
Digital Communication Systems by Simon Haykin-126
Digital Communication Systems by Simon Haykin-126
You might also like
- Iso 13374 1 en PDFDocument8 pagesIso 13374 1 en PDFRodrigo Raziel Bernal ChulinNo ratings yet
- SDH Overhead BytesDocument45 pagesSDH Overhead Bytesandinguyen2004100% (1)
- ELEC1010 Homework 4Document3 pagesELEC1010 Homework 4Yuen Hei Max LeeNo ratings yet
- Digital Logic Design Chapter 4: Combinational Function and Circuits 2 Semester BS ElectronicsDocument48 pagesDigital Logic Design Chapter 4: Combinational Function and Circuits 2 Semester BS Electronicsafzal khanNo ratings yet
- Music Theory Sample Paper 2 Grade 4Document10 pagesMusic Theory Sample Paper 2 Grade 4JESUFOLAFUNMI OMOYANo ratings yet
- Class Ix Number SystemDocument4 pagesClass Ix Number SystemAlok RanjanNo ratings yet
- Digital & MPDocument32 pagesDigital & MPApoorva KaradiNo ratings yet
- Nimble Number Logic Puzzle III QuizDocument1 pageNimble Number Logic Puzzle III QuizpikNo ratings yet
- SEAMO 2017 Paper CDocument7 pagesSEAMO 2017 Paper CCht Geby100% (1)
- Section 1: Section 2Document3 pagesSection 1: Section 2Brian WilliamsNo ratings yet
- Nco Sample Paper Class-9Document2 pagesNco Sample Paper Class-9Kavya BhanushaliNo ratings yet
- Nco Sample Paper Class-9Document2 pagesNco Sample Paper Class-9Jiya YadukulNo ratings yet
- Chap 4Document13 pagesChap 4John SmithNo ratings yet
- Max Marks:50: Computer ScienceDocument8 pagesMax Marks:50: Computer ScienceMP12No ratings yet
- Math5 Q4 Mod17 Week9aDocument15 pagesMath5 Q4 Mod17 Week9aAngelica W. PetinesNo ratings yet
- NodesDocument9 pagesNodesA K AbhayNo ratings yet
- KIE1003 Digital System Tutorial 5Document5 pagesKIE1003 Digital System Tutorial 5brainnytanNo ratings yet
- CEJ - ECE 3rd - Unit No.1 - Decoder & Encoder - DSDDocument32 pagesCEJ - ECE 3rd - Unit No.1 - Decoder & Encoder - DSDsonu sreekumarNo ratings yet
- Pre-Board Papers With MS Computer ScienceDocument85 pagesPre-Board Papers With MS Computer ScienceHema ChaudhryNo ratings yet
- CS PQMSDocument9 pagesCS PQMSBoss of the worldNo ratings yet
- Chapter 3 - FractionsDocument25 pagesChapter 3 - FractionsSITI NURSYIFA BINTI ROZALI MoeNo ratings yet
- January 2012 MS - Paper 2F Edexcel Maths (A) IGCSEDocument12 pagesJanuary 2012 MS - Paper 2F Edexcel Maths (A) IGCSEpanya prachachitNo ratings yet
- Set P3 20Document16 pagesSet P3 20krishna jkanaNo ratings yet
- CS Sample Paper 1Document10 pagesCS Sample Paper 1SpreadSheetsNo ratings yet
- Homework 4 SolDocument3 pagesHomework 4 SolAlison LeeNo ratings yet
- 6689 01 Que 20050118Document19 pages6689 01 Que 20050118charlesmccoyiNo ratings yet
- Complex Number-Advanced Clip - 1Document6 pagesComplex Number-Advanced Clip - 1RayNo ratings yet
- Maximum Marks: 70: (Theory) DATE: 05-12-22 Questions CompulsoryDocument9 pagesMaximum Marks: 70: (Theory) DATE: 05-12-22 Questions CompulsoryArnavNo ratings yet
- Cs Paper-4Document10 pagesCs Paper-4rishabhNo ratings yet
- Amc8 1985Document7 pagesAmc8 1985Mendoza Ramos Rossy RoussNo ratings yet
- ALPS 2329 Maths Assignment PaperDocument10 pagesALPS 2329 Maths Assignment PaperAyushNo ratings yet
- Mu Alpha Theta National Convention: Denver, 2001: Colorado Bowl - Alpha DivisionDocument6 pagesMu Alpha Theta National Convention: Denver, 2001: Colorado Bowl - Alpha DivisionSimon SiregarNo ratings yet
- Application of DerivativesDocument23 pagesApplication of DerivativesAk GamerNo ratings yet
- Csen 2101Document2 pagesCsen 2101Bipin kumarNo ratings yet
- DS Unit IIDocument36 pagesDS Unit IIsriaishwaryaNo ratings yet
- Class 4 Math Mye 2021 PDFDocument10 pagesClass 4 Math Mye 2021 PDFRaheeq LodhiNo ratings yet
- Quiz GR 7B p2Document5 pagesQuiz GR 7B p2Larry MofaNo ratings yet
- Ds 10 Binary TreeDocument21 pagesDs 10 Binary Treeprakashashish25No ratings yet
- Class 12 CS 32 Sets QP Combined PapersDocument295 pagesClass 12 CS 32 Sets QP Combined Paperstpmsomrolc.anirudha9bNo ratings yet
- Section-A (Mathematics) : Previous Years' Solved PapersDocument8 pagesSection-A (Mathematics) : Previous Years' Solved PapersRudra DasNo ratings yet
- RCS087 Data CompressionDocument8 pagesRCS087 Data CompressionTushar BakshiNo ratings yet
- Computer Science 1Document85 pagesComputer Science 1Rehan ThakurNo ratings yet
- Encoder and DecoderDocument30 pagesEncoder and DecoderSuresh KumarNo ratings yet
- LOGIC GATE - DPP-01 - Parakram GATE-2024 Electrical Weekday (English)Document3 pagesLOGIC GATE - DPP-01 - Parakram GATE-2024 Electrical Weekday (English)Virag ParekhNo ratings yet
- Document PDF 358Document12 pagesDocument PDF 358pranaybaderaNo ratings yet
- Arco Master satII Math1c 2c 4th Ed Arco Master Sat Subject Test Math Levels111Document8 pagesArco Master satII Math1c 2c 4th Ed Arco Master Sat Subject Test Math Levels111ibrahim HaggagNo ratings yet
- 2019 JSDocument12 pages2019 JSamit kumarNo ratings yet
- CSEC January 2007 Mathematics P1Document11 pagesCSEC January 2007 Mathematics P1Tamera GreenNo ratings yet
- Computer Science MS Mumbai Cluster - 2Document10 pagesComputer Science MS Mumbai Cluster - 2Ganesh BhandareNo ratings yet
- IOM Sample Paper PDFDocument6 pagesIOM Sample Paper PDFNitin ManojNo ratings yet
- 1 Definate Indafinate Integration Paper 01Document4 pages1 Definate Indafinate Integration Paper 01whizdom sale1No ratings yet
- Assignment IC Binary Trees PDFDocument15 pagesAssignment IC Binary Trees PDFNick SoniNo ratings yet
- Chapter 2 TestDocument2 pagesChapter 2 TestBrian WilliamsNo ratings yet
- CS Sample Paper 2Document8 pagesCS Sample Paper 2SpreadSheetsNo ratings yet
- Quiz 1 DEC IT 2021 BatchDocument2 pagesQuiz 1 DEC IT 2021 BatchMITU BARALNo ratings yet
- Fractions & Decimals Printable Worksheet PDFDocument5 pagesFractions & Decimals Printable Worksheet PDFAkanshaNo ratings yet
- CS - 2002 - by WWW - Learnengineering.inDocument9 pagesCS - 2002 - by WWW - Learnengineering.inPNo ratings yet
- Digital Communication Systems by Simon Haykin-98Document6 pagesDigital Communication Systems by Simon Haykin-98matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-97Document6 pagesDigital Communication Systems by Simon Haykin-97matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-96Document6 pagesDigital Communication Systems by Simon Haykin-96matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-101Document6 pagesDigital Communication Systems by Simon Haykin-101matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-106Document6 pagesDigital Communication Systems by Simon Haykin-106matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-99Document6 pagesDigital Communication Systems by Simon Haykin-99matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-104Document6 pagesDigital Communication Systems by Simon Haykin-104matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-100Document6 pagesDigital Communication Systems by Simon Haykin-100matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-105Document6 pagesDigital Communication Systems by Simon Haykin-105matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-102Document6 pagesDigital Communication Systems by Simon Haykin-102matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-108Document6 pagesDigital Communication Systems by Simon Haykin-108matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-103Document6 pagesDigital Communication Systems by Simon Haykin-103matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-110Document6 pagesDigital Communication Systems by Simon Haykin-110matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-107Document6 pagesDigital Communication Systems by Simon Haykin-107matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-112Document6 pagesDigital Communication Systems by Simon Haykin-112matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-117Document6 pagesDigital Communication Systems by Simon Haykin-117matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-113Document6 pagesDigital Communication Systems by Simon Haykin-113matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-111Document6 pagesDigital Communication Systems by Simon Haykin-111matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-116Document6 pagesDigital Communication Systems by Simon Haykin-116matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-127Document6 pagesDigital Communication Systems by Simon Haykin-127matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-118Document6 pagesDigital Communication Systems by Simon Haykin-118matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-129Document6 pagesDigital Communication Systems by Simon Haykin-129matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-128Document6 pagesDigital Communication Systems by Simon Haykin-128matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-121Document6 pagesDigital Communication Systems by Simon Haykin-121matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-124Document6 pagesDigital Communication Systems by Simon Haykin-124matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-122Document6 pagesDigital Communication Systems by Simon Haykin-122matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-125Document6 pagesDigital Communication Systems by Simon Haykin-125matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-130Document6 pagesDigital Communication Systems by Simon Haykin-130matildaNo ratings yet
- OpenNMS Provisioning User GuideDocument34 pagesOpenNMS Provisioning User GuideEmbagraf TINo ratings yet
- 21MCI1126 - Nikhil - Raj 2.1Document11 pages21MCI1126 - Nikhil - Raj 2.1nikhilsinghraj11No ratings yet
- 6AV66440AA012AX0 Datasheet enDocument6 pages6AV66440AA012AX0 Datasheet enJoseph MagonduNo ratings yet
- Channel Partner Event Guide: Live Days June 21-23 Platform Open Until July 2Document32 pagesChannel Partner Event Guide: Live Days June 21-23 Platform Open Until July 2Diepreye BinaebiNo ratings yet
- Bachelor of Science in Computer Engineering (Effective SY: 2014 - 2015)Document6 pagesBachelor of Science in Computer Engineering (Effective SY: 2014 - 2015)Kenneth FloresNo ratings yet
- Azure Stack Operator Azs 2301Document1,506 pagesAzure Stack Operator Azs 2301Pt BuddhakirdNo ratings yet
- Turing Machine Documentation-V2-1Document9 pagesTuring Machine Documentation-V2-1informagicNo ratings yet
- Data StructureDocument3 pagesData Structureranaashutosh698No ratings yet
- Suraj Srivastav ResumeDocument1 pageSuraj Srivastav ResumeDaminiNo ratings yet
- Educational ComputingDocument17 pagesEducational ComputingJorgie Mae CruzNo ratings yet
- SCI Job Application - CleanerDocument3 pagesSCI Job Application - CleanerShujauddin SultaniNo ratings yet
- Servicenow System Administration Questions: Correct Answer Is Maintain ItemsDocument18 pagesServicenow System Administration Questions: Correct Answer Is Maintain Itemsprachi kadamNo ratings yet
- 521 A Mutiple Ring Buffer PDFDocument7 pages521 A Mutiple Ring Buffer PDFRahmanNo ratings yet
- 128860-JD Edwards EnterpriseOne Hotkeys ReferenceDocument3 pages128860-JD Edwards EnterpriseOne Hotkeys ReferenceHUNG555No ratings yet
- English: TEACHER: Fabiola Patiño ArreolaDocument4 pagesEnglish: TEACHER: Fabiola Patiño ArreolaMonica DuranNo ratings yet
- SafariViewService - 11 Apr 2019 10.48Document1 pageSafariViewService - 11 Apr 2019 10.48Annisa Dwi MRNo ratings yet
- Difference Between Data Science and Machine LearningDocument5 pagesDifference Between Data Science and Machine LearningrishuraijaishreeramNo ratings yet
- Object Oriented Programming Assignment 4Document5 pagesObject Oriented Programming Assignment 4faria emanNo ratings yet
- MIS MCQsDocument10 pagesMIS MCQsSalman ShaikhNo ratings yet
- Schmatics Dell 7548 7547 Quanta AM6 MB - DA0AM6MB8E0 REV E PDFDocument58 pagesSchmatics Dell 7548 7547 Quanta AM6 MB - DA0AM6MB8E0 REV E PDFacsacrNo ratings yet
- Uber Business 2021Document29 pagesUber Business 2021Cheung Yi SHNo ratings yet
- Sun ZipDocument18 pagesSun ZipKunal BishtNo ratings yet
- Oracle® Hyperion Strategic Finance: ReadmeDocument10 pagesOracle® Hyperion Strategic Finance: ReadmemanliomarxNo ratings yet
- VPDSF Ch1 AppA Sample Questions and Example Information Assets V1.1Document4 pagesVPDSF Ch1 AppA Sample Questions and Example Information Assets V1.1fawas hamdiNo ratings yet
- Material Kanban KEPC enDocument121 pagesMaterial Kanban KEPC enCharlineNo ratings yet
- F23 CST8804-IntroDocument22 pagesF23 CST8804-IntroReham BakounyNo ratings yet
- Logcat OutputDocument231 pagesLogcat OutputMirza Golam Abbas ShahneelNo ratings yet
- U3851A: RF Microwave Circuit Design, Simulation and Measurement Courseware, 5G NR n3Document2 pagesU3851A: RF Microwave Circuit Design, Simulation and Measurement Courseware, 5G NR n3p.mallikarjunaNo ratings yet
- Ericsson Rbs Fault RectificationDocument52 pagesEricsson Rbs Fault RectificationVineet Singh100% (5)
















































































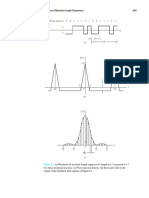



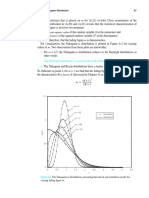































Download as pdf or txt
You might also like
- Iso 13374 1 en PDFDocument8 pagesIso 13374 1 en PDFRodrigo Raziel Bernal ChulinNo ratings yet
- SDH Overhead BytesDocument45 pagesSDH Overhead Bytesandinguyen2004100% (1)
- ELEC1010 Homework 4Document3 pagesELEC1010 Homework 4Yuen Hei Max LeeNo ratings yet
- Digital Logic Design Chapter 4: Combinational Function and Circuits 2 Semester BS ElectronicsDocument48 pagesDigital Logic Design Chapter 4: Combinational Function and Circuits 2 Semester BS Electronicsafzal khanNo ratings yet
- Music Theory Sample Paper 2 Grade 4Document10 pagesMusic Theory Sample Paper 2 Grade 4JESUFOLAFUNMI OMOYANo ratings yet
- Class Ix Number SystemDocument4 pagesClass Ix Number SystemAlok RanjanNo ratings yet
- Digital & MPDocument32 pagesDigital & MPApoorva KaradiNo ratings yet
- Nimble Number Logic Puzzle III QuizDocument1 pageNimble Number Logic Puzzle III QuizpikNo ratings yet
- SEAMO 2017 Paper CDocument7 pagesSEAMO 2017 Paper CCht Geby100% (1)
- Section 1: Section 2Document3 pagesSection 1: Section 2Brian WilliamsNo ratings yet
- Nco Sample Paper Class-9Document2 pagesNco Sample Paper Class-9Kavya BhanushaliNo ratings yet
- Nco Sample Paper Class-9Document2 pagesNco Sample Paper Class-9Jiya YadukulNo ratings yet
- Chap 4Document13 pagesChap 4John SmithNo ratings yet
- Max Marks:50: Computer ScienceDocument8 pagesMax Marks:50: Computer ScienceMP12No ratings yet
- Math5 Q4 Mod17 Week9aDocument15 pagesMath5 Q4 Mod17 Week9aAngelica W. PetinesNo ratings yet
- NodesDocument9 pagesNodesA K AbhayNo ratings yet
- KIE1003 Digital System Tutorial 5Document5 pagesKIE1003 Digital System Tutorial 5brainnytanNo ratings yet
- CEJ - ECE 3rd - Unit No.1 - Decoder & Encoder - DSDDocument32 pagesCEJ - ECE 3rd - Unit No.1 - Decoder & Encoder - DSDsonu sreekumarNo ratings yet
- Pre-Board Papers With MS Computer ScienceDocument85 pagesPre-Board Papers With MS Computer ScienceHema ChaudhryNo ratings yet
- CS PQMSDocument9 pagesCS PQMSBoss of the worldNo ratings yet
- Chapter 3 - FractionsDocument25 pagesChapter 3 - FractionsSITI NURSYIFA BINTI ROZALI MoeNo ratings yet
- January 2012 MS - Paper 2F Edexcel Maths (A) IGCSEDocument12 pagesJanuary 2012 MS - Paper 2F Edexcel Maths (A) IGCSEpanya prachachitNo ratings yet
- Set P3 20Document16 pagesSet P3 20krishna jkanaNo ratings yet
- CS Sample Paper 1Document10 pagesCS Sample Paper 1SpreadSheetsNo ratings yet
- Homework 4 SolDocument3 pagesHomework 4 SolAlison LeeNo ratings yet
- 6689 01 Que 20050118Document19 pages6689 01 Que 20050118charlesmccoyiNo ratings yet
- Complex Number-Advanced Clip - 1Document6 pagesComplex Number-Advanced Clip - 1RayNo ratings yet
- Maximum Marks: 70: (Theory) DATE: 05-12-22 Questions CompulsoryDocument9 pagesMaximum Marks: 70: (Theory) DATE: 05-12-22 Questions CompulsoryArnavNo ratings yet
- Cs Paper-4Document10 pagesCs Paper-4rishabhNo ratings yet
- Amc8 1985Document7 pagesAmc8 1985Mendoza Ramos Rossy RoussNo ratings yet
- ALPS 2329 Maths Assignment PaperDocument10 pagesALPS 2329 Maths Assignment PaperAyushNo ratings yet
- Mu Alpha Theta National Convention: Denver, 2001: Colorado Bowl - Alpha DivisionDocument6 pagesMu Alpha Theta National Convention: Denver, 2001: Colorado Bowl - Alpha DivisionSimon SiregarNo ratings yet
- Application of DerivativesDocument23 pagesApplication of DerivativesAk GamerNo ratings yet
- Csen 2101Document2 pagesCsen 2101Bipin kumarNo ratings yet
- DS Unit IIDocument36 pagesDS Unit IIsriaishwaryaNo ratings yet
- Class 4 Math Mye 2021 PDFDocument10 pagesClass 4 Math Mye 2021 PDFRaheeq LodhiNo ratings yet
- Quiz GR 7B p2Document5 pagesQuiz GR 7B p2Larry MofaNo ratings yet
- Ds 10 Binary TreeDocument21 pagesDs 10 Binary Treeprakashashish25No ratings yet
- Class 12 CS 32 Sets QP Combined PapersDocument295 pagesClass 12 CS 32 Sets QP Combined Paperstpmsomrolc.anirudha9bNo ratings yet
- Section-A (Mathematics) : Previous Years' Solved PapersDocument8 pagesSection-A (Mathematics) : Previous Years' Solved PapersRudra DasNo ratings yet
- RCS087 Data CompressionDocument8 pagesRCS087 Data CompressionTushar BakshiNo ratings yet
- Computer Science 1Document85 pagesComputer Science 1Rehan ThakurNo ratings yet
- Encoder and DecoderDocument30 pagesEncoder and DecoderSuresh KumarNo ratings yet
- LOGIC GATE - DPP-01 - Parakram GATE-2024 Electrical Weekday (English)Document3 pagesLOGIC GATE - DPP-01 - Parakram GATE-2024 Electrical Weekday (English)Virag ParekhNo ratings yet
- Document PDF 358Document12 pagesDocument PDF 358pranaybaderaNo ratings yet
- Arco Master satII Math1c 2c 4th Ed Arco Master Sat Subject Test Math Levels111Document8 pagesArco Master satII Math1c 2c 4th Ed Arco Master Sat Subject Test Math Levels111ibrahim HaggagNo ratings yet
- 2019 JSDocument12 pages2019 JSamit kumarNo ratings yet
- CSEC January 2007 Mathematics P1Document11 pagesCSEC January 2007 Mathematics P1Tamera GreenNo ratings yet
- Computer Science MS Mumbai Cluster - 2Document10 pagesComputer Science MS Mumbai Cluster - 2Ganesh BhandareNo ratings yet
- IOM Sample Paper PDFDocument6 pagesIOM Sample Paper PDFNitin ManojNo ratings yet
- 1 Definate Indafinate Integration Paper 01Document4 pages1 Definate Indafinate Integration Paper 01whizdom sale1No ratings yet
- Assignment IC Binary Trees PDFDocument15 pagesAssignment IC Binary Trees PDFNick SoniNo ratings yet
- Chapter 2 TestDocument2 pagesChapter 2 TestBrian WilliamsNo ratings yet
- CS Sample Paper 2Document8 pagesCS Sample Paper 2SpreadSheetsNo ratings yet
- Quiz 1 DEC IT 2021 BatchDocument2 pagesQuiz 1 DEC IT 2021 BatchMITU BARALNo ratings yet
- Fractions & Decimals Printable Worksheet PDFDocument5 pagesFractions & Decimals Printable Worksheet PDFAkanshaNo ratings yet
- CS - 2002 - by WWW - Learnengineering.inDocument9 pagesCS - 2002 - by WWW - Learnengineering.inPNo ratings yet
- Digital Communication Systems by Simon Haykin-98Document6 pagesDigital Communication Systems by Simon Haykin-98matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-97Document6 pagesDigital Communication Systems by Simon Haykin-97matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-96Document6 pagesDigital Communication Systems by Simon Haykin-96matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-101Document6 pagesDigital Communication Systems by Simon Haykin-101matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-106Document6 pagesDigital Communication Systems by Simon Haykin-106matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-99Document6 pagesDigital Communication Systems by Simon Haykin-99matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-104Document6 pagesDigital Communication Systems by Simon Haykin-104matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-100Document6 pagesDigital Communication Systems by Simon Haykin-100matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-105Document6 pagesDigital Communication Systems by Simon Haykin-105matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-102Document6 pagesDigital Communication Systems by Simon Haykin-102matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-108Document6 pagesDigital Communication Systems by Simon Haykin-108matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-103Document6 pagesDigital Communication Systems by Simon Haykin-103matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-110Document6 pagesDigital Communication Systems by Simon Haykin-110matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-107Document6 pagesDigital Communication Systems by Simon Haykin-107matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-112Document6 pagesDigital Communication Systems by Simon Haykin-112matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-117Document6 pagesDigital Communication Systems by Simon Haykin-117matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-113Document6 pagesDigital Communication Systems by Simon Haykin-113matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-111Document6 pagesDigital Communication Systems by Simon Haykin-111matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-116Document6 pagesDigital Communication Systems by Simon Haykin-116matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-127Document6 pagesDigital Communication Systems by Simon Haykin-127matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-118Document6 pagesDigital Communication Systems by Simon Haykin-118matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-129Document6 pagesDigital Communication Systems by Simon Haykin-129matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-128Document6 pagesDigital Communication Systems by Simon Haykin-128matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-121Document6 pagesDigital Communication Systems by Simon Haykin-121matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-124Document6 pagesDigital Communication Systems by Simon Haykin-124matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-122Document6 pagesDigital Communication Systems by Simon Haykin-122matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-125Document6 pagesDigital Communication Systems by Simon Haykin-125matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-130Document6 pagesDigital Communication Systems by Simon Haykin-130matildaNo ratings yet
- OpenNMS Provisioning User GuideDocument34 pagesOpenNMS Provisioning User GuideEmbagraf TINo ratings yet
- 21MCI1126 - Nikhil - Raj 2.1Document11 pages21MCI1126 - Nikhil - Raj 2.1nikhilsinghraj11No ratings yet
- 6AV66440AA012AX0 Datasheet enDocument6 pages6AV66440AA012AX0 Datasheet enJoseph MagonduNo ratings yet
- Channel Partner Event Guide: Live Days June 21-23 Platform Open Until July 2Document32 pagesChannel Partner Event Guide: Live Days June 21-23 Platform Open Until July 2Diepreye BinaebiNo ratings yet
- Bachelor of Science in Computer Engineering (Effective SY: 2014 - 2015)Document6 pagesBachelor of Science in Computer Engineering (Effective SY: 2014 - 2015)Kenneth FloresNo ratings yet
- Azure Stack Operator Azs 2301Document1,506 pagesAzure Stack Operator Azs 2301Pt BuddhakirdNo ratings yet
- Turing Machine Documentation-V2-1Document9 pagesTuring Machine Documentation-V2-1informagicNo ratings yet
- Data StructureDocument3 pagesData Structureranaashutosh698No ratings yet
- Suraj Srivastav ResumeDocument1 pageSuraj Srivastav ResumeDaminiNo ratings yet
- Educational ComputingDocument17 pagesEducational ComputingJorgie Mae CruzNo ratings yet
- SCI Job Application - CleanerDocument3 pagesSCI Job Application - CleanerShujauddin SultaniNo ratings yet
- Servicenow System Administration Questions: Correct Answer Is Maintain ItemsDocument18 pagesServicenow System Administration Questions: Correct Answer Is Maintain Itemsprachi kadamNo ratings yet
- 521 A Mutiple Ring Buffer PDFDocument7 pages521 A Mutiple Ring Buffer PDFRahmanNo ratings yet
- 128860-JD Edwards EnterpriseOne Hotkeys ReferenceDocument3 pages128860-JD Edwards EnterpriseOne Hotkeys ReferenceHUNG555No ratings yet
- English: TEACHER: Fabiola Patiño ArreolaDocument4 pagesEnglish: TEACHER: Fabiola Patiño ArreolaMonica DuranNo ratings yet
- SafariViewService - 11 Apr 2019 10.48Document1 pageSafariViewService - 11 Apr 2019 10.48Annisa Dwi MRNo ratings yet
- Difference Between Data Science and Machine LearningDocument5 pagesDifference Between Data Science and Machine LearningrishuraijaishreeramNo ratings yet
- Object Oriented Programming Assignment 4Document5 pagesObject Oriented Programming Assignment 4faria emanNo ratings yet
- MIS MCQsDocument10 pagesMIS MCQsSalman ShaikhNo ratings yet
- Schmatics Dell 7548 7547 Quanta AM6 MB - DA0AM6MB8E0 REV E PDFDocument58 pagesSchmatics Dell 7548 7547 Quanta AM6 MB - DA0AM6MB8E0 REV E PDFacsacrNo ratings yet
- Uber Business 2021Document29 pagesUber Business 2021Cheung Yi SHNo ratings yet
- Sun ZipDocument18 pagesSun ZipKunal BishtNo ratings yet
- Oracle® Hyperion Strategic Finance: ReadmeDocument10 pagesOracle® Hyperion Strategic Finance: ReadmemanliomarxNo ratings yet
- VPDSF Ch1 AppA Sample Questions and Example Information Assets V1.1Document4 pagesVPDSF Ch1 AppA Sample Questions and Example Information Assets V1.1fawas hamdiNo ratings yet
- Material Kanban KEPC enDocument121 pagesMaterial Kanban KEPC enCharlineNo ratings yet
- F23 CST8804-IntroDocument22 pagesF23 CST8804-IntroReham BakounyNo ratings yet
- Logcat OutputDocument231 pagesLogcat OutputMirza Golam Abbas ShahneelNo ratings yet
- U3851A: RF Microwave Circuit Design, Simulation and Measurement Courseware, 5G NR n3Document2 pagesU3851A: RF Microwave Circuit Design, Simulation and Measurement Courseware, 5G NR n3p.mallikarjunaNo ratings yet
- Ericsson Rbs Fault RectificationDocument52 pagesEricsson Rbs Fault RectificationVineet Singh100% (5)