Download as pdf or txt
You might also like
- Al Maths Pure Unit 6 MsDocument8 pagesAl Maths Pure Unit 6 MsHacjer EiNSTi3NNo ratings yet
- Differences Between Organization ChangeDocument3 pagesDifferences Between Organization ChangehksNo ratings yet
- BWT Septron Line 31-61 Rev01!08!05-18 Opm enDocument56 pagesBWT Septron Line 31-61 Rev01!08!05-18 Opm enDavide Grioni100% (1)
- History of U.S. Table Tennis - Vol. VI: 1970-1973Document506 pagesHistory of U.S. Table Tennis - Vol. VI: 1970-1973Tim Boggan100% (2)
- Statistical Approach To Machine TranslationDocument7 pagesStatistical Approach To Machine Translationمحمد سعدNo ratings yet
- 20 TolerantretrievalDocument39 pages20 TolerantretrievalAmit PrakashNo ratings yet
- Document PDFDocument6 pagesDocument PDFTaha TmaNo ratings yet
- Regular-Expression Derivatives Re-ExaminedDocument18 pagesRegular-Expression Derivatives Re-ExaminedAndri WijayaNo ratings yet
- Textual Characteristics For Language Engineering: Mathias Bank, Robert Remus, Martin SchierleDocument5 pagesTextual Characteristics For Language Engineering: Mathias Bank, Robert Remus, Martin SchierleacouillaultNo ratings yet
- Lect 11Document7 pagesLect 11Randika PereraNo ratings yet
- Automatic Identification of Non-Compositional PhrasesDocument8 pagesAutomatic Identification of Non-Compositional PhrasesNatalia MoskvinaNo ratings yet
- UrinomerricDocument7 pagesUrinomerricTimothy TateNo ratings yet
- Emnlp05 TextinferencegraphmatchingDocument8 pagesEmnlp05 Textinferencegraphmatchingdixade1732No ratings yet
- What's in A Translation Rule?: Michel Galley Mark Hopkins Kevin Knight and Daniel MarcuDocument8 pagesWhat's in A Translation Rule?: Michel Galley Mark Hopkins Kevin Knight and Daniel MarcuLaura Ana Maria BostanNo ratings yet
- NLP Unit II NotesDocument18 pagesNLP Unit II Notesnsyadav895950% (4)
- Wang Predicting Intonational PhrasingDocument8 pagesWang Predicting Intonational PhrasingAnonymous xo7GDeQNo ratings yet
- Ijsrmjournal, Journal Manager, 6 IjsrmDocument4 pagesIjsrmjournal, Journal Manager, 6 IjsrmSuparna SinhaNo ratings yet
- Processing Text: 4.1 From Words To TermsDocument52 pagesProcessing Text: 4.1 From Words To TermsThangam NatarajanNo ratings yet
- Context Sensitive EarleyDocument18 pagesContext Sensitive EarleyPraveen RajNo ratings yet
- Chapter 3Document21 pagesChapter 3kenenisa kibuNo ratings yet
- Multi-Tagging For Transition-Based Dependency ParsingDocument10 pagesMulti-Tagging For Transition-Based Dependency ParsingFreyja SigurgisladottirNo ratings yet
- Measure Word Generation For English-Chinese SMT Systems: Dongdong Zhang, Mu Li, Nan Duan, Chi-Ho Li, Ming ZhouDocument8 pagesMeasure Word Generation For English-Chinese SMT Systems: Dongdong Zhang, Mu Li, Nan Duan, Chi-Ho Li, Ming ZhouthemdktdNo ratings yet
- Fdocuments - in 1 Itcs 6265 Lecture 3 Dictionaries and Tolerant RetrievalDocument48 pagesFdocuments - in 1 Itcs 6265 Lecture 3 Dictionaries and Tolerant RetrievalNguyen Trung HieuNo ratings yet
- Evaluating Part-Of-speech Tagging and ParsingDocument26 pagesEvaluating Part-Of-speech Tagging and ParsingMayank GoyalNo ratings yet
- The Penn Treebank: An Overview: University of York Heslington, York, UKDocument18 pagesThe Penn Treebank: An Overview: University of York Heslington, York, UKNguyen HuyenNo ratings yet
- A Preference-First Language Processor Integrating The Unification Grammar and Markov Language Model For Speech Recognition-ApplicationsDocument6 pagesA Preference-First Language Processor Integrating The Unification Grammar and Markov Language Model For Speech Recognition-ApplicationsSruthi VargheseNo ratings yet
- Grammatical Methods in Computer Vision: An OverviewDocument23 pagesGrammatical Methods in Computer Vision: An OverviewDuncan Dunn DundeeNo ratings yet
- AI Notes Part-3Document29 pagesAI Notes Part-3Divyanshu PatwalNo ratings yet
- 2 - Text OperationDocument45 pages2 - Text OperationKirubel WakjiraNo ratings yet
- Vickrey - Word-Sense Disambiguation For Machine TranslationDocument8 pagesVickrey - Word-Sense Disambiguation For Machine TranslationPedor RomerNo ratings yet
- Weighted Automata in Text and Speech ProcessingDocument5 pagesWeighted Automata in Text and Speech ProcessingRadheshyam GawariNo ratings yet
- Unit IiiDocument17 pagesUnit IiiAllan RobeyNo ratings yet
- Class-Based N-Gram Models of Natural LanguageDocument14 pagesClass-Based N-Gram Models of Natural LanguageSorina ButurăNo ratings yet
- Yacht Club and Linea CalcDocument16 pagesYacht Club and Linea CalcTibyanNo ratings yet
- NLPDocument4 pagesNLPfarheen shaikhNo ratings yet
- Grammaire Et Rapport Final TP1 - Ing - Ling - 2019 - OrozcoRosnenDocument10 pagesGrammaire Et Rapport Final TP1 - Ing - Ling - 2019 - OrozcoRosnenplanetalinguaNo ratings yet
- Character N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataDocument9 pagesCharacter N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataHalahManehNo ratings yet
- UnitDocument3 pagesUnitkryonicmelNo ratings yet
- CS 540 Lecture Notes - LogicDocument5 pagesCS 540 Lecture Notes - Logicabdolmojeeb nourNo ratings yet
- An Algorithm For Suffix StrippingDocument7 pagesAn Algorithm For Suffix StrippingAnonymous z2QZEthyHoNo ratings yet
- Linguistic Regularities in Continuous Space Word RepresentationsDocument6 pagesLinguistic Regularities in Continuous Space Word RepresentationsAnonymous t5aOqdHpuhNo ratings yet
- Recognizing Textual Entailment With Tree Edit Distance AlgorithmsDocument4 pagesRecognizing Textual Entailment With Tree Edit Distance Algorithmsfacada10No ratings yet
- SBG Study NLP Notes From Unit 3Document14 pagesSBG Study NLP Notes From Unit 3KILLSHOT SKJNo ratings yet
- How To Write A Spelling CorrectorDocument9 pagesHow To Write A Spelling CorrectorafboterosNo ratings yet
- MCA Assignment MC0073Document21 pagesMCA Assignment MC0073Sanjay BhattacharyaNo ratings yet
- Joshua 4.0: Packing, PRO, and ParaphrasesDocument9 pagesJoshua 4.0: Packing, PRO, and ParaphrasesHuWalterNo ratings yet
- Natural Language Systems in PrologDocument29 pagesNatural Language Systems in PrologAnbe TranNo ratings yet
- Finite Automata, Digraph Connectivity, and Regular Expression SizeDocument12 pagesFinite Automata, Digraph Connectivity, and Regular Expression Sizebkaj chkoNo ratings yet
- NLP MCQ 153 Out of 427 - Part OneDocument30 pagesNLP MCQ 153 Out of 427 - Part Onemasumamemories12No ratings yet
- (Evenzoha, Danr) Uiuc, Edu: A Classification Approach To Word PredictionDocument8 pages(Evenzoha, Danr) Uiuc, Edu: A Classification Approach To Word PredictionsujanNo ratings yet
- 2 - Text OperationDocument43 pages2 - Text OperationHailemariam SetegnNo ratings yet
- Semeval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of NominalsDocument6 pagesSemeval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of NominalsaaaNo ratings yet
- NLP Unit 5Document10 pagesNLP Unit 5Shobhit RahaNo ratings yet
- Least Effort and The Origins of Scaling in Human Language: Ramon Ferrer I Cancho and Ricard V. SoleDocument4 pagesLeast Effort and The Origins of Scaling in Human Language: Ramon Ferrer I Cancho and Ricard V. SolermNo ratings yet
- Figure 1: Block Diagram of Combined Acoustic/syntactic Prosodic Label RecognizerDocument5 pagesFigure 1: Block Diagram of Combined Acoustic/syntactic Prosodic Label RecognizerMaulik MadhaviNo ratings yet
- N-Gram Language Models: Random Sentence Generated From A Jane Austen Trigram ModelDocument28 pagesN-Gram Language Models: Random Sentence Generated From A Jane Austen Trigram ModelAdi PutraNo ratings yet
- Definition and Classification of Semi-Fuzzy Quantifiers For The Evaluation of Fuzzy Quantified SentencesDocument40 pagesDefinition and Classification of Semi-Fuzzy Quantifiers For The Evaluation of Fuzzy Quantified SentencesAnastasiia DrapakNo ratings yet
- An Empirical Evaluation of Stop Word Removal in Statistical Machine TranslationDocument8 pagesAn Empirical Evaluation of Stop Word Removal in Statistical Machine Translationbujor2000ajaNo ratings yet
- A Classifier-Based Approach To Preposition and Determiner Error Correction in L2 EnglishDocument8 pagesA Classifier-Based Approach To Preposition and Determiner Error Correction in L2 EnglishSajadAbdaliNo ratings yet
- A Statistical Learning Algorithm For Word Segmentation: Problem StatementDocument30 pagesA Statistical Learning Algorithm For Word Segmentation: Problem StatementdinhbiNo ratings yet
- Constraint-Based Learning of Phonological ProcessesDocument11 pagesConstraint-Based Learning of Phonological Processesكرة القدم عالميNo ratings yet
- Sms TestDocument11 pagesSms TestVaishali KashyapNo ratings yet
- Data Mining:: Concepts and TechniquesDocument37 pagesData Mining:: Concepts and TechniquessuriyachackNo ratings yet
- Deep Learning Based NLP TechniquesDocument7 pagesDeep Learning Based NLP Techniquesabaynesh mogesNo ratings yet
- Pre-Trained Text Embeddings For Enhanced Text-to-Speech SynthesisDocument5 pagesPre-Trained Text Embeddings For Enhanced Text-to-Speech Synthesisabaynesh mogesNo ratings yet
- Exploiting Morphological and Phonological Features To Improve Prosodic Phrasing For Mongolian Speech SynthesisDocument12 pagesExploiting Morphological and Phonological Features To Improve Prosodic Phrasing For Mongolian Speech Synthesisabaynesh mogesNo ratings yet
- Cross-Lingual, Multi-Speaker Text-To-Speech Synthesis Using Neural Speaker EmbeddingDocument5 pagesCross-Lingual, Multi-Speaker Text-To-Speech Synthesis Using Neural Speaker Embeddingabaynesh mogesNo ratings yet
- Improving The Prosody of RNN-based English Text-To-Speech Synthesis by Incorporating A BERT ModelDocument5 pagesImproving The Prosody of RNN-based English Text-To-Speech Synthesis by Incorporating A BERT Modelabaynesh mogesNo ratings yet
- Decision Tree and KNN Assignment TwoDocument13 pagesDecision Tree and KNN Assignment Twoabaynesh mogesNo ratings yet
- AirlinesDocument16 pagesAirlinesPipie SafikahNo ratings yet
- Xt2052y2asr GDocument1 pageXt2052y2asr GjoseNo ratings yet
- Ultra Tech Cement Review 16 9 19Document3 pagesUltra Tech Cement Review 16 9 19vivekNo ratings yet
- Cases On EntrapmentDocument25 pagesCases On Entrapmentmarion914No ratings yet
- Cargo Handling and Stowage Pages 120Document21 pagesCargo Handling and Stowage Pages 120arafeeu83% (12)
- The Ayurveda Encyclopedia - Natural Secrets To Healing, PreventionDocument10 pagesThe Ayurveda Encyclopedia - Natural Secrets To Healing, PreventionBhushan100% (2)
- Describing The Impact of Massive Open Online Course: Darielle Apilas-Bacayan Developer LessonDocument5 pagesDescribing The Impact of Massive Open Online Course: Darielle Apilas-Bacayan Developer LessonJhunel FernandezNo ratings yet
- Endocrine SystemDocument11 pagesEndocrine SystemDayledaniel SorvetoNo ratings yet
- "Green Finance": A Powerful Tool For SustainabilityDocument7 pages"Green Finance": A Powerful Tool For SustainabilitySocial Science Journal for Advanced ResearchNo ratings yet
- LGU-Santa Maria CC2021Document35 pagesLGU-Santa Maria CC2021Alyssa Marie MartinezNo ratings yet
- Certiport Exam Administration Policies: Examination SecurityDocument2 pagesCertiport Exam Administration Policies: Examination SecurityrajputamitdNo ratings yet
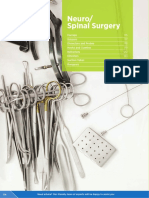
- SH Catalogue - Neuro & SpinalDocument17 pagesSH Catalogue - Neuro & SpinalSaqibullah ShahzadNo ratings yet
- Report On Seismic CodesDocument2 pagesReport On Seismic CodesLakshmiRaviChanduKolusuNo ratings yet
- 7.bow-Tie Analysis For Risk ManagementDocument20 pages7.bow-Tie Analysis For Risk ManagementSabah Khan Raja100% (1)
- MiraglianoDocument52 pagesMiraglianohansudongNo ratings yet
- Form Jurnal JesikomDocument9 pagesForm Jurnal JesikomAhmad Hafiizh kudrawiNo ratings yet
- Pvh56 Pvh63 Parts and ServiceDocument8 pagesPvh56 Pvh63 Parts and ServiceRiki AkbarNo ratings yet
- The Hydrological CycleDocument6 pagesThe Hydrological CycleF A L L E NNo ratings yet
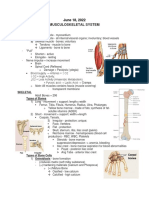
- Musculoskeletal SystemDocument5 pagesMusculoskeletal SystemAdriane VillanuevaNo ratings yet
- Writing A Narrative EssayDocument6 pagesWriting A Narrative EssayBob BolNo ratings yet
- The SNG Blueprint Part 1 PDFDocument26 pagesThe SNG Blueprint Part 1 PDFAdrian PatrikNo ratings yet
- CTPaper IIDocument118 pagesCTPaper IIMahmoud MansourNo ratings yet
- Acc Grip Housing: Code Itemname Unit M.O.P MRPDocument118 pagesAcc Grip Housing: Code Itemname Unit M.O.P MRPphenomenal hunkNo ratings yet
- Audit Non Conformance ReportDocument4 pagesAudit Non Conformance Reportbudi_alamsyah100% (2)
- Multiple Compounding Periods in A Year: Example: Credit Card DebtDocument36 pagesMultiple Compounding Periods in A Year: Example: Credit Card DebtnorahNo ratings yet
- Website Designing Company in DallasDocument6 pagesWebsite Designing Company in DallasRyan WilsonNo ratings yet