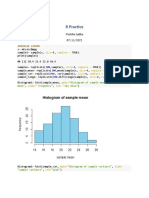
Download as pdf or txt
You might also like
- Naiye Bayes Classification ApplicationDocument3 pagesNaiye Bayes Classification ApplicationAjitkumar SharmaNo ratings yet
- Decision TreeDocument1 pageDecision Treesid-harth sid-harth100% (1)
- Kamaljeet Singh (19103052) : DF Datasets IrisDocument5 pagesKamaljeet Singh (19103052) : DF Datasets IrisJagrit SharmaNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Matplotlib Arya ManasDocument44 pagesMatplotlib Arya ManasFarook Muhammad AliNo ratings yet
- Answer All Questions:: SolutionDocument4 pagesAnswer All Questions:: SolutionAyoub MohamedNo ratings yet
- PLOTLYDocument8 pagesPLOTLYpranjal0981.psNo ratings yet
- Assignment 3 1Document13 pagesAssignment 3 1lizahxmNo ratings yet
- Lab - 5 (CB - En.u4ece22115)Document5 pagesLab - 5 (CB - En.u4ece22115)Daejuswaram GopinathNo ratings yet
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- Tugas Clustering - 132021012 - Kevin Gazkia NaufalDocument6 pagesTugas Clustering - 132021012 - Kevin Gazkia NaufalkevinNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- Variance GammaDocument24 pagesVariance GammaMichaelNo ratings yet
- Iris ClaasificationDocument1 pageIris ClaasificationMohammad Faysal KhanNo ratings yet
- Implementing KNN Algorithm: Importing LibrariesDocument6 pagesImplementing KNN Algorithm: Importing LibrariesHarish Kumar PamnaniNo ratings yet
- 3 SVM - Jupyter NotebookDocument4 pages3 SVM - Jupyter Notebookvenkatesh mNo ratings yet
- MINI PROJECT - MergedDocument8 pagesMINI PROJECT - Mergedbhanucse16No ratings yet
- Experiment 1Document8 pagesExperiment 1Akshat AjayNo ratings yet
- Assignment No - 6-1Document3 pagesAssignment No - 6-1Sid Chabukswar100% (1)
- Model - Ipynb - ColaboratoryDocument3 pagesModel - Ipynb - ColaboratorySHREYANSHU KODILKARNo ratings yet
- Naive Bayes Classifier 066Document14 pagesNaive Bayes Classifier 06621EE076 NIDHINNo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- Decision TreeDocument6 pagesDecision TreeSazeda SultanaNo ratings yet
- Linear Regression Mca Lab - Jupyter NotebookDocument2 pagesLinear Regression Mca Lab - Jupyter NotebookSmriti SharmaNo ratings yet
- Decision Tree Algorithm in Machine LearningDocument13 pagesDecision Tree Algorithm in Machine LearningVasudevanNo ratings yet
- Scala Cheat SheetDocument60 pagesScala Cheat Sheetahmed_sftNo ratings yet
- P06 The Classification Pipeline AnsDocument16 pagesP06 The Classification Pipeline AnsJayson CarlsenNo ratings yet
- ML 1Document4 pagesML 1yefigoh133No ratings yet
- JournalDev - How To Take The Samples Using SAMPLE in RDocument6 pagesJournalDev - How To Take The Samples Using SAMPLE in RSílvia AmadoriNo ratings yet
- DL 8Document6 pagesDL 8Siddesh PingaleNo ratings yet
- Cross ValidationDocument14 pagesCross ValidationSajina PKNo ratings yet
- Sixth Class Hands On - Jupyter NotebookDocument4 pagesSixth Class Hands On - Jupyter NotebookRidwan DereNo ratings yet
- KNN SVM Class Reading: October 31, 2017Document14 pagesKNN SVM Class Reading: October 31, 2017Ayush NagoriNo ratings yet
- Sem-3 (Vector Space)Document2 pagesSem-3 (Vector Space)Elw ayNo ratings yet
- Tugas Mandiri Pertemuan 9 - Dea Ashari Oktavia - ITSDocument1 pageTugas Mandiri Pertemuan 9 - Dea Ashari Oktavia - ITSDeaNo ratings yet
- It - S All About Neighbors - CompletedDocument14 pagesIt - S All About Neighbors - CompletedSoulaimaNo ratings yet
- R ProgramsDocument30 pagesR ProgramsRanga SwamyNo ratings yet
- Measures-of-Spread-or-Dispersion-Learning MaterialDocument9 pagesMeasures-of-Spread-or-Dispersion-Learning MaterialTOLENTINO, Joferose AluyenNo ratings yet
- Title: Solve N-Queen Problem Using Backtracking Algorithm: Department of Computer Science and EngineeringDocument6 pagesTitle: Solve N-Queen Problem Using Backtracking Algorithm: Department of Computer Science and EngineeringSazeda SultanaNo ratings yet
- Braids CodeDocument36 pagesBraids CodeMonica Cabria ZambranoNo ratings yet
- Short Refcard RDocument34 pagesShort Refcard RRavshonbek OtojanovNo ratings yet
- Linear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsDocument2 pagesLinear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsmansiNo ratings yet
- Using The MarkowitzR PackageDocument12 pagesUsing The MarkowitzR PackageAlmighty59No ratings yet
- Relative Viewport For Graphics InclusionDocument7 pagesRelative Viewport For Graphics InclusionJoséL.VerçosaMarquesNo ratings yet
- Experiment - 2 Misc.Document4 pagesExperiment - 2 Misc.Siffatjot SinghNo ratings yet
- STQA Experiment 5 8 PDFDocument14 pagesSTQA Experiment 5 8 PDFAkshat AjayNo ratings yet
- Week11 N9Document5 pagesWeek11 N920131A05N9 SRUTHIK THOKALANo ratings yet
- WriteUp IDSECCONF 2017Document22 pagesWriteUp IDSECCONF 2017FallCrescentNo ratings yet
- Linear Control Systems Lab: E X Per I M E NT NO: 1Document17 pagesLinear Control Systems Lab: E X Per I M E NT NO: 1Syed Shehryar Ali NaqviNo ratings yet
- ADi COmpUTer PrOjEctDocument55 pagesADi COmpUTer PrOjEctAditya SinghNo ratings yet
- Name: Mussab Bin Shahid Sap-Id: 2024 Assignment: Machine-LearningDocument5 pagesName: Mussab Bin Shahid Sap-Id: 2024 Assignment: Machine-LearningMussab ShahidNo ratings yet
- Udacity Machine Learning Analysis Supervised LearningDocument504 pagesUdacity Machine Learning Analysis Supervised Learningyousef shaban100% (1)
- Dataviz CheatsheetDocument9 pagesDataviz CheatsheetLakshit ManraoNo ratings yet
- Package Origami': R Topics DocumentedDocument10 pagesPackage Origami': R Topics DocumentedLuis De La Cruz PrietoNo ratings yet
- Praktikum Matematika Metode Tertutup, Bagi Dua, Dan Posisi PalsuDocument31 pagesPraktikum Matematika Metode Tertutup, Bagi Dua, Dan Posisi Palsusamehadaku 217No ratings yet
- 4c Sklearn-Classification-Regression-Bkhw-Spring 2019Document20 pages4c Sklearn-Classification-Regression-Bkhw-Spring 2019Radhika KhandelwalNo ratings yet
- Coding TemplateDocument67 pagesCoding TemplateKarandeep JagpalNo ratings yet
- DSM 2Document7 pagesDSM 2no0r32200No ratings yet
- Programming Assignment 4 PDFDocument16 pagesProgramming Assignment 4 PDFThanh NguyenNo ratings yet
- ESO207: Data Structures and Algorithms: Theoretical Assignment 1 Due Date: 12th February, 2022Document2 pagesESO207: Data Structures and Algorithms: Theoretical Assignment 1 Due Date: 12th February, 2022MakingItSimpleNo ratings yet
- Lec - 4 Window Function v4.0Document4 pagesLec - 4 Window Function v4.0Nikesh BajajNo ratings yet
- ML JournalDocument37 pagesML JournalVaishnavis ARTNo ratings yet
- Optimization AAOCZC222Document3 pagesOptimization AAOCZC222Baluontheline_001100% (1)
- Ch08 - Applications To Filters and Equalizers PDFDocument98 pagesCh08 - Applications To Filters and Equalizers PDFMochamad Fahmi FajrinNo ratings yet
- Bessel Stirling Formula Numerical AnalysisDocument1 pageBessel Stirling Formula Numerical Analysisomed100% (1)
- Digital Image ProcessingDocument2 pagesDigital Image ProcessingSaisriram KarthikeyaNo ratings yet
- 011 C and Data Structres QuizDocument40 pages011 C and Data Structres Quizvinay harshaNo ratings yet
- Automatic Search of Attacks On Round-Reduced AES and ApplicationsDocument40 pagesAutomatic Search of Attacks On Round-Reduced AES and Applicationssomeone :-ONo ratings yet
- Two Assumptions Made On Jacobi Method:: 7.3 The Jacobi and Gauss-Seidel Iterative Methods The Jacobi MethodDocument7 pagesTwo Assumptions Made On Jacobi Method:: 7.3 The Jacobi and Gauss-Seidel Iterative Methods The Jacobi MethodLân Võ ThànhNo ratings yet
- Algorithms and FlowchartDocument23 pagesAlgorithms and FlowchartYuneswari MuniandyNo ratings yet
- OS LAB A3 KiranDocument11 pagesOS LAB A3 KiranSohaNo ratings yet
- Skewb GuideDocument11 pagesSkewb GuideAlex SalgadoNo ratings yet
- Memory Bounded A AlgorithmDocument16 pagesMemory Bounded A AlgorithmTURAGA VIJAYAAKASH100% (1)
- Convolutional Neural Networks: Computer VisionDocument41 pagesConvolutional Neural Networks: Computer VisionThànhĐạt NgôNo ratings yet
- MD5, MD5 DecrypterDocument1 pageMD5, MD5 Decrypterarun11nov85No ratings yet
- Cryptography and Network Security: Fifth Edition by William StallingsDocument25 pagesCryptography and Network Security: Fifth Edition by William StallingsAisha Saman KhanNo ratings yet
- MATLAB Optimization ToolboxDocument37 pagesMATLAB Optimization Toolboxkushkhanna06No ratings yet
- Lecture 3: Simple Sorting and Searching Algorithms: Data Structure and Algorithm AnalysisDocument39 pagesLecture 3: Simple Sorting and Searching Algorithms: Data Structure and Algorithm Analysissami damtewNo ratings yet
- Linear Multistep Methods: Lei LiuDocument28 pagesLinear Multistep Methods: Lei LiuJoão Marcelo RomanoNo ratings yet
- DSP - P4 Digital Images - A-D & D-ADocument9 pagesDSP - P4 Digital Images - A-D & D-AArmando CajahuaringaNo ratings yet
- Region of Convergence Example 2: Inverse Z-TransformDocument1 pageRegion of Convergence Example 2: Inverse Z-Transformalokesh1982No ratings yet
- Measuring ErrorDocument6 pagesMeasuring ErrorAwais AwanNo ratings yet
- Lec 11Document18 pagesLec 11uday singh meenaNo ratings yet
- Tripoli University Department of Electrical & Electronic EngineeringDocument44 pagesTripoli University Department of Electrical & Electronic EngineeringtojogofirNo ratings yet
- Sacant MethodDocument20 pagesSacant MethodDiego Rangel RangelNo ratings yet
- SPE-197932-MS Decline Curve Analysis Using Artificial IntelligenceDocument13 pagesSPE-197932-MS Decline Curve Analysis Using Artificial IntelligenceGHIFFARI PARAMANTA ELBEESNo ratings yet
- Interpolation and The Lagrange PolynomialDocument9 pagesInterpolation and The Lagrange PolynomialEmmanuel Jerome TagaroNo ratings yet
- Deep Learning State of The Art: Amulya Viswambharan ID 202090007 Kehkshan Fatima IDDocument17 pagesDeep Learning State of The Art: Amulya Viswambharan ID 202090007 Kehkshan Fatima IDAmulyaNo ratings yet
- Lesson 4: Linear Programming - Simplex MethodDocument7 pagesLesson 4: Linear Programming - Simplex MethodQueenie ValleNo ratings yet