
Nvidia Ampere Ga 102 Gpu Architecture Whitepaper v2
Nvidia Ampere Ga 102 Gpu Architecture Whitepaper v2
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5820)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Decklink Mini Monitor TechspecsDocument5 pagesDecklink Mini Monitor TechspecsDaniel SevillaNo ratings yet
- ITC100 Tally Pin Cross ReferenceDocument1 pageITC100 Tally Pin Cross ReferenceDaniel SevillaNo ratings yet
- Instruction Manual: Intercom SystemDocument24 pagesInstruction Manual: Intercom SystemDaniel SevillaNo ratings yet
- Datavideo DN-400 DN-500Document2 pagesDatavideo DN-400 DN-500Daniel SevillaNo ratings yet
- Blackmagic Converters Manual PDFDocument658 pagesBlackmagic Converters Manual PDFDaniel SevillaNo ratings yet
- Datavideo CG 100Document130 pagesDatavideo CG 100Daniel SevillaNo ratings yet
- AH - Dlive - Brochure 17 Final WebDocument24 pagesAH - Dlive - Brochure 17 Final WebDaniel SevillaNo ratings yet
- Autumn 2018: Converter CatalogDocument46 pagesAutumn 2018: Converter CatalogDaniel SevillaNo ratings yet
- ACEDVio Manuale PDFDocument28 pagesACEDVio Manuale PDFDaniel SevillaNo ratings yet
- 5 GHZ Point To Point 1.0+ Gbps Radio: Models: Af5, Af5UDocument52 pages5 GHZ Point To Point 1.0+ Gbps Radio: Models: Af5, Af5UDaniel SevillaNo ratings yet
- Tikilive Live Transcoder Beta 05Document4 pagesTikilive Live Transcoder Beta 05Daniel SevillaNo ratings yet
- HXR-NX5 24Document1 pageHXR-NX5 24Daniel SevillaNo ratings yet
- Hdstorm & Hdstorm PlusDocument4 pagesHdstorm & Hdstorm PlusDaniel SevillaNo ratings yet
- CCD TRV15Document84 pagesCCD TRV15Daniel SevillaNo ratings yet
- Hardware Setup Manual: Edius NX Pci-X / Edius NX Pci-E / Edius NX Express / HdstormDocument52 pagesHardware Setup Manual: Edius NX Pci-X / Edius NX Pci-E / Edius NX Express / HdstormDaniel SevillaNo ratings yet
- CP1290 Bateria Gel 12vDocument2 pagesCP1290 Bateria Gel 12vDaniel SevillaNo ratings yet
- HD/SD Digital Video SwitcherDocument4 pagesHD/SD Digital Video SwitcherDaniel SevillaNo ratings yet
- System Diagram - SE-600 Application: Program 1Document2 pagesSystem Diagram - SE-600 Application: Program 1Daniel SevillaNo ratings yet
- Datavideo Product Guide 2015 PDFDocument19 pagesDatavideo Product Guide 2015 PDFDaniel SevillaNo ratings yet
- AMD Value Proposition in Imaging, Media, and Collaboration - For CustomersDocument28 pagesAMD Value Proposition in Imaging, Media, and Collaboration - For CustomersFamily LinNo ratings yet
- OSCA Group Assignment PDFDocument102 pagesOSCA Group Assignment PDFjames smithNo ratings yet
- S8906: Fast Data Pipelines For Deep Learning Training: Przemek Tredak, Simon LaytonDocument41 pagesS8906: Fast Data Pipelines For Deep Learning Training: Przemek Tredak, Simon LaytonRyan BloxhamNo ratings yet
- Bits On Blocks: A Gentle Introduction To Bitcoin MiningDocument16 pagesBits On Blocks: A Gentle Introduction To Bitcoin MiningJulio Mallma RodriguezNo ratings yet
- StereoCad 2.2.1 - User Guide (Ingles)Document45 pagesStereoCad 2.2.1 - User Guide (Ingles)Adrian AvilaNo ratings yet
- Bosch Releaseletter VideoClient 1.7.6 SR3 PDFDocument26 pagesBosch Releaseletter VideoClient 1.7.6 SR3 PDFmairenero1No ratings yet
- Understanding Video RAM Memory BandwidthDocument1 pageUnderstanding Video RAM Memory BandwidthHarish MahadevanNo ratings yet
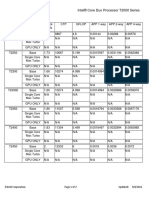
- Intel® Core Duo Processor T2000 Series: ©intel Corporation Page 1 of 2 9/8/2011 UpdatedDocument2 pagesIntel® Core Duo Processor T2000 Series: ©intel Corporation Page 1 of 2 9/8/2011 UpdatedeuricoNo ratings yet
- Toshiba Personal Computer Satellite P10 Series Maintenance ManualDocument213 pagesToshiba Personal Computer Satellite P10 Series Maintenance ManualindianmonkNo ratings yet
- Workshop 15 - Fea-Dem Transient Coupling: Roc K Y. Es S S. CoDocument61 pagesWorkshop 15 - Fea-Dem Transient Coupling: Roc K Y. Es S S. Cobruno franco di domenico di domenico100% (1)
- Training Manual LatestDocument47 pagesTraining Manual Latestcarlos abraham ZemdejasNo ratings yet
- Adobe Media Encoder Log-LastDocument2 pagesAdobe Media Encoder Log-LastNatalia AcuñaNo ratings yet
- Cpus: Latency Oriented DesignDocument2 pagesCpus: Latency Oriented DesignShaha MubarakNo ratings yet
- Unit Iii - AcaDocument13 pagesUnit Iii - AcaAnitha DenisNo ratings yet
- ASRock Z77 Extreme4 User ManualDocument79 pagesASRock Z77 Extreme4 User ManualMarian BucurNo ratings yet
- Nvidia - Group 2 NBI8ADocument9 pagesNvidia - Group 2 NBI8AFarah WawaNo ratings yet
- Tunel GTXDocument60 pagesTunel GTXVijay Jha100% (1)
- Distributed Computing and Internet Technology 16th International Conference ICDCIT 2020 Bhubaneswar India January 9 12 2020 Proceedings Dang Van HungDocument54 pagesDistributed Computing and Internet Technology 16th International Conference ICDCIT 2020 Bhubaneswar India January 9 12 2020 Proceedings Dang Van Hungdale.crews361100% (3)
- A13 Bionic ChipDocument12 pagesA13 Bionic ChipManikanta SriramNo ratings yet
- DxDiag Copy MSIDocument45 pagesDxDiag Copy MSITạ Anh TuấnNo ratings yet
- D&I of GPU Based Image Processing On CASE ClusterDocument28 pagesD&I of GPU Based Image Processing On CASE ClusterKRNo ratings yet
- Log 2023-04-22 16 - 42 - 33 - 562Document6 pagesLog 2023-04-22 16 - 42 - 33 - 562acfch2022No ratings yet
- Ans DanDocument54 pagesAns DanSuresh RajuNo ratings yet
- High Performance Computing in CST Studio Suite: Felix WolfheimerDocument18 pagesHigh Performance Computing in CST Studio Suite: Felix WolfheimerPragash SangaranNo ratings yet
- Alienware m17 R3 Setup and Specifications: Regulatory Model: P45E Regulatory Type: P45E001 June 2020 Rev. A01Document22 pagesAlienware m17 R3 Setup and Specifications: Regulatory Model: P45E Regulatory Type: P45E001 June 2020 Rev. A01bunklyNo ratings yet
- 1st Sem - Sec B - Computer AssignmentDocument4 pages1st Sem - Sec B - Computer Assignmentakyadav123No ratings yet
- Vtune Profiler User GuideDocument881 pagesVtune Profiler User GuidenoneNo ratings yet
- Lastexception 63841429172Document63 pagesLastexception 63841429172amwibowo95No ratings yet
- About Gpu 2024 04 11T01 51 00 206ZDocument24 pagesAbout Gpu 2024 04 11T01 51 00 206Zstheffanyerapha0608No ratings yet
- Dakar10Abx: WWW - Vinafix.vnDocument57 pagesDakar10Abx: WWW - Vinafix.vnubiquiti mikrotikNo ratings yet

























































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5820)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Decklink Mini Monitor TechspecsDocument5 pagesDecklink Mini Monitor TechspecsDaniel SevillaNo ratings yet
- ITC100 Tally Pin Cross ReferenceDocument1 pageITC100 Tally Pin Cross ReferenceDaniel SevillaNo ratings yet
- Instruction Manual: Intercom SystemDocument24 pagesInstruction Manual: Intercom SystemDaniel SevillaNo ratings yet
- Datavideo DN-400 DN-500Document2 pagesDatavideo DN-400 DN-500Daniel SevillaNo ratings yet
- Blackmagic Converters Manual PDFDocument658 pagesBlackmagic Converters Manual PDFDaniel SevillaNo ratings yet
- Datavideo CG 100Document130 pagesDatavideo CG 100Daniel SevillaNo ratings yet
- AH - Dlive - Brochure 17 Final WebDocument24 pagesAH - Dlive - Brochure 17 Final WebDaniel SevillaNo ratings yet
- Autumn 2018: Converter CatalogDocument46 pagesAutumn 2018: Converter CatalogDaniel SevillaNo ratings yet
- ACEDVio Manuale PDFDocument28 pagesACEDVio Manuale PDFDaniel SevillaNo ratings yet
- 5 GHZ Point To Point 1.0+ Gbps Radio: Models: Af5, Af5UDocument52 pages5 GHZ Point To Point 1.0+ Gbps Radio: Models: Af5, Af5UDaniel SevillaNo ratings yet
- Tikilive Live Transcoder Beta 05Document4 pagesTikilive Live Transcoder Beta 05Daniel SevillaNo ratings yet
- HXR-NX5 24Document1 pageHXR-NX5 24Daniel SevillaNo ratings yet
- Hdstorm & Hdstorm PlusDocument4 pagesHdstorm & Hdstorm PlusDaniel SevillaNo ratings yet
- CCD TRV15Document84 pagesCCD TRV15Daniel SevillaNo ratings yet
- Hardware Setup Manual: Edius NX Pci-X / Edius NX Pci-E / Edius NX Express / HdstormDocument52 pagesHardware Setup Manual: Edius NX Pci-X / Edius NX Pci-E / Edius NX Express / HdstormDaniel SevillaNo ratings yet
- CP1290 Bateria Gel 12vDocument2 pagesCP1290 Bateria Gel 12vDaniel SevillaNo ratings yet
- HD/SD Digital Video SwitcherDocument4 pagesHD/SD Digital Video SwitcherDaniel SevillaNo ratings yet
- System Diagram - SE-600 Application: Program 1Document2 pagesSystem Diagram - SE-600 Application: Program 1Daniel SevillaNo ratings yet
- Datavideo Product Guide 2015 PDFDocument19 pagesDatavideo Product Guide 2015 PDFDaniel SevillaNo ratings yet
- AMD Value Proposition in Imaging, Media, and Collaboration - For CustomersDocument28 pagesAMD Value Proposition in Imaging, Media, and Collaboration - For CustomersFamily LinNo ratings yet
- OSCA Group Assignment PDFDocument102 pagesOSCA Group Assignment PDFjames smithNo ratings yet
- S8906: Fast Data Pipelines For Deep Learning Training: Przemek Tredak, Simon LaytonDocument41 pagesS8906: Fast Data Pipelines For Deep Learning Training: Przemek Tredak, Simon LaytonRyan BloxhamNo ratings yet
- Bits On Blocks: A Gentle Introduction To Bitcoin MiningDocument16 pagesBits On Blocks: A Gentle Introduction To Bitcoin MiningJulio Mallma RodriguezNo ratings yet
- StereoCad 2.2.1 - User Guide (Ingles)Document45 pagesStereoCad 2.2.1 - User Guide (Ingles)Adrian AvilaNo ratings yet
- Bosch Releaseletter VideoClient 1.7.6 SR3 PDFDocument26 pagesBosch Releaseletter VideoClient 1.7.6 SR3 PDFmairenero1No ratings yet
- Understanding Video RAM Memory BandwidthDocument1 pageUnderstanding Video RAM Memory BandwidthHarish MahadevanNo ratings yet
- Intel® Core Duo Processor T2000 Series: ©intel Corporation Page 1 of 2 9/8/2011 UpdatedDocument2 pagesIntel® Core Duo Processor T2000 Series: ©intel Corporation Page 1 of 2 9/8/2011 UpdatedeuricoNo ratings yet
- Toshiba Personal Computer Satellite P10 Series Maintenance ManualDocument213 pagesToshiba Personal Computer Satellite P10 Series Maintenance ManualindianmonkNo ratings yet
- Workshop 15 - Fea-Dem Transient Coupling: Roc K Y. Es S S. CoDocument61 pagesWorkshop 15 - Fea-Dem Transient Coupling: Roc K Y. Es S S. Cobruno franco di domenico di domenico100% (1)
- Training Manual LatestDocument47 pagesTraining Manual Latestcarlos abraham ZemdejasNo ratings yet
- Adobe Media Encoder Log-LastDocument2 pagesAdobe Media Encoder Log-LastNatalia AcuñaNo ratings yet
- Cpus: Latency Oriented DesignDocument2 pagesCpus: Latency Oriented DesignShaha MubarakNo ratings yet
- Unit Iii - AcaDocument13 pagesUnit Iii - AcaAnitha DenisNo ratings yet
- ASRock Z77 Extreme4 User ManualDocument79 pagesASRock Z77 Extreme4 User ManualMarian BucurNo ratings yet
- Nvidia - Group 2 NBI8ADocument9 pagesNvidia - Group 2 NBI8AFarah WawaNo ratings yet
- Tunel GTXDocument60 pagesTunel GTXVijay Jha100% (1)
- Distributed Computing and Internet Technology 16th International Conference ICDCIT 2020 Bhubaneswar India January 9 12 2020 Proceedings Dang Van HungDocument54 pagesDistributed Computing and Internet Technology 16th International Conference ICDCIT 2020 Bhubaneswar India January 9 12 2020 Proceedings Dang Van Hungdale.crews361100% (3)
- A13 Bionic ChipDocument12 pagesA13 Bionic ChipManikanta SriramNo ratings yet
- DxDiag Copy MSIDocument45 pagesDxDiag Copy MSITạ Anh TuấnNo ratings yet
- D&I of GPU Based Image Processing On CASE ClusterDocument28 pagesD&I of GPU Based Image Processing On CASE ClusterKRNo ratings yet
- Log 2023-04-22 16 - 42 - 33 - 562Document6 pagesLog 2023-04-22 16 - 42 - 33 - 562acfch2022No ratings yet
- Ans DanDocument54 pagesAns DanSuresh RajuNo ratings yet
- High Performance Computing in CST Studio Suite: Felix WolfheimerDocument18 pagesHigh Performance Computing in CST Studio Suite: Felix WolfheimerPragash SangaranNo ratings yet
- Alienware m17 R3 Setup and Specifications: Regulatory Model: P45E Regulatory Type: P45E001 June 2020 Rev. A01Document22 pagesAlienware m17 R3 Setup and Specifications: Regulatory Model: P45E Regulatory Type: P45E001 June 2020 Rev. A01bunklyNo ratings yet
- 1st Sem - Sec B - Computer AssignmentDocument4 pages1st Sem - Sec B - Computer Assignmentakyadav123No ratings yet
- Vtune Profiler User GuideDocument881 pagesVtune Profiler User GuidenoneNo ratings yet
- Lastexception 63841429172Document63 pagesLastexception 63841429172amwibowo95No ratings yet
- About Gpu 2024 04 11T01 51 00 206ZDocument24 pagesAbout Gpu 2024 04 11T01 51 00 206Zstheffanyerapha0608No ratings yet
- Dakar10Abx: WWW - Vinafix.vnDocument57 pagesDakar10Abx: WWW - Vinafix.vnubiquiti mikrotikNo ratings yet