Download as pdf or txt
You might also like
- Interactive Dashboards and Data Apps With Plotly and DashDocument362 pagesInteractive Dashboards and Data Apps With Plotly and DashNishna Ajmal89% (9)
- Effective PandasDocument20 pagesEffective PandasRonan Freire Gois50% (2)
- Data Science From Scratch, 2nd EditionDocument72 pagesData Science From Scratch, 2nd EditionAhmed HusseinNo ratings yet
- IKEA Case StudyDocument12 pagesIKEA Case StudyAmrit Prasad0% (1)
- Introduction To Machine Learning With Python: A Guide For Data Scientists - Andreas C. MüllerDocument4 pagesIntroduction To Machine Learning With Python: A Guide For Data Scientists - Andreas C. Müllerhipiwatu0% (7)
- 2020 Practical Statistics For Data Scientists - 50+ Essential Concepts Using R and O'Reilly MediaDocument363 pages2020 Practical Statistics For Data Scientists - 50+ Essential Concepts Using R and O'Reilly MediaRaghavendran100% (18)
- R in Action, Second EditionDocument2 pagesR in Action, Second EditionDreamtech Press0% (1)
- Practical Text Mining and Statistical Analysis for Non-structured Text Data ApplicationsFrom EverandPractical Text Mining and Statistical Analysis for Non-structured Text Data ApplicationsRating: 5 out of 5 stars5/5 (1)
- 02.06 Module Two ProjectDocument5 pages02.06 Module Two ProjectBob SmithNo ratings yet
- Python Data Science Handbook: Essential Tools For Working With Data - Jake VanderPlasDocument4 pagesPython Data Science Handbook: Essential Tools For Working With Data - Jake VanderPlasgytucaji14% (7)
- Python Social Media Analytics - Analyze and Visualize Data From Twitter, Youtube, GitHub, and More PDFDocument307 pagesPython Social Media Analytics - Analyze and Visualize Data From Twitter, Youtube, GitHub, and More PDFOSHIN MALVIYANo ratings yet
- Beyond Spreadsheets R PDFDocument470 pagesBeyond Spreadsheets R PDFGowri PonprakashNo ratings yet
- OReilly Learning Python 4th Edition Oct 2009Document1,214 pagesOReilly Learning Python 4th Edition Oct 2009Siyoung Byun100% (16)
- Hands-On Programming With R: Write Your Own Functions and Simulations - Garrett GrolemundDocument4 pagesHands-On Programming With R: Write Your Own Functions and Simulations - Garrett Grolemundxytejeje100% (1)
- R Machine Learning PDFDocument137 pagesR Machine Learning PDFAnonymous NoermyAEpdNo ratings yet
- Java Data Mining: Strategy, Standard, and Practice: A Practical Guide for Architecture, Design, and ImplementationFrom EverandJava Data Mining: Strategy, Standard, and Practice: A Practical Guide for Architecture, Design, and ImplementationRating: 5 out of 5 stars5/5 (1)
- D3 Tips and Tricks PDFDocument497 pagesD3 Tips and Tricks PDFSanjayNo ratings yet
- R in Action: Data Analysis and Graphics With R - Internet, Groupware, & TelecommunicationsDocument6 pagesR in Action: Data Analysis and Graphics With R - Internet, Groupware, & TelecommunicationsxizenokaNo ratings yet
- Python Data Analytics: With Pandas, NumPy, and MatplotlibFrom EverandPython Data Analytics: With Pandas, NumPy, and MatplotlibRating: 2 out of 5 stars2/5 (1)
- Programming Python: Powerful Object-Oriented Programming - Mark LutzDocument4 pagesProgramming Python: Powerful Object-Oriented Programming - Mark Lutzsitoweda0% (2)
- Ultimate Neural Network Programming with Python: Create Powerful Modern AI Systems by Harnessing Neural Networks with Python, Keras, and TensorFlowFrom EverandUltimate Neural Network Programming with Python: Create Powerful Modern AI Systems by Harnessing Neural Networks with Python, Keras, and TensorFlowNo ratings yet
- Database Reliability Engineering: Designing and Operating Resilient Database Systems - Laine CampbellDocument4 pagesDatabase Reliability Engineering: Designing and Operating Resilient Database Systems - Laine CampbellkypezeriNo ratings yet
- Thoughtful Machine Learning With: PythonDocument216 pagesThoughtful Machine Learning With: Pythonrajagopalan19No ratings yet
- Think Python: How To Think Like A Computer Scientist - Allen B. DowneyDocument4 pagesThink Python: How To Think Like A Computer Scientist - Allen B. Downeyzykihiza0% (1)
- R Studio Cheat SheetDocument30 pagesR Studio Cheat Sheetanon_393044353100% (1)
- Michael Grogan - Python Vs R For Data Science-O'Reilly Media (2018)Document14 pagesMichael Grogan - Python Vs R For Data Science-O'Reilly Media (2018)sebastian gonzalesNo ratings yet
- XML Processing With PythonDocument447 pagesXML Processing With Pythonpjf54100% (1)
- Think Stats: Probability and Statistics For ProgrammersDocument140 pagesThink Stats: Probability and Statistics For ProgrammersIka KristinNo ratings yet
- Scientific Computing With Scala - Sample ChapterDocument33 pagesScientific Computing With Scala - Sample ChapterPackt PublishingNo ratings yet
- Practical Data Science With RDocument1 pagePractical Data Science With RDreamtech Press33% (3)
- The Art of R Programming - Norman MatloffDocument4 pagesThe Art of R Programming - Norman Matlofftenumesu0% (1)
- PyTorch Cookbook: 100+ Solutions across RNNs, CNNs, python tools, distributed training and graph networksFrom EverandPyTorch Cookbook: 100+ Solutions across RNNs, CNNs, python tools, distributed training and graph networksNo ratings yet
- Sigmod278 SilbersteinDocument12 pagesSigmod278 SilbersteinDmytro ShteflyukNo ratings yet
- Getting Data Science Done: Managing Projects From Ideas to ProductsFrom EverandGetting Data Science Done: Managing Projects From Ideas to ProductsNo ratings yet
- Data Analyst (1) (11168)Document399 pagesData Analyst (1) (11168)Dương Đình PhướcNo ratings yet
- Learn Ruby The Hard Way (Part 2)Document6 pagesLearn Ruby The Hard Way (Part 2)irohaNo ratings yet
- Practitioner’s Guide to Data Science: Streamlining Data Science Solutions using Python, Scikit-Learn, and Azure ML Service PlatformFrom EverandPractitioner’s Guide to Data Science: Streamlining Data Science Solutions using Python, Scikit-Learn, and Azure ML Service PlatformNo ratings yet
- The Absolutely Best Books For PyQt5 BeginnersDocument2 pagesThe Absolutely Best Books For PyQt5 BeginnersSamuel EffiongNo ratings yet
- Knowledge Graphs Data in Context ResponsiveDocument87 pagesKnowledge Graphs Data in Context ResponsiveTareq Salim100% (2)
- Datos CategóricosDocument451 pagesDatos Categóricoslaura melissa100% (1)
- State-of-the-Art Deep Learning Models in TensorFlow: Modern Machine Learning in the Google Colab EcosystemFrom EverandState-of-the-Art Deep Learning Models in TensorFlow: Modern Machine Learning in the Google Colab EcosystemNo ratings yet
- Python For Data Analysis - The Ultimate Beginner's Guide To Learn Programming in Python For Data Science With Pandas and NumPy, Master Statistical Analysis, and Visualization (2020)Document109 pagesPython For Data Analysis - The Ultimate Beginner's Guide To Learn Programming in Python For Data Science With Pandas and NumPy, Master Statistical Analysis, and Visualization (2020)Sudeshna NaskarNo ratings yet
- Andrew Troelsen - Pro C# 5.0 and The .NET 4.5 Framework - 2013Document1,310 pagesAndrew Troelsen - Pro C# 5.0 and The .NET 4.5 Framework - 2013Sergiu PanicoNo ratings yet
- Creating High-Quality Code: Hoa NguyenDocument95 pagesCreating High-Quality Code: Hoa NguyenHoa Nguyen100% (1)
- Experimentation for Engineers: From A/B testing to Bayesian optimizationFrom EverandExperimentation for Engineers: From A/B testing to Bayesian optimizationNo ratings yet
- Hadoop: The Definitive Guide: Storage and Analysis at Internet Scale - Tom WhiteDocument4 pagesHadoop: The Definitive Guide: Storage and Analysis at Internet Scale - Tom Whiteryfyceji0% (1)
- Practical Data Analysis Cookbook - Sample ChapterDocument31 pagesPractical Data Analysis Cookbook - Sample ChapterPackt Publishing100% (1)
- Laravel 5.1 Beauty - Creating Beautiful Web Apps With Laravel 5.1 PDFDocument247 pagesLaravel 5.1 Beauty - Creating Beautiful Web Apps With Laravel 5.1 PDFTulusNo ratings yet
- Python Data Visualization Essentials Guide: Become a Data Visualization expert by building strong proficiency in Pandas, Matplotlib, Seaborn, Plotly, Numpy, and BokehFrom EverandPython Data Visualization Essentials Guide: Become a Data Visualization expert by building strong proficiency in Pandas, Matplotlib, Seaborn, Plotly, Numpy, and BokehNo ratings yet
- Guerrilla Analytics: A Practical Approach to Working with DataFrom EverandGuerrilla Analytics: A Practical Approach to Working with DataRating: 4.5 out of 5 stars4.5/5 (1)
- Append (X) A (Len (A) :) (X) : A A A ADocument5 pagesAppend (X) A (Len (A) :) (X) : A A A AshanmugapriyaaNo ratings yet
- The Bermuda Triangle (A Mystery) : BY: D.Shanmugapriyaa Msc-Data ScienceDocument14 pagesThe Bermuda Triangle (A Mystery) : BY: D.Shanmugapriyaa Msc-Data ScienceshanmugapriyaaNo ratings yet
- Digital Electronics AssignmentDocument22 pagesDigital Electronics AssignmentshanmugapriyaaNo ratings yet
- S.No Name Age: HistogramDocument25 pagesS.No Name Age: HistogramshanmugapriyaaNo ratings yet
- Computing Lab Exercise1-15Document31 pagesComputing Lab Exercise1-15shanmugapriyaaNo ratings yet
- Computing Lab 13-12-2021Document7 pagesComputing Lab 13-12-2021shanmugapriyaaNo ratings yet
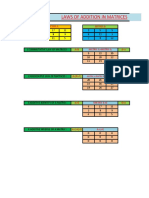
- Laws of Addition in Matrices: Matrix A Matrix BDocument2 pagesLaws of Addition in Matrices: Matrix A Matrix BshanmugapriyaaNo ratings yet
- Python Lab 26-28Document3 pagesPython Lab 26-28shanmugapriyaaNo ratings yet
- Python Lab Exercise 1-10Document12 pagesPython Lab Exercise 1-10shanmugapriyaaNo ratings yet
- Hindi Film by The Same Name Vishal Bhardwaj National Film Award For Best Children's FilmDocument1 pageHindi Film by The Same Name Vishal Bhardwaj National Film Award For Best Children's FilmshanmugapriyaaNo ratings yet
- Manual Exercise 1 - Speech SoundDocument4 pagesManual Exercise 1 - Speech SoundshanmugapriyaaNo ratings yet
- Previous Years Cutoffs and Ranks: TNEA 2021Document48 pagesPrevious Years Cutoffs and Ranks: TNEA 2021shanmugapriyaaNo ratings yet
- Manual Servico Home Theater Philips Hts2500 05Document36 pagesManual Servico Home Theater Philips Hts2500 05Karel Švihálek100% (1)
- Automated Packaging Machine Using PLCDocument7 pagesAutomated Packaging Machine Using PLCTimothy FieldsNo ratings yet
- Facility Layout TestDocument25 pagesFacility Layout TestTesfaye Belaye100% (1)
- Jackson - Cwa - Lodged Stipulated OrderDocument56 pagesJackson - Cwa - Lodged Stipulated Orderthe kingfishNo ratings yet
- Compensation: Introducing The Pay Model and Pay StrategyDocument27 pagesCompensation: Introducing The Pay Model and Pay StrategySyaz AmriNo ratings yet
- Sil ReviewDocument19 pagesSil Reviewtrung2i100% (1)
- Nato HF Modem PerspectiveDocument28 pagesNato HF Modem PerspectiveMax PowerNo ratings yet
- LIC Jeevan Anand Plan PPT Nitin 359Document11 pagesLIC Jeevan Anand Plan PPT Nitin 359Nitin ShindeNo ratings yet
- Appellants: Renu Tandon vs. Respondent: Union of India (UOI)Document7 pagesAppellants: Renu Tandon vs. Respondent: Union of India (UOI)aridaman raghuvanshiNo ratings yet
- Application Binary Interface For The ARM ArchitectureDocument15 pagesApplication Binary Interface For The ARM Architecturejames4registerNo ratings yet
- A Ip Steering Knuckle 2020Document10 pagesA Ip Steering Knuckle 2020Sunil Kumar BadigerNo ratings yet
- Ucl Dissertation SampleDocument5 pagesUcl Dissertation SampleCanYouWriteMyPaperForMeCanada100% (1)
- CH 12 Consumer ProtectionDocument78 pagesCH 12 Consumer Protectionleena shijuNo ratings yet
- Pharmacy Informatics in Multihospital Health Systems: Opportunities and ChallengesDocument8 pagesPharmacy Informatics in Multihospital Health Systems: Opportunities and ChallengesPriscila Navarro MedinaNo ratings yet
- Gay-Lussac's Law Problems and SolutionsDocument1 pageGay-Lussac's Law Problems and SolutionsBasic PhysicsNo ratings yet
- Asterisk DocumentationDocument34 pagesAsterisk DocumentationSafaa Shaaban50% (2)
- Finite Element Analysis of Butterfly ValveDocument13 pagesFinite Element Analysis of Butterfly ValveIJRASETPublicationsNo ratings yet
- Broton V DA Fitzpatrick (Doc 76) Motion To Strike' Delay Tactic. DA Counsel 'Not Ready'Document2 pagesBroton V DA Fitzpatrick (Doc 76) Motion To Strike' Delay Tactic. DA Counsel 'Not Ready'Desiree YaganNo ratings yet
- 2 - How To Cretae PIRDocument8 pages2 - How To Cretae PIRSambit MohantyNo ratings yet
- Digital Payments in IndiaDocument23 pagesDigital Payments in Indiaabhinav sethNo ratings yet
- Statement of Work (Sow) For "Recreational Park": ScopeDocument2 pagesStatement of Work (Sow) For "Recreational Park": ScopeIorga MihaiNo ratings yet
- Gmail - Booking Confirmation On IRCTC, Train - 13154, 05-Nov-2019, SL, NFK - SDAHDocument1 pageGmail - Booking Confirmation On IRCTC, Train - 13154, 05-Nov-2019, SL, NFK - SDAHJetha LalNo ratings yet
- Daywaise Diary of ITRDocument8 pagesDaywaise Diary of ITRIsha Awhale PatilNo ratings yet
- What Lies Ahead?: Learning EpisodeDocument8 pagesWhat Lies Ahead?: Learning EpisodeMarvin GeneblazoNo ratings yet
- Employment Applicant Form (FAB)Document2 pagesEmployment Applicant Form (FAB)kamie76100% (1)
- Personal Finance Canadian Canadian 5th Edition Kapoor Test Bank 1Document22 pagesPersonal Finance Canadian Canadian 5th Edition Kapoor Test Bank 1karenhalesondbatxme100% (26)
- Strategy CanvasDocument3 pagesStrategy CanvasarisuNo ratings yet
- Homebuilt Car With Wood Frames - Practical MechanicsDocument39 pagesHomebuilt Car With Wood Frames - Practical Mechanicssjdarkman1930100% (3)