Download as pdf or txt
You might also like
- K Means Cluster Analysis in SPSSDocument2 pagesK Means Cluster Analysis in SPSSsureshexecutive0% (1)
- Assignment5 Drw2 BDocument5 pagesAssignment5 Drw2 BdwongaNo ratings yet
- Ece306L 2 Syllabus s2018Document2 pagesEce306L 2 Syllabus s2018John Paul DulayNo ratings yet
- NN PDFDocument48 pagesNN PDFOscarNo ratings yet
- Face Recognition Using Complete Fuzzy LDADocument4 pagesFace Recognition Using Complete Fuzzy LDALeopoldo MauroNo ratings yet
- Fast Training of Multilayer PerceptronsDocument15 pagesFast Training of Multilayer Perceptronsgarima_rathiNo ratings yet
- Function Approximation Using Robust Wavelet Neural Networks: Sheng-Tun Li and Shu-Ching ChenDocument6 pagesFunction Approximation Using Robust Wavelet Neural Networks: Sheng-Tun Li and Shu-Ching ChenErezwaNo ratings yet
- RBFN Xor ProblemDocument16 pagesRBFN Xor ProblemCory SparksNo ratings yet
- Training Neural Networks With GA Hybrid AlgorithmsDocument12 pagesTraining Neural Networks With GA Hybrid Algorithmsjkl316No ratings yet
- Convolutional Neural Network TutorialDocument8 pagesConvolutional Neural Network TutorialGiri PrakashNo ratings yet
- Language Processing and ComputationalDocument10 pagesLanguage Processing and ComputationalCarolyn HardyNo ratings yet
- Radial Basis Function Networks: Applications: Introduction To Neural Networks: Lecture 14Document14 pagesRadial Basis Function Networks: Applications: Introduction To Neural Networks: Lecture 14scribdkhatnNo ratings yet
- 3.1.1weight Decay, Weight Elimination, and Unit Elimination: GX X X X, Which Is Plotted inDocument26 pages3.1.1weight Decay, Weight Elimination, and Unit Elimination: GX X X X, Which Is Plotted inStefanescu AlexandruNo ratings yet
- NCC 2016 7561206Document6 pagesNCC 2016 7561206Gautham SgNo ratings yet
- NYCU Introduction to Machine Learning,Homework 2 109550164 徐聖哲Document5 pagesNYCU Introduction to Machine Learning,Homework 2 109550164 徐聖哲吳守元No ratings yet
- Breaking The Curse of Dimensionality With Convex Neural NetworksDocument53 pagesBreaking The Curse of Dimensionality With Convex Neural NetworksJonny BidonNo ratings yet
- Sapp Automated Reconstruction of Ancient Languages PDFDocument30 pagesSapp Automated Reconstruction of Ancient Languages PDFANo ratings yet
- Applied Neural Networks For Predicting Approximate Structural Response Behavior Using Learning and Design ExperienceDocument15 pagesApplied Neural Networks For Predicting Approximate Structural Response Behavior Using Learning and Design ExperienceRamprasad SrinivasanNo ratings yet
- A Systolic Array Exploiting The Parallelisms of Artificial Neural Inherent NetworksDocument15 pagesA Systolic Array Exploiting The Parallelisms of Artificial Neural Inherent NetworksctorreshhNo ratings yet
- Lecture Five Radial-Basis Function Networks: Associate ProfessorDocument64 pagesLecture Five Radial-Basis Function Networks: Associate ProfessorWantong LiaoNo ratings yet
- Richi's Neural Nets SummaryDocument114 pagesRichi's Neural Nets Summaryanton dolganovNo ratings yet
- Neural Networks Regularization With Graph-Based Local ResamplingDocument11 pagesNeural Networks Regularization With Graph-Based Local ResamplingGabrielWalersonNo ratings yet
- Ann Work SheetDocument11 pagesAnn Work SheetTariku TesfayeNo ratings yet
- NN in CommDocument5 pagesNN in CommKashish NagpalNo ratings yet
- Khosravi2012 Article ANovelStructureForRadialBasisFDocument10 pagesKhosravi2012 Article ANovelStructureForRadialBasisFMaxNo ratings yet
- Networks With Threshold Activation Functions: NavigationDocument6 pagesNetworks With Threshold Activation Functions: NavigationsandmancloseNo ratings yet
- Deep Feedforward Networks Application To Patter RecognitionDocument5 pagesDeep Feedforward Networks Application To Patter RecognitionluizotaviocfgNo ratings yet
- Klqgceb Ewvhja SCDocument8 pagesKlqgceb Ewvhja SCAbhishek PaloNo ratings yet
- A Fuzzy Back Propagation AlgorithmDocument13 pagesA Fuzzy Back Propagation AlgorithmTung DangNo ratings yet
- An ANFIS Based Fuzzy Synthesis Judgment For Transformer Fault DiagnosisDocument10 pagesAn ANFIS Based Fuzzy Synthesis Judgment For Transformer Fault DiagnosisDanh Bui CongNo ratings yet
- Ensembling Neural Networks: Many Could Be Better Than All: Zhi-Hua Zhou, Jianxin Wu, Wei TangDocument23 pagesEnsembling Neural Networks: Many Could Be Better Than All: Zhi-Hua Zhou, Jianxin Wu, Wei TangSmiley JayNo ratings yet
- ANN PG Module1Document75 pagesANN PG Module1Sreerag Kunnathu SugathanNo ratings yet
- Fast Curvature Matrix-Vector Products For Second-Order Gradient DescentDocument16 pagesFast Curvature Matrix-Vector Products For Second-Order Gradient DescentKitanovic NenadNo ratings yet
- Applied Mathematics and Mechanics (English Edition)Document12 pagesApplied Mathematics and Mechanics (English Edition)airxNo ratings yet
- Pattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkDocument5 pagesPattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkEkin RafiaiNo ratings yet
- Fundamentals of Artificial Neural NetworksDocument27 pagesFundamentals of Artificial Neural Networksbhaskar rao mNo ratings yet
- An Immunological Approach To Initialize Centers of Radial Basis Function Neural NetworksDocument6 pagesAn Immunological Approach To Initialize Centers of Radial Basis Function Neural NetworksTéoTavaresNo ratings yet
- Fast Inference in Sparse Coding Algorithms With Applications To Object RecognitionDocument9 pagesFast Inference in Sparse Coding Algorithms With Applications To Object RecognitionMassimo TormenNo ratings yet
- Image Deblurring and Super-Resolution by Adaptive Sparse Domain Selection and Adaptive RegularizationDocument35 pagesImage Deblurring and Super-Resolution by Adaptive Sparse Domain Selection and Adaptive RegularizationSiddhesh PawarNo ratings yet
- Research Article: Deep Convolutional Extreme Learning Machine and Its Application in Handwritten Digit ClassificationDocument11 pagesResearch Article: Deep Convolutional Extreme Learning Machine and Its Application in Handwritten Digit ClassificationsyarahNo ratings yet
- ML Unit-2Document141 pagesML Unit-26644 HaripriyaNo ratings yet
- Radial Basis Function Networks: Algorithms: Neural Computation: Lecture 14Document18 pagesRadial Basis Function Networks: Algorithms: Neural Computation: Lecture 14Bobby JasujaNo ratings yet
- An Alternative Approach For Generation of Membership Functions and Fuzzy Rules Based On Radial and Cubic Basis Function NetworksDocument20 pagesAn Alternative Approach For Generation of Membership Functions and Fuzzy Rules Based On Radial and Cubic Basis Function NetworksAntonio Madueño LunaNo ratings yet
- Learning in Multi-Layer Perceptrons - Back-Propagation: Neural Computation: Lecture 7Document20 pagesLearning in Multi-Layer Perceptrons - Back-Propagation: Neural Computation: Lecture 7HakanKalaycıNo ratings yet
- IBM SPSS Modeler-Neural NetworksDocument18 pagesIBM SPSS Modeler-Neural NetworksJennifer Parker100% (1)
- Beyond Weights Adaptation: A New Neuron Model With Trainable Activation Function and Its Supervised LearningDocument6 pagesBeyond Weights Adaptation: A New Neuron Model With Trainable Activation Function and Its Supervised LearningJogo da VelhaNo ratings yet
- Feature Selection For Nonlinear Kernel Support Vector MachinesDocument6 pagesFeature Selection For Nonlinear Kernel Support Vector MachinesSelly Anastassia Amellia KharisNo ratings yet
- Evolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image ClassificationDocument13 pagesEvolving Neural Network Using Real Coded Genetic Algorithm (GA) For Multispectral Image Classificationjkl316No ratings yet
- Nhan Dang Khuon Mat Bi NghiengDocument6 pagesNhan Dang Khuon Mat Bi NghiengDao_Van_HiepNo ratings yet
- Machine Learning and Pattern Recognition Week 8 Neural Net ArchitecturesDocument3 pagesMachine Learning and Pattern Recognition Week 8 Neural Net ArchitectureszeliawillscumbergNo ratings yet
- Deep Online Sequential Extreme Learning Machines and Its Application in Pneumonia DetectionDocument6 pagesDeep Online Sequential Extreme Learning Machines and Its Application in Pneumonia DetectionRahul ShettyNo ratings yet
- Unit - II MLDocument9 pagesUnit - II MLraviNo ratings yet
- Extreme Learning Machines - A Review and State of The Art PDFDocument15 pagesExtreme Learning Machines - A Review and State of The Art PDFpatoototsNo ratings yet
- Learning Rules For Multilayer Feedforward Neural NetworksDocument19 pagesLearning Rules For Multilayer Feedforward Neural NetworksStefanescu AlexandruNo ratings yet
- ML Mid2 AnsDocument24 pagesML Mid2 Ansrayudu shivaNo ratings yet
- Convex MTFLDocument39 pagesConvex MTFLReshma KhemchandaniNo ratings yet
- Paper 2Document3 pagesPaper 2RakeshconclaveNo ratings yet
- 2012 - Analysis of The Influence of Forestry Environments On The Accuracy of GPS Measurements by Means of Recurrent Neural NetworksDocument8 pages2012 - Analysis of The Influence of Forestry Environments On The Accuracy of GPS Measurements by Means of Recurrent Neural NetworksSilverio G. CortesNo ratings yet
- Multilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksFrom EverandMultilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksNo ratings yet
- Competitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionFrom EverandCompetitive Learning: Fundamentals and Applications for Reinforcement Learning through CompetitionNo ratings yet
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Multiple Input Multiple Output Orthogonal Frequency Division Multiplexing (MIMO-OFDM)Document13 pagesMultiple Input Multiple Output Orthogonal Frequency Division Multiplexing (MIMO-OFDM)Anonymous bcDacMNo ratings yet
- Modified Pts With Fecs For Papr Reduction in Mimo-Ofdm System With Different SubcarriersDocument6 pagesModified Pts With Fecs For Papr Reduction in Mimo-Ofdm System With Different SubcarriersAnonymous bcDacMNo ratings yet
- Modified Pts With Fecs For Papr Reduction in Mimo-Ofdm System With Different SubcarriersDocument11 pagesModified Pts With Fecs For Papr Reduction in Mimo-Ofdm System With Different SubcarriersAnonymous bcDacMNo ratings yet
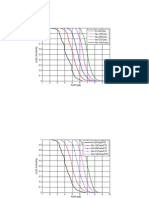
- 1 N1 64turbo N2 128turbo N3 256turbo N4 512turbo N5 1024turboDocument8 pages1 N1 64turbo N2 128turbo N3 256turbo N4 512turbo N5 1024turboAnonymous bcDacMNo ratings yet
- 1 N1 64turbo N2 128turbo N3 256turbo N4 512turbo N5 1024turboDocument8 pages1 N1 64turbo N2 128turbo N3 256turbo N4 512turbo N5 1024turboAnonymous bcDacMNo ratings yet
- PAPR (DB) : BPSK 4x4 QPSK 4x4 8QAM 4x4 16QAM 4x4 32QAM 4x4 64QAM 4x4Document10 pagesPAPR (DB) : BPSK 4x4 QPSK 4x4 8QAM 4x4 16QAM 4x4 32QAM 4x4 64QAM 4x4Anonymous bcDacMNo ratings yet
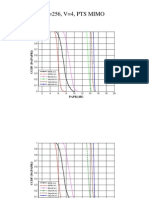
- Modptsmimo 2 X 2Document3 pagesModptsmimo 2 X 2Anonymous bcDacMNo ratings yet
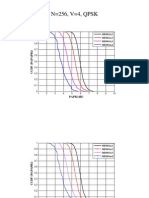
- N 256, V 4, QPSK: PAPR (DB)Document26 pagesN 256, V 4, QPSK: PAPR (DB)Anonymous bcDacMNo ratings yet
- Updated ML LAB Manual-2020-21Document57 pagesUpdated ML LAB Manual-2020-21SnehaNo ratings yet
- Regression Problems in Python PDFDocument34 pagesRegression Problems in Python PDFmathewNo ratings yet
- Dynamics and Control of Robotic Systems CH06 1Document1 pageDynamics and Control of Robotic Systems CH06 1Samo apkNo ratings yet
- NeelimaDocument3 pagesNeelimaDiv DudejaNo ratings yet
- Data StructureDocument9 pagesData StructureRiddhimaa GuptaNo ratings yet
- Digital - Logic Spring10 Quiz3Document4 pagesDigital - Logic Spring10 Quiz3Maria JoseNo ratings yet
- Sotero 07 Task Performance 1 InventoryDocument19 pagesSotero 07 Task Performance 1 Inventorybernadette soteroNo ratings yet
- Spam Detection ThesisDocument6 pagesSpam Detection Thesiszyxnlmikd100% (2)
- 10.6 Shortest-Path ProblemsDocument3 pages10.6 Shortest-Path ProblemsFilipus KevinNo ratings yet
- 1AI.04b - Introduction To Machine Learning - Supervised Learning - DT PDFDocument65 pages1AI.04b - Introduction To Machine Learning - Supervised Learning - DT PDFhải trần thị thúyNo ratings yet
- Calculate Your Risk of RuinDocument3 pagesCalculate Your Risk of Ruinsourabh6chakrabort-1No ratings yet
- Simple Brownian DiffusionDocument5 pagesSimple Brownian DiffusionIgnasi AlemanyNo ratings yet
- The Mathematics of Pagerank: Fan Chung University of California, San DiegoDocument84 pagesThe Mathematics of Pagerank: Fan Chung University of California, San DiegoRahulAgarwalNo ratings yet
- Programming Assignment-4Document4 pagesProgramming Assignment-4Abhishek ChaudharyNo ratings yet
- Lecture 5: Big-M Method and Two-Phase Method: Lecturer: Lily PANDocument9 pagesLecture 5: Big-M Method and Two-Phase Method: Lecturer: Lily PANLauraNo ratings yet
- Emotion Detection of Autistic Children Using Support Vector Machine: A ReviewDocument4 pagesEmotion Detection of Autistic Children Using Support Vector Machine: A ReviewInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Survery of Nearest NeighborDocument4 pagesSurvery of Nearest NeighborGanesh ChandrasekaranNo ratings yet
- Operations Research: Linear Programming ProblemsDocument28 pagesOperations Research: Linear Programming ProblemsyashvantNo ratings yet
- FIN 202 1st Assignment (Rawan Joudeh)Document2 pagesFIN 202 1st Assignment (Rawan Joudeh)rawan joudehNo ratings yet
- Distance Vector: Step by StepDocument12 pagesDistance Vector: Step by StepMd Saidur Rahman KohinoorNo ratings yet
- Sample Question Paper Class: Xii Session: 2021-22 Mathematics (Code-041) Term - 1Document8 pagesSample Question Paper Class: Xii Session: 2021-22 Mathematics (Code-041) Term - 1MasterzimoNo ratings yet
- Array-ADT: Slides Taken From Various Resources From InternetDocument14 pagesArray-ADT: Slides Taken From Various Resources From Internetkaushik.grNo ratings yet
- Pengaruh Citra Merek, Promosi, Kualitas Pelayan Dan Store Atmosphere Terhadap Kepuasan KonsumenDocument19 pagesPengaruh Citra Merek, Promosi, Kualitas Pelayan Dan Store Atmosphere Terhadap Kepuasan KonsumenMayada Dwi Rejeki PermatasariNo ratings yet
- Machine Learning in Wireless Sensor Networks: Algorithms, Strategies, and ApplicationsDocument23 pagesMachine Learning in Wireless Sensor Networks: Algorithms, Strategies, and Applicationsnoaman lachqarNo ratings yet
- Introduction To Pattern Recognition: Selim AksoyDocument40 pagesIntroduction To Pattern Recognition: Selim AksoyalcuperNo ratings yet
- Self-Driving Car Using Convolution Neural Network and Road Lane DetectionDocument4 pagesSelf-Driving Car Using Convolution Neural Network and Road Lane Detectionsudarsan.ghosh.webNo ratings yet
- IdkDocument2 pagesIdkAvery Poole0% (1)