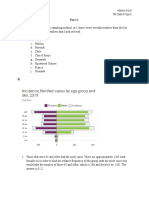
Download as docx, pdf, or txt
You might also like
- TB Data Project Part I To IVDocument23 pagesTB Data Project Part I To IVapi-354324979100% (1)
- Statistics Data ProjectDocument16 pagesStatistics Data Projectapi-250861401No ratings yet
- TB Data ProjectDocument14 pagesTB Data Projectapi-494772302No ratings yet
- Assesment of Risks From High Pressure Natural Gas PipeleinesDocument62 pagesAssesment of Risks From High Pressure Natural Gas Pipeleinesthawdar100% (1)
- The Ultimate YatchmasterDocument382 pagesThe Ultimate Yatchmasterkaikomc100% (1)
- TB Data Project FinalDocument13 pagesTB Data Project Finalapi-710388970No ratings yet
- Math Project CombinedDocument19 pagesMath Project Combinedapi-461405824No ratings yet
- Project Part 1 1018Document6 pagesProject Part 1 1018marwa alqaderiNo ratings yet
- Final Final 23 Stats Tbdata ProjectDocument14 pagesFinal Final 23 Stats Tbdata Projectapi-242534218No ratings yet
- TB Data Project All PartsDocument17 pagesTB Data Project All Partsapi-708741273No ratings yet
- Project Part 1 1018 1Document7 pagesProject Part 1 1018 1marwa alqaderiNo ratings yet
- Unit 5 Exam Review AnswersDocument6 pagesUnit 5 Exam Review AnswerssmothersdkenyonNo ratings yet
- Math 1040 ProjectDocument13 pagesMath 1040 Projectapi-664721593No ratings yet
- Final Project Math 1040Document16 pagesFinal Project Math 1040api-454291387No ratings yet
- TB Data Project 1Document9 pagesTB Data Project 1api-495040148No ratings yet
- TB Data Project 3Document18 pagesTB Data Project 3api-312475656No ratings yet
- GE - FEL DP 101 - R Programming ActivityDocument20 pagesGE - FEL DP 101 - R Programming ActivityLois Ira LimNo ratings yet
- Finals ReviewerDocument4 pagesFinals ReviewerGabrielli Anthonete MoradaNo ratings yet
- 10.1 REVIEW (For Quiz) NAME: - ANSWER KEY - : Men Women Completed Still Enrolled Dropped OutDocument6 pages10.1 REVIEW (For Quiz) NAME: - ANSWER KEY - : Men Women Completed Still Enrolled Dropped OutPhan Vinh PhongNo ratings yet
- Chapter 4 Sample SizeDocument28 pagesChapter 4 Sample Sizetemesgen yohannesNo ratings yet
- Quiz Part ADocument15 pagesQuiz Part AKaranNo ratings yet
- Chi SquareDocument25 pagesChi SquareJoseMelarte GoocoJr.No ratings yet
- 5 Session 18-19 (Z-Test and T-Test)Document28 pages5 Session 18-19 (Z-Test and T-Test)Shaira CogollodoNo ratings yet
- Week 11: Review Before New: After Watching The Video, Please Answer The Following QuestionsDocument8 pagesWeek 11: Review Before New: After Watching The Video, Please Answer The Following QuestionsDivyaNo ratings yet
- Tests of HypothesisDocument48 pagesTests of HypothesisDenmark Aleluya0% (1)
- Statistics FinalsDocument23 pagesStatistics FinalsToshinori YagiNo ratings yet
- Final Exam S1 2018 SolutionsDocument13 pagesFinal Exam S1 2018 SolutionsxanNo ratings yet
- Chapter 5Document12 pagesChapter 5Muhammad NoumanNo ratings yet
- 2009 Who Should Pay For DateDocument4 pages2009 Who Should Pay For DateteachopensourceNo ratings yet
- Stat Prob Q4 Module 4Document20 pagesStat Prob Q4 Module 4Lailanie Fortu0% (1)
- Inferential StatisticsDocument13 pagesInferential StatisticsVincentius Invictus TanoraNo ratings yet
- 16-17 Chapter 10 Quiz ReviewDocument6 pages16-17 Chapter 10 Quiz Reviewthunderboost123No ratings yet
- Full Skittles ProjectDocument13 pagesFull Skittles Projectapi-537189505No ratings yet
- Horizon Group Eco 204 Term PaperDocument10 pagesHorizon Group Eco 204 Term Paperআহনাফ গালিবNo ratings yet
- Class Work 3Document5 pagesClass Work 3kaszulu1No ratings yet
- TB Combined DataDocument8 pagesTB Combined Dataapi-584009212No ratings yet
- W8 Hypothesis TestingDocument18 pagesW8 Hypothesis TestingThu PhươngNo ratings yet
- Tests With More Than Two Independent Samples - The Kruskal-Wallis TestDocument7 pagesTests With More Than Two Independent Samples - The Kruskal-Wallis TestIL MareNo ratings yet
- Critical Appraisal For Diagnostic Study: Step 1: Are The Results of The Study Valid?Document3 pagesCritical Appraisal For Diagnostic Study: Step 1: Are The Results of The Study Valid?ainihanifiahNo ratings yet
- Statistics and ProbabilityDocument6 pagesStatistics and ProbabilityRonaldNo ratings yet
- Hypothesis Testing Part IDocument8 pagesHypothesis Testing Part IAbi AbeNo ratings yet
- AshleyBriones Homework Module5Document2 pagesAshleyBriones Homework Module5milove4uNo ratings yet
- Stat 1x1 Final Exam Review Questions (Units 9, 10, 11)Document8 pagesStat 1x1 Final Exam Review Questions (Units 9, 10, 11)Ho Uyen Thu NguyenNo ratings yet
- Soppr SvenDocument16 pagesSoppr SvenSvenNo ratings yet
- Exercise 1 Crosstabulation and Chi Square TestDocument3 pagesExercise 1 Crosstabulation and Chi Square TestCristina Valdez Delos SantosNo ratings yet
- Chapter #7 HW. Nghi HuynhDocument2 pagesChapter #7 HW. Nghi HuynhNghi HuynhNo ratings yet
- P values-and-q-values-in-RNA-SeqDocument7 pagesP values-and-q-values-in-RNA-Seq伊伊No ratings yet
- Introduction To Quantitative Techniques in BusinessDocument45 pagesIntroduction To Quantitative Techniques in BusinessUsama KhalidNo ratings yet
- Sample Size A Rough Guide: Ronán ConroyDocument30 pagesSample Size A Rough Guide: Ronán ConroyNaheedNo ratings yet
- All About Statistical Significance and TestingDocument15 pagesAll About Statistical Significance and TestingSherwan R ShalNo ratings yet
- Understanding P - Values and CI 20nov08Document37 pagesUnderstanding P - Values and CI 20nov08santoshchitraNo ratings yet
- Solutions4 301Document5 pagesSolutions4 301Glory OlalereNo ratings yet
- 11 Forms of Test Statistics For The Population Proportion SPTC 1602 Q4 FPFDocument15 pages11 Forms of Test Statistics For The Population Proportion SPTC 1602 Q4 FPFpatriciaaninon57No ratings yet
- 1.1 - Statistical Analysis PDFDocument10 pages1.1 - Statistical Analysis PDFzoohyun91720No ratings yet
- Cross ValidationDocument10 pagesCross Validationvinitrohit96No ratings yet
- Solution Manual For Statistical Reasoning For Everyday Life 5th Edition Jeff BennettDocument36 pagesSolution Manual For Statistical Reasoning For Everyday Life 5th Edition Jeff Bennetttentifcouteau.ze62100% (49)
- Statistics and Probability q4 Mod12 Computing Test Statistic Value Involving Population Proportion V2pdfDocument26 pagesStatistics and Probability q4 Mod12 Computing Test Statistic Value Involving Population Proportion V2pdfVan Harold SampotNo ratings yet
- Influence of Income, Age and Number of Children On TravellingDocument18 pagesInfluence of Income, Age and Number of Children On TravellingMahin MahbubNo ratings yet
- E 7 Bda 3 CaDocument15 pagesE 7 Bda 3 CaKaranNo ratings yet
- Hypothesis Test For One Population Mean: Unit 4A - Statistical Inference Part 1Document28 pagesHypothesis Test For One Population Mean: Unit 4A - Statistical Inference Part 1Shravani PalandeNo ratings yet
- Design and Evaluation of High Gain Microstrip Patch Antenna Using Double Layer With Air GapDocument4 pagesDesign and Evaluation of High Gain Microstrip Patch Antenna Using Double Layer With Air GapEditor IJRITCCNo ratings yet
- Cs101 Program Logic Formulation 1Document4 pagesCs101 Program Logic Formulation 1Multiple Criteria DssNo ratings yet
- Latihan Soal Pat Bahasa InggrisDocument8 pagesLatihan Soal Pat Bahasa InggrisDragNo ratings yet
- Harmonica For Beginners - Ami LuzDocument89 pagesHarmonica For Beginners - Ami LuzMoramay Martínez100% (4)
- 2Q Budget of Work Math IVDocument2 pages2Q Budget of Work Math IVEurika LimNo ratings yet
- Design of ColumnsDocument20 pagesDesign of ColumnsnoahNo ratings yet
- Professional Price List: 03-04-2018Document17 pagesProfessional Price List: 03-04-2018Eimantas ČiurinskasNo ratings yet
- Nucl - Phys.B v.797 PDFDocument551 pagesNucl - Phys.B v.797 PDFbuddy72No ratings yet
- MSC - Superform: Advanced Finite Element Software For Manufacturing Process SimulationDocument3 pagesMSC - Superform: Advanced Finite Element Software For Manufacturing Process SimulationAnderNo ratings yet
- HUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-BDocument93 pagesHUAWEI BTS3900 Hardware Structure and Principle-200903-IsSUE1.0-Bkashf415100% (4)
- OTFS: A New Modulation Scheme For High Mobility Use Cases: M. K. Ramachandran, G. D. Surabhi and A. ChockalingamDocument22 pagesOTFS: A New Modulation Scheme For High Mobility Use Cases: M. K. Ramachandran, G. D. Surabhi and A. ChockalingamUpasana KouravNo ratings yet
- Reading Comprehension 1Document2 pagesReading Comprehension 1Rodaina MahmoudNo ratings yet
- Hydraulic Components and SystemsDocument157 pagesHydraulic Components and SystemsFernando TezzaNo ratings yet
- Allen Chemistry Class 10-Pages-45-55-CompressedDocument11 pagesAllen Chemistry Class 10-Pages-45-55-CompressedSaismita ParidaNo ratings yet
- Omni Catolog 2005Document116 pagesOmni Catolog 2005Tuan SsvcNo ratings yet
- Pengantar Akuntan II: Present Value of Principal To Be Received at MaturityDocument4 pagesPengantar Akuntan II: Present Value of Principal To Be Received at MaturityalifNo ratings yet
- Sap WMDocument6 pagesSap WMAkhil MehtaNo ratings yet
- Overview:: Book Title:-Engineering Physics, 2E Author:-B. K. Pandey - SDocument2 pagesOverview:: Book Title:-Engineering Physics, 2E Author:-B. K. Pandey - Sdamini chandi priyaNo ratings yet
- Midterm Report: in Electrical EngineeringDocument11 pagesMidterm Report: in Electrical Engineeringdr.Sabita shresthaNo ratings yet
- One Dimensional FlowDocument11 pagesOne Dimensional FlowmechgokulNo ratings yet
- Process Integration Scenario in SAP PI 7.1Document19 pagesProcess Integration Scenario in SAP PI 7.1Durga Prasad Anagani100% (1)
- Manage Test Equipment Calibration Processes With SAP Plant Maintenance and Quality ManagementDocument6 pagesManage Test Equipment Calibration Processes With SAP Plant Maintenance and Quality ManagementRajendra G100% (1)
- Liebherr Hs 855 With Hydraulic Slurry Wall Grab EnglishDocument12 pagesLiebherr Hs 855 With Hydraulic Slurry Wall Grab EnglishMary JeanNo ratings yet
- FORMULA S SHEET Math IIIDocument2 pagesFORMULA S SHEET Math IIIDani RuizNo ratings yet
- MPC5777C MCAL4 0 RTM 1 0 1 ReleaseNotesDocument427 pagesMPC5777C MCAL4 0 RTM 1 0 1 ReleaseNotesasix25No ratings yet
- Window 95Document13 pagesWindow 95Jiro SaldiviaNo ratings yet
- Elasticity, Consumer Surplus and Producer SurplusDocument88 pagesElasticity, Consumer Surplus and Producer SurplusCkristeneJean Baltazar De VeraNo ratings yet
- Tungsten Carbide: Tungsten Carbide (Chemical Formula: WC) Is A ChemicalDocument10 pagesTungsten Carbide: Tungsten Carbide (Chemical Formula: WC) Is A Chemicalroberto jimenezNo ratings yet