Download as pdf or txt
You might also like
- Hardy Weinberg GizmosDocument6 pagesHardy Weinberg Gizmosapi-52284773775% (4)
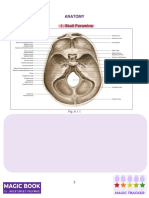
- Magic Book DR Nikita 2.0 OnlineDocument263 pagesMagic Book DR Nikita 2.0 OnlineDinesh MorNo ratings yet
- HSB June 2020Document18 pagesHSB June 2020Osmany MadrigalNo ratings yet
- Applied Multivariate Statistical Analysis Solution Manual PDFDocument18 pagesApplied Multivariate Statistical Analysis Solution Manual PDFALVYAN ARIFNo ratings yet
- Improving Short and Long Term Genetic Gain by Accounting For Within Family Variance in Optimal Cross SelectionDocument36 pagesImproving Short and Long Term Genetic Gain by Accounting For Within Family Variance in Optimal Cross Selectioncata2099No ratings yet
- MODULE 4 in GeneticsDocument6 pagesMODULE 4 in GeneticsChris TianNo ratings yet
- GBS PDFDocument8 pagesGBS PDFLeonardo LilloNo ratings yet
- Review: Plant Breeding With Marker-Assisted Selection in BrazilDocument7 pagesReview: Plant Breeding With Marker-Assisted Selection in BrazilYounas JavedNo ratings yet
- Food Chemistry: A B C A B C ADocument11 pagesFood Chemistry: A B C A B C AGeraldine Muñoz SNo ratings yet
- Assessment of Breeding Programs Sustainability: Application of Phenotypic and Genomic Indicators To A North European Grain Maize ProgramDocument14 pagesAssessment of Breeding Programs Sustainability: Application of Phenotypic and Genomic Indicators To A North European Grain Maize Programcata2099No ratings yet
- Genomic Selection For Crop Improvement: Elliot L. Heff Ner, Mark E. Sorrells, and Jean-Luc JanninkDocument12 pagesGenomic Selection For Crop Improvement: Elliot L. Heff Ner, Mark E. Sorrells, and Jean-Luc JanninkmonaNo ratings yet
- Multivariate Statistical Machine Learning Methods For Genomic PredictionDocument707 pagesMultivariate Statistical Machine Learning Methods For Genomic Predictioncvg.azevedoNo ratings yet
- Machine Learning Approaches For Crop Improvement Lever - 2021 - Journal of PlanDocument13 pagesMachine Learning Approaches For Crop Improvement Lever - 2021 - Journal of PlanTricia Marvi NavarroNo ratings yet
- Estimation of A Significance Threshold For Genome-Wide Association StudiesDocument8 pagesEstimation of A Significance Threshold For Genome-Wide Association Studiesmassariolsuela97No ratings yet
- C1107021636 PDFDocument21 pagesC1107021636 PDFTeflon SlimNo ratings yet
- Unlocking The Genetic Variability Potential of Germplasm Using Genome-Wide Association Study (GWAS) For Salt ToleranceDocument5 pagesUnlocking The Genetic Variability Potential of Germplasm Using Genome-Wide Association Study (GWAS) For Salt ToleranceDr. Jogendra SinghNo ratings yet
- Best Linear Unbiased Prediction of Genomic Breeding PDFDocument8 pagesBest Linear Unbiased Prediction of Genomic Breeding PDFEdjane FreitasNo ratings yet
- Jurnal BiokimiaDocument9 pagesJurnal BiokimiaSri NingsihNo ratings yet
- BMC Bioinformatics: Bayesian Clustering and Feature Selection For Cancer Tissue SamplesDocument18 pagesBMC Bioinformatics: Bayesian Clustering and Feature Selection For Cancer Tissue SamplesY YNo ratings yet
- Training Population Selection and Use of Fixed Effects To Optimize Genomic Predictions in A Historical USA Winter Wheat PanelDocument15 pagesTraining Population Selection and Use of Fixed Effects To Optimize Genomic Predictions in A Historical USA Winter Wheat Panelakohoue.fNo ratings yet
- Gene Selection ACOSampling An Ant Colony Optimization-Based Undersampling Methodfor Microarray Data Classification Using A Novel AntDocument13 pagesGene Selection ACOSampling An Ant Colony Optimization-Based Undersampling Methodfor Microarray Data Classification Using A Novel AntinstallheriNo ratings yet
- 2016 Article 829Document16 pages2016 Article 829mahadevagriNo ratings yet
- Integrative Clustering Methods For High-Dimensional Molecular DataDocument15 pagesIntegrative Clustering Methods For High-Dimensional Molecular DataIhsen IbNo ratings yet
- Cross A EtalDocument13 pagesCross A EtalLeonardo OrnellaNo ratings yet
- Barba Et Al-2014-Molecular Ecology ResourcesDocument18 pagesBarba Et Al-2014-Molecular Ecology ResourcesAndrés FrankowNo ratings yet
- HTPdb and HTPtools-正式发表版Document10 pagesHTPdb and HTPtools-正式发表版Holibut HoNo ratings yet
- Genomic Breed Prediction in New Zealand Sheep: Researcharticle Open AccessDocument15 pagesGenomic Breed Prediction in New Zealand Sheep: Researcharticle Open AccessAlfin Nur FauziNo ratings yet
- VIP SoftwareDocument18 pagesVIP SoftwareYounas JavedNo ratings yet
- BMC BioinformaticsDocument10 pagesBMC Bioinformaticsakhtar abbasNo ratings yet
- Improving The Efficiency of Soybean Breeding With High-Throughput Canopy PhenotypingDocument9 pagesImproving The Efficiency of Soybean Breeding With High-Throughput Canopy PhenotypingOmero Castro SanchezNo ratings yet
- Multiple Traits Selection Strategies A Proposal FoDocument13 pagesMultiple Traits Selection Strategies A Proposal FoMatheus Massariol SuelaNo ratings yet
- Unknown, SF, Methods Benthic Samples, ProtocolDocument10 pagesUnknown, SF, Methods Benthic Samples, ProtocolEduardoNo ratings yet
- Mohammadi and Prasanna 2003 Analysis of Genetic Diversity in PlantsDocument14 pagesMohammadi and Prasanna 2003 Analysis of Genetic Diversity in PlantsTeflon SlimNo ratings yet
- Detecting Signatures of Positive Selection Along DDocument16 pagesDetecting Signatures of Positive Selection Along Dlophostoma1No ratings yet
- Briefings in Functional Genomics 2010 Jannink 166 77Document12 pagesBriefings in Functional Genomics 2010 Jannink 166 77Edjane FreitasNo ratings yet
- 2 - Sampling For IPMDocument8 pages2 - Sampling For IPMJosé Rafael Avila RamosNo ratings yet
- Genome-Wide Association Mapping: A Case Study in Bread Wheat (Triticum Aestivum L.)Document22 pagesGenome-Wide Association Mapping: A Case Study in Bread Wheat (Triticum Aestivum L.)Ahmad MasoodNo ratings yet
- BarbourGerritsen 1996 Subsampling JNABSDocument8 pagesBarbourGerritsen 1996 Subsampling JNABSFon “Fon” Nebra CostasNo ratings yet
- Genome Wide Association Studies and Genomic Selection - Promises and PremisesDocument16 pagesGenome Wide Association Studies and Genomic Selection - Promises and Premisessalman672003No ratings yet
- Mas 4Document26 pagesMas 4Nofiya RuswantiNo ratings yet
- Replacement Strategies To Preserve Useful Diversity in Steady-StateDocument13 pagesReplacement Strategies To Preserve Useful Diversity in Steady-StateEnas DhuhriNo ratings yet
- 000 rstb20051670Document9 pages000 rstb20051670Abdul GhaniNo ratings yet
- Diversity Analysis of Cotton (Gossypium Hirsutum L.) Germplasm Using The Cottonsnp63K ArrayDocument20 pagesDiversity Analysis of Cotton (Gossypium Hirsutum L.) Germplasm Using The Cottonsnp63K ArrayJULIO CÉSAR CHÁVEZ GALARZANo ratings yet
- Lopez Cruz Et Al 2022Document15 pagesLopez Cruz Et Al 2022massariolsuela97No ratings yet
- Using Gut Microbiota As A Diagnostic Tool For Colorectal Cancer Machine Learning Techniques Reveal Promising Results CompressDocument12 pagesUsing Gut Microbiota As A Diagnostic Tool For Colorectal Cancer Machine Learning Techniques Reveal Promising Results CompressphopicsignerNo ratings yet
- A High-Throughput Media Design Approach For High Performance Mammalian Fed-Batch CulturesDocument11 pagesA High-Throughput Media Design Approach For High Performance Mammalian Fed-Batch CulturesbiocloneNo ratings yet
- Statistics Biology Experiments Medicine Pharmacy Agriculture FisheryDocument15 pagesStatistics Biology Experiments Medicine Pharmacy Agriculture Fisherykavya nainitaNo ratings yet
- Brief-Bioinform-2016-Meng-628-41.pdf (REF 5) (PAG - 629)Document14 pagesBrief-Bioinform-2016-Meng-628-41.pdf (REF 5) (PAG - 629)gustavo rodriguezNo ratings yet
- Use of Molecular Markers and Major Genes in The Genetic Improvement of LivestockDocument7 pagesUse of Molecular Markers and Major Genes in The Genetic Improvement of LivestockrengachenNo ratings yet
- Prediction-of-Sorghum-bicolor-Genotype-from In-situ-Images-UsingDocument9 pagesPrediction-of-Sorghum-bicolor-Genotype-from In-situ-Images-Usingtagne simo rodrigueNo ratings yet
- Gomez Et Al 2012 Statistical Procedures Most Used in The Analysis of Measures Repeated in Time in The Agricultural SectorDocument7 pagesGomez Et Al 2012 Statistical Procedures Most Used in The Analysis of Measures Repeated in Time in The Agricultural SectorCarlos AndradeNo ratings yet
- (Elect. Jurnal of Biotech) Use of Molecular Markers and Major Genes in The Genetic Improvement of Livestock Hugo H. MontaldoDocument33 pages(Elect. Jurnal of Biotech) Use of Molecular Markers and Major Genes in The Genetic Improvement of Livestock Hugo H. MontaldohasnawwNo ratings yet
- Species Assemblages and Indicator Species: The Need For A Flexible Asymmetrical ApproachDocument22 pagesSpecies Assemblages and Indicator Species: The Need For A Flexible Asymmetrical ApproachAdrianaNo ratings yet
- Genomics 5Document8 pagesGenomics 5MoriwamNo ratings yet
- Agronomy 09 00095Document16 pagesAgronomy 09 00095Abby ReadNo ratings yet
- ArticleDocument8 pagesArticleLe SmithNo ratings yet
- An in Vivo Multiplexed Small-Molecule Screening Platform: ArticlesDocument11 pagesAn in Vivo Multiplexed Small-Molecule Screening Platform: ArticlesApocalypto StatumNo ratings yet
- Ddi 12970Document12 pagesDdi 12970Vellin LusianaNo ratings yet
- 2010.12 - A Robust, Simple Genotyping-By-Sequencing (GBS) Approach For High Diversity SpeciesDocument10 pages2010.12 - A Robust, Simple Genotyping-By-Sequencing (GBS) Approach For High Diversity SpeciesRibamar NunesNo ratings yet
- Allelic Analysis of Sheath Blight Resistance With Association Mapping in RiceDocument10 pagesAllelic Analysis of Sheath Blight Resistance With Association Mapping in Rice10sgNo ratings yet
- tmpAC TMPDocument12 pagestmpAC TMPFrontiersNo ratings yet
- Group 11 Quantitative PresentationDocument6 pagesGroup 11 Quantitative PresentationLincoln MazivanhangaNo ratings yet
- Use of Principal Component Analysis (PCA) and Hierarchical Cluster Analysis 2017Document8 pagesUse of Principal Component Analysis (PCA) and Hierarchical Cluster Analysis 2017Gustavo Andres Fuentes RodriguezNo ratings yet
- Principal Component Analysis On Spatial Data An 15072012Document25 pagesPrincipal Component Analysis On Spatial Data An 15072012Gustavo Andres Fuentes RodriguezNo ratings yet
- Principal Component Analysis 2016Document16 pagesPrincipal Component Analysis 2016Gustavo Andres Fuentes RodriguezNo ratings yet
- Mps 05 00049 v2Document16 pagesMps 05 00049 v2Gustavo Andres Fuentes RodriguezNo ratings yet
- Morphological and Molecular Studies of Three Species of 062020Document13 pagesMorphological and Molecular Studies of Three Species of 062020Gustavo Andres Fuentes RodriguezNo ratings yet
- Akpunarlievaetal 2016Document15 pagesAkpunarlievaetal 2016Gustavo Andres Fuentes RodriguezNo ratings yet
- 12th STD Bio-Botany Lesson-5 EM Book Back Answers-1Document3 pages12th STD Bio-Botany Lesson-5 EM Book Back Answers-1D Ashok KumarNo ratings yet
- Review Ontology and Endocrinology of The Reproductive System of Bulls From Fetus To MaturityDocument8 pagesReview Ontology and Endocrinology of The Reproductive System of Bulls From Fetus To MaturitySyahzidane YusufNo ratings yet
- HB-2061-003 HB DNY Blood Tissue 0720 WWDocument64 pagesHB-2061-003 HB DNY Blood Tissue 0720 WWAboubakar SidickNo ratings yet
- Kami Export - 9.4 - UsingTheHardyWeinbergEquation - Worksheet Danielle Ngambia TchetmiDocument3 pagesKami Export - 9.4 - UsingTheHardyWeinbergEquation - Worksheet Danielle Ngambia TchetmijongambiaNo ratings yet
- Theories of Aging: Eva B. Jugador, RNDocument56 pagesTheories of Aging: Eva B. Jugador, RNEva Boje-JugadorNo ratings yet
- Kendra Cherry: The Age Old Debate of Nature vs. NurtureDocument4 pagesKendra Cherry: The Age Old Debate of Nature vs. NurtureCharles Duke100% (1)
- Biology SPM Hots Questions & Answers (2020)Document9 pagesBiology SPM Hots Questions & Answers (2020)Sushi Emilia100% (1)
- Mi Rna Scope BrochureDocument3 pagesMi Rna Scope BrochurewendyNo ratings yet
- Fertilization & ImplantationDocument61 pagesFertilization & ImplantationchidimmaNo ratings yet
- ATM Gene: Genetics Home ReferenceDocument5 pagesATM Gene: Genetics Home ReferenceDurga MadhuriNo ratings yet
- Metabolism of LipidsDocument37 pagesMetabolism of LipidsSafura IjazNo ratings yet
- Molecular Biology of The Cell, Sixth Edition Chapter 7: Control of Gene ExpressionDocument36 pagesMolecular Biology of The Cell, Sixth Edition Chapter 7: Control of Gene ExpressionIsmael Torres-Pizarro100% (2)
- Exploring The Drug Development ProcessDocument9 pagesExploring The Drug Development Processs adhikariNo ratings yet
- Glycolytic Enzymes in Non-Glycolytic Web - Functional Analysis of The Key Players - Cell Biochemistry and BiophysicsDocument66 pagesGlycolytic Enzymes in Non-Glycolytic Web - Functional Analysis of The Key Players - Cell Biochemistry and BiophysicsAna JuliaNo ratings yet
- Week 5 Heredity Inheritance and Variation of TraitsDocument5 pagesWeek 5 Heredity Inheritance and Variation of TraitsMarlon James TobiasNo ratings yet
- B Pharma 3rd Year Biotechnology 21-04-2020Document5 pagesB Pharma 3rd Year Biotechnology 21-04-2020Shailesh MauryaNo ratings yet
- GENBIO2 MOD4 Mechanisms of Change of Population.Document22 pagesGENBIO2 MOD4 Mechanisms of Change of Population.Kris LaglivaNo ratings yet
- Earth and Life Sci QRTR 2 Module 4 Intro To Life Student Edition Grade II DescartesDocument53 pagesEarth and Life Sci QRTR 2 Module 4 Intro To Life Student Edition Grade II Descartesmelvin madronalNo ratings yet
- Human Genome Project Fridovich 2023Document6 pagesHuman Genome Project Fridovich 2023Santiago Castro HernándezNo ratings yet
- Microscopic Colitis Is Characterized by Intestinal DysbiosisDocument3 pagesMicroscopic Colitis Is Characterized by Intestinal Dysbiosisalexandra robuNo ratings yet
- TO Biochemistry TO Biochemistry: Basic Biomolecules and Their Polymers Basic Biomolecules and Their PolymersDocument7 pagesTO Biochemistry TO Biochemistry: Basic Biomolecules and Their Polymers Basic Biomolecules and Their PolymersShubhAm Pal100% (1)
- Structure of ADC-68, a novel carbapenem-hydrolyzing class C extended-spectrum β-lactamase isolated from Acinetobacter baumanniiDocument14 pagesStructure of ADC-68, a novel carbapenem-hydrolyzing class C extended-spectrum β-lactamase isolated from Acinetobacter baumanniigeerthi vasanNo ratings yet
- Production of Human Induced Pluripotent Stem CellDerived Cortical Neurospheres in The DASbox® MiniDocument12 pagesProduction of Human Induced Pluripotent Stem CellDerived Cortical Neurospheres in The DASbox® MiniHendryck Joseth Reguillo GonzalezNo ratings yet
- Mitosis Study GuideDocument2 pagesMitosis Study GuideKirstyn LathamNo ratings yet
- Mulualem Et Al.Document5 pagesMulualem Et Al.Amsalu Nebiyu WoldekirstosNo ratings yet
- Biology Project Human Health and DiseaseDocument11 pagesBiology Project Human Health and Diseasesonidipanshu66No ratings yet
- BIO101 Lec 04-DNA Denaturation and RenaturationDocument29 pagesBIO101 Lec 04-DNA Denaturation and RenaturationMika MaravillaNo ratings yet