousing and Data Mining: Dr. Hammad AfzalDocument25 pagesCS423 Data Warehousing and Data Mining: Dr. Hammad AfzalZafar IqbalNo ratings yet
- 04OLAPDocument35 pages04OLAPrafihassanNo ratings yet
- DWH MergedDocument388 pagesDWH MergedAbhishek GuptaNo ratings yet
- Data Warehousing: Data Warehouse and OLAP TechnologyDocument44 pagesData Warehousing: Data Warehouse and OLAP TechnologyReham RaafatNo ratings yet
- Data Warehouse OLAP OLTPDocument12 pagesData Warehouse OLAP OLTPShayan BalochNo ratings yet
- UNIT-1 Data Warehousing Part-IIIDocument68 pagesUNIT-1 Data Warehousing Part-IIIDeepak Varma22No ratings yet
- OlapDocument58 pagesOlapTowsif SalauddinNo ratings yet
- Data Warehousing and Data Mining - Unit2Document14 pagesData Warehousing and Data Mining - Unit2Shreedhar PangeniNo ratings yet
- Introduction To DWHDocument10 pagesIntroduction To DWHmubeen mushtaqNo ratings yet
- CSB4318 Datawarehousing and Data MiningDocument577 pagesCSB4318 Datawarehousing and Data MiningDr. M. Kathiravan Assistant Professor III - CSENo ratings yet
- Data War Eh PuseDocument51 pagesData War Eh PuseMuneeba HussainNo ratings yet
- Data Warehousing and OLAP Technology For Data Mining: - Chapter 3Document35 pagesData Warehousing and OLAP Technology For Data Mining: - Chapter 3biswanath dehuriNo ratings yet
- Concepts and Techniques: Data MiningDocument52 pagesConcepts and Techniques: Data MiningindiraNo ratings yet
- Concepts and Techniques: Data MiningDocument61 pagesConcepts and Techniques: Data MiningindiraNo ratings yet
- Ilovepdf MergedDocument47 pagesIlovepdf Mergedsubash pandayNo ratings yet
- Olp PDFDocument25 pagesOlp PDFGhaji AbalonNo ratings yet
- DM Part 2Document24 pagesDM Part 2madeehaNo ratings yet
- Iare DWDM PPT CseDocument249 pagesIare DWDM PPT CseSalmanNo ratings yet
- 2 DWDocument43 pages2 DWLevi AckermanNo ratings yet
- What Is A Data Warehouse?Document59 pagesWhat Is A Data Warehouse?Lakshmi PrashanthNo ratings yet
- 04OLAPDocument50 pages04OLAPsami hasanNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningbhargaviNo ratings yet
- 5 OlapDocument61 pages5 OlapMH PolashNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningSudhakar TripathiNo ratings yet
- CT075!3!2-DTM-Topic 7 - Data WarehouseDocument35 pagesCT075!3!2-DTM-Topic 7 - Data Warehousekishanselvarajah80No ratings yet
- Concepts and Techniques: Data MiningDocument55 pagesConcepts and Techniques: Data MiningSaumya PandaNo ratings yet
- Databases: System Concepts, Designs, Management, and ImplementationFrom EverandDatabases: System Concepts, Designs, Management, and ImplementationNo ratings yet
- PM2 ToolsDocument68 pagesPM2 ToolsThảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Mpi - (Cuuduongthancong - Com)Document33 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Mpi - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Pthreads - (Cuuduongthancong - Com)Document59 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Pthreads - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Openmp - (Cuuduongthancong - Com)Document61 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Openmp - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Text Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument27 pagesText Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- Time Series Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument11 pagesTime Series Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- Data Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument31 pagesData Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- 1 IntroductionDocument36 pages1 IntroductionThảo Nguyên TrầnNo ratings yet
- 2distributed File System DfsDocument21 pages2distributed File System DfsNUREDIN KEDIRNo ratings yet
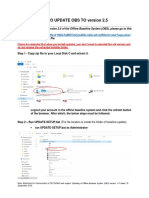
- Annex C How To Update Offline Baseline System v2.5 Update GuidelineDocument4 pagesAnnex C How To Update Offline Baseline System v2.5 Update GuidelineMohammad Sa-ad IndarNo ratings yet
- UG Even Sem Table 2021-2022Document1 pageUG Even Sem Table 2021-2022Anon writNo ratings yet
- Sap BW: Extraction and LoadingDocument3 pagesSap BW: Extraction and LoadingDeepu NyalakantiNo ratings yet
- OMG - Dbms - Mgwadm and Dbms - MGWMSG TipsDocument6 pagesOMG - Dbms - Mgwadm and Dbms - MGWMSG TipsNagaraj GuntiNo ratings yet
- Mysql SubqueryDocument19 pagesMysql Subqueryblob232No ratings yet
- Debugging Access Control in Websphere Commerce: Err - User - AuthorityDocument16 pagesDebugging Access Control in Websphere Commerce: Err - User - AuthorityAkhs SharmaNo ratings yet
- Hash Tables With ChainingDocument5 pagesHash Tables With ChainingJack MadNo ratings yet
- Oracle SQL Tuning For Developers Workshop - D73549GC10 - 1080544 - USDocument3 pagesOracle SQL Tuning For Developers Workshop - D73549GC10 - 1080544 - USJinendraabhiNo ratings yet
- Sap Supercluster DR WP Final3 5032000Document77 pagesSap Supercluster DR WP Final3 5032000manojNo ratings yet
- Business Intelligence INTRODocument45 pagesBusiness Intelligence INTROShivam MishraNo ratings yet
- Ds Netapp E2600 Storage SystemDocument4 pagesDs Netapp E2600 Storage Systemlkjsdfo9isda90j98nh394No ratings yet
- Made by Vince Midterm Exam (S.A D.D) Not For Sale: : AnswerDocument6 pagesMade by Vince Midterm Exam (S.A D.D) Not For Sale: : AnswerNathanielvince C OngNo ratings yet
- Honey Choudhary Mysql CH 14Document65 pagesHoney Choudhary Mysql CH 14Guddu ChaudharyNo ratings yet
- Data Structure For Text SequencesDocument29 pagesData Structure For Text SequencesTuo Chen PengNo ratings yet
- MemoryDocument87 pagesMemoryrajkumarNo ratings yet
- LogDocument5 pagesLogGabrielle Grace RiveraNo ratings yet
- Database Programming With SQL 1-2: Relational Database Technology Practice ActivitiesDocument2 pagesDatabase Programming With SQL 1-2: Relational Database Technology Practice Activitiesstenly940% (1)
- Linux RajDocument172 pagesLinux RajSahil Suri100% (1)
- Chapter 1 - Closing Case PDFDocument2 pagesChapter 1 - Closing Case PDFJohnny Abou YounesNo ratings yet
- KB1956 - EMC Data Domain Storage Best PracticesDocument2 pagesKB1956 - EMC Data Domain Storage Best PracticesDaniel BastosNo ratings yet
- 00001367-It-List of Practicals - XDocument2 pages00001367-It-List of Practicals - Xchirag242424jNo ratings yet
- 1403 Confio SQL Server Tuning Infographics 8 5x11Document1 page1403 Confio SQL Server Tuning Infographics 8 5x11Barry GhotraNo ratings yet
- Access Control Matrix and Confused DeputyDocument18 pagesAccess Control Matrix and Confused DeputyArun Anoop MNo ratings yet
- Module 1 - ITMDocument5 pagesModule 1 - ITMneenasukesh01No ratings yet
- Chapter 8 - Assignment - Marcellana, Ariel P. - BSA-31Document2 pagesChapter 8 - Assignment - Marcellana, Ariel P. - BSA-31Marcellana ArianeNo ratings yet
- HDDScan EngDocument24 pagesHDDScan EngEJ Corpuz SalvadorNo ratings yet

































































































Download as pdf or txt
You might also like
- Test Bank For Database Systems Introduction To Databases and Data Warehouses Nenad Jukic Susan Vrbsky Svetlozar NestorovDocument18 pagesTest Bank For Database Systems Introduction To Databases and Data Warehouses Nenad Jukic Susan Vrbsky Svetlozar Nestorovloriandersonbzrqxwnfym100% (32)
- Illustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions ManualDocument10 pagesIllustrated Course Guide Microsoft Office 365 and Access 2016 Intermediate Spiral Bound Version 1st Edition Friedrichsen Solutions Manualfizzexponeo04xv0100% (26)
- Ivan Bayross Book PDFDocument39 pagesIvan Bayross Book PDFVivek Sharma21% (14)
- Data Mining: Concepts and Techniques: - Chapter 2Document62 pagesData Mining: Concepts and Techniques: - Chapter 2Jay ShahNo ratings yet
- 02datawarehousing For DMDocument38 pages02datawarehousing For DMhawariya abelNo ratings yet
- Data Warehousing and OLAP TechnologyDocument48 pagesData Warehousing and OLAP Technologyjrleriche9364100% (1)
- 04 Data WarehousingDocument32 pages04 Data WarehousingNashrah AnsariNo ratings yet
- Data Warehousing and OLAP TechnologyDocument49 pagesData Warehousing and OLAP TechnologyNitin ShelkeNo ratings yet
- What Is A Data Warehouse?Document58 pagesWhat Is A Data Warehouse?Maha LakshmiNo ratings yet
- 04OLAPDocument48 pages04OLAPnadirakhalid143No ratings yet
- What Is Data Warehouse?Document26 pagesWhat Is Data Warehouse?GODDU NAVVEN BABUNo ratings yet
- Concepts and Techniques: Data MiningDocument24 pagesConcepts and Techniques: Data MiningRahaf AhmadNo ratings yet
- Data Warehouse and OLAPDocument55 pagesData Warehouse and OLAProdrigolgnNo ratings yet
- DWM Unit-IVDocument27 pagesDWM Unit-IVnageshNo ratings yet
- Data Warehousing and OLAP TechnologyDocument51 pagesData Warehousing and OLAP Technologyanagha2982No ratings yet
- Datawarehouse NotesDocument39 pagesDatawarehouse Notescekexog892No ratings yet
- Slides For Textbook - Chapter 2Document64 pagesSlides For Textbook - Chapter 2de_ep_anNo ratings yet
- Unit - 3 Data Warehousing and OLAP TechnologyDocument20 pagesUnit - 3 Data Warehousing and OLAP TechnologyPagoti JyothirmayeNo ratings yet
- 04DWH & OlapDocument50 pages04DWH & Olaprm23082001No ratings yet
- Csb4318 DWDM Unit - 1 RevisedDocument68 pagesCsb4318 DWDM Unit - 1 RevisedDr. M. Kathiravan Assistant Professor III - CSENo ratings yet
- Chapter TwoDocument59 pagesChapter Twoaddis alemayhuNo ratings yet
- Chapter04 (DataWareHousing) - UpdatedDocument46 pagesChapter04 (DataWareHousing) - Updatedjozef jostarNo ratings yet
- Concepts and Techniques: Data MiningDocument66 pagesConcepts and Techniques: Data MiningHasibur Rahman PoragNo ratings yet
- Data Mining: Concepts and TechniquesDocument70 pagesData Mining: Concepts and TechniquessunnynnusNo ratings yet
- Data Mining:: Concepts and TechniquesDocument48 pagesData Mining:: Concepts and TechniquesVrushali Vilas BorleNo ratings yet
- 04OLAPDocument58 pages04OLAPSagar Chauhan100% (1)
- Concepts and Techniques: - Chapter 3Document73 pagesConcepts and Techniques: - Chapter 3mahendiranaNo ratings yet
- Data WarehouseDocument174 pagesData WarehouseDishant kumar yadav mhakhariyaNo ratings yet
- Concepts and Techniques: - Chapter 4Document58 pagesConcepts and Techniques: - Chapter 4shyamNo ratings yet
- 04OLAPDocument66 pages04OLAPgondaliyakinnari2906No ratings yet
- An Overview of Data Warehousing and OLAP Technology: Presented by Manish DesaiDocument17 pagesAn Overview of Data Warehousing and OLAP Technology: Presented by Manish Desaisaiteja1989No ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningXhy KatNo ratings yet
- DMChapter 2 - ForclassDocument58 pagesDMChapter 2 - ForclassPrasanna Kumar pandaNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data Miningchandrasekhar yerragandhulaNo ratings yet
- CS423 Data Warehousing and Data Mining: Dr. Hammad AfzalDocument25 pagesCS423 Data Warehousing and Data Mining: Dr. Hammad AfzalZafar IqbalNo ratings yet
- 04OLAPDocument35 pages04OLAPrafihassanNo ratings yet
- DWH MergedDocument388 pagesDWH MergedAbhishek GuptaNo ratings yet
- Data Warehousing: Data Warehouse and OLAP TechnologyDocument44 pagesData Warehousing: Data Warehouse and OLAP TechnologyReham RaafatNo ratings yet
- Data Warehouse OLAP OLTPDocument12 pagesData Warehouse OLAP OLTPShayan BalochNo ratings yet
- UNIT-1 Data Warehousing Part-IIIDocument68 pagesUNIT-1 Data Warehousing Part-IIIDeepak Varma22No ratings yet
- OlapDocument58 pagesOlapTowsif SalauddinNo ratings yet
- Data Warehousing and Data Mining - Unit2Document14 pagesData Warehousing and Data Mining - Unit2Shreedhar PangeniNo ratings yet
- Introduction To DWHDocument10 pagesIntroduction To DWHmubeen mushtaqNo ratings yet
- CSB4318 Datawarehousing and Data MiningDocument577 pagesCSB4318 Datawarehousing and Data MiningDr. M. Kathiravan Assistant Professor III - CSENo ratings yet
- Data War Eh PuseDocument51 pagesData War Eh PuseMuneeba HussainNo ratings yet
- Data Warehousing and OLAP Technology For Data Mining: - Chapter 3Document35 pagesData Warehousing and OLAP Technology For Data Mining: - Chapter 3biswanath dehuriNo ratings yet
- Concepts and Techniques: Data MiningDocument52 pagesConcepts and Techniques: Data MiningindiraNo ratings yet
- Concepts and Techniques: Data MiningDocument61 pagesConcepts and Techniques: Data MiningindiraNo ratings yet
- Ilovepdf MergedDocument47 pagesIlovepdf Mergedsubash pandayNo ratings yet
- Olp PDFDocument25 pagesOlp PDFGhaji AbalonNo ratings yet
- DM Part 2Document24 pagesDM Part 2madeehaNo ratings yet
- Iare DWDM PPT CseDocument249 pagesIare DWDM PPT CseSalmanNo ratings yet
- 2 DWDocument43 pages2 DWLevi AckermanNo ratings yet
- What Is A Data Warehouse?Document59 pagesWhat Is A Data Warehouse?Lakshmi PrashanthNo ratings yet
- 04OLAPDocument50 pages04OLAPsami hasanNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningbhargaviNo ratings yet
- 5 OlapDocument61 pages5 OlapMH PolashNo ratings yet
- Concepts and Techniques: Data MiningDocument58 pagesConcepts and Techniques: Data MiningSudhakar TripathiNo ratings yet
- CT075!3!2-DTM-Topic 7 - Data WarehouseDocument35 pagesCT075!3!2-DTM-Topic 7 - Data Warehousekishanselvarajah80No ratings yet
- Concepts and Techniques: Data MiningDocument55 pagesConcepts and Techniques: Data MiningSaumya PandaNo ratings yet
- Databases: System Concepts, Designs, Management, and ImplementationFrom EverandDatabases: System Concepts, Designs, Management, and ImplementationNo ratings yet
- PM2 ToolsDocument68 pagesPM2 ToolsThảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Mpi - (Cuuduongthancong - Com)Document33 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Mpi - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Pthreads - (Cuuduongthancong - Com)Document59 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Pthreads - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Lap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Openmp - (Cuuduongthancong - Com)Document61 pagesLap-Trinh-Song-Song - Pham-Quang-Dung - Chapter-Openmp - (Cuuduongthancong - Com)Thảo Nguyên TrầnNo ratings yet
- Text Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument27 pagesText Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- Time Series Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument11 pagesTime Series Mining: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- Data Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument31 pagesData Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- 1 IntroductionDocument36 pages1 IntroductionThảo Nguyên TrầnNo ratings yet
- 2distributed File System DfsDocument21 pages2distributed File System DfsNUREDIN KEDIRNo ratings yet
- Annex C How To Update Offline Baseline System v2.5 Update GuidelineDocument4 pagesAnnex C How To Update Offline Baseline System v2.5 Update GuidelineMohammad Sa-ad IndarNo ratings yet
- UG Even Sem Table 2021-2022Document1 pageUG Even Sem Table 2021-2022Anon writNo ratings yet
- Sap BW: Extraction and LoadingDocument3 pagesSap BW: Extraction and LoadingDeepu NyalakantiNo ratings yet
- OMG - Dbms - Mgwadm and Dbms - MGWMSG TipsDocument6 pagesOMG - Dbms - Mgwadm and Dbms - MGWMSG TipsNagaraj GuntiNo ratings yet
- Mysql SubqueryDocument19 pagesMysql Subqueryblob232No ratings yet
- Debugging Access Control in Websphere Commerce: Err - User - AuthorityDocument16 pagesDebugging Access Control in Websphere Commerce: Err - User - AuthorityAkhs SharmaNo ratings yet
- Hash Tables With ChainingDocument5 pagesHash Tables With ChainingJack MadNo ratings yet
- Oracle SQL Tuning For Developers Workshop - D73549GC10 - 1080544 - USDocument3 pagesOracle SQL Tuning For Developers Workshop - D73549GC10 - 1080544 - USJinendraabhiNo ratings yet
- Sap Supercluster DR WP Final3 5032000Document77 pagesSap Supercluster DR WP Final3 5032000manojNo ratings yet
- Business Intelligence INTRODocument45 pagesBusiness Intelligence INTROShivam MishraNo ratings yet
- Ds Netapp E2600 Storage SystemDocument4 pagesDs Netapp E2600 Storage Systemlkjsdfo9isda90j98nh394No ratings yet
- Made by Vince Midterm Exam (S.A D.D) Not For Sale: : AnswerDocument6 pagesMade by Vince Midterm Exam (S.A D.D) Not For Sale: : AnswerNathanielvince C OngNo ratings yet
- Honey Choudhary Mysql CH 14Document65 pagesHoney Choudhary Mysql CH 14Guddu ChaudharyNo ratings yet
- Data Structure For Text SequencesDocument29 pagesData Structure For Text SequencesTuo Chen PengNo ratings yet
- MemoryDocument87 pagesMemoryrajkumarNo ratings yet
- LogDocument5 pagesLogGabrielle Grace RiveraNo ratings yet
- Database Programming With SQL 1-2: Relational Database Technology Practice ActivitiesDocument2 pagesDatabase Programming With SQL 1-2: Relational Database Technology Practice Activitiesstenly940% (1)
- Linux RajDocument172 pagesLinux RajSahil Suri100% (1)
- Chapter 1 - Closing Case PDFDocument2 pagesChapter 1 - Closing Case PDFJohnny Abou YounesNo ratings yet
- KB1956 - EMC Data Domain Storage Best PracticesDocument2 pagesKB1956 - EMC Data Domain Storage Best PracticesDaniel BastosNo ratings yet
- 00001367-It-List of Practicals - XDocument2 pages00001367-It-List of Practicals - Xchirag242424jNo ratings yet
- 1403 Confio SQL Server Tuning Infographics 8 5x11Document1 page1403 Confio SQL Server Tuning Infographics 8 5x11Barry GhotraNo ratings yet
- Access Control Matrix and Confused DeputyDocument18 pagesAccess Control Matrix and Confused DeputyArun Anoop MNo ratings yet
- Module 1 - ITMDocument5 pagesModule 1 - ITMneenasukesh01No ratings yet
- Chapter 8 - Assignment - Marcellana, Ariel P. - BSA-31Document2 pagesChapter 8 - Assignment - Marcellana, Ariel P. - BSA-31Marcellana ArianeNo ratings yet
- HDDScan EngDocument24 pagesHDDScan EngEJ Corpuz SalvadorNo ratings yet