Download as pdf or txt
You might also like
- Some Sample Problem Solved With KenslabDocument33 pagesSome Sample Problem Solved With KenslabFahmid Tousif KhanNo ratings yet
- AR Model Session2 Output: Install - Packages ("Forecast")Document30 pagesAR Model Session2 Output: Install - Packages ("Forecast")karthikmaddula007_66No ratings yet
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Fraud Analytics Using Descriptive, Predictive, and Social Network Techniques: A Guide to Data Science for Fraud DetectionFrom EverandFraud Analytics Using Descriptive, Predictive, and Social Network Techniques: A Guide to Data Science for Fraud DetectionNo ratings yet
- Apples and Oranges - AngrybadgergirlDocument693 pagesApples and Oranges - Angrybadgergirlfyrebyrd89100% (1)
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- K MeansDocument15 pagesK MeansJEISON ANDRES GOMEZ PEDRAZANo ratings yet
- Granger Causality and VAR ModelsDocument1 pageGranger Causality and VAR ModelsManoj MNo ratings yet
- Decision-Tree-Lab 3Document4 pagesDecision-Tree-Lab 3api-559045701No ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- 2 Linear RegressionDocument5 pages2 Linear RegressionRushabh VashikarNo ratings yet
- Pattern - Recognition - 3 - Code With OutputDocument7 pagesPattern - Recognition - 3 - Code With OutputReem NasserNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- E21CSEU0770 Lab4Document4 pagesE21CSEU0770 Lab4kumar.nayan26No ratings yet
- Data ScienceDocument1 pageData Science2001yashkhandelwalNo ratings yet
- Final DSR Lab RecordDocument16 pagesFinal DSR Lab RecordSaketh MacharlaNo ratings yet
- Lab1: Introduction To R: Islr2Document10 pagesLab1: Introduction To R: Islr2rusoNo ratings yet
- 20nov PDFDocument20 pages20nov PDFgianni moiNo ratings yet
- RunCrossCorrelations AcrossSmallArray PlotAndMapResults-forStudents-AfterCompletingRunningDocument75 pagesRunCrossCorrelations AcrossSmallArray PlotAndMapResults-forStudents-AfterCompletingRunningAde Surya PutraNo ratings yet
- LammpsDocument5 pagesLammpsAnkon SahaNo ratings yet
- 1 Solution1Document6 pages1 Solution1Mix-Kat ZiakaNo ratings yet
- Data Final RegressionDocument10 pagesData Final RegressionisaacbougherabNo ratings yet
- Post Test Praktikum8Document14 pagesPost Test Praktikum8MHNDRPRTMA ACTRYNo ratings yet
- Logistic Pima Indians - Ipynb - ColaboratoryDocument4 pagesLogistic Pima Indians - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Exercises 2 UnfinishedDocument8 pagesExercises 2 UnfinishedRio Zain DeogratiasNo ratings yet
- Lab 5Document4 pagesLab 5Muhammad SalmanNo ratings yet
- ROC and AUC Practical Implementation PDFDocument6 pagesROC and AUC Practical Implementation PDFNermine LimemeNo ratings yet
- Hasil Praktikum 5 AnregDocument15 pagesHasil Praktikum 5 AnregSitti Nur AgeNo ratings yet
- Answer PDF LabDocument34 pagesAnswer PDF LabAl KafiNo ratings yet
- Ash RegressionDocument11 pagesAsh Regressionsarpateashish5No ratings yet
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- Python For Telco Network Performance AnalysisDocument23 pagesPython For Telco Network Performance AnalysisSarfaraj AkramNo ratings yet
- Advertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryDocument7 pagesAdvertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryPaulina Frigia RanteNo ratings yet
- CompressorDocument6 pagesCompressor吳晨維No ratings yet
- Assignment 1 OutputDocument17 pagesAssignment 1 OutputVivek ChanpaNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- 1) Dimension - 20, Temperature - 1000 Kelvin Test - Lammps FileDocument13 pages1) Dimension - 20, Temperature - 1000 Kelvin Test - Lammps FileNavin Kumar (B21MT022)No ratings yet
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- Assignment Submitted By-Srishti Bhateja 19021141116: STR (Crew - Data)Document11 pagesAssignment Submitted By-Srishti Bhateja 19021141116: STR (Crew - Data)srishti bhatejaNo ratings yet
- Ayushi Patel A044 R SoftwareDocument8 pagesAyushi Patel A044 R SoftwareAyushi PatelNo ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Matplotlib 1652960400Document13 pagesMatplotlib 1652960400Washington AzevedoNo ratings yet
- Autocorrelación, Heteroscedasticidad, Multicolinealidad, No Linealidad y NormalidadDocument12 pagesAutocorrelación, Heteroscedasticidad, Multicolinealidad, No Linealidad y NormalidadFelix MartinezNo ratings yet
- AppendixDocument12 pagesAppendixsadyehclenNo ratings yet
- Capítulo 3 - Análisis Univariante de Series Temporales. Modelos ARIMA, Intervención y Función de TransferenciaDocument12 pagesCapítulo 3 - Análisis Univariante de Series Temporales. Modelos ARIMA, Intervención y Función de TransferenciaFelix MartinezNo ratings yet
- RM FA ExplainedDocument23 pagesRM FA ExplainedAshwin SinghviNo ratings yet
- ARIMA Predict ForecastDocument1 pageARIMA Predict ForecastManoj MNo ratings yet
- Capítulo 2 - Autocorrelación, Heteroscedasticidad, Multicolinealidad, No Linealidad y NormalidadDocument12 pagesCapítulo 2 - Autocorrelación, Heteroscedasticidad, Multicolinealidad, No Linealidad y NormalidadFelix MartinezNo ratings yet
- Sales Forecast: October 9, 2020Document9 pagesSales Forecast: October 9, 2020salnasuNo ratings yet
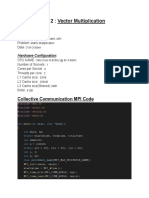
- HPC MPI LAB 2 Vector AdditionDocument9 pagesHPC MPI LAB 2 Vector AdditionMridul HarishNo ratings yet
- Welcome To "Rte-Book1Ddeltanorm - XLS" Calculator For 1D Subaerial Fluvial Fan-Delta With Channel of Constant WidthDocument23 pagesWelcome To "Rte-Book1Ddeltanorm - XLS" Calculator For 1D Subaerial Fluvial Fan-Delta With Channel of Constant WidthsteveNo ratings yet
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- Ridge - Lasso - Regression (1) .Ipynb - ColaboratoryDocument4 pagesRidge - Lasso - Regression (1) .Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Simple Linear RegressionDocument5 pagesSimple Linear Regression2023005No ratings yet
- STAT2 2e R Markdown Files Sec4.7Document10 pagesSTAT2 2e R Markdown Files Sec4.71603365No ratings yet
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet
- Data SciDocument29 pagesData Sciketisi2987No ratings yet
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- De 1Document8 pagesDe 1Anonymous jxeb81uINo ratings yet
- Dissertation Topics (Manufacturing Engineering)Document7 pagesDissertation Topics (Manufacturing Engineering)AcademicPaperWritersUK100% (1)
- Distributed Faulty Node Detection in Delay Tolerant Networks Design and AnalysisDocument5 pagesDistributed Faulty Node Detection in Delay Tolerant Networks Design and AnalysisRaj SekharNo ratings yet
- 14 Websitesto Download Research Paperfor Free 2022Document9 pages14 Websitesto Download Research Paperfor Free 2022gowridpi.1210No ratings yet
- Ren RC32312-RC32308 DST 20240405Document36 pagesRen RC32312-RC32308 DST 20240405NANDA KUMAR S NAIRNo ratings yet
- Hmt140 User Guide M211488enDocument68 pagesHmt140 User Guide M211488enJorge Rojas GuerreroNo ratings yet
- Test Bank For Social Media Marketing 0132551799Document5 pagesTest Bank For Social Media Marketing 0132551799ChristineRogerswdqb100% (42)
- S15C Analog Voltage To IO-Link Device Converter: DatasheetDocument4 pagesS15C Analog Voltage To IO-Link Device Converter: DatasheetVicente Català PousNo ratings yet
- An SPPMLFrameworkto Classify Students Performance Using MLPDocument11 pagesAn SPPMLFrameworkto Classify Students Performance Using MLPShujat Hussain GadiNo ratings yet
- BotnoviembreDocument17 pagesBotnoviembreYan MikhlinNo ratings yet
- Zensar Technologies...Document24 pagesZensar Technologies...Vibhuti Mehta100% (1)
- DpacnuasDocument35 pagesDpacnuasAmber MohantyNo ratings yet
- Agent Login Errors&TroubleshootingDocument3 pagesAgent Login Errors&TroubleshootingtheajkumarNo ratings yet
- POMDocument114 pagesPOMAbhijeet AgarwalNo ratings yet
- Jul I Kvinnaböske: Jump To Navigation Jump To SearchDocument5 pagesJul I Kvinnaböske: Jump To Navigation Jump To SearchMarwin AceNo ratings yet
- Ics Question PaperDocument28 pagesIcs Question PaperNisha MateNo ratings yet
- Cybersecurity Strategy Development Guide: Cadmus Group LLCDocument36 pagesCybersecurity Strategy Development Guide: Cadmus Group LLCgmagalha79No ratings yet
- PROPOSAL 1Coin-Operated-Hand-Sanitizer-Refiller-Vending-Machine For Edna's Pasalubong Pacita Complex San Pedro City LagunaDocument32 pagesPROPOSAL 1Coin-Operated-Hand-Sanitizer-Refiller-Vending-Machine For Edna's Pasalubong Pacita Complex San Pedro City LagunaPauline GozoNo ratings yet
- Department of Education: Region II - Cagayan Valley Schools Division of CagayanDocument2 pagesDepartment of Education: Region II - Cagayan Valley Schools Division of CagayanEleanor PascuaNo ratings yet
- Miniature Drive Systems: Dr. Fritz Faulhaber GMBH & Co. KGDocument440 pagesMiniature Drive Systems: Dr. Fritz Faulhaber GMBH & Co. KGVic MayAlNo ratings yet
- Get Essential Math For Data Science Thomas Nield PDF Full ChapterDocument24 pagesGet Essential Math For Data Science Thomas Nield PDF Full Chaptergigicmeshy36100% (6)
- Electronic Business and Performance of Smes in UgandaDocument42 pagesElectronic Business and Performance of Smes in UgandaAtukwatse Ambrose100% (1)
- BDA (18CS72) Module-1Document40 pagesBDA (18CS72) Module-1Swathi HsNo ratings yet
- 6189216Document2 pages6189216NIRANJAN RAO ENo ratings yet
- Okd Installation CentosDocument6 pagesOkd Installation Centosmeister ederNo ratings yet
- ENG-59 VCAS DVB 2.0 - Subscriber Management System Interface (SMSI) DescriptionDocument46 pagesENG-59 VCAS DVB 2.0 - Subscriber Management System Interface (SMSI) DescriptionHalil Ibrahim AyıkNo ratings yet
- 'SubnettingDocument31 pages'SubnettingTariq ShahzadNo ratings yet
- Ece2610 Chap4 PDFDocument24 pagesEce2610 Chap4 PDFBitu NirmaliaNo ratings yet
- 4.1 4.2 System of Equations StudentDocument9 pages4.1 4.2 System of Equations StudentSITI NUR AQILAH ZULKEFLINo ratings yet