
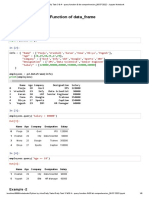
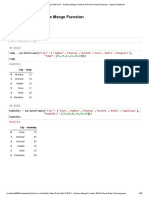
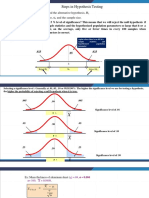
Daily Task 9 - Statistical Tests - Jupyter Notebook
Daily Task 9 - Statistical Tests - Jupyter Notebook
You might also like
- Statistics For People Who Hate Statistics 5th Edition Salkind Test BankDocument15 pagesStatistics For People Who Hate Statistics 5th Edition Salkind Test Bankedithelizabeth5mz18100% (26)
- Questions For Exercise 50Document3 pagesQuestions For Exercise 50araceliNo ratings yet
- M6 - Problem Set - Introduction To Statistics-2021 - LagiosDocument6 pagesM6 - Problem Set - Introduction To Statistics-2021 - LagiosAmandeep SinghNo ratings yet
- Practical Design of Experiments: DoE Made EasyFrom EverandPractical Design of Experiments: DoE Made EasyRating: 4.5 out of 5 stars4.5/5 (7)
- Null & Alternative HypothesesDocument3 pagesNull & Alternative HypothesesCristy Mohammed0% (1)
- Hypothesis TestingDocument54 pagesHypothesis Testingsiddharth shirwadkarNo ratings yet
- Chapter 1 Statistical Sleuth in RDocument10 pagesChapter 1 Statistical Sleuth in RCollin SandersonNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- 'Iris': Import As Import As Import As Import AsDocument5 pages'Iris': Import As Import As Import As Import Asadel hanyNo ratings yet
- Calculating P-ValueDocument3 pagesCalculating P-ValueMuhammad IsmaelNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- NAME-Rajat Gupta Section - B2B2 (Marketing and Analytics) UID - 2019-1706-0001-0007Document9 pagesNAME-Rajat Gupta Section - B2B2 (Marketing and Analytics) UID - 2019-1706-0001-0007Rajat GuptaNo ratings yet
- ML Lab Program 7Document7 pagesML Lab Program 7sbaradwaj22No ratings yet
- R Homework Help: For Any Homework Related Queries, Call Us At:-+1 678 648 4277 You Can Mail Us At: - or Reach Us AtDocument8 pagesR Homework Help: For Any Homework Related Queries, Call Us At:-+1 678 648 4277 You Can Mail Us At: - or Reach Us AtStatistics Homework SolverNo ratings yet
- Lab4 - Jupyter NotebookDocument3 pagesLab4 - Jupyter NotebookGautam SharmaNo ratings yet
- Hypothesis Testing: ObjectivesDocument9 pagesHypothesis Testing: ObjectivesAdles RioNo ratings yet
- Assignment 4Document3 pagesAssignment 4makabigail7No ratings yet
- 1c Review of Concepts in Statistics Measures of Central TendencyDocument14 pages1c Review of Concepts in Statistics Measures of Central TendencyCamille SalmasanNo ratings yet
- T-Test With Likert Scale VariablesDocument5 pagesT-Test With Likert Scale VariablesTim BookNo ratings yet
- Chapter 1Document32 pagesChapter 1matheuslaraNo ratings yet
- Hypothesis TestingDocument17 pagesHypothesis TestingJose Maria Arjona CaballeroNo ratings yet
- Population Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument11 pagesPopulation Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTRamona BaculinaoNo ratings yet
- Genetic AlgorithmDocument3 pagesGenetic AlgorithmJerald RoyNo ratings yet
- BS 8 1Document27 pagesBS 8 1Prudhvinadh KopparapuNo ratings yet
- Lesson 14 - Hypothesis Testing Independent Samples: Return To Cover PageDocument4 pagesLesson 14 - Hypothesis Testing Independent Samples: Return To Cover PagezaenalkmiNo ratings yet
- Naive Bayes NumericalsDocument9 pagesNaive Bayes NumericalshelloiamthepointNo ratings yet
- One-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Document4 pagesOne-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Chris TanginNo ratings yet
- IGNOU MBA MS - 08 Solved Assignments 2011Document12 pagesIGNOU MBA MS - 08 Solved Assignments 2011Manoj SharmaNo ratings yet
- Group 7 - Hypothesis Testing - 1Document25 pagesGroup 7 - Hypothesis Testing - 1John Christopher GozunNo ratings yet
- Mann Whitney U TestDocument19 pagesMann Whitney U TestANGELO JOSEPH CASTILLONo ratings yet
- Population Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument11 pagesPopulation Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTRochelle AlmeraNo ratings yet
- Statistical Methods For Decision MakingDocument10 pagesStatistical Methods For Decision MakingBiruk YidnekachewNo ratings yet
- Detecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonDocument6 pagesDetecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonNarendra SinghNo ratings yet
- ISOM2500Practice Final SolDocument8 pagesISOM2500Practice Final SoljayceeshuiNo ratings yet
- Chapter 1Document32 pagesChapter 1CALVIN ALBERTO LOPEZ ALVAREZNo ratings yet
- Hypothesis Testing of Population MeanDocument51 pagesHypothesis Testing of Population MeanRamesh GoudNo ratings yet
- Unlabeled Data - Semi-Supervised Classification (PU Learning) - by Alon Agmon - Towards Data ScienceDocument10 pagesUnlabeled Data - Semi-Supervised Classification (PU Learning) - by Alon Agmon - Towards Data Sciencearunspai1478No ratings yet
- The MeanDocument10 pagesThe MeanEprinthousespNo ratings yet
- Topic 7Document26 pagesTopic 7Zienab AhmedNo ratings yet
- Sta NotesDocument44 pagesSta NotesManshal BrohiNo ratings yet
- Ch10 and 11 Rev AnswersDocument16 pagesCh10 and 11 Rev AnswerskrothrocNo ratings yet
- 2019 - 01 - 29 - Second - Partial - Exam - D - SolutionsDocument6 pages2019 - 01 - 29 - Second - Partial - Exam - D - SolutionsfabriNo ratings yet
- Chapter 3Document29 pagesChapter 3matheuslaraNo ratings yet
- Tagpuno 9.1Document30 pagesTagpuno 9.1rikitagpunoNo ratings yet
- NLP PDFDocument17 pagesNLP PDFvlmohammedadnan9No ratings yet
- Graded Homework 11 1Document19 pagesGraded Homework 11 1Hunter ChastainNo ratings yet
- Stat Doc Pract 6,7,8Document17 pagesStat Doc Pract 6,7,8Ajay KajaniyaNo ratings yet
- Python and SQL Interview QuestionsDocument29 pagesPython and SQL Interview Questionsmd sajid samiNo ratings yet
- Probability Basics Part1Document143 pagesProbability Basics Part1Vishal SharmaNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- UntitledDocument12 pagesUntitledapi-262707463No ratings yet
- Week 6 - Result Analysis 2bDocument60 pagesWeek 6 - Result Analysis 2bAbdul KarimNo ratings yet
- Digi-Notes-Percentage - Maths-4-12-2015 PDFDocument46 pagesDigi-Notes-Percentage - Maths-4-12-2015 PDFSelvaraj VillyNo ratings yet
- Dependent T TestDocument38 pagesDependent T TestRatna Monika SariNo ratings yet
- Kimjeesoo - LATE - 292309 - 18721255 - PS 2 - Flores, Kim, Moon & Wu - DXDocument10 pagesKimjeesoo - LATE - 292309 - 18721255 - PS 2 - Flores, Kim, Moon & Wu - DXJeesoo KimNo ratings yet
- Project - Stat210: Spring2020 Instructor: Group MembersDocument7 pagesProject - Stat210: Spring2020 Instructor: Group MembersWaqas NadeemNo ratings yet
- Sampling in PythonDocument140 pagesSampling in PythonjcmayacNo ratings yet
- Advanced Statistical Methods Using RDocument32 pagesAdvanced Statistical Methods Using RPratik GugliyaNo ratings yet
- SLG 28.2 - Procedure in Doing A Test For A MeanDocument7 pagesSLG 28.2 - Procedure in Doing A Test For A Meanrex pangetNo ratings yet
- Math 1040 Final ProjectDocument11 pagesMath 1040 Final Projectapi-300784866No ratings yet
- Vrushali Resume SAP 2022Document4 pagesVrushali Resume SAP 2022Vrushali VishwasraoNo ratings yet
- Daily Task 8 - Data AnalysisDocument11 pagesDaily Task 8 - Data AnalysisVrushali VishwasraoNo ratings yet
- Daily Task - Day - 2 - Jupyter NotebookDocument6 pagesDaily Task - Day - 2 - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Day - 1 - String - Functions - Jupyter NotebookDocument16 pagesDay - 1 - String - Functions - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Daily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookDocument6 pagesDaily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Daily Task 6 & 7 - Explore Merge Function & Perform Data Cleaning - Jupyter NotebookDocument23 pagesDaily Task 6 & 7 - Explore Merge Function & Perform Data Cleaning - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Adipose - Tissue - Prediction - Jupyter NotebookDocument8 pagesAdipose - Tissue - Prediction - Jupyter NotebookVrushali VishwasraoNo ratings yet
- ANOVADocument33 pagesANOVABhatara Ayi MeataNo ratings yet
- Assignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Document32 pagesAssignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Sakib Ul-abrarNo ratings yet
- Hypothesis Testing (Vikram Shermale)Document5 pagesHypothesis Testing (Vikram Shermale)vikram shermaleNo ratings yet
- Inferential StatsDocument11 pagesInferential Statsvisu009No ratings yet
- Type 1 and Ii ErrorDocument8 pagesType 1 and Ii ErrorDina Jean SombrioNo ratings yet
- Performance Task in Statistics and ProbabilityDocument4 pagesPerformance Task in Statistics and ProbabilityF 12-Einstein Fatima V. de CastroNo ratings yet
- Kajian Tentang Perumusan Hipotesis Statistik Dalam Pengujian Hipotesis PenelitianDocument4 pagesKajian Tentang Perumusan Hipotesis Statistik Dalam Pengujian Hipotesis PenelitianMeylan HusinNo ratings yet
- Mid Term Exam - Statistical Analysis: A. I OnlyDocument6 pagesMid Term Exam - Statistical Analysis: A. I OnlyJanine LerumNo ratings yet
- Annexure Granger Causality Test For Sectoral Indices and USD/INR Null Hypothesis F-Statistics ProbabilityDocument31 pagesAnnexure Granger Causality Test For Sectoral Indices and USD/INR Null Hypothesis F-Statistics ProbabilitytouffiqNo ratings yet
- Hypothesis Testing With One SampleDocument68 pagesHypothesis Testing With One SampleDavid EdemNo ratings yet
- Hypothesis TestingDocument66 pagesHypothesis TestingkiranNo ratings yet
- Artikel Septi Nurhayati 0719011921Document14 pagesArtikel Septi Nurhayati 0719011921Serba SerbiNo ratings yet
- Uji Hipotesis Satu Sampel Bu SoDocument18 pagesUji Hipotesis Satu Sampel Bu SoangesthyNo ratings yet
- Tables - Hypothesis Testing FormulaDocument7 pagesTables - Hypothesis Testing FormulaecirecirNo ratings yet
- ANOVADocument18 pagesANOVADiofel Rose FernandezNo ratings yet
- L23 - Hypothesis Testing ExamplesDocument24 pagesL23 - Hypothesis Testing Examplesquang hoaNo ratings yet
- Basic Business Statistics 5Th Edition Mark Test Bank Full Chapter PDFDocument60 pagesBasic Business Statistics 5Th Edition Mark Test Bank Full Chapter PDFbenedictrobertvchkb100% (14)
- MCQ On Unit 6.3 - Attempt ReviewDocument3 pagesMCQ On Unit 6.3 - Attempt ReviewDemo Account 1No ratings yet
- Data T-TestDocument4 pagesData T-TestMUHAMMAD HAFIDZ MUNAWARNo ratings yet
- 14 Interpretation of The Population Proportion SPTC 1702 q4 FPFDocument34 pages14 Interpretation of The Population Proportion SPTC 1702 q4 FPFpersonalizedlife6No ratings yet
- BEale Papers-3-4Document2 pagesBEale Papers-3-4Ladislao BellagambaNo ratings yet
- Assignment Chapter 13 - Nabilah AuliaDocument12 pagesAssignment Chapter 13 - Nabilah AuliaNabilah AuliaNo ratings yet
- Wa0007.Document72 pagesWa0007.Sony SurbaktyNo ratings yet
- Module 4 Excel Utility II: Hypothesis Tests For Two PopulationsDocument5 pagesModule 4 Excel Utility II: Hypothesis Tests For Two PopulationsYash ModiNo ratings yet
- ANOVA, T-Test and Other Statistical Tests With PythonDocument11 pagesANOVA, T-Test and Other Statistical Tests With PythonTeto ScheduleNo ratings yet
- Quiz Lesson 6 Hypothesis Testing (Quantitative Methods)Document24 pagesQuiz Lesson 6 Hypothesis Testing (Quantitative Methods)Hareen JuniorNo ratings yet
- Hypothesis Testing Random MotorsDocument8 pagesHypothesis Testing Random MotorsLinn ArshadNo ratings yet






























































































Download as pdf or txt
You might also like
- Statistics For People Who Hate Statistics 5th Edition Salkind Test BankDocument15 pagesStatistics For People Who Hate Statistics 5th Edition Salkind Test Bankedithelizabeth5mz18100% (26)
- Questions For Exercise 50Document3 pagesQuestions For Exercise 50araceliNo ratings yet
- M6 - Problem Set - Introduction To Statistics-2021 - LagiosDocument6 pagesM6 - Problem Set - Introduction To Statistics-2021 - LagiosAmandeep SinghNo ratings yet
- Practical Design of Experiments: DoE Made EasyFrom EverandPractical Design of Experiments: DoE Made EasyRating: 4.5 out of 5 stars4.5/5 (7)
- Null & Alternative HypothesesDocument3 pagesNull & Alternative HypothesesCristy Mohammed0% (1)
- Hypothesis TestingDocument54 pagesHypothesis Testingsiddharth shirwadkarNo ratings yet
- Chapter 1 Statistical Sleuth in RDocument10 pagesChapter 1 Statistical Sleuth in RCollin SandersonNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- 'Iris': Import As Import As Import As Import AsDocument5 pages'Iris': Import As Import As Import As Import Asadel hanyNo ratings yet
- Calculating P-ValueDocument3 pagesCalculating P-ValueMuhammad IsmaelNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- NAME-Rajat Gupta Section - B2B2 (Marketing and Analytics) UID - 2019-1706-0001-0007Document9 pagesNAME-Rajat Gupta Section - B2B2 (Marketing and Analytics) UID - 2019-1706-0001-0007Rajat GuptaNo ratings yet
- ML Lab Program 7Document7 pagesML Lab Program 7sbaradwaj22No ratings yet
- R Homework Help: For Any Homework Related Queries, Call Us At:-+1 678 648 4277 You Can Mail Us At: - or Reach Us AtDocument8 pagesR Homework Help: For Any Homework Related Queries, Call Us At:-+1 678 648 4277 You Can Mail Us At: - or Reach Us AtStatistics Homework SolverNo ratings yet
- Lab4 - Jupyter NotebookDocument3 pagesLab4 - Jupyter NotebookGautam SharmaNo ratings yet
- Hypothesis Testing: ObjectivesDocument9 pagesHypothesis Testing: ObjectivesAdles RioNo ratings yet
- Assignment 4Document3 pagesAssignment 4makabigail7No ratings yet
- 1c Review of Concepts in Statistics Measures of Central TendencyDocument14 pages1c Review of Concepts in Statistics Measures of Central TendencyCamille SalmasanNo ratings yet
- T-Test With Likert Scale VariablesDocument5 pagesT-Test With Likert Scale VariablesTim BookNo ratings yet
- Chapter 1Document32 pagesChapter 1matheuslaraNo ratings yet
- Hypothesis TestingDocument17 pagesHypothesis TestingJose Maria Arjona CaballeroNo ratings yet
- Population Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument11 pagesPopulation Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTRamona BaculinaoNo ratings yet
- Genetic AlgorithmDocument3 pagesGenetic AlgorithmJerald RoyNo ratings yet
- BS 8 1Document27 pagesBS 8 1Prudhvinadh KopparapuNo ratings yet
- Lesson 14 - Hypothesis Testing Independent Samples: Return To Cover PageDocument4 pagesLesson 14 - Hypothesis Testing Independent Samples: Return To Cover PagezaenalkmiNo ratings yet
- Naive Bayes NumericalsDocument9 pagesNaive Bayes NumericalshelloiamthepointNo ratings yet
- One-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Document4 pagesOne-Sample Test of Proportions: Z 1.733 One-Tailed Probability 0.042 Two-Tailed Probability 0.084Chris TanginNo ratings yet
- IGNOU MBA MS - 08 Solved Assignments 2011Document12 pagesIGNOU MBA MS - 08 Solved Assignments 2011Manoj SharmaNo ratings yet
- Group 7 - Hypothesis Testing - 1Document25 pagesGroup 7 - Hypothesis Testing - 1John Christopher GozunNo ratings yet
- Mann Whitney U TestDocument19 pagesMann Whitney U TestANGELO JOSEPH CASTILLONo ratings yet
- Population Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument11 pagesPopulation Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTRochelle AlmeraNo ratings yet
- Statistical Methods For Decision MakingDocument10 pagesStatistical Methods For Decision MakingBiruk YidnekachewNo ratings yet
- Detecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonDocument6 pagesDetecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonNarendra SinghNo ratings yet
- ISOM2500Practice Final SolDocument8 pagesISOM2500Practice Final SoljayceeshuiNo ratings yet
- Chapter 1Document32 pagesChapter 1CALVIN ALBERTO LOPEZ ALVAREZNo ratings yet
- Hypothesis Testing of Population MeanDocument51 pagesHypothesis Testing of Population MeanRamesh GoudNo ratings yet
- Unlabeled Data - Semi-Supervised Classification (PU Learning) - by Alon Agmon - Towards Data ScienceDocument10 pagesUnlabeled Data - Semi-Supervised Classification (PU Learning) - by Alon Agmon - Towards Data Sciencearunspai1478No ratings yet
- The MeanDocument10 pagesThe MeanEprinthousespNo ratings yet
- Topic 7Document26 pagesTopic 7Zienab AhmedNo ratings yet
- Sta NotesDocument44 pagesSta NotesManshal BrohiNo ratings yet
- Ch10 and 11 Rev AnswersDocument16 pagesCh10 and 11 Rev AnswerskrothrocNo ratings yet
- 2019 - 01 - 29 - Second - Partial - Exam - D - SolutionsDocument6 pages2019 - 01 - 29 - Second - Partial - Exam - D - SolutionsfabriNo ratings yet
- Chapter 3Document29 pagesChapter 3matheuslaraNo ratings yet
- Tagpuno 9.1Document30 pagesTagpuno 9.1rikitagpunoNo ratings yet
- NLP PDFDocument17 pagesNLP PDFvlmohammedadnan9No ratings yet
- Graded Homework 11 1Document19 pagesGraded Homework 11 1Hunter ChastainNo ratings yet
- Stat Doc Pract 6,7,8Document17 pagesStat Doc Pract 6,7,8Ajay KajaniyaNo ratings yet
- Python and SQL Interview QuestionsDocument29 pagesPython and SQL Interview Questionsmd sajid samiNo ratings yet
- Probability Basics Part1Document143 pagesProbability Basics Part1Vishal SharmaNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- UntitledDocument12 pagesUntitledapi-262707463No ratings yet
- Week 6 - Result Analysis 2bDocument60 pagesWeek 6 - Result Analysis 2bAbdul KarimNo ratings yet
- Digi-Notes-Percentage - Maths-4-12-2015 PDFDocument46 pagesDigi-Notes-Percentage - Maths-4-12-2015 PDFSelvaraj VillyNo ratings yet
- Dependent T TestDocument38 pagesDependent T TestRatna Monika SariNo ratings yet
- Kimjeesoo - LATE - 292309 - 18721255 - PS 2 - Flores, Kim, Moon & Wu - DXDocument10 pagesKimjeesoo - LATE - 292309 - 18721255 - PS 2 - Flores, Kim, Moon & Wu - DXJeesoo KimNo ratings yet
- Project - Stat210: Spring2020 Instructor: Group MembersDocument7 pagesProject - Stat210: Spring2020 Instructor: Group MembersWaqas NadeemNo ratings yet
- Sampling in PythonDocument140 pagesSampling in PythonjcmayacNo ratings yet
- Advanced Statistical Methods Using RDocument32 pagesAdvanced Statistical Methods Using RPratik GugliyaNo ratings yet
- SLG 28.2 - Procedure in Doing A Test For A MeanDocument7 pagesSLG 28.2 - Procedure in Doing A Test For A Meanrex pangetNo ratings yet
- Math 1040 Final ProjectDocument11 pagesMath 1040 Final Projectapi-300784866No ratings yet
- Vrushali Resume SAP 2022Document4 pagesVrushali Resume SAP 2022Vrushali VishwasraoNo ratings yet
- Daily Task 8 - Data AnalysisDocument11 pagesDaily Task 8 - Data AnalysisVrushali VishwasraoNo ratings yet
- Daily Task - Day - 2 - Jupyter NotebookDocument6 pagesDaily Task - Day - 2 - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Day - 1 - String - Functions - Jupyter NotebookDocument16 pagesDay - 1 - String - Functions - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Daily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookDocument6 pagesDaily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Daily Task 6 & 7 - Explore Merge Function & Perform Data Cleaning - Jupyter NotebookDocument23 pagesDaily Task 6 & 7 - Explore Merge Function & Perform Data Cleaning - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Adipose - Tissue - Prediction - Jupyter NotebookDocument8 pagesAdipose - Tissue - Prediction - Jupyter NotebookVrushali VishwasraoNo ratings yet
- ANOVADocument33 pagesANOVABhatara Ayi MeataNo ratings yet
- Assignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Document32 pagesAssignment On Chapter-10 (Maths Solved) Business Statistics Course Code - ALD 2104Sakib Ul-abrarNo ratings yet
- Hypothesis Testing (Vikram Shermale)Document5 pagesHypothesis Testing (Vikram Shermale)vikram shermaleNo ratings yet
- Inferential StatsDocument11 pagesInferential Statsvisu009No ratings yet
- Type 1 and Ii ErrorDocument8 pagesType 1 and Ii ErrorDina Jean SombrioNo ratings yet
- Performance Task in Statistics and ProbabilityDocument4 pagesPerformance Task in Statistics and ProbabilityF 12-Einstein Fatima V. de CastroNo ratings yet
- Kajian Tentang Perumusan Hipotesis Statistik Dalam Pengujian Hipotesis PenelitianDocument4 pagesKajian Tentang Perumusan Hipotesis Statistik Dalam Pengujian Hipotesis PenelitianMeylan HusinNo ratings yet
- Mid Term Exam - Statistical Analysis: A. I OnlyDocument6 pagesMid Term Exam - Statistical Analysis: A. I OnlyJanine LerumNo ratings yet
- Annexure Granger Causality Test For Sectoral Indices and USD/INR Null Hypothesis F-Statistics ProbabilityDocument31 pagesAnnexure Granger Causality Test For Sectoral Indices and USD/INR Null Hypothesis F-Statistics ProbabilitytouffiqNo ratings yet
- Hypothesis Testing With One SampleDocument68 pagesHypothesis Testing With One SampleDavid EdemNo ratings yet
- Hypothesis TestingDocument66 pagesHypothesis TestingkiranNo ratings yet
- Artikel Septi Nurhayati 0719011921Document14 pagesArtikel Septi Nurhayati 0719011921Serba SerbiNo ratings yet
- Uji Hipotesis Satu Sampel Bu SoDocument18 pagesUji Hipotesis Satu Sampel Bu SoangesthyNo ratings yet
- Tables - Hypothesis Testing FormulaDocument7 pagesTables - Hypothesis Testing FormulaecirecirNo ratings yet
- ANOVADocument18 pagesANOVADiofel Rose FernandezNo ratings yet
- L23 - Hypothesis Testing ExamplesDocument24 pagesL23 - Hypothesis Testing Examplesquang hoaNo ratings yet
- Basic Business Statistics 5Th Edition Mark Test Bank Full Chapter PDFDocument60 pagesBasic Business Statistics 5Th Edition Mark Test Bank Full Chapter PDFbenedictrobertvchkb100% (14)
- MCQ On Unit 6.3 - Attempt ReviewDocument3 pagesMCQ On Unit 6.3 - Attempt ReviewDemo Account 1No ratings yet
- Data T-TestDocument4 pagesData T-TestMUHAMMAD HAFIDZ MUNAWARNo ratings yet
- 14 Interpretation of The Population Proportion SPTC 1702 q4 FPFDocument34 pages14 Interpretation of The Population Proportion SPTC 1702 q4 FPFpersonalizedlife6No ratings yet
- BEale Papers-3-4Document2 pagesBEale Papers-3-4Ladislao BellagambaNo ratings yet
- Assignment Chapter 13 - Nabilah AuliaDocument12 pagesAssignment Chapter 13 - Nabilah AuliaNabilah AuliaNo ratings yet
- Wa0007.Document72 pagesWa0007.Sony SurbaktyNo ratings yet
- Module 4 Excel Utility II: Hypothesis Tests For Two PopulationsDocument5 pagesModule 4 Excel Utility II: Hypothesis Tests For Two PopulationsYash ModiNo ratings yet
- ANOVA, T-Test and Other Statistical Tests With PythonDocument11 pagesANOVA, T-Test and Other Statistical Tests With PythonTeto ScheduleNo ratings yet
- Quiz Lesson 6 Hypothesis Testing (Quantitative Methods)Document24 pagesQuiz Lesson 6 Hypothesis Testing (Quantitative Methods)Hareen JuniorNo ratings yet
- Hypothesis Testing Random MotorsDocument8 pagesHypothesis Testing Random MotorsLinn ArshadNo ratings yet