Download as pdf or txt
You might also like
- CHAPTER 4 Measure of DispersionDocument76 pagesCHAPTER 4 Measure of DispersionAyushi JangpangiNo ratings yet
- Statistics & Molecular MRCP1Document87 pagesStatistics & Molecular MRCP1Raouf Ra'fat Soliman100% (2)
- File Based Item Import For Non-PIM Cloud Customers - Rel 11Document30 pagesFile Based Item Import For Non-PIM Cloud Customers - Rel 11ranvijay100% (1)
- LabModule - Exploratory Data Analysis - 2023icDocument24 pagesLabModule - Exploratory Data Analysis - 2023icFiola NurhalizaNo ratings yet
- Define StatisticsDocument89 pagesDefine StatisticskhanjiNo ratings yet
- Define StatisticsDocument89 pagesDefine StatisticskhanjiNo ratings yet
- Descriptive Statistics and Normality Tests For Statistical DataDocument13 pagesDescriptive Statistics and Normality Tests For Statistical DataVictoriaNo ratings yet
- Measures of Dispersion-Range: BiostatisticsDocument11 pagesMeasures of Dispersion-Range: BiostatisticsponnasaikumarNo ratings yet
- Letter For ExemptionDocument9 pagesLetter For ExemptionJean NjeruNo ratings yet
- ADIGRAT UNIVERSITY Bass NewDocument8 pagesADIGRAT UNIVERSITY Bass Newmebrahtuhadush3No ratings yet
- 10.1007@s00296 020 04740 ZDocument13 pages10.1007@s00296 020 04740 ZLuis LuengoNo ratings yet
- BRM Unit-1Document25 pagesBRM Unit-1K R SAI LAKSHMINo ratings yet
- Statistics Chapter 4 Notes Section 4.1 Designing Studies: Definition: Population and SampleDocument6 pagesStatistics Chapter 4 Notes Section 4.1 Designing Studies: Definition: Population and Samplesharmanator99No ratings yet
- Basic Statistical Tools in Research and Data AnalysisDocument19 pagesBasic Statistical Tools in Research and Data AnalysisHermit XTNo ratings yet
- Wolcottetal 2018StatisticalInference EncyclopediaofEcology2ndEditionDocument8 pagesWolcottetal 2018StatisticalInference EncyclopediaofEcology2ndEditionfaizaNo ratings yet
- Meta-Analysis of Screening and Diagnostic TestsDocument12 pagesMeta-Analysis of Screening and Diagnostic TestsLaurens KramerNo ratings yet
- Revisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationDocument14 pagesRevisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationlacisagNo ratings yet
- Application of Statistical Concepts in The Determination of Weight Variation in SamplesDocument2 pagesApplication of Statistical Concepts in The Determination of Weight Variation in SamplesCharlette InaoNo ratings yet
- Standard Error and DeviationDocument1 pageStandard Error and DeviationM Kamran RajaNo ratings yet
- Application of Statistical Concepts in The Determination of Weight Variation in Coin SamplesDocument2 pagesApplication of Statistical Concepts in The Determination of Weight Variation in Coin SamplesEXO SVTNo ratings yet
- Profed 10Document4 pagesProfed 10Junel SildoNo ratings yet
- Colegio de Dagupan: Master of EducationDocument3 pagesColegio de Dagupan: Master of Educationthea margareth martinezNo ratings yet
- ZGE1104 Chapter 4Document7 pagesZGE1104 Chapter 4Mae RocelleNo ratings yet
- Research Techniques - Reference Notes: HypothesisDocument6 pagesResearch Techniques - Reference Notes: HypothesisHarshitBabooNo ratings yet
- Research Methodology: Week 9 October 11-15, 2021Document57 pagesResearch Methodology: Week 9 October 11-15, 2021Catherine BandolonNo ratings yet
- Application of Statistical Concepts in The Determination of Weight Variation in Coin SamplesDocument2 pagesApplication of Statistical Concepts in The Determination of Weight Variation in Coin SamplesZyrle Nikko UchidaNo ratings yet
- Expe FinalsDocument8 pagesExpe FinalsAirame Dela RosaNo ratings yet
- Week 1 ProbDocument31 pagesWeek 1 ProbIslam TokoevNo ratings yet
- Python Unit-4Document24 pagesPython Unit-4sainiranjan2005No ratings yet
- STATISTICSDocument2 pagesSTATISTICSIrine BrionesNo ratings yet
- The Cost of Dichotomising Continuous VariablesDocument1 pageThe Cost of Dichotomising Continuous VariablesLakshmi SethNo ratings yet
- 2 Statistical Theory and Methods: Measures of Central Tendency (Averages)Document4 pages2 Statistical Theory and Methods: Measures of Central Tendency (Averages)TinNo ratings yet
- Measures of Variabilit1Document7 pagesMeasures of Variabilit1Ken EncisoNo ratings yet
- Bio-Statistics and RD Lecture NoteDocument176 pagesBio-Statistics and RD Lecture NotefayanNo ratings yet
- 2012 - Dawson - Dichotomizing Continuous Variables in Statistical Analysis - A Practice To AvoidDocument2 pages2012 - Dawson - Dichotomizing Continuous Variables in Statistical Analysis - A Practice To AvoidAbdul HadiNo ratings yet
- Key Words: Basic Statistical Tools, Degree of Dispersion, Measures of Central Tendency, Parametric Tests andDocument16 pagesKey Words: Basic Statistical Tools, Degree of Dispersion, Measures of Central Tendency, Parametric Tests andchitraNo ratings yet
- VAN MHUTE - Research MethodsDocument3 pagesVAN MHUTE - Research Methodsvalentine mhuteNo ratings yet
- Biostatistics 2Document4 pagesBiostatistics 2mcpaulfreemanNo ratings yet
- Advancedstatistics 130526200328 Phpapp02Document91 pagesAdvancedstatistics 130526200328 Phpapp02Gerry Makilan100% (1)
- Mean, Median, Mode and Standard DeviationDocument42 pagesMean, Median, Mode and Standard DeviationTanu ShreyaNo ratings yet
- Activity 1 - FinalsDocument2 pagesActivity 1 - FinalsCalebjosiah GetubigNo ratings yet
- PED-6 Joebert AciertoDocument4 pagesPED-6 Joebert AciertoJoebert AciertoNo ratings yet
- Statistical Dispersion - WikipediaDocument3 pagesStatistical Dispersion - Wikipediakirthi83No ratings yet
- BIOSTATISTICSDocument52 pagesBIOSTATISTICSbelachew meleseNo ratings yet
- Basic Biostatistics For Post-Graduate Students: Educational ForumDocument9 pagesBasic Biostatistics For Post-Graduate Students: Educational ForumSuryaprakash Reddy ChappidiNo ratings yet
- Descriptive Research Embraces A Large Proportion of Research. It Is Preplanned and Structured in DesignDocument6 pagesDescriptive Research Embraces A Large Proportion of Research. It Is Preplanned and Structured in DesigncelNo ratings yet
- 12 Evidence Based Period Ontology Systematic ReviewsDocument17 pages12 Evidence Based Period Ontology Systematic ReviewsAparna PandeyNo ratings yet
- Sonia Khondakar - Data Analytics - BBA 504 (A)Document13 pagesSonia Khondakar - Data Analytics - BBA 504 (A)Avik SamantaNo ratings yet
- CHAPTER 4 Measure of DispersionDocument76 pagesCHAPTER 4 Measure of DispersionAyushi JangpangiNo ratings yet
- Main Point List - Lec3Document2 pagesMain Point List - Lec3Hương DiệuNo ratings yet
- Madam SubjectDocument3 pagesMadam Subjectkasi FNo ratings yet
- Characterizing Measurements and Results: Level 2 Analytical Chemistry 2020/2021Document9 pagesCharacterizing Measurements and Results: Level 2 Analytical Chemistry 2020/2021bobby la fleurNo ratings yet
- Leys MAD Final-LibreDocument3 pagesLeys MAD Final-LibreJorgeTrabajoNo ratings yet
- Quantitative Method CP 102Document5 pagesQuantitative Method CP 102Prittam Kumar JenaNo ratings yet
- Chem LabDocument2 pagesChem LabMicaella Unique DoradoNo ratings yet
- Measures of Central Tendency Median and ModeDocument2 pagesMeasures of Central Tendency Median and Modesyeda fizza shoaib zaidiNo ratings yet
- Measures of Central Tendency Median and ModeDocument2 pagesMeasures of Central Tendency Median and ModeShubham NamdevNo ratings yet
- Chapter Exercises:: Chapter 5:utilization of Assessment DataDocument6 pagesChapter Exercises:: Chapter 5:utilization of Assessment DataJessa Mae CantilloNo ratings yet
- Which Measure of Central Tendency To UseDocument8 pagesWhich Measure of Central Tendency To UseSyah MiNo ratings yet
- Biostatistics Explored Through R Software: An OverviewFrom EverandBiostatistics Explored Through R Software: An OverviewRating: 3.5 out of 5 stars3.5/5 (2)
- 1 Management Theories and PracticesDocument96 pages1 Management Theories and PracticesAsegid H/meskelNo ratings yet
- The Featinian Issue 2 2011-2012Document12 pagesThe Featinian Issue 2 2011-2012Saxs Gabrielle Peralta SantosNo ratings yet
- Multimode Relay MT: 2 / 3 Pole 10 A, DC-or AC-coilDocument4 pagesMultimode Relay MT: 2 / 3 Pole 10 A, DC-or AC-coilgoo gleNo ratings yet
- AJODO-90 Petrovic Et Al Role of The Lateral Pterigoid Muscle and Menisco Temporomandibular...Document12 pagesAJODO-90 Petrovic Et Al Role of The Lateral Pterigoid Muscle and Menisco Temporomandibular...ortodoncia 2018No ratings yet
- Written Theory Sample12Document1 pageWritten Theory Sample12John SmithNo ratings yet
- Unit 3 - Cyclic Code MCQDocument6 pagesUnit 3 - Cyclic Code MCQShubhamNo ratings yet
- Semi-Detailed Lesson Plan: Teacher: Blessie Jean A. YbañezDocument3 pagesSemi-Detailed Lesson Plan: Teacher: Blessie Jean A. YbañezJENNIFER YBAÑEZNo ratings yet
- MLOG GX CMXA75 v4 0 322985a0 UM-ENDocument311 pagesMLOG GX CMXA75 v4 0 322985a0 UM-ENjamiekuangNo ratings yet
- TATA MOTORS STP AnalysisDocument7 pagesTATA MOTORS STP AnalysisBharat RachuriNo ratings yet
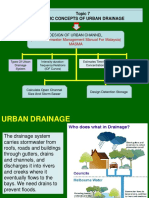
- Topic 7 Basic Concepts of Urban Drainage: (Urban Stormwater Management Manual For Malaysia) MasmaDocument29 pagesTopic 7 Basic Concepts of Urban Drainage: (Urban Stormwater Management Manual For Malaysia) MasmaAzhar SabriNo ratings yet
- GeoseaDocument9 pagesGeoseaArthur WakashimasuNo ratings yet
- Historical Antecedents That Changed The Course of Science and TechnologyDocument57 pagesHistorical Antecedents That Changed The Course of Science and TechnologyJennypee MadrinaNo ratings yet
- Medium Power Film Capacitor AvxDocument70 pagesMedium Power Film Capacitor AvxPeio GilNo ratings yet
- Quantum Tunneling and Spin 14Document14 pagesQuantum Tunneling and Spin 14plfratarNo ratings yet
- VR8304 Intermittent Pilot Combination Gas Control: ApplicationDocument8 pagesVR8304 Intermittent Pilot Combination Gas Control: ApplicationGregorio Mata MartínezNo ratings yet
- HelicoptersDocument11 pagesHelicoptersJordan MosesNo ratings yet
- Mehfill MenuDocument6 pagesMehfill Menuutkarsh shrivastavaNo ratings yet
- Food Truck PresentationDocument17 pagesFood Truck Presentationapi-218589673No ratings yet
- Cost Audit RepairDocument7 pagesCost Audit RepairkayseNo ratings yet
- Method Statement Ceiling RemovalDocument7 pagesMethod Statement Ceiling RemovalSimpol MathNo ratings yet
- CGL PRE 2023 English All SetsDocument314 pagesCGL PRE 2023 English All Setskumarmohit0203No ratings yet
- Cleopatra Wall Tiles CatalogueDocument151 pagesCleopatra Wall Tiles CatalogueHussain ElarabiNo ratings yet
- History: The History of The Hospitality Industry Dates All The WayDocument10 pagesHistory: The History of The Hospitality Industry Dates All The WaySAKET TYAGINo ratings yet
- Key Performance IndicatorsDocument27 pagesKey Performance IndicatorsZiad NayyerNo ratings yet
- NV10 TRB 3.3Document234 pagesNV10 TRB 3.3Juan perezNo ratings yet
- Kristian M. Dinapo: ObjectiveDocument2 pagesKristian M. Dinapo: ObjectiveX.oFlawlesso.XNo ratings yet
- Exadata and Database Machine Administration Workshop PDFDocument316 pagesExadata and Database Machine Administration Workshop PDFusman newtonNo ratings yet
- 2018-2 TechPresentation BallDocument52 pages2018-2 TechPresentation BallAmar SheteNo ratings yet
- Soalan Psikologi Pengujian Dan PengukuranDocument11 pagesSoalan Psikologi Pengujian Dan PengukuranmisxcheaNo ratings yet