Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5824)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Mining Attachment Final ReportDocument53 pagesMining Attachment Final Reporttkubvos100% (5)
- CampbellDocument32 pagesCampbellapi-3720161No ratings yet
- Prs w13d1 QonlyDocument2 pagesPrs w13d1 Qonlyakirank1No ratings yet
- Prs w14d1 QonlyDocument4 pagesPrs w14d1 Qonlyakirank1No ratings yet
- Prs w07d1 QonlyDocument5 pagesPrs w07d1 Qonlyakirank1No ratings yet
- Coherent, Monochromatic Plane WavesDocument6 pagesCoherent, Monochromatic Plane Wavesakirank1No ratings yet
- LexisNexis® 1976 Copyright ActDocument1 pageLexisNexis® 1976 Copyright Actakirank1No ratings yet
- Class 33: Outline: Hour 1: InterferenceDocument38 pagesClass 33: Outline: Hour 1: Interferenceakirank1No ratings yet
- Experiment 6: Prediction 1Document8 pagesExperiment 6: Prediction 1akirank1No ratings yet
- Prs w09d1 QonlyDocument4 pagesPrs w09d1 Qonlyakirank1No ratings yet
- Look at The 2 Top Vote Getters (Tied For First Place!) On The Handout Sheet and Vote For The One You Find Most Appealing or Striking. 1. 2Document39 pagesLook at The 2 Top Vote Getters (Tied For First Place!) On The Handout Sheet and Vote For The One You Find Most Appealing or Striking. 1. 2akirank1No ratings yet
- Class 36: Outline: Yell If You Have Any QuestionsDocument46 pagesClass 36: Outline: Yell If You Have Any Questionsakirank1No ratings yet
- Practice Right Hand Rule #1Document4 pagesPractice Right Hand Rule #1akirank1No ratings yet
- Prs w03d2 QonlyDocument8 pagesPrs w03d2 Qonlyakirank1No ratings yet
- Class 31: Outline: Hour 1: Concept Review / Overview PRS Questions - Possible Exam Questions Hour 2Document46 pagesClass 31: Outline: Hour 1: Concept Review / Overview PRS Questions - Possible Exam Questions Hour 2akirank1No ratings yet
- Resistance: L and Cross Sectional Area A, TheDocument5 pagesResistance: L and Cross Sectional Area A, Theakirank1No ratings yet
- Prs w05d1 QonlyDocument3 pagesPrs w05d1 Qonlyakirank1No ratings yet
- Prs w02d1 QonlyDocument6 pagesPrs w02d1 Qonlyakirank1No ratings yet
- Class 32: OutlineDocument36 pagesClass 32: Outlineakirank1No ratings yet
- Class 30: Outline: Hour 1: Traveling & Standing WavesDocument29 pagesClass 30: Outline: Hour 1: Traveling & Standing Wavesakirank1No ratings yet
- Prs w03d1 QonlyDocument4 pagesPrs w03d1 Qonlyakirank1No ratings yet
- Prs w01d1 QonlyDocument9 pagesPrs w01d1 Qonlyakirank1No ratings yet
- Class 24: Outline: Hour 1: Inductance & LR Circuits Hour 2: Energy in InductorsDocument37 pagesClass 24: Outline: Hour 1: Inductance & LR Circuits Hour 2: Energy in Inductorsakirank1No ratings yet
- Class 20: Outline: Hour 1: Faraday's LawDocument42 pagesClass 20: Outline: Hour 1: Faraday's Lawakirank1No ratings yet
- Lecture 23: Outline: Yell If You Have Any QuestionsDocument43 pagesLecture 23: Outline: Yell If You Have Any Questionsakirank1No ratings yet
- Class 18: Outline: Hour 1: Levitation Experiment 8: Magnetic Forces Hour 2: Ampere's LawDocument49 pagesClass 18: Outline: Hour 1: Levitation Experiment 8: Magnetic Forces Hour 2: Ampere's Lawakirank1No ratings yet
- Class 17: Outline: Hour 1: Dipoles & Magnetic FieldsDocument26 pagesClass 17: Outline: Hour 1: Dipoles & Magnetic Fieldsakirank1No ratings yet
- Class 28: Outline: Hour 1: Displacement Current Maxwell's Equations Hour 2: Electromagnetic WavesDocument33 pagesClass 28: Outline: Hour 1: Displacement Current Maxwell's Equations Hour 2: Electromagnetic Wavesakirank1No ratings yet
- Class 14: Outline: Hour 1: Magnetic Fields Expt. 5: Magnetic FieldsDocument31 pagesClass 14: Outline: Hour 1: Magnetic Fields Expt. 5: Magnetic Fieldsakirank1No ratings yet
- Class 15: Outline: Hour 1: Magnetic Force Expt. 6: Magnetic ForceDocument33 pagesClass 15: Outline: Hour 1: Magnetic Force Expt. 6: Magnetic Forceakirank1No ratings yet
- Class 13: Outline: Hour 1Document33 pagesClass 13: Outline: Hour 1akirank1No ratings yet
- Corporate BrochureDocument5 pagesCorporate BrochuremersiumNo ratings yet
- JSW Steel Deluxe - LowResolutionDocument196 pagesJSW Steel Deluxe - LowResolutionChiranjit RoyNo ratings yet
- Ge Mining Cas Smart Group 17 Oct 2013Document81 pagesGe Mining Cas Smart Group 17 Oct 2013Eleazar DavidNo ratings yet
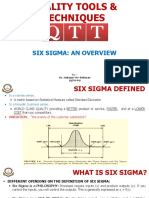
- Six Sigma-An Overview-1Document28 pagesSix Sigma-An Overview-1Maria ShahzadiNo ratings yet
- Dilution and Ore Loss - A Short Practical GuideDocument6 pagesDilution and Ore Loss - A Short Practical GuideTúlio AbduaniNo ratings yet
- Aluminium Zeitung 01-02-11Document100 pagesAluminium Zeitung 01-02-11Jose DenizNo ratings yet
- NMRSYorkshireDocument31 pagesNMRSYorkshirepaul metcalfeNo ratings yet
- Casanovas vs. HordDocument10 pagesCasanovas vs. HordHeidiNo ratings yet
- Contoh Std.Document4 pagesContoh Std.septian yodhaskaraNo ratings yet
- Carriers of Conflict (2017)Document19 pagesCarriers of Conflict (2017)Western Sahara Resource Watch100% (2)
- 2014 List Delegates From WWW - Coal China - Org.cnDocument4 pages2014 List Delegates From WWW - Coal China - Org.cnamitsh20072458No ratings yet
- Errington-Vermillion Fact SheetDocument4 pagesErrington-Vermillion Fact SheetsebastienperthNo ratings yet
- Citronen Feasibility Study PDFDocument157 pagesCitronen Feasibility Study PDFrjkmehtaNo ratings yet
- Analyst Coverage - Elecon EngineeringDocument17 pagesAnalyst Coverage - Elecon EngineeringdebarkaNo ratings yet
- ThyssenKrupp Brochure Minerals and MiningDocument36 pagesThyssenKrupp Brochure Minerals and MiningjoacochacomanNo ratings yet
- The Mining CycleDocument36 pagesThe Mining CyclePraneeth Kumar LedhalaNo ratings yet
- Litian Rock Drilling Tools CatalogueDocument52 pagesLitian Rock Drilling Tools CatalogueLitian MachineryNo ratings yet
- R13 MTSR May 2017 PDFDocument46 pagesR13 MTSR May 2017 PDFblackieNo ratings yet
- Iron Ore Dressing Plant Auditing - LectureDocument7 pagesIron Ore Dressing Plant Auditing - LectureravibelavadiNo ratings yet
- MMTCDocument13 pagesMMTCbarotviral05No ratings yet
- DrillingDocument68 pagesDrillingVenkata Ramana67% (3)
- Data MiningDocument30 pagesData MiningHarminderSingh Bindra100% (1)
- The Evolution and Optimization of Sublevel Cave Drill and Blast Practices at Ridgeway Gold Mine - Production RingsDocument11 pagesThe Evolution and Optimization of Sublevel Cave Drill and Blast Practices at Ridgeway Gold Mine - Production RingsBoris Leal MartinezNo ratings yet
- Sample Micro-Macro Questions EnglishDocument3 pagesSample Micro-Macro Questions EnglishAhmed HajiNo ratings yet
- Coal Operations Capability Statement 24ppDocument24 pagesCoal Operations Capability Statement 24ppChandan PandeyNo ratings yet
- Pei201309 DLDocument116 pagesPei201309 DLNinh Quoc TrungNo ratings yet
- Manila Standard Today - June 29, 2012 IssueDocument24 pagesManila Standard Today - June 29, 2012 IssueManila Standard TodayNo ratings yet
- Liberation, Separation, ExtractionDocument100 pagesLiberation, Separation, Extractiongaol_bird009No ratings yet
- QMRS Guidelines For Rescue CapabilityDocument9 pagesQMRS Guidelines For Rescue CapabilityAdrian CohenNo ratings yet