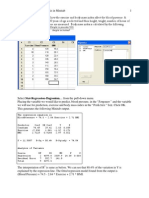
Download as docx, pdf, or txt
You might also like
- Midterm: (15 Points) : Indian Institute of Management Bangalore Decision Science II Old ExamsDocument72 pagesMidterm: (15 Points) : Indian Institute of Management Bangalore Decision Science II Old ExamsNitishNo ratings yet
- HE Mini-Pak 6 ManualDocument100 pagesHE Mini-Pak 6 ManualJavier Alejandro QuingaNo ratings yet
- Regression AnalysisDocument14 pagesRegression AnalysisSona VermaNo ratings yet
- CovarDocument9 pagesCovarLoubill Dayne AceronNo ratings yet
- Practice Questions - Quantitative - Reading 7Document13 pagesPractice Questions - Quantitative - Reading 7Khải HoànNo ratings yet
- Perception 1Document25 pagesPerception 1PiyulNo ratings yet
- Ardl 1Document166 pagesArdl 1sunil kumarNo ratings yet
- Few Basic Financial Econometrics Q&ADocument9 pagesFew Basic Financial Econometrics Q&ASubhrodip Sengupta100% (1)
- Minitab Multiple Regression AnalysisDocument6 pagesMinitab Multiple Regression Analysisbuat akunNo ratings yet
- Minitab Multiple Regression Analysis PDFDocument6 pagesMinitab Multiple Regression Analysis PDFBen GuhmanNo ratings yet
- Forecasting For Economics and Business 1st Edition Gloria Gonzalez Rivera Solutions ManualDocument36 pagesForecasting For Economics and Business 1st Edition Gloria Gonzalez Rivera Solutions Manualbrownismkanacka9oir100% (30)
- Lecture 6 - Multiple Regression AnalysisDocument32 pagesLecture 6 - Multiple Regression AnalysisSubmission PortalNo ratings yet
- Attitude 1Document25 pagesAttitude 1PiyulNo ratings yet
- Lecture 5 - Correlation Regression Analysis Part IIDocument35 pagesLecture 5 - Correlation Regression Analysis Part IISubmission PortalNo ratings yet
- Dwnload Full Forecasting For Economics and Business 1st Edition Gloria Gonzalez Rivera Solutions Manual PDFDocument36 pagesDwnload Full Forecasting For Economics and Business 1st Edition Gloria Gonzalez Rivera Solutions Manual PDFjulianale9drNo ratings yet
- Assignment - The File Logitsubscribedata - Xls Gives The Number of People in Each Age Group WhoDocument4 pagesAssignment - The File Logitsubscribedata - Xls Gives The Number of People in Each Age Group WhoSneh JuyalNo ratings yet
- Multiple Regression and Issues in Regression AnalysisDocument25 pagesMultiple Regression and Issues in Regression AnalysisRaghav BhatnagarNo ratings yet
- Kartika B Nair BDBA AssignmentDocument8 pagesKartika B Nair BDBA AssignmentKartika Bhuvaneswaran NairNo ratings yet
- Practical Problems in StatisticDocument8 pagesPractical Problems in StatisticAkhileshNo ratings yet
- Minitab Multiple Regression AnalysisDocument6 pagesMinitab Multiple Regression AnalysisEka Rahma Paramita100% (1)
- Multiple Regression in SPSS: X X X y X X y X X yDocument13 pagesMultiple Regression in SPSS: X X X y X X y X X yRohit SikriNo ratings yet
- Tugas Regresi & Kuisoner Aldi DKKDocument7 pagesTugas Regresi & Kuisoner Aldi DKKRegan Muammar NugrahaNo ratings yet
- Coventry Simple Linear RegressionDocument4 pagesCoventry Simple Linear RegressionHà HàNo ratings yet
- Report Has Prepared by Kamran Selimli and Sahil MesimovDocument14 pagesReport Has Prepared by Kamran Selimli and Sahil MesimovsahilNo ratings yet
- Name: Marcelina SRN: 1901120020 Class: 5C Course: Statistics Research Methodology Meet 11Document6 pagesName: Marcelina SRN: 1901120020 Class: 5C Course: Statistics Research Methodology Meet 11Marcelina InaaNo ratings yet
- Example Did Berkeley 1.11Document4 pagesExample Did Berkeley 1.11panosx87No ratings yet
- BF IndividualDocument6 pagesBF Individualrajvi prajapatiNo ratings yet
- StatistikDocument4 pagesStatistikAnonymous qADhosNo ratings yet
- Topic: Regression Model (Chapter 3 & 4) : Quantitative AnalysisDocument6 pagesTopic: Regression Model (Chapter 3 & 4) : Quantitative AnalysisAlverdo RicardoNo ratings yet
- Findings and Analysis (ARM)Document4 pagesFindings and Analysis (ARM)wasifaNo ratings yet
- RegressionDocument3 pagesRegressionAdeel NasirNo ratings yet
- SPSS Logistic RegressionDocument4 pagesSPSS Logistic Regressionmushtaque61No ratings yet
- Simple Linear Regression Interpretation PDFDocument2 pagesSimple Linear Regression Interpretation PDFBernard Flores BellezaNo ratings yet
- Lab 6 AnswersDocument14 pagesLab 6 Answerswelcome martinNo ratings yet
- Tugas Analisa Data Regresi Logistik - Amelia Putryanti Sudiono - 1714201039 - 7aDocument7 pagesTugas Analisa Data Regresi Logistik - Amelia Putryanti Sudiono - 1714201039 - 7aAmelia PutryNo ratings yet
- Presentation of Regression ResultsDocument5 pagesPresentation of Regression ResultsElizabeth CollinsNo ratings yet
- Multiple Linear RegressionDocument3 pagesMultiple Linear RegressionVimal PrajapatiNo ratings yet
- Rhonda Hamilton Case Scenario: Exhibit 1 Hamilton'S Regression Model For Electric Utility IndustryDocument34 pagesRhonda Hamilton Case Scenario: Exhibit 1 Hamilton'S Regression Model For Electric Utility IndustryĐặng Xuân ĐỉnhNo ratings yet
- Forecasting For Economics and Business 1St Edition Gloria Gonzalez Rivera Solutions Manual Full Chapter PDFDocument38 pagesForecasting For Economics and Business 1St Edition Gloria Gonzalez Rivera Solutions Manual Full Chapter PDFmiguelstone5tt0f100% (13)
- MGT782 - Assignment 3Document8 pagesMGT782 - Assignment 3arzieismailNo ratings yet
- Simple Linear Regression: Interpreting Minitab OutputDocument4 pagesSimple Linear Regression: Interpreting Minitab Outputrkrajesh86No ratings yet
- Regression 3: Medical Supplies Costs A + (B: Summary OutputDocument2 pagesRegression 3: Medical Supplies Costs A + (B: Summary OutputElliot RichardNo ratings yet
- Using Binary Logistic Analysis For Analyzing BankruptcyDocument5 pagesUsing Binary Logistic Analysis For Analyzing BankruptcyIjbmm JournalNo ratings yet
- Analyisis ResultsDocument11 pagesAnalyisis ResultsQasim ShahNo ratings yet
- Artea - DataDocument1,266 pagesArtea - DataAnh TúNo ratings yet
- Multiple Regression PDFDocument19 pagesMultiple Regression PDFSachen KulandaivelNo ratings yet
- Think Pair Share Team G1 - 7Document8 pagesThink Pair Share Team G1 - 7Akash Kashyap100% (1)
- Interpretasi n47Document8 pagesInterpretasi n47Mahgfira GintingNo ratings yet
- Full Forecasting For Economics and Business 1St Edition Gloria Gonzalez Rivera Solutions Manual Online PDF All ChapterDocument25 pagesFull Forecasting For Economics and Business 1St Edition Gloria Gonzalez Rivera Solutions Manual Online PDF All Chapterrowedanoami100% (5)
- Advanced 11Document19 pagesAdvanced 11Gurmessa GemechuNo ratings yet
- Practical Session 1 SolvedDocument14 pagesPractical Session 1 SolvedThéobald VitouxNo ratings yet
- Multiple Regression Analysis & ApplicationsDocument23 pagesMultiple Regression Analysis & ApplicationsHarshul BansalNo ratings yet
- Activity 5.2 Illana W, Silla KDocument6 pagesActivity 5.2 Illana W, Silla KDanielle M. IllanaNo ratings yet
- Regression AnalysisDocument3 pagesRegression AnalysisSumama IkhlasNo ratings yet
- 1.10 Simple Linear Regression - AnswersDocument22 pages1.10 Simple Linear Regression - AnswersThe SpectreNo ratings yet
- QMB3200 - Project Make UpDocument3 pagesQMB3200 - Project Make UpKateryna TernovaNo ratings yet
- SLRin RDocument23 pagesSLRin RJyo BrahmaraNo ratings yet
- Regression - Binary Logit - QDocument7 pagesRegression - Binary Logit - QfuadNo ratings yet
- LmodelDocument12 pagesLmodelRaghavendra SwamyNo ratings yet
- Practical Examples With STATADocument36 pagesPractical Examples With STATAwudnehkassahun97No ratings yet
- Genre and Institututions Rothery e Stenglin (1997)Document38 pagesGenre and Institututions Rothery e Stenglin (1997)Gabriel LimaNo ratings yet
- CEV633 Tutorial - CHP 2a - QuestionDocument1 pageCEV633 Tutorial - CHP 2a - QuestionRoger FernandezNo ratings yet
- MIKE21 HD ModuleDocument90 pagesMIKE21 HD ModulezariadjiNo ratings yet
- Chapter 5 SIMDocument12 pagesChapter 5 SIMsahle mamoNo ratings yet
- Day 3-8 - A) Setting Up Links For Haka (Voluum)Document24 pagesDay 3-8 - A) Setting Up Links For Haka (Voluum)Shell SusanNo ratings yet
- Line Follower Robot ProjectDocument6 pagesLine Follower Robot ProjectPravin GaretaNo ratings yet
- CerberusmanualDocument141 pagesCerberusmanualapi-3764104No ratings yet
- Tmobile Rebate FormDocument1 pageTmobile Rebate FormSam AbbNo ratings yet
- Ajira ManualDocument36 pagesAjira ManualMartin MugambiNo ratings yet
- List of BapisDocument242 pagesList of BapisAndre RosenthalNo ratings yet
- Python For Finance: Control Flow, Data Structures and First Application (Part 2)Document34 pagesPython For Finance: Control Flow, Data Structures and First Application (Part 2)Sergey BorisovNo ratings yet
- Update Form 0809 May08Document2 pagesUpdate Form 0809 May08mfrerichNo ratings yet
- Prepare 5 Vocabulary Plus Unit 11Document2 pagesPrepare 5 Vocabulary Plus Unit 11abugaienko1005No ratings yet
- Computer Viruses For Dummies Cheat Sheet - For DummiesDocument3 pagesComputer Viruses For Dummies Cheat Sheet - For DummiesGwyneth ZablanNo ratings yet
- AFFIDAVITDocument5 pagesAFFIDAVITPeejay ManejaNo ratings yet
- Project Management Software and How It WorksDocument9 pagesProject Management Software and How It WorkscgalhotraNo ratings yet
- CPCS204-06-LinkedList - Deletion-MergingDocument20 pagesCPCS204-06-LinkedList - Deletion-MerginghffhfNo ratings yet
- Mac vs. PCDocument18 pagesMac vs. PCsleepwlker2410No ratings yet
- GdtsUserGuideV4 10Document96 pagesGdtsUserGuideV4 10mzulkifle07No ratings yet
- Viavi Uplink Interference Case StudyDocument2 pagesViavi Uplink Interference Case StudyAtul DeshpandeNo ratings yet
- Ashwin Resume 2021 Pages DeletedDocument1 pageAshwin Resume 2021 Pages Deletedashwin SureshNo ratings yet
- CfaDocument40 pagesCfaAtiqah NizamNo ratings yet
- CnMaestro 2.2.1 RESTful API - 15-Jul-19Document75 pagesCnMaestro 2.2.1 RESTful API - 15-Jul-19СергейСоханёвNo ratings yet
- StrideDocument1 pageStridea.ibrahimovic1989No ratings yet
- DMGT 504Document31 pagesDMGT 504akshayNo ratings yet
- June 2020 Timetable Zone 4Document13 pagesJune 2020 Timetable Zone 4AriazNo ratings yet
- OFDMDocument137 pagesOFDMedemialemNo ratings yet
- Learn ASPDocument286 pagesLearn ASPapi-3708425100% (1)
- Gowtham Resume SampleDocument3 pagesGowtham Resume SampleGowtham PallekondaNo ratings yet