Download as pdf or txt
You might also like
- Instruction Writing - (For Single Vee)Document4 pagesInstruction Writing - (For Single Vee)Hoang Diep PhanNo ratings yet
- DBMS - Transaction Management NotesDocument43 pagesDBMS - Transaction Management NotesKomal Ramteke100% (2)
- Test Data For CP - BD - Direct - Input - Plan PDFDocument6 pagesTest Data For CP - BD - Direct - Input - Plan PDFgtipturnaNo ratings yet
- Service Manual: Dishwasher Integratable ADG 957/1 MDocument17 pagesService Manual: Dishwasher Integratable ADG 957/1 MJan PeterkaNo ratings yet
- Transaction Concurrency and DeadlockDocument65 pagesTransaction Concurrency and Deadlockfloraaluoch3No ratings yet
- DBMS: Notes Unit-4Document33 pagesDBMS: Notes Unit-4parth.2125ec1134No ratings yet
- DBMS Module5 NotesDocument16 pagesDBMS Module5 Notesrohithlokesh2912No ratings yet
- TransactionDocument43 pagesTransactionSangita BoseNo ratings yet
- DBMS4Document23 pagesDBMS4rocketgamer054No ratings yet
- UNIT-4 Final NotesDocument30 pagesUNIT-4 Final Notesbhatiaashika067No ratings yet
- Unit-4 DBMS NotesDocument32 pagesUnit-4 DBMS NotesAmrith MadhiraNo ratings yet
- 1transaction SystemDocument6 pages1transaction SystemHargun SinghNo ratings yet
- Unit-7 Class1Document9 pagesUnit-7 Class1Priyanka BanerjeeNo ratings yet
- Transaction ProcessingDocument14 pagesTransaction ProcessingJawad AhmadNo ratings yet
- DBMS Unit - 4Document43 pagesDBMS Unit - 4JANMEETNo ratings yet
- Unit 4Document104 pagesUnit 4deekshitha ReddyNo ratings yet
- Introduction To Transaction:: Active StateDocument11 pagesIntroduction To Transaction:: Active StateAyush NighotNo ratings yet
- Database IIDocument17 pagesDatabase IIMekonnen SolomonNo ratings yet
- Module - 5Document10 pagesModule - 5Yash Pathak YpNo ratings yet
- Transaction PropertyDocument6 pagesTransaction PropertyTerimaaNo ratings yet
- UNIT-4 Transactions and Concurrency ManagementDocument50 pagesUNIT-4 Transactions and Concurrency Managementsania.mustafa0123No ratings yet
- DBMS 2Document25 pagesDBMS 2haaabusharmaNo ratings yet
- DBMS Unit-5Document33 pagesDBMS Unit-5nehatabassum4237No ratings yet
- DBMS UNIT-4Document28 pagesDBMS UNIT-4aervaneha reddyNo ratings yet
- DBMS Unit-4 & 5Document93 pagesDBMS Unit-4 & 5harshitpanwaarNo ratings yet
- Unit 5: TransactionsDocument23 pagesUnit 5: TransactionsYesudas100% (1)
- CH8 SlideDocument97 pagesCH8 SlideAjaya KapaliNo ratings yet
- Dbms Unit IVDocument35 pagesDbms Unit IVKeshava VarmaNo ratings yet
- DBMS Unit - 3Document46 pagesDBMS Unit - 3logunaathanNo ratings yet
- ACID Properties in DBMSDocument11 pagesACID Properties in DBMSmother theressaNo ratings yet
- UNIT 5 Part 1Document6 pagesUNIT 5 Part 1Aparna AparnaNo ratings yet
- Dbms 3 IaimpDocument25 pagesDbms 3 IaimpravuNo ratings yet
- DB 2Document13 pagesDB 2Demsew TesfaNo ratings yet
- UNIT IV Dbms CollegeDocument30 pagesUNIT IV Dbms College20kd1a05c1No ratings yet
- Chapter-6 - Transactions-Concurrency and RecoveryDocument42 pagesChapter-6 - Transactions-Concurrency and RecoveryHarsh ChitaliyaNo ratings yet
- Unit 4Document13 pagesUnit 4Bhanu Prakash ReddyNo ratings yet
- Unit 3 FinalDocument38 pagesUnit 3 Final4073 JOSEPH SAVIO PEREIRA100% (1)
- Transaction ManagementDocument18 pagesTransaction ManagementParthvi AgarwalNo ratings yet
- Chapter 10Document52 pagesChapter 10A R P A N zNo ratings yet
- Unit-4 Transaction MGMTDocument67 pagesUnit-4 Transaction MGMTPunam SindhuNo ratings yet
- UNIT V Transaction and IndexingDocument26 pagesUNIT V Transaction and IndexingbhanutejakagithaNo ratings yet
- DBMS Unit 5 NotesDocument31 pagesDBMS Unit 5 NotesSiddharth JainNo ratings yet
- Transaction in DBMSDocument54 pagesTransaction in DBMSSravanti BagchiNo ratings yet
- 4 Transaction ProcessingDocument7 pages4 Transaction Processingpeter njugunaNo ratings yet
- DBMS 2 ReDocument10 pagesDBMS 2 Resarvajeetpatil09No ratings yet
- 10 - TransactionDocument70 pages10 - TransactionAditya jhaNo ratings yet
- DBMS KCS501 21 12 2023Document10 pagesDBMS KCS501 21 12 2023Arpit YadavNo ratings yet
- Module 2Document20 pagesModule 2RAMYA KANAGARAJ AutoNo ratings yet
- DBMS - Transactions ManagementDocument40 pagesDBMS - Transactions ManagementhariNo ratings yet
- Module 4 Transaction ProcessingDocument94 pagesModule 4 Transaction ProcessingVaidehi Verma100% (1)
- Presentation: Concurrency Control TechniqueDocument17 pagesPresentation: Concurrency Control TechniqueUmer FarooqNo ratings yet
- Unit-4 TransactionsDocument32 pagesUnit-4 Transactions219X1A3359 SINGASANI JAYA PRATHAP REDDYNo ratings yet
- DBMS Concurrency ControlDocument18 pagesDBMS Concurrency ControlHayat KhanNo ratings yet
- Set-B: - A Single Unit of WorkDocument12 pagesSet-B: - A Single Unit of WorkRami ReddyNo ratings yet
- Lecture 11Document77 pagesLecture 11Kavita DagarNo ratings yet
- DBMS Unit 5Document12 pagesDBMS Unit 5Naresh BabuNo ratings yet
- DBMS Transaction ManagementDocument10 pagesDBMS Transaction ManagementPalak RathoreNo ratings yet
- TransactionDocument39 pagesTransactionManisha SNo ratings yet
- Transaction and Serializibility2Document47 pagesTransaction and Serializibility2shibu 01No ratings yet
- Chapter 15 DBMSDocument75 pagesChapter 15 DBMSAyaan SharmaNo ratings yet
- Unit 4 - Database Management System - WWW - Rgpvnotes.inDocument17 pagesUnit 4 - Database Management System - WWW - Rgpvnotes.inmroriginal845438No ratings yet
- DBMS-Module - 5 UpdatedDocument98 pagesDBMS-Module - 5 Updatedgowtham.22bce7282No ratings yet
- FocDocument11 pagesFocSL PRASAD KOLLURUNo ratings yet
- CPP LabDocument35 pagesCPP LabSL PRASAD KOLLURUNo ratings yet
- Unit IiDocument27 pagesUnit IiSL PRASAD KOLLURUNo ratings yet
- Unit IvDocument24 pagesUnit IvSL PRASAD KOLLURUNo ratings yet
- Design and Implementations of Control System Quadruped Robot Driver Application Based On Windows PlatformDocument8 pagesDesign and Implementations of Control System Quadruped Robot Driver Application Based On Windows Platformpuskesmas III denpasar utaraNo ratings yet
- Accident Report Output - 202211230048 - 2022-11-28 - 01-30-39-PMDocument4 pagesAccident Report Output - 202211230048 - 2022-11-28 - 01-30-39-PMjuyla5479No ratings yet
- The Bilderberg GroupDocument35 pagesThe Bilderberg GroupTimothy100% (2)
- Typical Fcu Connections: ProposedDocument1 pageTypical Fcu Connections: ProposedIbrahim FarhanNo ratings yet
- Catering Job Duties For ResumeDocument7 pagesCatering Job Duties For Resumeafmrnroadofebl100% (1)
- Project 4 SBDocument87 pagesProject 4 SBDk Afa100% (3)
- Osram-Mini TwistDocument2 pagesOsram-Mini TwistHermanNo ratings yet
- Coop Chart of AccountsDocument30 pagesCoop Chart of AccountsAmalia Dela Cruz100% (17)
- G.R. No. 178713 LORENZO SHIPPING CORPORATION, Petitioner, vs. FLORENCIO O. VILLARINDocument4 pagesG.R. No. 178713 LORENZO SHIPPING CORPORATION, Petitioner, vs. FLORENCIO O. VILLARINMark VirayNo ratings yet
- Clearing and Grubbing (With Stripping - Mechnized)Document1 pageClearing and Grubbing (With Stripping - Mechnized)Pedro PakuNo ratings yet
- Electrica L Design 1: Term TestDocument12 pagesElectrica L Design 1: Term TestReynaldo CuestaNo ratings yet
- SIFANG CyberSolar Smart PV Solution 20180110Document31 pagesSIFANG CyberSolar Smart PV Solution 20180110Amine HedjemNo ratings yet
- Introduction To Color SpacesDocument4 pagesIntroduction To Color Spacesabdullah saifNo ratings yet
- Front-End Developer Interview Questions: Topics CoveredDocument15 pagesFront-End Developer Interview Questions: Topics CoveredYash DhawanNo ratings yet
- 10 Types of ComputersDocument3 pages10 Types of ComputersbingNo ratings yet
- DefinitionsDocument24 pagesDefinitionskenzy hanyNo ratings yet
- Case Study Transportation MGTDocument3 pagesCase Study Transportation MGTHải Đăng0% (1)
- Corporate Social and Environment Responsibility of Emirates AirlineDocument41 pagesCorporate Social and Environment Responsibility of Emirates AirlineSabicaSajidNo ratings yet
- JP Infra Mumbai 23dec2021Document6 pagesJP Infra Mumbai 23dec2021Rishabh MehtaNo ratings yet
- Capacitor Bank CatalougeDocument28 pagesCapacitor Bank CatalougeleyNo ratings yet
- Unit 14Document2 pagesUnit 14nibulaNo ratings yet
- ABNAMRO Soccernomics enDocument8 pagesABNAMRO Soccernomics enNeha AnandaniNo ratings yet
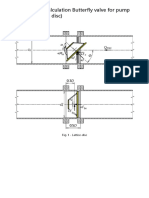
- Hydrodynamic Calculation Butterfly Valve For Pump Operation (Lattice Disc)Document19 pagesHydrodynamic Calculation Butterfly Valve For Pump Operation (Lattice Disc)met-calcNo ratings yet
- QC PL 0006Document1 pageQC PL 0006AmeerNo ratings yet
- LG 47lg90 Led LCD TV Training-ManualDocument109 pagesLG 47lg90 Led LCD TV Training-ManualErnie De Leon100% (2)
- Application Development With QT Creator: Second EditionDocument15 pagesApplication Development With QT Creator: Second EditionPackt PublishingNo ratings yet
- 78 - Triumph Stoker BrochureDocument2 pages78 - Triumph Stoker BrochureMatias MancillaNo ratings yet