
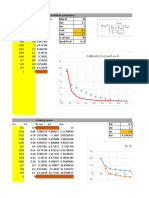
FracaFlow Petrel Comparison
FracaFlow Petrel Comparison
You might also like
- IGCSE Math Core Ext SODocument32 pagesIGCSE Math Core Ext SOhang yinNo ratings yet
- Pei ViewDocument38 pagesPei ViewEnrique TorresNo ratings yet
- CH 7 Linear FunctionsDocument34 pagesCH 7 Linear FunctionsHarry White100% (1)
- Contact Quality CheckDocument12 pagesContact Quality Checkc_b_umashankarNo ratings yet
- Using Multidisciplinary Multiscale Data To Create Nonstationary Facies Probability Trend ModelsDocument16 pagesUsing Multidisciplinary Multiscale Data To Create Nonstationary Facies Probability Trend ModelspggeologistNo ratings yet
- How To Create Stamp Plots: PETREL 2009.2Document14 pagesHow To Create Stamp Plots: PETREL 2009.2Muhamad Afiq RosnanNo ratings yet
- Vasilev2016 Interference TestDocument28 pagesVasilev2016 Interference TestAmr HegazyNo ratings yet
- SPE 150760 Efficient Methodology For Stimulation Candidate Selection and Well Workover OptimizationDocument14 pagesSPE 150760 Efficient Methodology For Stimulation Candidate Selection and Well Workover OptimizationVlassis SarantinosNo ratings yet
- Global Energy Perspective 2023Document26 pagesGlobal Energy Perspective 2023Andi IrawanNo ratings yet
- Res Minggu 1Document55 pagesRes Minggu 1Gh4n113 IdNo ratings yet
- 2 Dimensional Streamline SimulationDocument9 pages2 Dimensional Streamline Simulationpjy21257No ratings yet
- Case Reservoir 2023Document13 pagesCase Reservoir 2023LuciastNo ratings yet
- ENG Petrel AveragePorosity NTG Facies Per Zone 3Q15Document7 pagesENG Petrel AveragePorosity NTG Facies Per Zone 3Q15Rodrigo BatistaNo ratings yet
- Petrel Workflow - A Walkaround To Create Well Tops Display List - 7586416 - 03Document5 pagesPetrel Workflow - A Walkaround To Create Well Tops Display List - 7586416 - 03krackku kNo ratings yet
- BP Energy Outlook 2023Document66 pagesBP Energy Outlook 2023Danna Lizeth Rueda ParedesNo ratings yet
- Week 9b - Adjunct Lecture Polymer Flooding 1 Apr 2021 PDFDocument37 pagesWeek 9b - Adjunct Lecture Polymer Flooding 1 Apr 2021 PDFHaries SeptiyawanNo ratings yet
- Ch1 Advanced Reservoir Engineering 2007Document78 pagesCh1 Advanced Reservoir Engineering 2007RrelicNo ratings yet
- Eor 3Document49 pagesEor 3mohsen ahmed thabetNo ratings yet
- F (X) 1130 Exp ( - 0.044 X) R 1: Base ModelDocument9 pagesF (X) 1130 Exp ( - 0.044 X) R 1: Base ModelFabio ChavezNo ratings yet
- Exponential Decline Curve: STB/MDocument10 pagesExponential Decline Curve: STB/MNurhabibahNo ratings yet
- ANPG Roadshows 2020 English WebDocument86 pagesANPG Roadshows 2020 English WebVenkat PachaNo ratings yet
- Breakouts CompressorsDocument10 pagesBreakouts CompressorsarispriyatmonoNo ratings yet
- K Relative PermeabilityDocument13 pagesK Relative PermeabilityTripoli ManoNo ratings yet
- Tutorial Material Balance Water InfluxDocument8 pagesTutorial Material Balance Water Influxsameer bakshiNo ratings yet
- Calibrate CWD and Awd: Max PC Swi Sor CWD Awd % Oil Wet SW at PC 0Document5 pagesCalibrate CWD and Awd: Max PC Swi Sor CWD Awd % Oil Wet SW at PC 0AiwarikiaarNo ratings yet
- S1 DataDocument12 pagesS1 DatagregNo ratings yet
- Reservoir ReportDocument48 pagesReservoir ReportMustapha BouregaaNo ratings yet
- Original Gas in PlaceDocument2 pagesOriginal Gas in PlaceGabrielaMSNo ratings yet
- SimRes 3 Grid 1D 1 FasaDocument14 pagesSimRes 3 Grid 1D 1 FasarrobikhunNo ratings yet
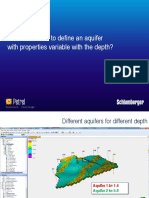
- Petrel RE: How To Define An Aquifer With Properties Variable With The Depth?Document7 pagesPetrel RE: How To Define An Aquifer With Properties Variable With The Depth?mcemceNo ratings yet
- PVT ExcelDocument8 pagesPVT ExcelolaseyeNo ratings yet
- TekGas SugiDocument9 pagesTekGas SugisugiantoNo ratings yet
- Depositional Environments and SystemsDocument24 pagesDepositional Environments and SystemsaliNo ratings yet
- Matrices One Shot #BBDocument158 pagesMatrices One Shot #BBPoonam JainNo ratings yet
- Harms - Optimizing Compressors - Part 2Document31 pagesHarms - Optimizing Compressors - Part 2arispriyatmonoNo ratings yet
- Capillary Pressure Pore Size Distribution TutorialDocument3 pagesCapillary Pressure Pore Size Distribution Tutorialarjun2014No ratings yet
- To Determine The Minimum Miscibility Pressure by Using Different CorrelationDocument21 pagesTo Determine The Minimum Miscibility Pressure by Using Different CorrelationahmedNo ratings yet
- Swiir 48,859 2: Pressure Vs Brine Saturation (De-Normalisasi)Document32 pagesSwiir 48,859 2: Pressure Vs Brine Saturation (De-Normalisasi)Meulana Fajariadi VicadimasNo ratings yet
- 4 Presentation Hacksma Continuous Gas CirculationDocument28 pages4 Presentation Hacksma Continuous Gas CirculationRrelicNo ratings yet
- Imprimir Reser FinalDocument4 pagesImprimir Reser FinalvanesaNo ratings yet
- BACHELOR OF PHYSIOTHERAPY Ist YEARDocument34 pagesBACHELOR OF PHYSIOTHERAPY Ist YEARdurgesh yadavNo ratings yet
- Solution 2-2 Relative PermeabilityDocument8 pagesSolution 2-2 Relative Permeabilitymhuf89No ratings yet
- Gas Well LoadingDocument9 pagesGas Well LoadingalyshahNo ratings yet
- TotalEnergies Energy Outlook 2022Document42 pagesTotalEnergies Energy Outlook 2022Pangeran Christofel Yoshua SilalahiNo ratings yet
- Chem CH 11 NIE Premium NOtesDocument22 pagesChem CH 11 NIE Premium NOtesmuhammadmansuri815No ratings yet
- Evaluation of Polymeric Materials For ChemEORDocument45 pagesEvaluation of Polymeric Materials For ChemEORIhsan ArifNo ratings yet
- OTC - The Future of Offshore TechnologyDocument16 pagesOTC - The Future of Offshore TechnologyVillalba-Tapia EdwinNo ratings yet
- Aldehyde Ketone Carboxylic Acid IDocument20 pagesAldehyde Ketone Carboxylic Acid IAman KeshariNo ratings yet
- 11 Alcohols Phenols and Ethers 1Document35 pages11 Alcohols Phenols and Ethers 1Aswath SNo ratings yet
- Split and MergeDocument36 pagesSplit and MergeFelipe GualsaquiNo ratings yet
- Equilibration Exercise OriginalDocument90 pagesEquilibration Exercise OriginaldiegoNo ratings yet
- Activities Data Handout SenergyDocument28 pagesActivities Data Handout SenergynvnvNo ratings yet
- Haloalkane & HaloarenesDocument19 pagesHaloalkane & HaloarenesAnusha SharmaNo ratings yet
- Organic Halides Live Class-6 Teacher NotesDocument28 pagesOrganic Halides Live Class-6 Teacher Notessiddhartha singhNo ratings yet
- Permeabilitas Relatif Hasil SCAL Sistem Gas-Air: SW, FraksiDocument6 pagesPermeabilitas Relatif Hasil SCAL Sistem Gas-Air: SW, FraksiRarasati KusumawardhaniNo ratings yet
- Ch3 Steam Turbine System - BoilerDocument49 pagesCh3 Steam Turbine System - BoilerAzraqul Ilmi100% (1)
- Well EconomicsDocument571 pagesWell Economics10manbearpig01No ratings yet
- Alcohol Phenol and Ether FinalDocument33 pagesAlcohol Phenol and Ether FinalC.S. KrithikNo ratings yet
- PC & Rel. PermDocument150 pagesPC & Rel. PermRestyanti YunseNo ratings yet
- Tugas TekresDocument4 pagesTugas TekresAdli Rahadian IrfreeNo ratings yet
- Alcohol Phenol Ether (1) 6Document9 pagesAlcohol Phenol Ether (1) 6sdnishacNo ratings yet
- Chem CH 12 NIE Premium NOtesDocument22 pagesChem CH 12 NIE Premium NOtesansarahmad6931No ratings yet
- Hydrocarbon Fluid Inclusions in Petroliferous BasinsFrom EverandHydrocarbon Fluid Inclusions in Petroliferous BasinsNo ratings yet
- C3 Differentiation Topic AssessmentDocument5 pagesC3 Differentiation Topic Assessmentamandeep kaurNo ratings yet
- Paper 11 Sem-5 Vbu & Bbmku Guess PaperDocument37 pagesPaper 11 Sem-5 Vbu & Bbmku Guess Papernnbhbbb83No ratings yet
- Vector Analysis 2021-2022 Sanoar Molla: Assistant Professor Rammohan College, CU Whatsapp: 9163530503Document40 pagesVector Analysis 2021-2022 Sanoar Molla: Assistant Professor Rammohan College, CU Whatsapp: 9163530503payigiyNo ratings yet
- Lovely Professional University: PunjabDocument18 pagesLovely Professional University: PunjabPuru RajNo ratings yet
- Applications of Differentiation PDFDocument9 pagesApplications of Differentiation PDFKeri-ann MillarNo ratings yet
- PHYSICS-Engineering-First-Year Notes, Books, Ebook PDF Download PDFDocument205 pagesPHYSICS-Engineering-First-Year Notes, Books, Ebook PDF Download PDFVinnie SinghNo ratings yet
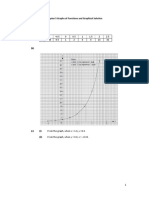
- Chapter 5 Graphs of Functions and Graphical Solution Exercise 5B 1. (A) 4 X - 1 - 0.5 0 0.5 1 1.5 2 2.5 y 0.25 0.5 1 2 4 8 16 32 (B)Document8 pagesChapter 5 Graphs of Functions and Graphical Solution Exercise 5B 1. (A) 4 X - 1 - 0.5 0 0.5 1 1.5 2 2.5 y 0.25 0.5 1 2 4 8 16 32 (B)Ashley HongNo ratings yet
- Lecture 6 - Ridge Regression, Polynomial Regression (DONE!!) PDFDocument26 pagesLecture 6 - Ridge Regression, Polynomial Regression (DONE!!) PDFSharelle TewNo ratings yet
- Line Integrals in The Plane: 4. 4A. Plane Vector FieldsDocument7 pagesLine Integrals in The Plane: 4. 4A. Plane Vector FieldsShaip DautiNo ratings yet
- Darcy S Law and The Field Equations of The Flow of Underground FluidsDocument38 pagesDarcy S Law and The Field Equations of The Flow of Underground FluidsAnonymous BVbpSENo ratings yet
- 2020 Calculus 3-1tangent and NormalDocument18 pages2020 Calculus 3-1tangent and NormalKer Yin YapNo ratings yet
- Ai Mod3@Azdocuments - inDocument42 pagesAi Mod3@Azdocuments - inK SubramanyeshwaraNo ratings yet
- PHY103A: Lecture # 2: Semester II, 2017-18 Department of Physics, IIT KanpurDocument21 pagesPHY103A: Lecture # 2: Semester II, 2017-18 Department of Physics, IIT KanpurSABARI BALANo ratings yet
- Solutions 4Document4 pagesSolutions 4Mohanarajan Mohan KumarNo ratings yet
- Composition of Functions of Several VariablesDocument2 pagesComposition of Functions of Several VariablesAmiin HirphoNo ratings yet
- Sunshading GeophysicsDocument2 pagesSunshading GeophysicsHerbert MohriNo ratings yet
- Introduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsDocument47 pagesIntroduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsSeyed SadeghNo ratings yet
- Chapter 05Document32 pagesChapter 05richaNo ratings yet
- Presentasi 25 Jun ModifiDocument26 pagesPresentasi 25 Jun ModifiMarvin Satrio UtomoNo ratings yet
- Equation of A Straight Line - Gradient and Intercept by WWW - Mathematics.me - UkDocument3 pagesEquation of A Straight Line - Gradient and Intercept by WWW - Mathematics.me - UkrodwellheadNo ratings yet
- Unit I: Electromagnetic TheoryDocument139 pagesUnit I: Electromagnetic TheoryDependra SinghNo ratings yet
- Adjoints and Automatic (Algorithmic) Dierentiation in Computational NanceDocument25 pagesAdjoints and Automatic (Algorithmic) Dierentiation in Computational NanceArnaud NekamNo ratings yet
- VIBSHELLDocument426 pagesVIBSHELLNaresh JonnaNo ratings yet
- 2.3 - Theorems On Gradient, Divergent & CurlDocument13 pages2.3 - Theorems On Gradient, Divergent & CurlindraNo ratings yet
- Chapter2 Answers 3rdDocument24 pagesChapter2 Answers 3rdAbd Elrahman RashadNo ratings yet
- Brannon - Large Deformation KinematicsDocument66 pagesBrannon - Large Deformation KinematicsPatrick SummersNo ratings yet
- Calculus III CompleteDocument287 pagesCalculus III CompleteMaestro King MagnificoNo ratings yet























































































Download as pdf or txt
You might also like
- IGCSE Math Core Ext SODocument32 pagesIGCSE Math Core Ext SOhang yinNo ratings yet
- Pei ViewDocument38 pagesPei ViewEnrique TorresNo ratings yet
- CH 7 Linear FunctionsDocument34 pagesCH 7 Linear FunctionsHarry White100% (1)
- Contact Quality CheckDocument12 pagesContact Quality Checkc_b_umashankarNo ratings yet
- Using Multidisciplinary Multiscale Data To Create Nonstationary Facies Probability Trend ModelsDocument16 pagesUsing Multidisciplinary Multiscale Data To Create Nonstationary Facies Probability Trend ModelspggeologistNo ratings yet
- How To Create Stamp Plots: PETREL 2009.2Document14 pagesHow To Create Stamp Plots: PETREL 2009.2Muhamad Afiq RosnanNo ratings yet
- Vasilev2016 Interference TestDocument28 pagesVasilev2016 Interference TestAmr HegazyNo ratings yet
- SPE 150760 Efficient Methodology For Stimulation Candidate Selection and Well Workover OptimizationDocument14 pagesSPE 150760 Efficient Methodology For Stimulation Candidate Selection and Well Workover OptimizationVlassis SarantinosNo ratings yet
- Global Energy Perspective 2023Document26 pagesGlobal Energy Perspective 2023Andi IrawanNo ratings yet
- Res Minggu 1Document55 pagesRes Minggu 1Gh4n113 IdNo ratings yet
- 2 Dimensional Streamline SimulationDocument9 pages2 Dimensional Streamline Simulationpjy21257No ratings yet
- Case Reservoir 2023Document13 pagesCase Reservoir 2023LuciastNo ratings yet
- ENG Petrel AveragePorosity NTG Facies Per Zone 3Q15Document7 pagesENG Petrel AveragePorosity NTG Facies Per Zone 3Q15Rodrigo BatistaNo ratings yet
- Petrel Workflow - A Walkaround To Create Well Tops Display List - 7586416 - 03Document5 pagesPetrel Workflow - A Walkaround To Create Well Tops Display List - 7586416 - 03krackku kNo ratings yet
- BP Energy Outlook 2023Document66 pagesBP Energy Outlook 2023Danna Lizeth Rueda ParedesNo ratings yet
- Week 9b - Adjunct Lecture Polymer Flooding 1 Apr 2021 PDFDocument37 pagesWeek 9b - Adjunct Lecture Polymer Flooding 1 Apr 2021 PDFHaries SeptiyawanNo ratings yet
- Ch1 Advanced Reservoir Engineering 2007Document78 pagesCh1 Advanced Reservoir Engineering 2007RrelicNo ratings yet
- Eor 3Document49 pagesEor 3mohsen ahmed thabetNo ratings yet
- F (X) 1130 Exp ( - 0.044 X) R 1: Base ModelDocument9 pagesF (X) 1130 Exp ( - 0.044 X) R 1: Base ModelFabio ChavezNo ratings yet
- Exponential Decline Curve: STB/MDocument10 pagesExponential Decline Curve: STB/MNurhabibahNo ratings yet
- ANPG Roadshows 2020 English WebDocument86 pagesANPG Roadshows 2020 English WebVenkat PachaNo ratings yet
- Breakouts CompressorsDocument10 pagesBreakouts CompressorsarispriyatmonoNo ratings yet
- K Relative PermeabilityDocument13 pagesK Relative PermeabilityTripoli ManoNo ratings yet
- Tutorial Material Balance Water InfluxDocument8 pagesTutorial Material Balance Water Influxsameer bakshiNo ratings yet
- Calibrate CWD and Awd: Max PC Swi Sor CWD Awd % Oil Wet SW at PC 0Document5 pagesCalibrate CWD and Awd: Max PC Swi Sor CWD Awd % Oil Wet SW at PC 0AiwarikiaarNo ratings yet
- S1 DataDocument12 pagesS1 DatagregNo ratings yet
- Reservoir ReportDocument48 pagesReservoir ReportMustapha BouregaaNo ratings yet
- Original Gas in PlaceDocument2 pagesOriginal Gas in PlaceGabrielaMSNo ratings yet
- SimRes 3 Grid 1D 1 FasaDocument14 pagesSimRes 3 Grid 1D 1 FasarrobikhunNo ratings yet
- Petrel RE: How To Define An Aquifer With Properties Variable With The Depth?Document7 pagesPetrel RE: How To Define An Aquifer With Properties Variable With The Depth?mcemceNo ratings yet
- PVT ExcelDocument8 pagesPVT ExcelolaseyeNo ratings yet
- TekGas SugiDocument9 pagesTekGas SugisugiantoNo ratings yet
- Depositional Environments and SystemsDocument24 pagesDepositional Environments and SystemsaliNo ratings yet
- Matrices One Shot #BBDocument158 pagesMatrices One Shot #BBPoonam JainNo ratings yet
- Harms - Optimizing Compressors - Part 2Document31 pagesHarms - Optimizing Compressors - Part 2arispriyatmonoNo ratings yet
- Capillary Pressure Pore Size Distribution TutorialDocument3 pagesCapillary Pressure Pore Size Distribution Tutorialarjun2014No ratings yet
- To Determine The Minimum Miscibility Pressure by Using Different CorrelationDocument21 pagesTo Determine The Minimum Miscibility Pressure by Using Different CorrelationahmedNo ratings yet
- Swiir 48,859 2: Pressure Vs Brine Saturation (De-Normalisasi)Document32 pagesSwiir 48,859 2: Pressure Vs Brine Saturation (De-Normalisasi)Meulana Fajariadi VicadimasNo ratings yet
- 4 Presentation Hacksma Continuous Gas CirculationDocument28 pages4 Presentation Hacksma Continuous Gas CirculationRrelicNo ratings yet
- Imprimir Reser FinalDocument4 pagesImprimir Reser FinalvanesaNo ratings yet
- BACHELOR OF PHYSIOTHERAPY Ist YEARDocument34 pagesBACHELOR OF PHYSIOTHERAPY Ist YEARdurgesh yadavNo ratings yet
- Solution 2-2 Relative PermeabilityDocument8 pagesSolution 2-2 Relative Permeabilitymhuf89No ratings yet
- Gas Well LoadingDocument9 pagesGas Well LoadingalyshahNo ratings yet
- TotalEnergies Energy Outlook 2022Document42 pagesTotalEnergies Energy Outlook 2022Pangeran Christofel Yoshua SilalahiNo ratings yet
- Chem CH 11 NIE Premium NOtesDocument22 pagesChem CH 11 NIE Premium NOtesmuhammadmansuri815No ratings yet
- Evaluation of Polymeric Materials For ChemEORDocument45 pagesEvaluation of Polymeric Materials For ChemEORIhsan ArifNo ratings yet
- OTC - The Future of Offshore TechnologyDocument16 pagesOTC - The Future of Offshore TechnologyVillalba-Tapia EdwinNo ratings yet
- Aldehyde Ketone Carboxylic Acid IDocument20 pagesAldehyde Ketone Carboxylic Acid IAman KeshariNo ratings yet
- 11 Alcohols Phenols and Ethers 1Document35 pages11 Alcohols Phenols and Ethers 1Aswath SNo ratings yet
- Split and MergeDocument36 pagesSplit and MergeFelipe GualsaquiNo ratings yet
- Equilibration Exercise OriginalDocument90 pagesEquilibration Exercise OriginaldiegoNo ratings yet
- Activities Data Handout SenergyDocument28 pagesActivities Data Handout SenergynvnvNo ratings yet
- Haloalkane & HaloarenesDocument19 pagesHaloalkane & HaloarenesAnusha SharmaNo ratings yet
- Organic Halides Live Class-6 Teacher NotesDocument28 pagesOrganic Halides Live Class-6 Teacher Notessiddhartha singhNo ratings yet
- Permeabilitas Relatif Hasil SCAL Sistem Gas-Air: SW, FraksiDocument6 pagesPermeabilitas Relatif Hasil SCAL Sistem Gas-Air: SW, FraksiRarasati KusumawardhaniNo ratings yet
- Ch3 Steam Turbine System - BoilerDocument49 pagesCh3 Steam Turbine System - BoilerAzraqul Ilmi100% (1)
- Well EconomicsDocument571 pagesWell Economics10manbearpig01No ratings yet
- Alcohol Phenol and Ether FinalDocument33 pagesAlcohol Phenol and Ether FinalC.S. KrithikNo ratings yet
- PC & Rel. PermDocument150 pagesPC & Rel. PermRestyanti YunseNo ratings yet
- Tugas TekresDocument4 pagesTugas TekresAdli Rahadian IrfreeNo ratings yet
- Alcohol Phenol Ether (1) 6Document9 pagesAlcohol Phenol Ether (1) 6sdnishacNo ratings yet
- Chem CH 12 NIE Premium NOtesDocument22 pagesChem CH 12 NIE Premium NOtesansarahmad6931No ratings yet
- Hydrocarbon Fluid Inclusions in Petroliferous BasinsFrom EverandHydrocarbon Fluid Inclusions in Petroliferous BasinsNo ratings yet
- C3 Differentiation Topic AssessmentDocument5 pagesC3 Differentiation Topic Assessmentamandeep kaurNo ratings yet
- Paper 11 Sem-5 Vbu & Bbmku Guess PaperDocument37 pagesPaper 11 Sem-5 Vbu & Bbmku Guess Papernnbhbbb83No ratings yet
- Vector Analysis 2021-2022 Sanoar Molla: Assistant Professor Rammohan College, CU Whatsapp: 9163530503Document40 pagesVector Analysis 2021-2022 Sanoar Molla: Assistant Professor Rammohan College, CU Whatsapp: 9163530503payigiyNo ratings yet
- Lovely Professional University: PunjabDocument18 pagesLovely Professional University: PunjabPuru RajNo ratings yet
- Applications of Differentiation PDFDocument9 pagesApplications of Differentiation PDFKeri-ann MillarNo ratings yet
- PHYSICS-Engineering-First-Year Notes, Books, Ebook PDF Download PDFDocument205 pagesPHYSICS-Engineering-First-Year Notes, Books, Ebook PDF Download PDFVinnie SinghNo ratings yet
- Chapter 5 Graphs of Functions and Graphical Solution Exercise 5B 1. (A) 4 X - 1 - 0.5 0 0.5 1 1.5 2 2.5 y 0.25 0.5 1 2 4 8 16 32 (B)Document8 pagesChapter 5 Graphs of Functions and Graphical Solution Exercise 5B 1. (A) 4 X - 1 - 0.5 0 0.5 1 1.5 2 2.5 y 0.25 0.5 1 2 4 8 16 32 (B)Ashley HongNo ratings yet
- Lecture 6 - Ridge Regression, Polynomial Regression (DONE!!) PDFDocument26 pagesLecture 6 - Ridge Regression, Polynomial Regression (DONE!!) PDFSharelle TewNo ratings yet
- Line Integrals in The Plane: 4. 4A. Plane Vector FieldsDocument7 pagesLine Integrals in The Plane: 4. 4A. Plane Vector FieldsShaip DautiNo ratings yet
- Darcy S Law and The Field Equations of The Flow of Underground FluidsDocument38 pagesDarcy S Law and The Field Equations of The Flow of Underground FluidsAnonymous BVbpSENo ratings yet
- 2020 Calculus 3-1tangent and NormalDocument18 pages2020 Calculus 3-1tangent and NormalKer Yin YapNo ratings yet
- Ai Mod3@Azdocuments - inDocument42 pagesAi Mod3@Azdocuments - inK SubramanyeshwaraNo ratings yet
- PHY103A: Lecture # 2: Semester II, 2017-18 Department of Physics, IIT KanpurDocument21 pagesPHY103A: Lecture # 2: Semester II, 2017-18 Department of Physics, IIT KanpurSABARI BALANo ratings yet
- Solutions 4Document4 pagesSolutions 4Mohanarajan Mohan KumarNo ratings yet
- Composition of Functions of Several VariablesDocument2 pagesComposition of Functions of Several VariablesAmiin HirphoNo ratings yet
- Sunshading GeophysicsDocument2 pagesSunshading GeophysicsHerbert MohriNo ratings yet
- Introduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsDocument47 pagesIntroduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsSeyed SadeghNo ratings yet
- Chapter 05Document32 pagesChapter 05richaNo ratings yet
- Presentasi 25 Jun ModifiDocument26 pagesPresentasi 25 Jun ModifiMarvin Satrio UtomoNo ratings yet
- Equation of A Straight Line - Gradient and Intercept by WWW - Mathematics.me - UkDocument3 pagesEquation of A Straight Line - Gradient and Intercept by WWW - Mathematics.me - UkrodwellheadNo ratings yet
- Unit I: Electromagnetic TheoryDocument139 pagesUnit I: Electromagnetic TheoryDependra SinghNo ratings yet
- Adjoints and Automatic (Algorithmic) Dierentiation in Computational NanceDocument25 pagesAdjoints and Automatic (Algorithmic) Dierentiation in Computational NanceArnaud NekamNo ratings yet
- VIBSHELLDocument426 pagesVIBSHELLNaresh JonnaNo ratings yet
- 2.3 - Theorems On Gradient, Divergent & CurlDocument13 pages2.3 - Theorems On Gradient, Divergent & CurlindraNo ratings yet
- Chapter2 Answers 3rdDocument24 pagesChapter2 Answers 3rdAbd Elrahman RashadNo ratings yet
- Brannon - Large Deformation KinematicsDocument66 pagesBrannon - Large Deformation KinematicsPatrick SummersNo ratings yet
- Calculus III CompleteDocument287 pagesCalculus III CompleteMaestro King MagnificoNo ratings yet