Download as docx, pdf, or txt
You might also like
- Old Oregon Wood Store Case Analysis: or Group 11: Sravan Barbie Vignesh Rittik Mihira Shruti GotarkarDocument20 pagesOld Oregon Wood Store Case Analysis: or Group 11: Sravan Barbie Vignesh Rittik Mihira Shruti GotarkarBarbie JainNo ratings yet
- The Art of DifferentiatingDocument348 pagesThe Art of DifferentiatingIvánPortillaNo ratings yet
- For 100% Result Oriented IGNOU Coaching and Project Training Call CPD: 011-65164822, 08860352748Document9 pagesFor 100% Result Oriented IGNOU Coaching and Project Training Call CPD: 011-65164822, 08860352748Kamal TiwariNo ratings yet
- Predicting Near-Future Churners and Win-Backs in The Telecommunications IndustryDocument4 pagesPredicting Near-Future Churners and Win-Backs in The Telecommunications Industryjbsimha3629No ratings yet
- Data ScienceDocument7 pagesData ScienceDennis MutemiNo ratings yet
- Contact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperDocument7 pagesContact Me To Get Fully Solved Smu Assignments/Project/Synopsis/Exam Guide PaperMrinal KalitaNo ratings yet
- DW Assessment Exam Paper MG March 2023 FinalDocument10 pagesDW Assessment Exam Paper MG March 2023 Finalbida22-016No ratings yet
- 1 - BDA Summative Assessment BriefDocument21 pages1 - BDA Summative Assessment Briefpeterthiongo150No ratings yet
- DW PDFDocument18 pagesDW PDFBhavesh KhomneNo ratings yet
- Asonam 2018 DemoDocument5 pagesAsonam 2018 DemoInas BawareshNo ratings yet
- (2 Hours) (Max Marks: 75Document13 pages(2 Hours) (Max Marks: 75Sartaj InamdarNo ratings yet
- Data Visualization Tools ModuleDocument29 pagesData Visualization Tools ModuleEric Kevin LecarosNo ratings yet
- Wa0000Document38 pagesWa0000Aurobinda MohantyNo ratings yet
- Advanced Database Management System: Diploma in Computer Engineering (Gtu) Semester: 4 SUBJECT CODE: 3340701Document17 pagesAdvanced Database Management System: Diploma in Computer Engineering (Gtu) Semester: 4 SUBJECT CODE: 3340701Anand GoudaNo ratings yet
- 4DATA: Data Scientist M1 - Project (2020-2021) : 1-Import The Useful LibraryDocument1 page4DATA: Data Scientist M1 - Project (2020-2021) : 1-Import The Useful Libraryhoussam ziouanyNo ratings yet
- INF554: M L I E P AXA Data Challenge - Assignment: 1 Description of The AssignmentDocument6 pagesINF554: M L I E P AXA Data Challenge - Assignment: 1 Description of The Assignmentmeriem bahaNo ratings yet
- Handling Missing DataDocument21 pagesHandling Missing DataJenny CastilloNo ratings yet
- Disaster Response Classification Using NLPDocument24 pagesDisaster Response Classification Using NLPKaranveer SinghNo ratings yet
- Predictive Modeling Business Report Seetharaman Final Changes PDFDocument28 pagesPredictive Modeling Business Report Seetharaman Final Changes PDFAnkita Mishra100% (1)
- Welcome To The Information AgeDocument120 pagesWelcome To The Information AgeNanthiga BabuNo ratings yet
- Ipl Matches DocumentationDocument28 pagesIpl Matches DocumentationNitish Kumar MohantyNo ratings yet
- Clubcf: A Clustering-Based Collaborative Filtering Approach For Big Data ApplicationDocument12 pagesClubcf: A Clustering-Based Collaborative Filtering Approach For Big Data Applicationtp2006sterNo ratings yet
- Bussiness File - K Sandhya RaniDocument25 pagesBussiness File - K Sandhya Ranisanisani1020No ratings yet
- TESTDocument44 pagesTESTForward BiasNo ratings yet
- Big Data Analytics NotesDocument9 pagesBig Data Analytics Notessanthosh shrinivasNo ratings yet
- Industrial Internship: Week 6 (31 May, 2021 - 4 June, 2021)Document8 pagesIndustrial Internship: Week 6 (31 May, 2021 - 4 June, 2021)Vikas GuptaNo ratings yet
- Data Mining and Data Warehouse: Raju - Qis@yahoo - Co.in Praneeth - Grp@yahoo - Co.inDocument8 pagesData Mining and Data Warehouse: Raju - Qis@yahoo - Co.in Praneeth - Grp@yahoo - Co.inapi-19799369No ratings yet
- INDUSTRY 2 JaiminDocument14 pagesINDUSTRY 2 JaiminKrish ParekhNo ratings yet
- Day13 K Means ClusteringDocument4 pagesDay13 K Means ClusteringPriya kambleNo ratings yet
- All Interview Questions Cognos IbmDocument13 pagesAll Interview Questions Cognos IbmKishore MaramNo ratings yet
- Monitor and Support Data Conversion Abenet DBMS L IVDocument5 pagesMonitor and Support Data Conversion Abenet DBMS L IVAbenet AsmellashNo ratings yet
- Top 40 SAP BW - BI Interview Questions OnDocument12 pagesTop 40 SAP BW - BI Interview Questions OnyaswanthrdyNo ratings yet
- It 4004 2019Document6 pagesIt 4004 2019Malith JayasingheNo ratings yet
- Itb 10BM60092 Term PaperDocument8 pagesItb 10BM60092 Term PaperSwarnabha RayNo ratings yet
- Vijay Rathod TableauDocument3 pagesVijay Rathod TableauVijay rathodNo ratings yet
- 2018 & 2019 Data Mining AnswersDocument25 pages2018 & 2019 Data Mining AnswerstumarebawaNo ratings yet
- Data Warehousing and Data MiningDocument7 pagesData Warehousing and Data MiningDeepti SinghNo ratings yet
- Modeling A Complex Global Service Delivery System: Proceedings - Winter Simulation Conference December 2011Document13 pagesModeling A Complex Global Service Delivery System: Proceedings - Winter Simulation Conference December 2011AWANGKU AZIZAN BIN AWANGKU IFNI -No ratings yet
- Project Occupancy Alfonso Vicente AraguesDocument18 pagesProject Occupancy Alfonso Vicente AraguesAlfonsoNo ratings yet
- INDUSTRY 2 AkshatDocument12 pagesINDUSTRY 2 AkshatKrish ParekhNo ratings yet
- Table of ContentsDocument13 pagesTable of ContentsVibes MainaNo ratings yet
- Top 88 Data Modeling Interview Questions and AnswersDocument19 pagesTop 88 Data Modeling Interview Questions and AnswersEnobie BrianNo ratings yet
- 01.ad3491 Fdsa QBDocument16 pages01.ad3491 Fdsa QBkandasamy.1229No ratings yet
- Predicting The Term Deposit SubscriptionDocument38 pagesPredicting The Term Deposit SubscriptionMUSA AHMED ABDULLAHI ALINo ratings yet
- User Manual (Mental Health Issue Among University StudentDocument19 pagesUser Manual (Mental Health Issue Among University StudentANIS NABIHAH BINTI MOHD JAISNo ratings yet
- How To Get: Model Answers of Various Questions Asked in MIS TestDocument17 pagesHow To Get: Model Answers of Various Questions Asked in MIS TestKuldeep ChoubeyNo ratings yet
- Tableau Interview Questions 1Document22 pagesTableau Interview Questions 1Christine CaoNo ratings yet
- Data WareHouse Previous Year Question PaperDocument10 pagesData WareHouse Previous Year Question PaperMadhusudan Das100% (1)
- Data Warehousing EC-1 Regular Feb 2011 SolutionsDocument5 pagesData Warehousing EC-1 Regular Feb 2011 SolutionsShivam ShuklaNo ratings yet
- SEN CT 2 Question Bank With AnswerDocument18 pagesSEN CT 2 Question Bank With AnswerHarshraj MandhareNo ratings yet
- Data Warehousing - Notes (Only Till Chapter 5)Document54 pagesData Warehousing - Notes (Only Till Chapter 5)HardikNo ratings yet
- CH 05 - Analysis ModelingDocument8 pagesCH 05 - Analysis ModelingzackNo ratings yet
- Data Mining Problem 2 ReportDocument13 pagesData Mining Problem 2 ReportBabu ShaikhNo ratings yet
- 0-4-31271 - DBdesign Assignment Specification - A2024Document15 pages0-4-31271 - DBdesign Assignment Specification - A2024magicmarotta420b2No ratings yet
- Assignment No 2Document26 pagesAssignment No 2Rahul RajpurohitkNo ratings yet
- Analysis and Data Mining of Call Detail RecordsDocument4 pagesAnalysis and Data Mining of Call Detail RecordsRafaVelasquezNo ratings yet
- Kiran AbinitioDocument66 pagesKiran AbinitioSandeep ShawNo ratings yet
- Sap BWDocument9 pagesSap BWanilsharma2001No ratings yet
- Develop A Program To Implement Data Preprocessing UsingDocument19 pagesDevelop A Program To Implement Data Preprocessing UsingFucker JamunNo ratings yet
- Advanced Analytics with Transact-SQL: Exploring Hidden Patterns and Rules in Your DataFrom EverandAdvanced Analytics with Transact-SQL: Exploring Hidden Patterns and Rules in Your DataNo ratings yet
- Valve'S Organization: Opportunities and Open QuestionsDocument2 pagesValve'S Organization: Opportunities and Open QuestionsMINH TRAN LENo ratings yet
- File 20210918 203939Document14 pagesFile 20210918 203939MINH TRAN LENo ratings yet
- Group 3 INS3055 Trương Công ĐoànDocument60 pagesGroup 3 INS3055 Trương Công ĐoànMINH TRAN LENo ratings yet
- Homework (Modal Verbs)Document6 pagesHomework (Modal Verbs)MINH TRAN LENo ratings yet
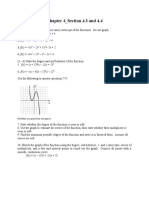
- Practice Sheet - 4.3,4.4Document7 pagesPractice Sheet - 4.3,4.4Shubh RawalNo ratings yet
- Design FIR FilterDocument22 pagesDesign FIR Filtersaran52_eceNo ratings yet
- Audine - Laurence - Rue - Presentation 1 Decision Theory MME321Document25 pagesAudine - Laurence - Rue - Presentation 1 Decision Theory MME321Laurence Rue AudineNo ratings yet
- Basic Control System PDFDocument176 pagesBasic Control System PDFJunaldi100% (1)
- Quiz 2 Solutions: and Analysis of AlgorithmsDocument12 pagesQuiz 2 Solutions: and Analysis of Algorithmstestuser4realNo ratings yet
- Math F212 1122Document3 pagesMath F212 1122shivam12365No ratings yet
- Lower Bound On Deterministic Evaluation Algorithms For NOR Circuits - Yao's Principle For Proving Lower BoundsDocument61 pagesLower Bound On Deterministic Evaluation Algorithms For NOR Circuits - Yao's Principle For Proving Lower BoundsMirza AbdullaNo ratings yet
- CHAPTER 1 Introduction CHAPTER 2 Transportation SystemsDocument10 pagesCHAPTER 1 Introduction CHAPTER 2 Transportation SystemsSantiago Torreglosa DiazNo ratings yet
- Microsoft PowerPoint - 03 - ETL Process - PPT (Compatibility Mode)Document16 pagesMicrosoft PowerPoint - 03 - ETL Process - PPT (Compatibility Mode)alhamzahaudaiNo ratings yet
- Cat2vec Learning Distributed Representation of Multi Field Categorical DataDocument9 pagesCat2vec Learning Distributed Representation of Multi Field Categorical DataManikanta SreekakulaNo ratings yet
- Solutions Computer Control Systems PDFDocument116 pagesSolutions Computer Control Systems PDFDuvan Gonzalez SandovalNo ratings yet
- Thermal Physics: 1 Boltzmann's LawDocument8 pagesThermal Physics: 1 Boltzmann's LawAbid KhanNo ratings yet
- LabviewDocument5 pagesLabviewAmineSlamaNo ratings yet
- Recurrence RelationsDocument54 pagesRecurrence Relationsphoenix1020% (1)
- Activity 1Document8 pagesActivity 1Philip Jansen GuarinNo ratings yet
- MN621 Advanced Network Design: CheckDocument4 pagesMN621 Advanced Network Design: CheckNESTOR DAVID TEHERAN VEGANo ratings yet
- hw1 PDFDocument3 pageshw1 PDFJason HoffmanNo ratings yet
- Topic 5 - Part1 Multilayer PerceptronDocument28 pagesTopic 5 - Part1 Multilayer Perceptronﻣﺤﻤﺪ الخميسNo ratings yet
- Latihan Lab Statistik - 1Document6 pagesLatihan Lab Statistik - 1Alma AuliaNo ratings yet
- Resources OpenSolver For ExcelDocument3 pagesResources OpenSolver For ExcelAnonymous 1rLNlqUNo ratings yet
- Sakshi ThermodynamicsDocument16 pagesSakshi Thermodynamicssakshi aroraNo ratings yet
- DSP - Unit 4 - DecimationDocument14 pagesDSP - Unit 4 - DecimationNaganarasaiah GoudNo ratings yet
- Lecture Notes Quantum Computing and Quantum Information: ES 643 Indian Institute of Technology Gandhinagar, 2018Document13 pagesLecture Notes Quantum Computing and Quantum Information: ES 643 Indian Institute of Technology Gandhinagar, 2018Sanu GangwarNo ratings yet
- Data Mining: Practical Machine Learning Tools and Techniques With Java ImplementationsDocument2 pagesData Mining: Practical Machine Learning Tools and Techniques With Java ImplementationsraaghavendiranNo ratings yet
- Strategic STIT FragmentDocument48 pagesStrategic STIT FragmentDaniil KhaitovichNo ratings yet
- ESD UNIT III Lecture 03 Task Scheduling Rate MonotonicDocument44 pagesESD UNIT III Lecture 03 Task Scheduling Rate MonotonicNeha MendheNo ratings yet
- 4 MCQ Ann Ann Quiz SelectedDocument18 pages4 MCQ Ann Ann Quiz SelectedĐồng DươngNo ratings yet
- Ekonomi Manajerial Pada Ekonomi GlobalDocument26 pagesEkonomi Manajerial Pada Ekonomi GlobalArif DarmawanNo ratings yet