Download as pdf or txt
You might also like
- Kobelco Excavator Error CodesDocument7 pagesKobelco Excavator Error CodesMaryam86% (57)
- Diabetes DectectionDocument7 pagesDiabetes DectectionDeshigan DhimleeNo ratings yet
- DWDM Lab 3Document10 pagesDWDM Lab 3shreyastha2058No ratings yet
- ML 1 HackDocument2 pagesML 1 Hackrcpit109No ratings yet
- SUMMARYDocument16 pagesSUMMARYStanley OmezieNo ratings yet
- Exp 4Document10 pagesExp 4jayNo ratings yet
- Lab Experiments Vi Sem-1Document10 pagesLab Experiments Vi Sem-1kunnu6263No ratings yet
- Support Vector Machine A) ClassificationDocument3 pagesSupport Vector Machine A) Classification4NM20IS003 ABHISHEK ANo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
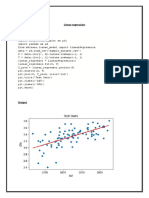
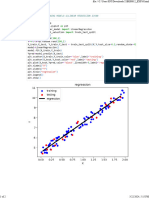
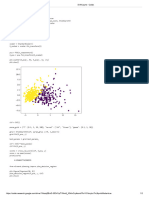
- Linear RegressionDocument2 pagesLinear Regressionanish.t.pNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- Supervised Logistic Tutorial Final PDFDocument9 pagesSupervised Logistic Tutorial Final PDFmichaelkotze03No ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- Linearregression SVMDocument3 pagesLinearregression SVM4023 KeerthanaNo ratings yet
- 7Document1 page7Arjun harishNo ratings yet
- Experiment 5Document6 pagesExperiment 5Nesamanikandan SNo ratings yet
- Neural Networks Report HW2: Pripoae Serbanescu MihaiDocument5 pagesNeural Networks Report HW2: Pripoae Serbanescu MihaiCreepy ChaosNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- MLfullDocument29 pagesMLfullJanvi PatelNo ratings yet
- Experiment No 2 MLDocument3 pagesExperiment No 2 MLANIKET THAKUR [UCOE- 4388]No ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- 21bei0012 Exp10Document2 pages21bei0012 Exp10srujanNo ratings yet
- 20-SE-66 ML Assign 2Document4 pages20-SE-66 ML Assign 2Muhammad Ali EjazNo ratings yet
- XSTK Câu hỏiDocument19 pagesXSTK Câu hỏiimaboneofmyswordNo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- Summary and Discussion Of: "Stability Selection"Document7 pagesSummary and Discussion Of: "Stability Selection"GokuNo ratings yet
- Seguridad MLDocument7 pagesSeguridad MLandres pythonNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- Machine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Document2 pagesMachine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Penchal DoggalaNo ratings yet
- Week 7 Laboratory ActivityDocument12 pagesWeek 7 Laboratory ActivityGar NoobNo ratings yet
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- Time Series Notes9Document32 pagesTime Series Notes9Sam SkywalkerNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- Ml-A2 CodeDocument5 pagesMl-A2 CodeBECOC362Atharva UtekarNo ratings yet
- GyandeepSarmahDocument6 pagesGyandeepSarmahAman Bansal100% (1)
- ASNM Program ExplainDocument4 pagesASNM Program ExplainKesehoNo ratings yet
- Linear Regression - Numpy and SklearnDocument7 pagesLinear Regression - Numpy and SklearnArala FolaNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Maxbox - Starter67 Machine LearningDocument7 pagesMaxbox - Starter67 Machine LearningMax KleinerNo ratings yet
- TutorialDocument27 pagesTutorialxbsdNo ratings yet
- ML Lab 4Document2 pagesML Lab 4trismatthew1234No ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- Tugas Akhir Big DataDocument10 pagesTugas Akhir Big DataSaskya LidayaniNo ratings yet
- ML0101EN Clas Decision Trees Drug Py v1Document12 pagesML0101EN Clas Decision Trees Drug Py v1banicxNo ratings yet
- Tutorial 6Document8 pagesTutorial 6POEASONo ratings yet
- K Nearest NeighborsDocument5 pagesK Nearest NeighborsDerek DegbedzuiNo ratings yet
- Supervidsed AlgorithmDocument19 pagesSupervidsed AlgorithmMittu RajareddyNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Scikit LearnDocument17 pagesScikit LearnRRNo ratings yet
- 244.ml4 (1)Document5 pages244.ml4 (1)saitejakasani091No ratings yet
- Himmatun Najah - SVM SVR Data MiningDocument12 pagesHimmatun Najah - SVM SVR Data MiningHimma RubyNo ratings yet
- ML With Python PracticalDocument22 pagesML With Python Practicaln58648017No ratings yet
- OhkkwellDocument1 pageOhkkwellshivkumar620400No ratings yet
- SionDocument2 pagesSionsai prashanthNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Ass 4Document4 pagesAss 4Vedant AndhaleNo ratings yet
- Role of Mid-Day Meal SchemeDocument3 pagesRole of Mid-Day Meal SchemekishorebharathNo ratings yet
- Tu Vung Ngu Phap Bai Tap Global Success 8Document8 pagesTu Vung Ngu Phap Bai Tap Global Success 8Han LangNo ratings yet
- 1 Introduction of GeophysicsDocument7 pages1 Introduction of GeophysicsAl MamunNo ratings yet
- F1102 GPRS Intelligent Modem USER MANUAL PDFDocument30 pagesF1102 GPRS Intelligent Modem USER MANUAL PDFChelsea MedellinNo ratings yet
- Feed Formulation Manual 2017Document40 pagesFeed Formulation Manual 2017Jennifer Legaspi86% (7)
- Shark Finning Final DraftDocument11 pagesShark Finning Final Draftilana lutzNo ratings yet
- Abhishek AnandDocument1 pageAbhishek AnandPritanshi AnandNo ratings yet
- Integrate Pentaho With MapR Using Apache DrillDocument13 pagesIntegrate Pentaho With MapR Using Apache DrillDat TranNo ratings yet
- Enclosed Conductor Rail Boxline Program 0842: WWW - Conductix.UsDocument28 pagesEnclosed Conductor Rail Boxline Program 0842: WWW - Conductix.UsElsad HuseynovNo ratings yet
- Rahul 132Document67 pagesRahul 132gulatisrishti15No ratings yet
- Supervisi Perawat Primer Perawat Associate Dalam MDocument7 pagesSupervisi Perawat Primer Perawat Associate Dalam MFlorida BhokiNo ratings yet
- Samsung CLX-2160 (Service Manual)Document158 pagesSamsung CLX-2160 (Service Manual)info3551No ratings yet
- Boral Partiwall and Fire Wall Class 1aDocument28 pagesBoral Partiwall and Fire Wall Class 1aRaja RajanNo ratings yet
- Tushar MalhotraDocument54 pagesTushar MalhotraAkash BhadalaNo ratings yet
- Joy Hermalyn CV 2020Document5 pagesJoy Hermalyn CV 2020api-518378178No ratings yet
- Themes of A Story: - To Build A Fire: Instinctual Knowledge vs. Scientific KnowledgeDocument3 pagesThemes of A Story: - To Build A Fire: Instinctual Knowledge vs. Scientific Knowledgemoin khanNo ratings yet
- Springs Are Fundamental Mechanical Components Found in Many Mechanical SystemsDocument4 pagesSprings Are Fundamental Mechanical Components Found in Many Mechanical SystemsZandro GagoteNo ratings yet
- Integer Programming Part 2Document41 pagesInteger Programming Part 2missMITNo ratings yet
- What Is Seed and Angel FundingDocument2 pagesWhat Is Seed and Angel FundingQueen ValleNo ratings yet
- Proof of The Orthogonality RelationsDocument3 pagesProof of The Orthogonality RelationsDeepikaNo ratings yet
- Project On UnileverDocument27 pagesProject On Unileverirfan103158100% (1)
- Playground Safety StandardDocument2 pagesPlayground Safety StandardJer FortzNo ratings yet
- Office of The RegistrarDocument3 pagesOffice of The RegistrarAdemolaNo ratings yet
- The Warren Buffet Portfolio - SUMMARY NOTESDocument33 pagesThe Warren Buffet Portfolio - SUMMARY NOTESMMMMM99999100% (1)
- Textbook Mapping Modernisms Art Indigeneity Colonialism Elizabeth Harney Ebook All Chapter PDFDocument53 pagesTextbook Mapping Modernisms Art Indigeneity Colonialism Elizabeth Harney Ebook All Chapter PDFcharles.valle114100% (11)
- PTR 38Document23 pagesPTR 38CyNo ratings yet
- Compact Phase Shifter For 4G Base Station AntennaDocument2 pagesCompact Phase Shifter For 4G Base Station AntennaDo SonNo ratings yet
- Molecular Biology: Laboratory Safety and PrecautionDocument7 pagesMolecular Biology: Laboratory Safety and PrecautionSamantha100% (1)
- Akanksha Ranjan Christ (Deemed To Be University) RESUMEDocument2 pagesAkanksha Ranjan Christ (Deemed To Be University) RESUMEAkanksha Ranjan 2028039No ratings yet