Download as docx, pdf, or txt
You might also like
- Pythagorean Triangle NumerologyDocument13 pagesPythagorean Triangle Numerologyarchana67% (3)
- 04 La3cna TeDocument22 pages04 La3cna Tegibson marvalNo ratings yet
- Captiva - Engine Controls and Fuel - 2.4LDocument177 pagesCaptiva - Engine Controls and Fuel - 2.4Lhskv20025525100% (1)
- 1 Demag AC 300-6Document20 pages1 Demag AC 300-6Iain KirkNo ratings yet
- 3 Demag CC2800-1Document6 pages3 Demag CC2800-1Jon Csehi100% (2)
- Chart Title: Unrestrained ShrinkageDocument8 pagesChart Title: Unrestrained ShrinkageYELLAMANDA SANKATINo ratings yet
- Exercise 2 RefractionDocument2 pagesExercise 2 Refractionjj jonaNo ratings yet
- Spindo 4Document1 pageSpindo 4Urip RudyantoNo ratings yet
- Tami 0Document4 pagesTami 0Kurniawan Dwi PutraNo ratings yet
- Formula: Day Amount Per Trade (10%) Total Trade Per Day Total Trade Amount Per DayDocument2 pagesFormula: Day Amount Per Trade (10%) Total Trade Per Day Total Trade Amount Per DayinayathNo ratings yet
- م21Document2 pagesم21اسومي الوكحNo ratings yet
- Petrol Refining Ass1Document2 pagesPetrol Refining Ass1Danny TanNo ratings yet
- Aveo 2009 PDFDocument121 pagesAveo 2009 PDFEdwin Peña Pinto100% (1)
- Fuel Consumption ChartDocument1 pageFuel Consumption Chartuzair faridNo ratings yet
- Fuel Consumption ChartDocument1 pageFuel Consumption ChartMannyBaldonadoDeJesusNo ratings yet
- Volume (K) Value ($M) : 2015 2016 2017 FP SP TTL 2015 2016 2017 FP SP TTLDocument2 pagesVolume (K) Value ($M) : 2015 2016 2017 FP SP TTL 2015 2016 2017 FP SP TTLAyan MitraNo ratings yet
- Engine Controls and Fuel Part 2 PDFDocument705 pagesEngine Controls and Fuel Part 2 PDFManuel Fernandez100% (3)
- CrouthDocument6 pagesCrouthIgnatius PathulaNo ratings yet
- Fuel Consumption Chart PDFDocument1 pageFuel Consumption Chart PDFhc1210No ratings yet
- Hardness (A370)Document2 pagesHardness (A370)pramodNo ratings yet
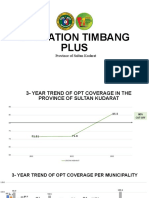
- Opt Presentation 2023 FinalDocument11 pagesOpt Presentation 2023 Finalpdoho adminNo ratings yet
- Learning Activity in Lesson 3Document5 pagesLearning Activity in Lesson 3Carl Stephen Martinez TiongsonNo ratings yet
- Highway & Traffic EngineeringDocument14 pagesHighway & Traffic EngineeringAim ZalainiNo ratings yet
- QI Macros CPU Dashboard Instructions XL2007-2016Document12 pagesQI Macros CPU Dashboard Instructions XL2007-2016NurbayaniNo ratings yet
- IBPA Yield Curve: Daily Fair Price & Yield Indonesia Government Securities December 12, 2018Document3 pagesIBPA Yield Curve: Daily Fair Price & Yield Indonesia Government Securities December 12, 2018Nelli MarselinaNo ratings yet
- Engine Controls and Fuel - 4.8L, 5.3L, 6.0L, 6.2L, or 7.0LDocument136 pagesEngine Controls and Fuel - 4.8L, 5.3L, 6.0L, 6.2L, or 7.0LАндрей ОвчаренкоNo ratings yet
- Table of Section Properties For IPE, HEA, HEB, HEM Profiles - Eurocode 3Document22 pagesTable of Section Properties For IPE, HEA, HEB, HEM Profiles - Eurocode 3Daniel OkereNo ratings yet
- BFC 32302 Tutorial 1 - SolutionDocument5 pagesBFC 32302 Tutorial 1 - SolutionLebya UminNo ratings yet
- Torsion TestDocument7 pagesTorsion TestAmmar AlaufiNo ratings yet
- Datasheet Ac 500 2Document11 pagesDatasheet Ac 500 2Yay B. GicoNo ratings yet
- Approximate Fuel Consumption ChartDocument1 pageApproximate Fuel Consumption ChartMykeNo ratings yet
- Fuel Consumption ChartDocument1 pageFuel Consumption ChartLupul50No ratings yet
- DiagramDocument1 pageDiagramTue TranNo ratings yet
- Book 1Document2 pagesBook 1hafidh1922No ratings yet
- Engine Controls and Fuel - 1.6L (LXV) PDFDocument81 pagesEngine Controls and Fuel - 1.6L (LXV) PDFBenz Aio Calachua Araujo100% (1)
- Set Back DistanceDocument10 pagesSet Back DistanceFranciscoNo ratings yet
- Fuel Consumption Chart Diesel GeneratorsDocument1 pageFuel Consumption Chart Diesel GeneratorsYasir MehmoodNo ratings yet
- Approximate Fuel Consumption ChartDocument1 pageApproximate Fuel Consumption ChartMohammed AlkhawlaniNo ratings yet
- Debre Markos Institute of TechnologyDocument42 pagesDebre Markos Institute of Technologyyeshfe21No ratings yet
- Full Load AmpsDocument2 pagesFull Load AmpsambuenaflorNo ratings yet
- IBPA Pricing Public PDFDocument3 pagesIBPA Pricing Public PDFS. AgustinaNo ratings yet
- Stability of Floating Bodies 1Document7 pagesStability of Floating Bodies 1Kimkate GeronimoNo ratings yet
- Latihan 2 - ContohDocument14 pagesLatihan 2 - ContohCindy NabillahNo ratings yet
- Hyd. Torque WrenchDocument15 pagesHyd. Torque WrenchTH HABIBNo ratings yet
- IBPA Pricing PublicDocument3 pagesIBPA Pricing PublicNelli MarselinaNo ratings yet
- Aerospace & Defense Singles Ampacity RatingDocument2 pagesAerospace & Defense Singles Ampacity RatingScott DobartNo ratings yet
- Diesel Generator Fuel Consumption ChartDocument1 pageDiesel Generator Fuel Consumption ChartsurangaNo ratings yet
- Productivity Criteria Measurement Variables #1 #2 #3 #4 #5 #6 Actual Performance (Score) Row ADocument3 pagesProductivity Criteria Measurement Variables #1 #2 #3 #4 #5 #6 Actual Performance (Score) Row APratibha ThakurNo ratings yet
- Charts & Tables: Rated Motor Current Conversion TableDocument1 pageCharts & Tables: Rated Motor Current Conversion Tablemuqtar4uNo ratings yet
- CamScanner ٠٤-٢٩-٢٠٢٣ ٠٢.٥٨Document2 pagesCamScanner ٠٤-٢٩-٢٠٢٣ ٠٢.٥٨ali alkassemNo ratings yet
- BookDocument2 pagesBookSelome KassayeNo ratings yet
- Air Pollution Modelling at The ITO IntersectionDocument22 pagesAir Pollution Modelling at The ITO IntersectionK_Prabhav_Phal_295No ratings yet
- Viteza DreptDocument3 pagesViteza DreptElena RomanNo ratings yet
- HDPE Pipe Flow RatesDocument2 pagesHDPE Pipe Flow Ratesalaa sadikNo ratings yet
- Bridge Design 2023aDocument5 pagesBridge Design 2023aShiv kumar ThakurNo ratings yet
- B-Class Medium Pipe - Is.1239.1.b.2004Document1 pageB-Class Medium Pipe - Is.1239.1.b.2004Anwar khanNo ratings yet
- Reported Data Corrected Data For 760 MMHG and Vol. Loss Fraction # P, MM HG Cutt (F) V% Sum V% SP - GR@ 60/60 (F) Corrected T (F) Corrected V%Document3 pagesReported Data Corrected Data For 760 MMHG and Vol. Loss Fraction # P, MM HG Cutt (F) V% Sum V% SP - GR@ 60/60 (F) Corrected T (F) Corrected V%Siraj AL sharifNo ratings yet
- Tugas StatistikaDocument5 pagesTugas StatistikaMoh Alfaritzsi RahmanNo ratings yet
- CST 232 Assignment 1 1718Document5 pagesCST 232 Assignment 1 1718WeiYewHuongNo ratings yet
- Frasco Vazio: Número de Vezes)Document8 pagesFrasco Vazio: Número de Vezes)Rafael Campos MaiaNo ratings yet
- MicroGen 说明书Document24 pagesMicroGen 说明书Kailyne WatersNo ratings yet
- On Intermediate RegimesDocument8 pagesOn Intermediate RegimesNikhil SNo ratings yet
- Process Optimization For Dietary Fiber Production From Cassava Pulp Using Acid TreatmentDocument12 pagesProcess Optimization For Dietary Fiber Production From Cassava Pulp Using Acid TreatmentYanuar PramanaNo ratings yet
- Curriculum Map: Mapeh DepartmentDocument9 pagesCurriculum Map: Mapeh DepartmentArvenParafinaNo ratings yet
- Pit DesignDocument82 pagesPit DesignYair Galindo Vega0% (1)
- EU - Type Examination Certificate: II 2G Ex Ia IIC T5/T6 GB II 2D Ex Ia IIIC T100°C/T85°C DB IP6XDocument4 pagesEU - Type Examination Certificate: II 2G Ex Ia IIC T5/T6 GB II 2D Ex Ia IIIC T100°C/T85°C DB IP6XHabibulla BavajiNo ratings yet
- Hanwha SolarOne's SF220 PDFDocument2 pagesHanwha SolarOne's SF220 PDFKirsten HernandezNo ratings yet
- Internship Research Project Guidelines - 2020-23Document7 pagesInternship Research Project Guidelines - 2020-23today.sureshjk6No ratings yet
- Tuasoc - Cen 100 A - Specializations of Civil EngineeringDocument3 pagesTuasoc - Cen 100 A - Specializations of Civil EngineeringAllysa Mae TuasocNo ratings yet
- Viscometer Manual PDFDocument47 pagesViscometer Manual PDFBalqis yasinNo ratings yet
- Goles Rio - Learning Target and Assessment Method MATCHDocument4 pagesGoles Rio - Learning Target and Assessment Method MATCHRhea Antiola GolesNo ratings yet
- Sample TRM All Series 2020v1 - ShortseDocument40 pagesSample TRM All Series 2020v1 - ShortseSuhail AhmadNo ratings yet
- Microsoft Access 2016 - Stewart MelartDocument74 pagesMicrosoft Access 2016 - Stewart Melartmaidanez_ro324133% (3)
- Evolution of EntrepreneurshipDocument5 pagesEvolution of EntrepreneurshipJeyarajasekar Ttr0% (1)
- Exam 01Document2 pagesExam 01Tanima KabirNo ratings yet
- Bash - Ls - FundamentalsDocument5 pagesBash - Ls - FundamentalsPradip ShahiNo ratings yet
- MM 330LX 20170315Document539 pagesMM 330LX 20170315Fabiola Nayeli Villafaña GonzálezNo ratings yet
- ReadmeDocument2 pagesReadmeVictor MilhomemNo ratings yet
- Loria Michelle Fernandes SWAT Analysis PresentationDocument11 pagesLoria Michelle Fernandes SWAT Analysis PresentationLoria FernandesNo ratings yet
- Python-Cluster Documentation: Release 1.4.2Document26 pagesPython-Cluster Documentation: Release 1.4.2César Anderson HNNo ratings yet
- GESE G7-9 - Classroom Activity 4 - Preparing The ConversationDocument8 pagesGESE G7-9 - Classroom Activity 4 - Preparing The Conversationatm4uNo ratings yet
- Phrases & ClausesDocument9 pagesPhrases & ClausesMOHAMMED FURQAN BIN MUSTAFANo ratings yet
- Thoreson, Scott Resume-Cc FinalizedDocument2 pagesThoreson, Scott Resume-Cc Finalizedapi-281404829No ratings yet
- Inverse Laplace TransformDocument12 pagesInverse Laplace TransformjmciurcaNo ratings yet
- 72 Generations UKDocument10 pages72 Generations UKszymonmaj712No ratings yet
- KNRDFV 8348 FJ 43 NF 43Document13 pagesKNRDFV 8348 FJ 43 NF 43Huso KuralicNo ratings yet
- ADIS - COURSE Information SheetDocument1 pageADIS - COURSE Information SheetPriteshJangamNo ratings yet
- Geotex 111F PDSDocument1 pageGeotex 111F PDStranoNo ratings yet