Download as pdf or txt
You might also like
- Statwiki JamesDocument57 pagesStatwiki JameshermancxNo ratings yet
- Solution Manual, Managerial Accounting Hansen Mowen 8th Editions - CH 9Document46 pagesSolution Manual, Managerial Accounting Hansen Mowen 8th Editions - CH 9jasperkennedy086% (22)
- .Discrete Probability Distributions WorksheetDocument6 pages.Discrete Probability Distributions WorksheetRuzherry Angeli T. AzcuetaNo ratings yet
- Six SigmaDocument28 pagesSix SigmaA.P. RajaNo ratings yet
- SimonDocument2 pagesSimonpoertadeNo ratings yet
- Plan Eksekusi Site SC40 DSF MajalengkaDocument2 pagesPlan Eksekusi Site SC40 DSF MajalengkaObettNo ratings yet
- Ass12 StatisticDocument24 pagesAss12 StatisticSnehal WagholeNo ratings yet
- Herbert LegrasseDocument1 pageHerbert LegrasseAndreNo ratings yet
- Makoto Edamura Call of ChtuluDocument2 pagesMakoto Edamura Call of Chtulukaj kosterNo ratings yet
- SƠ ĐỒ 5 YẾU TỐDocument3 pagesSƠ ĐỒ 5 YẾU TỐNguyễn Ngọc ThắngNo ratings yet
- Problemario Capítulo 6 Ingeniería de Procesos MicrobiológicosDocument25 pagesProblemario Capítulo 6 Ingeniería de Procesos MicrobiológicosKenia CarrilloNo ratings yet
- Classeur 2Document2 pagesClasseur 2Twin KileNo ratings yet
- Kali RivieraDocument2 pagesKali RivieraDumbdink63No ratings yet
- Excel PracticăDocument3 pagesExcel PracticăDoina ManuelaNo ratings yet
- Graduated Cylinders: ScienceDocument2 pagesGraduated Cylinders: SciencerameshraomeshNo ratings yet
- VelocidaD de autoMOVILDocument1 pageVelocidaD de autoMOVILdinosaurio cerritosNo ratings yet
- Trabajo TecnologiaDocument2 pagesTrabajo Tecnologiafredy corralesNo ratings yet
- Libro 1Document5 pagesLibro 1Oscar Mauricio Serrano MuñozNo ratings yet
- Colegio 1 Colegio 2Document5 pagesColegio 1 Colegio 2David SerranoNo ratings yet
- Libro 1Document5 pagesLibro 1David SerranoNo ratings yet
- Effect of TemperatureDocument4 pagesEffect of Temperaturebushra shahidNo ratings yet
- People Awarness Towards Online Edu PlatformDocument6 pagesPeople Awarness Towards Online Edu PlatformRanjith KumarNo ratings yet
- Ficha Editavel CthulhuDocument2 pagesFicha Editavel CthulhuCelso Lucas Meireles da SilvaNo ratings yet
- Scatter PlotsDocument7 pagesScatter PlotsLouisNo ratings yet
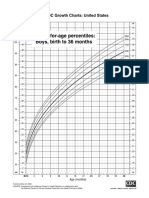
- Boy 36 Tb-UDocument1 pageBoy 36 Tb-UAlmira ClaraNo ratings yet
- NC WWD InitiativesDocument17 pagesNC WWD InitiativesstprepsNo ratings yet
- Pool Fire T-76 RadiosDocument1 pagePool Fire T-76 RadiosManuel SaavedraNo ratings yet
- Result Nilai Rapot Sts GenapDocument1 pageResult Nilai Rapot Sts Genapikok budak taruna communitasNo ratings yet
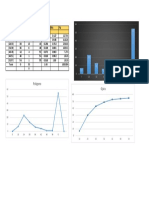
- CDC Growth Charts: United States: KG LB LBDocument1 pageCDC Growth Charts: United States: KG LB LBAlmira ClaraNo ratings yet
- Graph For LabDocument2 pagesGraph For LabMuhammad AbdullahNo ratings yet
- June Exam: Part I: Section I: Open Response - Answer The Questions in The Space ProvidedDocument3 pagesJune Exam: Part I: Section I: Open Response - Answer The Questions in The Space ProvidedrmhacheyNo ratings yet
- Teams Oppurtunities Target Actual Defects %Document4 pagesTeams Oppurtunities Target Actual Defects %ramaiahgantaNo ratings yet
- Gestra v725 PDFDocument1 pageGestra v725 PDFErdincNo ratings yet
- Pivot TableDocument7 pagesPivot TableRuchi SoniNo ratings yet
- Grampex LadraoDocument2 pagesGrampex Ladraosmurfkkj8No ratings yet
- Lightning Protection Systems: Appendix I Ground Measurement TechniquesDocument2 pagesLightning Protection Systems: Appendix I Ground Measurement TechniquesRabia akramNo ratings yet
- Annexure A (Lightning)Document3 pagesAnnexure A (Lightning)Rabia akramNo ratings yet
- Call - of - Cthulhu - Gabriela SantosDocument2 pagesCall - of - Cthulhu - Gabriela SantosHaimonNo ratings yet
- Control-Valves-electric - DATA SHEETDocument1 pageControl-Valves-electric - DATA SHEETwowkoreansNo ratings yet
- CDC Growth Charts: United States: KG LB LBDocument1 pageCDC Growth Charts: United States: KG LB LBAlmira ClaraNo ratings yet
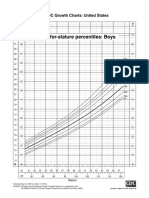
- Girl BB-TBDocument1 pageGirl BB-TBAlmira ClaraNo ratings yet
- Tegan MathsDocument2 pagesTegan Mathskaitao03No ratings yet
- teste termoparDocument3 pagesteste termoparJuliana OliveiraNo ratings yet
- AllDocument20 pagesAllanon_33083814No ratings yet
- Lab 4Document2 pagesLab 4Masud SarkerNo ratings yet
- RM Numerical DataDocument17 pagesRM Numerical DataPearlNo ratings yet
- Kauri MathsDocument2 pagesKauri Mathskaitao03No ratings yet
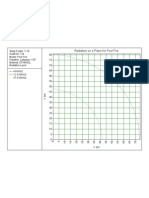
- Graphic of Length Alteration Graphic of Weight AlterationDocument2 pagesGraphic of Length Alteration Graphic of Weight Alterationirma rhmwtiNo ratings yet
- MathDocument1 pageMathapi-242107677No ratings yet
- Oil Pan and Suction TubeDocument2 pagesOil Pan and Suction TubeCalon KayaNo ratings yet
- Brandpro Simulation Learning Diary: Team 28 - No RulesDocument21 pagesBrandpro Simulation Learning Diary: Team 28 - No Rulesananyaverma695No ratings yet
- Introduction To Malaysia NRW - Water Supply Dept.Document32 pagesIntroduction To Malaysia NRW - Water Supply Dept.mssdigitalNo ratings yet
- Howard GilmanDocument1 pageHoward GilmanAndreNo ratings yet
- Ficha Chamado de Cthulhu 7a Preenchivel Personalizada 1 1Document1 pageFicha Chamado de Cthulhu 7a Preenchivel Personalizada 1 1Anna LizNo ratings yet
- Plan Ammenage R+2: BalconDocument1 pagePlan Ammenage R+2: BalconKONAN KOFFI DESIRENo ratings yet
- James MathsDocument2 pagesJames Mathskaitao03No ratings yet
- Kelsey MathsDocument2 pagesKelsey Mathskaitao03No ratings yet
- Crane Operator's Cab 4Document26 pagesCrane Operator's Cab 4Arslan AhmedNo ratings yet
- Folgore Moon: Mechanical RepairDocument2 pagesFolgore Moon: Mechanical RepairDumbdink63No ratings yet
- Using Statistical Techniques in Analysing Data: Lesson 3Document3 pagesUsing Statistical Techniques in Analysing Data: Lesson 3Christian Jim PollerosNo ratings yet
- Ficha Do PersonagemDocument1 pageFicha Do PersonagemdanieldotsNo ratings yet
- Hayden MathsDocument2 pagesHayden Mathskaitao03No ratings yet
- Figure 2 (B) : Transactions On Neural Networks and Learning Systems 4Document1 pageFigure 2 (B) : Transactions On Neural Networks and Learning Systems 4xing007No ratings yet
- Timit Timit: Transactions On Neural Networks and Learning Systems 9Document1 pageTimit Timit: Transactions On Neural Networks and Learning Systems 9xing007No ratings yet
- Transactions On Neural Networks and Learning Systems 12Document1 pageTransactions On Neural Networks and Learning Systems 12xing007No ratings yet
- Information On IC EngineDocument6 pagesInformation On IC Enginexing007No ratings yet
- Components & Strokes of I.C.EngineDocument6 pagesComponents & Strokes of I.C.Enginexing007No ratings yet
- Components & Strokes of I.C.EngineDocument6 pagesComponents & Strokes of I.C.Enginexing007No ratings yet
- AssignmentDocument4 pagesAssignmentxing007No ratings yet
- Vapour Compression Refrigeration Test Rig: Experimental ProcedureDocument5 pagesVapour Compression Refrigeration Test Rig: Experimental Procedurexing007No ratings yet
- Lecture 5 StatisticsDocument52 pagesLecture 5 Statisticsbedasie23850% (1)
- Chapter 5 Some Important Discrete Probability Distributions PDFDocument38 pagesChapter 5 Some Important Discrete Probability Distributions PDFMishelNo ratings yet
- Thesis Ebe 1999 Tattersfield George Metcalf PDFDocument203 pagesThesis Ebe 1999 Tattersfield George Metcalf PDFLucas P. KusareNo ratings yet
- Advanced Econometrics (I) Chapter 9 - Hypothesis Testing Fall 2012Document33 pagesAdvanced Econometrics (I) Chapter 9 - Hypothesis Testing Fall 2012Keith MadrilejosNo ratings yet
- Nonparametric RegressionDocument24 pagesNonparametric RegressionSNo ratings yet
- Astm E1086Document5 pagesAstm E1086KHNo ratings yet
- Banks Customer Satisfaction in Kuwait PDFDocument77 pagesBanks Customer Satisfaction in Kuwait PDFpavlov2No ratings yet
- What I Need To Know: System of MeasurementDocument9 pagesWhat I Need To Know: System of Measurementzest ishuriNo ratings yet
- Assignment No # 1: Program: Course Name: Course CodeDocument23 pagesAssignment No # 1: Program: Course Name: Course CodeShokha JuttNo ratings yet
- A Generalized Normal DistributionDocument11 pagesA Generalized Normal Distributionchang lichangNo ratings yet
- Ps 0Document3 pagesPs 0Rupesh ParabNo ratings yet
- Module 4 Educ 105 FinalDocument35 pagesModule 4 Educ 105 FinalMaria Zobel Cruz0% (1)
- StatisticsDocument211 pagesStatisticsHasan Hüseyin Çakır100% (6)
- Descriptive Statistics ModifiedDocument36 pagesDescriptive Statistics ModifiedMohammad Bony IsrailNo ratings yet
- DAY 5 - PROBABILITY AND STATISTICS L TAKE HOME PROBLEMSDocument4 pagesDAY 5 - PROBABILITY AND STATISTICS L TAKE HOME PROBLEMSJay Andrew AbañoNo ratings yet
- 2014 CMOST Presentation PDFDocument86 pages2014 CMOST Presentation PDFFransiskus SitompulNo ratings yet
- Statistics 4040 2013 - 2014Document183 pagesStatistics 4040 2013 - 2014Ahmad HanifNo ratings yet
- THNN2 - Đề 4Document16 pagesTHNN2 - Đề 4Ngọc HânNo ratings yet
- Factors Affecting Self-Regulated Learning in Nursing Students in TurkeyDocument13 pagesFactors Affecting Self-Regulated Learning in Nursing Students in TurkeyDebbieNo ratings yet
- ThesisDocument20 pagesThesisKaiye Rasonable100% (1)
- Open Electives Circular VII Sem AY 2021-22Document31 pagesOpen Electives Circular VII Sem AY 2021-22Pavan KumarNo ratings yet
- Baye 9e Chapter 12Document40 pagesBaye 9e Chapter 12Jessie Sethdavid100% (1)
- StatisticsDocument15 pagesStatisticsSalman ShakirNo ratings yet
- Thesis Statement On Population ControlDocument5 pagesThesis Statement On Population Controlafbteepof100% (2)
- Bachelor'S Graduation Thethisthesis: National Economics University Centre For Advanced Educational ProgramsDocument64 pagesBachelor'S Graduation Thethisthesis: National Economics University Centre For Advanced Educational ProgramsHà Anh NguyễnNo ratings yet
- Seminar Slides Week 3 - With Solutions - FullpageDocument33 pagesSeminar Slides Week 3 - With Solutions - FullpageAnika JainNo ratings yet