
Input: Output: Id Name Id Name - A Name - B Name - C
Input: Output: Id Name Id Name - A Name - B Name - C
You might also like
- Cda HS - Two Octave Scales Violin PDFDocument5 pagesCda HS - Two Octave Scales Violin PDFRuzell100% (1)
- Paco de Lucia Guajiras de Lucia PDFDocument13 pagesPaco de Lucia Guajiras de Lucia PDFRoy RodriguezNo ratings yet
- Grade 1 Scales ABRSM: Hands Separately 60Document2 pagesGrade 1 Scales ABRSM: Hands Separately 60Elliot EW100% (5)
- Huawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkDocument5 pagesHuawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkHamad KhanNo ratings yet
- Assesment of Risks From High Pressure Natural Gas PipeleinesDocument62 pagesAssesment of Risks From High Pressure Natural Gas Pipeleinesthawdar100% (1)
- HY-eVision2 7.0 User ManualDocument50 pagesHY-eVision2 7.0 User ManualEmerson GomesNo ratings yet
- Assignment2. Insertion Heurestic TSP HeuresticsDocument73 pagesAssignment2. Insertion Heurestic TSP HeuresticschadwakhemissiNo ratings yet
- Partitura Aula 4 - Arpejo IntercaladoDocument1 pagePartitura Aula 4 - Arpejo IntercaladoJOSE EMIDIO DE ARAUJO MAGALHAES JUNIORNo ratings yet
- GAVOTA-Robert ChaputDocument1 pageGAVOTA-Robert ChaputJosé VictoriaNo ratings yet
- R, Chaput. GavotteDocument2 pagesR, Chaput. GavotteCarmine de LuciaNo ratings yet
- 7 Levels of 1 Major ScaleDocument2 pages7 Levels of 1 Major ScaleStefano FerrantiNo ratings yet
- Do Sostenido Menor NaturalDocument1 pageDo Sostenido Menor NaturalIvan SuarezNo ratings yet
- Regondi Etude No1Document12 pagesRegondi Etude No1Charles GNo ratings yet
- C Major ScaleDocument1 pageC Major ScaleAileen NicoleNo ratings yet
- Grade 2 - Scales, Contrary Motions, ArpeggiosDocument13 pagesGrade 2 - Scales, Contrary Motions, Arpeggiosarda gucluNo ratings yet
- Color Number Race CarDocument1 pageColor Number Race CarSaurabh PatelNo ratings yet
- Wild Stream: Ciaran Farrell 65Document4 pagesWild Stream: Ciaran Farrell 65Вячеслав ШевелевNo ratings yet
- BEATRICE WILDER FaM Rem EscalasArpegiosAcordesDocument2 pagesBEATRICE WILDER FaM Rem EscalasArpegiosAcordesCatalina MayorgaNo ratings yet
- Dilbar MereDocument1 pageDilbar MereAditya PawarNo ratings yet
- Modulo ArtDocument11 pagesModulo Artjanelaudrey2601No ratings yet
- Batter Analysis ChartDocument1 pageBatter Analysis ChartIda Soraya HamidonNo ratings yet
- Mario Castelnuovo-Tedesco - Tarantella (Guitar Pro)Document11 pagesMario Castelnuovo-Tedesco - Tarantella (Guitar Pro)Gil Gamesh100% (2)
- Do Menor NaturalDocument1 pageDo Menor NaturalIvan SuarezNo ratings yet
- Bach, Invention in A Minor, BWV 784Document2 pagesBach, Invention in A Minor, BWV 784Edson RamosNo ratings yet
- Unit+4+ +Common+Functions+'20Document38 pagesUnit+4+ +Common+Functions+'20William GokeyNo ratings yet
- Top 3 ExercisesDocument2 pagesTop 3 ExercisesDoody EmNo ratings yet
- Top 3 Exercises For Guitar: Rolf Van Meurs WWW - Rolfvanmeurs.nlDocument2 pagesTop 3 Exercises For Guitar: Rolf Van Meurs WWW - Rolfvanmeurs.nlsasa100% (1)
- Choros-Tab 231009 224023Document3 pagesChoros-Tab 231009 224023kwan ho koNo ratings yet
- Khachaturian Andantino DDocument1 pageKhachaturian Andantino DDinaNo ratings yet
- Ved Jurassic Park MathDocument4 pagesVed Jurassic Park MathdrchiNo ratings yet
- Lec 252Document31 pagesLec 252Padiyappa KoogatiNo ratings yet
- The Girl From Ipanema Acordes Básicos Basic ChordsDocument7 pagesThe Girl From Ipanema Acordes Básicos Basic ChordsJoseMariaMondelo100% (1)
- D Major ScaleDocument1 pageD Major ScaleAileen NicoleNo ratings yet
- Structured LightDocument10 pagesStructured LightKopkoHNo ratings yet
- IndolenteDocument1 pageIndolentesergioNo ratings yet
- t-t-17181-winter-colour-by-number_ver_4Document3 pagest-t-17181-winter-colour-by-number_ver_4alonsomicaelabelenNo ratings yet
- Mixolydian Chromatics Turnaround #24Document1 pageMixolydian Chromatics Turnaround #24Miguel De Leon MuñizNo ratings yet
- Chinguun92: Chinguun92's Bracket Entry # 3962Document2 pagesChinguun92: Chinguun92's Bracket Entry # 3962Batsaikhan BatgerelNo ratings yet
- Learn Cursive Script by Ian Barnard PDFDocument12 pagesLearn Cursive Script by Ian Barnard PDFasiegrainenicoleNo ratings yet
- Sorrow Methode de Piano Dbutants NDocument1 pageSorrow Methode de Piano Dbutants NYianniNo ratings yet
- Igors Chromatic ExerciseDocument2 pagesIgors Chromatic ExerciseAlejandro GonzalezNo ratings yet
- E Minor Scales & ArpeggiosDocument2 pagesE Minor Scales & ArpeggiosAndré OliveiraNo ratings yet
- 20 Items v4 PrintoutDocument1 page20 Items v4 PrintoutJoeyNo ratings yet
- Exer 05 Freehand Lettering ExerciseDocument1 pageExer 05 Freehand Lettering ExerciseKristine SingsonNo ratings yet
- Escala Melodica CDocument2 pagesEscala Melodica CDavid Puc NarvaezNo ratings yet
- Cda HS - Two Octave Scales ViolinDocument5 pagesCda HS - Two Octave Scales ViolinRuzellNo ratings yet
- WorksheetsAlg2Systems20of20Two20Equations PDFDocument4 pagesWorksheetsAlg2Systems20of20Two20Equations PDFColleen GriswoldNo ratings yet
- Systems of Two EquationsDocument4 pagesSystems of Two Equationsapi-253892365No ratings yet
- Scoring Hackaton UGDocument8 pagesScoring Hackaton UGDxmplesNo ratings yet
- Exerci Cio SDocument1 pageExerci Cio SWillians PaternoNo ratings yet
- Sim Lif IcationDocument4 pagesSim Lif Icationattwbdh0922No ratings yet
- Persia and Moose: PerformanceDocument2 pagesPersia and Moose: Performancethiago rykelveNo ratings yet
- 3D Labyrinth BoardDocument2 pages3D Labyrinth BoardNeoravenxNo ratings yet
- Tenor Banjo Chords StandardDocument4 pagesTenor Banjo Chords StandardLaurentTuquetNo ratings yet
- Tenor Banjo Chords Standard PDFDocument4 pagesTenor Banjo Chords Standard PDFCroco FoxNo ratings yet
- Tributos de Louvor 312Document1 pageTributos de Louvor 312John BarretoNo ratings yet
- CR3 Cromatismos Mano Izquierda 2Document2 pagesCR3 Cromatismos Mano Izquierda 2Bastian InostrozaNo ratings yet
- Partido AltoDocument3 pagesPartido AltoLeandro PortelaNo ratings yet
- Ed Sheeran - Bad HabitsDocument1 pageEd Sheeran - Bad HabitsAndré ValérioNo ratings yet
- SMSFB 021Document1 pageSMSFB 021li LewisNo ratings yet
- SMSFB 053Document2 pagesSMSFB 053li LewisNo ratings yet
- J. K. Mertz. Estudio 6Document1 pageJ. K. Mertz. Estudio 6vinceNo ratings yet
- Login To Informatica Powercenter Workflow ManagerDocument21 pagesLogin To Informatica Powercenter Workflow ManagerSQL INFORMATICANo ratings yet
- WorkletsDocument7 pagesWorkletsSQL INFORMATICANo ratings yet
- XML Target Data Import Source Definition From Relational Database As BelowDocument9 pagesXML Target Data Import Source Definition From Relational Database As BelowSQL INFORMATICANo ratings yet
- Data Transformation Manager (DTM) Process: Courtesy InformaticaDocument2 pagesData Transformation Manager (DTM) Process: Courtesy InformaticaSQL INFORMATICANo ratings yet
- Informatica Pushdown Tips - NewDocument5 pagesInformatica Pushdown Tips - NewSQL INFORMATICANo ratings yet
- Lookup Transformation: To Introduce Look Up Transformation, Types of Look Ups and Its PropertiesDocument24 pagesLookup Transformation: To Introduce Look Up Transformation, Types of Look Ups and Its PropertiesSQL INFORMATICANo ratings yet
- DWH-Concepts NewDocument33 pagesDWH-Concepts NewSQL INFORMATICANo ratings yet
- Expression 1 With Sequence Generator Input: Seq Id Col1 Col2 Col3Document6 pagesExpression 1 With Sequence Generator Input: Seq Id Col1 Col2 Col3SQL INFORMATICANo ratings yet
- Assignment-15 NewDocument6 pagesAssignment-15 NewSQL INFORMATICANo ratings yet
- Window 95Document13 pagesWindow 95Jiro SaldiviaNo ratings yet
- 07 TutorialDocument5 pages07 TutorialRanga KirankishoreNo ratings yet
- Data Sheet US - W3G910GU2201 KM89187Document7 pagesData Sheet US - W3G910GU2201 KM89187Bruno Cezar FurlinNo ratings yet
- MSE2183Document102 pagesMSE2183MarkusNo ratings yet
- Midterm Report: in Electrical EngineeringDocument11 pagesMidterm Report: in Electrical Engineeringdr.Sabita shresthaNo ratings yet
- S6 Service Manual: EnglishDocument96 pagesS6 Service Manual: EnglishpurbaariefNo ratings yet
- CH 11 Lecture SlidesDocument44 pagesCH 11 Lecture SlidesUyên Trần NhưNo ratings yet
- Linear Algebra and Random Processes (CS6015)Document5 pagesLinear Algebra and Random Processes (CS6015)CHAKRADHAR PALAVALASANo ratings yet
- Antim Prahar Business Research MethodsDocument66 pagesAntim Prahar Business Research Methodsharshit bhatnagarNo ratings yet
- Whelchel Dissertation FinalDocument714 pagesWhelchel Dissertation FinalIsabel GonzalezNo ratings yet
- CT S&P-Avr13-THGT-SélectionDocument78 pagesCT S&P-Avr13-THGT-Sélectionkasztakatika100% (1)
- NumeracyDocument12 pagesNumeracySerah BijuNo ratings yet
- Operations Management - Chapter 12Document11 pagesOperations Management - Chapter 12David Van De FliertNo ratings yet
- NMRVDocument114 pagesNMRVNur SugiartoNo ratings yet
- Practice Question Ffor Module 7Document6 pagesPractice Question Ffor Module 7hemkumar DahalNo ratings yet
- Art Class 1Document20 pagesArt Class 1Dipanwita ChakrabortyNo ratings yet
- HUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-BDocument93 pagesHUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-Bkashf415100% (4)
- Compact DC Power SteeringDocument18 pagesCompact DC Power SteeringTihomir MarkovicNo ratings yet
- Harmonica For Beginners - Ami LuzDocument89 pagesHarmonica For Beginners - Ami LuzMoramay Martínez100% (4)
- The Solution For Automotive and Industrial DesignDocument3 pagesThe Solution For Automotive and Industrial DesignCharlesNo ratings yet
- Customer Inquiry Sheet BlankDocument3 pagesCustomer Inquiry Sheet BlankAbunawas_MJNo ratings yet
- Crime Type and Occurrence Prediction Using Machine LearningDocument28 pagesCrime Type and Occurrence Prediction Using Machine Learninggateway.manigandanNo ratings yet
- USR-GPRS232-730 Guide LineDocument18 pagesUSR-GPRS232-730 Guide LineKutu BukuNo ratings yet
- Bharat Heavy Electricals Limited: Tvenkat@bheltry - Co.inDocument5 pagesBharat Heavy Electricals Limited: Tvenkat@bheltry - Co.inRukma Goud Shakkari100% (1)
- Basic Principles For Sizing Grease InterceptorsDocument5 pagesBasic Principles For Sizing Grease InterceptorsSharon LambertNo ratings yet
- The Effect of Temperature On The PH Level of Lemon JuiceDocument12 pagesThe Effect of Temperature On The PH Level of Lemon JuicekjfanmNo ratings yet
- The Evaluation of Network Anomaly Detection Systems: Statistical Analysis ofDocument15 pagesThe Evaluation of Network Anomaly Detection Systems: Statistical Analysis ofMd. Fazle Rabbi Spondon 190041211No ratings yet































































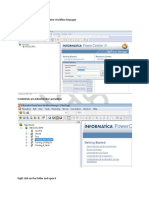
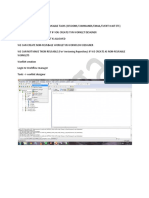

































Download as xlsx, pdf, or txt
You might also like
- Cda HS - Two Octave Scales Violin PDFDocument5 pagesCda HS - Two Octave Scales Violin PDFRuzell100% (1)
- Paco de Lucia Guajiras de Lucia PDFDocument13 pagesPaco de Lucia Guajiras de Lucia PDFRoy RodriguezNo ratings yet
- Grade 1 Scales ABRSM: Hands Separately 60Document2 pagesGrade 1 Scales ABRSM: Hands Separately 60Elliot EW100% (5)
- Huawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkDocument5 pagesHuawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkHamad KhanNo ratings yet
- Assesment of Risks From High Pressure Natural Gas PipeleinesDocument62 pagesAssesment of Risks From High Pressure Natural Gas Pipeleinesthawdar100% (1)
- HY-eVision2 7.0 User ManualDocument50 pagesHY-eVision2 7.0 User ManualEmerson GomesNo ratings yet
- Assignment2. Insertion Heurestic TSP HeuresticsDocument73 pagesAssignment2. Insertion Heurestic TSP HeuresticschadwakhemissiNo ratings yet
- Partitura Aula 4 - Arpejo IntercaladoDocument1 pagePartitura Aula 4 - Arpejo IntercaladoJOSE EMIDIO DE ARAUJO MAGALHAES JUNIORNo ratings yet
- GAVOTA-Robert ChaputDocument1 pageGAVOTA-Robert ChaputJosé VictoriaNo ratings yet
- R, Chaput. GavotteDocument2 pagesR, Chaput. GavotteCarmine de LuciaNo ratings yet
- 7 Levels of 1 Major ScaleDocument2 pages7 Levels of 1 Major ScaleStefano FerrantiNo ratings yet
- Do Sostenido Menor NaturalDocument1 pageDo Sostenido Menor NaturalIvan SuarezNo ratings yet
- Regondi Etude No1Document12 pagesRegondi Etude No1Charles GNo ratings yet
- C Major ScaleDocument1 pageC Major ScaleAileen NicoleNo ratings yet
- Grade 2 - Scales, Contrary Motions, ArpeggiosDocument13 pagesGrade 2 - Scales, Contrary Motions, Arpeggiosarda gucluNo ratings yet
- Color Number Race CarDocument1 pageColor Number Race CarSaurabh PatelNo ratings yet
- Wild Stream: Ciaran Farrell 65Document4 pagesWild Stream: Ciaran Farrell 65Вячеслав ШевелевNo ratings yet
- BEATRICE WILDER FaM Rem EscalasArpegiosAcordesDocument2 pagesBEATRICE WILDER FaM Rem EscalasArpegiosAcordesCatalina MayorgaNo ratings yet
- Dilbar MereDocument1 pageDilbar MereAditya PawarNo ratings yet
- Modulo ArtDocument11 pagesModulo Artjanelaudrey2601No ratings yet
- Batter Analysis ChartDocument1 pageBatter Analysis ChartIda Soraya HamidonNo ratings yet
- Mario Castelnuovo-Tedesco - Tarantella (Guitar Pro)Document11 pagesMario Castelnuovo-Tedesco - Tarantella (Guitar Pro)Gil Gamesh100% (2)
- Do Menor NaturalDocument1 pageDo Menor NaturalIvan SuarezNo ratings yet
- Bach, Invention in A Minor, BWV 784Document2 pagesBach, Invention in A Minor, BWV 784Edson RamosNo ratings yet
- Unit+4+ +Common+Functions+'20Document38 pagesUnit+4+ +Common+Functions+'20William GokeyNo ratings yet
- Top 3 ExercisesDocument2 pagesTop 3 ExercisesDoody EmNo ratings yet
- Top 3 Exercises For Guitar: Rolf Van Meurs WWW - Rolfvanmeurs.nlDocument2 pagesTop 3 Exercises For Guitar: Rolf Van Meurs WWW - Rolfvanmeurs.nlsasa100% (1)
- Choros-Tab 231009 224023Document3 pagesChoros-Tab 231009 224023kwan ho koNo ratings yet
- Khachaturian Andantino DDocument1 pageKhachaturian Andantino DDinaNo ratings yet
- Ved Jurassic Park MathDocument4 pagesVed Jurassic Park MathdrchiNo ratings yet
- Lec 252Document31 pagesLec 252Padiyappa KoogatiNo ratings yet
- The Girl From Ipanema Acordes Básicos Basic ChordsDocument7 pagesThe Girl From Ipanema Acordes Básicos Basic ChordsJoseMariaMondelo100% (1)
- D Major ScaleDocument1 pageD Major ScaleAileen NicoleNo ratings yet
- Structured LightDocument10 pagesStructured LightKopkoHNo ratings yet
- IndolenteDocument1 pageIndolentesergioNo ratings yet
- t-t-17181-winter-colour-by-number_ver_4Document3 pagest-t-17181-winter-colour-by-number_ver_4alonsomicaelabelenNo ratings yet
- Mixolydian Chromatics Turnaround #24Document1 pageMixolydian Chromatics Turnaround #24Miguel De Leon MuñizNo ratings yet
- Chinguun92: Chinguun92's Bracket Entry # 3962Document2 pagesChinguun92: Chinguun92's Bracket Entry # 3962Batsaikhan BatgerelNo ratings yet
- Learn Cursive Script by Ian Barnard PDFDocument12 pagesLearn Cursive Script by Ian Barnard PDFasiegrainenicoleNo ratings yet
- Sorrow Methode de Piano Dbutants NDocument1 pageSorrow Methode de Piano Dbutants NYianniNo ratings yet
- Igors Chromatic ExerciseDocument2 pagesIgors Chromatic ExerciseAlejandro GonzalezNo ratings yet
- E Minor Scales & ArpeggiosDocument2 pagesE Minor Scales & ArpeggiosAndré OliveiraNo ratings yet
- 20 Items v4 PrintoutDocument1 page20 Items v4 PrintoutJoeyNo ratings yet
- Exer 05 Freehand Lettering ExerciseDocument1 pageExer 05 Freehand Lettering ExerciseKristine SingsonNo ratings yet
- Escala Melodica CDocument2 pagesEscala Melodica CDavid Puc NarvaezNo ratings yet
- Cda HS - Two Octave Scales ViolinDocument5 pagesCda HS - Two Octave Scales ViolinRuzellNo ratings yet
- WorksheetsAlg2Systems20of20Two20Equations PDFDocument4 pagesWorksheetsAlg2Systems20of20Two20Equations PDFColleen GriswoldNo ratings yet
- Systems of Two EquationsDocument4 pagesSystems of Two Equationsapi-253892365No ratings yet
- Scoring Hackaton UGDocument8 pagesScoring Hackaton UGDxmplesNo ratings yet
- Exerci Cio SDocument1 pageExerci Cio SWillians PaternoNo ratings yet
- Sim Lif IcationDocument4 pagesSim Lif Icationattwbdh0922No ratings yet
- Persia and Moose: PerformanceDocument2 pagesPersia and Moose: Performancethiago rykelveNo ratings yet
- 3D Labyrinth BoardDocument2 pages3D Labyrinth BoardNeoravenxNo ratings yet
- Tenor Banjo Chords StandardDocument4 pagesTenor Banjo Chords StandardLaurentTuquetNo ratings yet
- Tenor Banjo Chords Standard PDFDocument4 pagesTenor Banjo Chords Standard PDFCroco FoxNo ratings yet
- Tributos de Louvor 312Document1 pageTributos de Louvor 312John BarretoNo ratings yet
- CR3 Cromatismos Mano Izquierda 2Document2 pagesCR3 Cromatismos Mano Izquierda 2Bastian InostrozaNo ratings yet
- Partido AltoDocument3 pagesPartido AltoLeandro PortelaNo ratings yet
- Ed Sheeran - Bad HabitsDocument1 pageEd Sheeran - Bad HabitsAndré ValérioNo ratings yet
- SMSFB 021Document1 pageSMSFB 021li LewisNo ratings yet
- SMSFB 053Document2 pagesSMSFB 053li LewisNo ratings yet
- J. K. Mertz. Estudio 6Document1 pageJ. K. Mertz. Estudio 6vinceNo ratings yet
- Login To Informatica Powercenter Workflow ManagerDocument21 pagesLogin To Informatica Powercenter Workflow ManagerSQL INFORMATICANo ratings yet
- WorkletsDocument7 pagesWorkletsSQL INFORMATICANo ratings yet
- XML Target Data Import Source Definition From Relational Database As BelowDocument9 pagesXML Target Data Import Source Definition From Relational Database As BelowSQL INFORMATICANo ratings yet
- Data Transformation Manager (DTM) Process: Courtesy InformaticaDocument2 pagesData Transformation Manager (DTM) Process: Courtesy InformaticaSQL INFORMATICANo ratings yet
- Informatica Pushdown Tips - NewDocument5 pagesInformatica Pushdown Tips - NewSQL INFORMATICANo ratings yet
- Lookup Transformation: To Introduce Look Up Transformation, Types of Look Ups and Its PropertiesDocument24 pagesLookup Transformation: To Introduce Look Up Transformation, Types of Look Ups and Its PropertiesSQL INFORMATICANo ratings yet
- DWH-Concepts NewDocument33 pagesDWH-Concepts NewSQL INFORMATICANo ratings yet
- Expression 1 With Sequence Generator Input: Seq Id Col1 Col2 Col3Document6 pagesExpression 1 With Sequence Generator Input: Seq Id Col1 Col2 Col3SQL INFORMATICANo ratings yet
- Assignment-15 NewDocument6 pagesAssignment-15 NewSQL INFORMATICANo ratings yet
- Window 95Document13 pagesWindow 95Jiro SaldiviaNo ratings yet
- 07 TutorialDocument5 pages07 TutorialRanga KirankishoreNo ratings yet
- Data Sheet US - W3G910GU2201 KM89187Document7 pagesData Sheet US - W3G910GU2201 KM89187Bruno Cezar FurlinNo ratings yet
- MSE2183Document102 pagesMSE2183MarkusNo ratings yet
- Midterm Report: in Electrical EngineeringDocument11 pagesMidterm Report: in Electrical Engineeringdr.Sabita shresthaNo ratings yet
- S6 Service Manual: EnglishDocument96 pagesS6 Service Manual: EnglishpurbaariefNo ratings yet
- CH 11 Lecture SlidesDocument44 pagesCH 11 Lecture SlidesUyên Trần NhưNo ratings yet
- Linear Algebra and Random Processes (CS6015)Document5 pagesLinear Algebra and Random Processes (CS6015)CHAKRADHAR PALAVALASANo ratings yet
- Antim Prahar Business Research MethodsDocument66 pagesAntim Prahar Business Research Methodsharshit bhatnagarNo ratings yet
- Whelchel Dissertation FinalDocument714 pagesWhelchel Dissertation FinalIsabel GonzalezNo ratings yet
- CT S&P-Avr13-THGT-SélectionDocument78 pagesCT S&P-Avr13-THGT-Sélectionkasztakatika100% (1)
- NumeracyDocument12 pagesNumeracySerah BijuNo ratings yet
- Operations Management - Chapter 12Document11 pagesOperations Management - Chapter 12David Van De FliertNo ratings yet
- NMRVDocument114 pagesNMRVNur SugiartoNo ratings yet
- Practice Question Ffor Module 7Document6 pagesPractice Question Ffor Module 7hemkumar DahalNo ratings yet
- Art Class 1Document20 pagesArt Class 1Dipanwita ChakrabortyNo ratings yet
- HUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-BDocument93 pagesHUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-Bkashf415100% (4)
- Compact DC Power SteeringDocument18 pagesCompact DC Power SteeringTihomir MarkovicNo ratings yet
- Harmonica For Beginners - Ami LuzDocument89 pagesHarmonica For Beginners - Ami LuzMoramay Martínez100% (4)
- The Solution For Automotive and Industrial DesignDocument3 pagesThe Solution For Automotive and Industrial DesignCharlesNo ratings yet
- Customer Inquiry Sheet BlankDocument3 pagesCustomer Inquiry Sheet BlankAbunawas_MJNo ratings yet
- Crime Type and Occurrence Prediction Using Machine LearningDocument28 pagesCrime Type and Occurrence Prediction Using Machine Learninggateway.manigandanNo ratings yet
- USR-GPRS232-730 Guide LineDocument18 pagesUSR-GPRS232-730 Guide LineKutu BukuNo ratings yet
- Bharat Heavy Electricals Limited: Tvenkat@bheltry - Co.inDocument5 pagesBharat Heavy Electricals Limited: Tvenkat@bheltry - Co.inRukma Goud Shakkari100% (1)
- Basic Principles For Sizing Grease InterceptorsDocument5 pagesBasic Principles For Sizing Grease InterceptorsSharon LambertNo ratings yet
- The Effect of Temperature On The PH Level of Lemon JuiceDocument12 pagesThe Effect of Temperature On The PH Level of Lemon JuicekjfanmNo ratings yet
- The Evaluation of Network Anomaly Detection Systems: Statistical Analysis ofDocument15 pagesThe Evaluation of Network Anomaly Detection Systems: Statistical Analysis ofMd. Fazle Rabbi Spondon 190041211No ratings yet