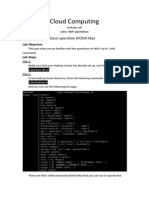
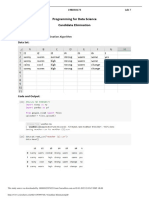
Download as pdf or txt
You might also like
- CS1702 Worksheet 7 - Built in Functions and Methods v1 (2022-2023)Document8 pagesCS1702 Worksheet 7 - Built in Functions and Methods v1 (2022-2023)John MoursyNo ratings yet
- E-Commerce Website: Major Project ReportDocument19 pagesE-Commerce Website: Major Project ReportAkash NegiNo ratings yet
- Cracking Software 0418Document38 pagesCracking Software 0418aaabbb100% (3)
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
- Steps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libDocument4 pagesSteps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libKarthick JothivelNo ratings yet
- Part B Assignment - No - 1Document6 pagesPart B Assignment - No - 1opscoldyNo ratings yet
- Developing A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanDocument22 pagesDeveloping A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanKaushal PrajapatiNo ratings yet
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDocument61 pagesPractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDocument5 pagesWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNo ratings yet
- Step 2 - First MapReduce ProgramDocument25 pagesStep 2 - First MapReduce ProgramSantosh Kumar DesaiNo ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- DSBDA GRP B PrintDocument21 pagesDSBDA GRP B PrinttmhrrsmordeNo ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- 12 CodigoNetbeansDocument5 pages12 CodigoNetbeansMiguel AngelNo ratings yet
- MapReduce Word Count ProgramDocument6 pagesMapReduce Word Count ProgramshaliniiiiNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocument11 pagesTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNo ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- Bda Final 11janDocument7 pagesBda Final 11janG dileep KumarNo ratings yet
- CC Hadoop LabDocument6 pagesCC Hadoop LabClaudia ArdeleanNo ratings yet
- Lab2 WCDocument2 pagesLab2 WCwisesharkwhaleNo ratings yet
- BDM Lab Manual 2Document4 pagesBDM Lab Manual 2Vijay ManoNo ratings yet
- Exp 4 Word CountDocument4 pagesExp 4 Word Countmunish kumar agarwalNo ratings yet
- Execute Java Map Reduce Sample Using EclipseDocument9 pagesExecute Java Map Reduce Sample Using EclipseArjun SNo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- Map Reduce ExampleDocument6 pagesMap Reduce ExampleJajang NurjamanNo ratings yet
- Big Data ManualDocument19 pagesBig Data ManualMadhubala JNo ratings yet
- Activity 2Document31 pagesActivity 2patilbhavesh991209No ratings yet
- LMSDocument34 pagesLMSSurajYT VlogsNo ratings yet
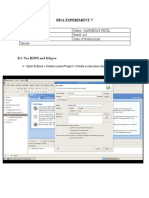
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- Hadoop Administrator Training - Lab Hand BookDocument12 pagesHadoop Administrator Training - Lab Hand BookdebkrcNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- @bigdatalabfile 09Document35 pages@bigdatalabfile 09goatrip2024No ratings yet
- PalakDocument10 pagesPalakDolly MehraNo ratings yet
- Bda LabDocument47 pagesBda LabpawanNo ratings yet
- Practical No 8 (C)Document3 pagesPractical No 8 (C)jenni kokoNo ratings yet
- Tut 3Document4 pagesTut 3Huy Trần QuangNo ratings yet
- BDA4Document7 pagesBDA4nikithakatta0No ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- OOP Lab01 EnvironmentSetup&JavaBasicsDocument17 pagesOOP Lab01 EnvironmentSetup&JavaBasicsViet LeNo ratings yet
- Cloudera Academic Partnership 4 PDFDocument38 pagesCloudera Academic Partnership 4 PDFEL MAMOUN ABDELLAHNo ratings yet
- Experiment No: 1: Create Different Entities DynamicallyDocument43 pagesExperiment No: 1: Create Different Entities Dynamicallyvinay DeshmukhNo ratings yet
- MA JournalDocument35 pagesMA JournalRohit MiryalaNo ratings yet
- Hive User Defined Functions: Step 1: CodeDocument5 pagesHive User Defined Functions: Step 1: Coderitesh_aladdinNo ratings yet
- Mean Stack QuestionsDocument71 pagesMean Stack Questionssuneel sekharNo ratings yet
- Hadoop WordCountDocument2 pagesHadoop WordCountkavya kavNo ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- How To Install Java Onto Your System: Java Platform (JDK) 7 Jdk-7-Windows-I586.exeDocument7 pagesHow To Install Java Onto Your System: Java Platform (JDK) 7 Jdk-7-Windows-I586.exeAjay KumarNo ratings yet
- Apache Ant Tampa JUGDocument17 pagesApache Ant Tampa JUGSabapathy KannappanNo ratings yet
- Big Data Fundamentals and Platforms Assginment 3Document6 pagesBig Data Fundamentals and Platforms Assginment 3sagar srivastavaNo ratings yet
- AJLabEx1to6 Without BorderDocument18 pagesAJLabEx1to6 Without BorderDhyaneshwarNo ratings yet
- Big DataDocument25 pagesBig DataAnu GraphicsNo ratings yet
- Java Native MethodsDocument29 pagesJava Native MethodsGopal Reddy KarriNo ratings yet
- Exp 12Document3 pagesExp 12Jayanth RangaNo ratings yet
- 1-Implementing A Java ProgramDocument13 pages1-Implementing A Java Programpratigya gNo ratings yet
- Big DataDocument23 pagesBig DataYashika SinghNo ratings yet
- Java and Project Delivery: E&CE 250 Winter 2002Document21 pagesJava and Project Delivery: E&CE 250 Winter 2002shiansaNo ratings yet
- ReportDocument69 pagesReportSAMINA ATTARINo ratings yet
- Data Leakage DetectionDocument5 pagesData Leakage DetectionSAMINA ATTARINo ratings yet
- Black BookDocument49 pagesBlack BookSAMINA ATTARINo ratings yet
- Sqoop Implementation RevisedDocument7 pagesSqoop Implementation RevisedSAMINA ATTARINo ratings yet
- 17 19 HMMsDocument23 pages17 19 HMMsSAMINA ATTARINo ratings yet
- Using Sqooptool To Transfer Data Between Hadoop and Mysql: ImplementationDocument4 pagesUsing Sqooptool To Transfer Data Between Hadoop and Mysql: ImplementationSAMINA ATTARINo ratings yet
- CFD Analysis of Single Stage Pulse Tube CryocoolerDocument36 pagesCFD Analysis of Single Stage Pulse Tube CryocoolerSAMINA ATTARINo ratings yet
- Machine Learning Lab ManualDocument43 pagesMachine Learning Lab ManualSAMINA ATTARINo ratings yet
- Hbase Commands: Create ',' 'Document7 pagesHbase Commands: Create ',' 'SAMINA ATTARINo ratings yet
- Practical-02 PCDocument12 pagesPractical-02 PCSAMINA ATTARINo ratings yet
- Digital Image Processing Lab Experiment-1 Aim: Gray-Level Mapping Apparatus UsedDocument21 pagesDigital Image Processing Lab Experiment-1 Aim: Gray-Level Mapping Apparatus UsedSAMINA ATTARINo ratings yet
- Internship Report Performance Analysis of Cryogenic Adsorber SystemDocument47 pagesInternship Report Performance Analysis of Cryogenic Adsorber SystemSAMINA ATTARINo ratings yet
- Stock Market Prediction: Santa Clara UniversityDocument44 pagesStock Market Prediction: Santa Clara UniversitySAMINA ATTARINo ratings yet
- Experiment No. 6 Aim: To Learn Basics of Openmp Api (Open Multi-Processor Api) Theory What Is Openmp?Document6 pagesExperiment No. 6 Aim: To Learn Basics of Openmp Api (Open Multi-Processor Api) Theory What Is Openmp?SAMINA ATTARINo ratings yet
- Mansi Kadam PC Lab Assignment 1Document4 pagesMansi Kadam PC Lab Assignment 1SAMINA ATTARINo ratings yet
- L7 Candidate Elimination PDFDocument5 pagesL7 Candidate Elimination PDFSAMINA ATTARINo ratings yet
- Maker's Square GUIDELINES 2017Document5 pagesMaker's Square GUIDELINES 2017SAMINA ATTARINo ratings yet
- Practical 1P: Parallel Computing Lab Name: Dhruv Shah Roll - No:201080901 Batch: IVDocument3 pagesPractical 1P: Parallel Computing Lab Name: Dhruv Shah Roll - No:201080901 Batch: IVSAMINA ATTARINo ratings yet
- Parallel Computing Lab Manual PDFDocument51 pagesParallel Computing Lab Manual PDFSAMINA ATTARINo ratings yet
- Assignment 4: Rachana Chaudhari 171081014 Ty Btech ItDocument4 pagesAssignment 4: Rachana Chaudhari 171081014 Ty Btech ItSAMINA ATTARINo ratings yet
- Anomaly Detection of Android Malware Using One-Class K-Nearest Neighbours (OC-KNN)Document12 pagesAnomaly Detection of Android Malware Using One-Class K-Nearest Neighbours (OC-KNN)SAMINA ATTARINo ratings yet
- CombinepdfDocument45 pagesCombinepdfSAMINA ATTARINo ratings yet
- Hospital Management System Database Project 1Document1 pageHospital Management System Database Project 1SAMINA ATTARINo ratings yet
- Technical Paper Technical Paper Presentation Presentation: What's at Stake - Rewards and PrizesDocument4 pagesTechnical Paper Technical Paper Presentation Presentation: What's at Stake - Rewards and PrizesSAMINA ATTARINo ratings yet
- Mahendra YadavDocument4 pagesMahendra YadavRaj MandloiNo ratings yet
- Chapter 3 QuestionsDocument6 pagesChapter 3 QuestionsMariam HeikalNo ratings yet
- The OTRS Comparison.: Features. Services. RequirementsDocument18 pagesThe OTRS Comparison.: Features. Services. RequirementsPericoNo ratings yet
- Sharmila Krishnappa ResumeDocument2 pagesSharmila Krishnappa ResumeKaranMPaiNo ratings yet
- Berg 1998Document3 pagesBerg 1998Klaas van den BergNo ratings yet
- Database Programming With PL/SQL 1-1: Practice ActivitiesDocument2 pagesDatabase Programming With PL/SQL 1-1: Practice ActivitiesPop AnaNo ratings yet
- 61bdbf675e77f - Spreadsheet By-Shyam Gopal TimsinaDocument16 pages61bdbf675e77f - Spreadsheet By-Shyam Gopal TimsinaAnuska ThapaNo ratings yet
- SQL Exam 6Document20 pagesSQL Exam 6gk.mobm33No ratings yet
- Use Case ModelingDocument31 pagesUse Case ModelingpacharneajayNo ratings yet
- FPL-I Lab Manual Final (10!6!15)Document71 pagesFPL-I Lab Manual Final (10!6!15)Shubham PatilNo ratings yet
- Sharepoint: Beginner TrainingDocument29 pagesSharepoint: Beginner TrainingYeifry AguasvivasNo ratings yet
- 2 Bca FoxproDocument3 pages2 Bca FoxprowishpondNo ratings yet
- University of Kashmir: Asmat AraDocument4 pagesUniversity of Kashmir: Asmat AraAsmat AraNo ratings yet
- Unit 3. SoftwareDocument2 pagesUnit 3. SoftwareEthan GooberNo ratings yet
- Playing Sounds With AS3: Introduction To Sound Related ClassesDocument6 pagesPlaying Sounds With AS3: Introduction To Sound Related Classesmame MagnawNo ratings yet
- MacrosDocument35 pagesMacrosManoj BojjaNo ratings yet
- CV - Nguyễn Đình QuýDocument1 pageCV - Nguyễn Đình QuýkhanhnamNo ratings yet
- HadoopDocument7 pagesHadoopMayank RaiNo ratings yet
- AtomMotion Manual V1.0Document211 pagesAtomMotion Manual V1.0Adrian Melero100% (1)
- Anisation SystemsDocument17 pagesAnisation SystemsVenkat KrishnaNo ratings yet
- Java Script MeterialDocument164 pagesJava Script Meterialpavan MamidannaNo ratings yet
- Analyzing Microsoft Office DocumentsDocument10 pagesAnalyzing Microsoft Office DocumentsThe Hungry QuokkaNo ratings yet
- How To Configure Listeners in Websphere Using TOCF (EE)Document27 pagesHow To Configure Listeners in Websphere Using TOCF (EE)Nett2kNo ratings yet
- MysticDocument218 pagesMysticMohit GuptaNo ratings yet
- PDF Cocoa Programming For Os X The Big Nerd Ranch Guide 5 E Fifth Edition Online Ausg Chandler Ebook Full ChapterDocument53 pagesPDF Cocoa Programming For Os X The Big Nerd Ranch Guide 5 E Fifth Edition Online Ausg Chandler Ebook Full Chapterdot.beitel948100% (4)
- Sudarshan H L: ObjectiveDocument1 pageSudarshan H L: ObjectivePoovaiahkkNishan100% (1)
- Imperative To Functional Programming SuccinctlyDocument101 pagesImperative To Functional Programming SuccinctlyIacob Razvan100% (1)
- Maghfiroh Izzani Maulani MQTTDocument24 pagesMaghfiroh Izzani Maulani MQTTAndi SeptianaNo ratings yet