Download as pdf or txt
You might also like
- Yang 2013Document9 pagesYang 2013Tanneru Hemanth KumarNo ratings yet
- Hijra Lives Exploring Their Lived Realities and Identity-Thesis by MrinaliniDocument102 pagesHijra Lives Exploring Their Lived Realities and Identity-Thesis by MrinaliniMrinalini RayNo ratings yet
- Dynamical Pool-Size Optimization For The Sars-Cov-2 PCR TestDocument7 pagesDynamical Pool-Size Optimization For The Sars-Cov-2 PCR Testanastasia buzaNo ratings yet
- Estimating False-Negative Detection Rate of Sars-Cov-2 by RT-PCRDocument14 pagesEstimating False-Negative Detection Rate of Sars-Cov-2 by RT-PCRsuper_facaNo ratings yet
- Advice - RAG - Interpretation PCRDocument5 pagesAdvice - RAG - Interpretation PCRHitesh MutrejaNo ratings yet
- Estimating The Sample Size For A Pilot Randomised Trial To Minimise The Overall Trial Sample Size For The External Pilot and Main Trial For A Continuous Outcome VariableDocument17 pagesEstimating The Sample Size For A Pilot Randomised Trial To Minimise The Overall Trial Sample Size For The External Pilot and Main Trial For A Continuous Outcome VariableMade SuryaNo ratings yet
- Hypothesis Tests For The Difference Between Two Population Proportions Using StataDocument6 pagesHypothesis Tests For The Difference Between Two Population Proportions Using StataAnhNo ratings yet
- CDC 99995 DS1Document12 pagesCDC 99995 DS1Tung NguyenNo ratings yet
- FormulaDocument27 pagesFormulaSadia KausarNo ratings yet
- Evaluation of Semi-Quantitative Scoring of Gram STDocument5 pagesEvaluation of Semi-Quantitative Scoring of Gram STNurul Kamilah SadliNo ratings yet
- PCT Paper Published in Clin Chem Lab Med 2014Document5 pagesPCT Paper Published in Clin Chem Lab Med 2014neofherNo ratings yet
- Assessment of Specimen Pooling To Conserve SARS - Really GoodDocument4 pagesAssessment of Specimen Pooling To Conserve SARS - Really Goodm.ihsan anggiNo ratings yet
- Detecting Sars-Cov-2 at Point of Care: Preliminary Data Comparing Loop-Mediated Isothermal Amplification (Lamp) To Polymerase Chain Reaction (PCR)Document8 pagesDetecting Sars-Cov-2 at Point of Care: Preliminary Data Comparing Loop-Mediated Isothermal Amplification (Lamp) To Polymerase Chain Reaction (PCR)Prita Amira Windy AsmaraNo ratings yet
- Diagnostic Testing Strategies To Manage COVID-19 Pandemic: Position PaperDocument4 pagesDiagnostic Testing Strategies To Manage COVID-19 Pandemic: Position PaperMia FernandezNo ratings yet
- VaccinateDocument5 pagesVaccinateahmadkhafidhidayatNo ratings yet
- CC 2Document12 pagesCC 2PojangNo ratings yet
- Statistical Aids To Hypothesis TestingDocument20 pagesStatistical Aids To Hypothesis TestingNikki EbilloNo ratings yet
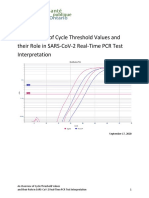
- An Overview of Cycle Threshold Values and Their Role in Sars-Cov-2 Real-Time PCR Test InterpretationDocument14 pagesAn Overview of Cycle Threshold Values and Their Role in Sars-Cov-2 Real-Time PCR Test InterpretationNabil Ziad KuddahNo ratings yet
- EM Alert Limits PDA - FullDocument9 pagesEM Alert Limits PDA - FullgombasgNo ratings yet
- Sample Size Determination in Health StudDocument88 pagesSample Size Determination in Health StudLely KarolinaNo ratings yet
- IKM - Sample Size Calculation in Epid Study PDFDocument7 pagesIKM - Sample Size Calculation in Epid Study PDFcindyNo ratings yet
- Chemometrics Lecture NoteDocument162 pagesChemometrics Lecture NoteBikila BelayNo ratings yet
- Sample Size DeterminationDocument66 pagesSample Size DeterminationAbrham BelayNo ratings yet
- Am. J. Epidemiol. 1997 Schaubel 450 8Document9 pagesAm. J. Epidemiol. 1997 Schaubel 450 8Madhu EvuriNo ratings yet
- Chi-Square Test - Judy AnnDocument33 pagesChi-Square Test - Judy AnnSharon AnchetaNo ratings yet
- MBT5g7fpQcGU YO36YHBEg - Summative Quiz Time To Event SolutionsDocument7 pagesMBT5g7fpQcGU YO36YHBEg - Summative Quiz Time To Event Solutionsmia widiastutiNo ratings yet
- Replacement Study On The Potency Test of Anti-Rabies Immunoglobulin in ChinaDocument7 pagesReplacement Study On The Potency Test of Anti-Rabies Immunoglobulin in ChinaGhanta Ranjith KumarNo ratings yet
- Statistical Techniques For The Biomedical Sciences: Lecture 12: Case-Control Studies and Cox Proportional HazardsDocument5 pagesStatistical Techniques For The Biomedical Sciences: Lecture 12: Case-Control Studies and Cox Proportional HazardsWaqas NadeemNo ratings yet
- Understanding Antigen Tests and Results ENG FinalDocument4 pagesUnderstanding Antigen Tests and Results ENG FinalAna CatarinaNo ratings yet
- M2 Formulation of Optimal Conditions For An Immunonephelometric AssayDocument8 pagesM2 Formulation of Optimal Conditions For An Immunonephelometric AssayELISANo ratings yet
- Comparison of Bayesian and Frequentist Methods For Prevalence Estimation Under MisclassificationDocument10 pagesComparison of Bayesian and Frequentist Methods For Prevalence Estimation Under MisclassificationAbhishek GuptaNo ratings yet
- Jurnal 2Document9 pagesJurnal 2terenadyaputriNo ratings yet
- Biostatics Freework - Ahlin AshrafDocument16 pagesBiostatics Freework - Ahlin Ashrafab JafarNo ratings yet
- Sample Size DeterminationDocument21 pagesSample Size DeterminationMichelle Kozmik JirakNo ratings yet
- PCR-based Diagnostics For Infectious Diseases: Uses, Limitations, and Future Applications in Acute-Care SettingsDocument12 pagesPCR-based Diagnostics For Infectious Diseases: Uses, Limitations, and Future Applications in Acute-Care SettingsLuciana SaundersNo ratings yet
- Meta-Analysis of Diagnostic Procedures For Pneumocystis Carinii Pneumonia in HIV-1-infected PatientsDocument8 pagesMeta-Analysis of Diagnostic Procedures For Pneumocystis Carinii Pneumonia in HIV-1-infected PatientsJenniffer M. Rodiño MontoyaNo ratings yet
- Samplesize - Ug 2021Document22 pagesSamplesize - Ug 2021Young QaysamNo ratings yet
- Cultivos Semicuantitativos NavDocument5 pagesCultivos Semicuantitativos NavMiguel SalvaNo ratings yet
- Journal Pre-Proof: Clinical Microbiology and InfectionDocument24 pagesJournal Pre-Proof: Clinical Microbiology and InfectionFrancisco BettencourtNo ratings yet
- A List A Statistical Definition For The CICM Fellowship ExamDocument5 pagesA List A Statistical Definition For The CICM Fellowship ExamSimon WongNo ratings yet
- 0.04 Glossary OieDocument8 pages0.04 Glossary OieAchmad NugrohoNo ratings yet
- ProjectreportDocument31 pagesProjectreportapi-515961562No ratings yet
- Review Related LiteratureDocument4 pagesReview Related LiteratureDRANo ratings yet
- Lecture 4 IMB 516Document26 pagesLecture 4 IMB 516Maipelo Opena MlanduNo ratings yet
- Mathematical Analysis of A Mouse Experiment Suggests Little Role For Resource Depletion in Controlling Influenza Infection Within HostDocument16 pagesMathematical Analysis of A Mouse Experiment Suggests Little Role For Resource Depletion in Controlling Influenza Infection Within HostPooya AavaniNo ratings yet
- Iddt 226ap2Document8 pagesIddt 226ap2pooja pandeyNo ratings yet
- Fluorescence Polarization Assay (FP) TestDocument23 pagesFluorescence Polarization Assay (FP) Testrifky waskitoNo ratings yet
- Comparison of Alternative Measurement MeDocument13 pagesComparison of Alternative Measurement Meelvis.ortizNo ratings yet
- Donald Uncertainty QMRADocument17 pagesDonald Uncertainty QMRAThefirefoxNo ratings yet
- Image JDocument5 pagesImage JIvie João GabrielNo ratings yet
- Molecularapproachesand Biomarkersfordetectionof MycobacteriumtuberculosisDocument14 pagesMolecularapproachesand Biomarkersfordetectionof MycobacteriumtuberculosischiralicNo ratings yet
- Commentary A Double Robust Approach To Causal Effects in Case-Control StudiesDocument7 pagesCommentary A Double Robust Approach To Causal Effects in Case-Control StudiesBerliana Via AnggeliNo ratings yet
- Assay For Measurement of Multilaboratory Evaluation of A ViabilityDocument7 pagesAssay For Measurement of Multilaboratory Evaluation of A ViabilityJenny TaylorNo ratings yet
- Mitigating The Hook Effect in Lateral Flow SandwichDocument12 pagesMitigating The Hook Effect in Lateral Flow SandwichJoana BarbosaNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OOK ViewNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OMakmur SejatiNo ratings yet
- T-Tests, Non-Parametric Tests, and Large Studies-A Paradox of Statistical Practice?Document7 pagesT-Tests, Non-Parametric Tests, and Large Studies-A Paradox of Statistical Practice?lacisagNo ratings yet
- Chapter 5 - Step 2 N Estimation and N Assessment of - 2012 - Practical BiostatDocument11 pagesChapter 5 - Step 2 N Estimation and N Assessment of - 2012 - Practical BiostattyanafmNo ratings yet
- Sample Size Estimation in Prevalence StudiesDocument7 pagesSample Size Estimation in Prevalence StudiesRajiv KabadNo ratings yet
- Histopathology Reporting: Guidelines for Surgical CancerFrom EverandHistopathology Reporting: Guidelines for Surgical CancerDavid P. BoyleNo ratings yet
- Rapid On-site Evaluation (ROSE): A Practical GuideFrom EverandRapid On-site Evaluation (ROSE): A Practical GuideGuoping CaiNo ratings yet
- A Report On Job SatisfactionDocument22 pagesA Report On Job SatisfactionDevKumar MahatoNo ratings yet
- Work Life Balance - Project ReportDocument68 pagesWork Life Balance - Project ReportRaj Kumar100% (2)
- Assessment of Budgetary PerformanceDocument44 pagesAssessment of Budgetary Performancepadm100% (1)
- Powergrid PresentationDocument24 pagesPowergrid PresentationAshokNo ratings yet
- Sourav Marketing (1) - 1Document61 pagesSourav Marketing (1) - 1vaibhavdudhal8492No ratings yet
- Kajaria Tiles Internship ProjectDocument65 pagesKajaria Tiles Internship ProjectKanchan33% (3)
- Introduction To The Study: Shivaji University, KolhapurDocument63 pagesIntroduction To The Study: Shivaji University, KolhapurAshokupadhye1955No ratings yet
- Assessment of Knowledge, Attitude and Practice of Segregation and Disposal of Solid Waste at Household Level in A Suburban Area of ChennaiDocument3 pagesAssessment of Knowledge, Attitude and Practice of Segregation and Disposal of Solid Waste at Household Level in A Suburban Area of ChennaiInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Peer Pressure and Its Impact To Personality Development (Chapter 1-5)Document51 pagesPeer Pressure and Its Impact To Personality Development (Chapter 1-5)Jaze RamosNo ratings yet
- Project On ": A Study On Consumer Satisfaction and Marketing Effectiveness of Red Bull Energy DrinkDocument35 pagesProject On ": A Study On Consumer Satisfaction and Marketing Effectiveness of Red Bull Energy DrinkSahil TalrejaNo ratings yet
- Excercise 4Document6 pagesExcercise 4Li Lie100% (1)
- Simple Random SamplingDocument10 pagesSimple Random SamplingNafees A. SiddiqueNo ratings yet
- Methodology For GHG and Co-Benefits in Grazing Systems: Regen Network Development, IncDocument42 pagesMethodology For GHG and Co-Benefits in Grazing Systems: Regen Network Development, IncCarlos Diaz AcostaNo ratings yet
- Consumer Preference of Tvs MotorcycleDocument82 pagesConsumer Preference of Tvs MotorcycleSUKUMAR97% (30)
- Wollo University College of Social Science and Humanity Department of SociologyDocument46 pagesWollo University College of Social Science and Humanity Department of SociologyHanfere MohammedNo ratings yet
- AQLDocument4 pagesAQLAnonymous wA6NGuyklDNo ratings yet
- WrongDocument10 pagesWrongparesarebNo ratings yet
- BSBAMM 2.1 Group 4Document47 pagesBSBAMM 2.1 Group 4sachi u0% (1)
- Untitled 2Document61 pagesUntitled 2MaimboNo ratings yet
- Qualitative Research Method - PhenomenologyDocument14 pagesQualitative Research Method - PhenomenologyjixNo ratings yet
- G7 Math Q4 Module-1Document22 pagesG7 Math Q4 Module-1charmainebontolNo ratings yet
- Auditing and Assurance Services A Systematic Approach 11th Edition Messier Test BankDocument24 pagesAuditing and Assurance Services A Systematic Approach 11th Edition Messier Test Banklacewingdespise6pva100% (31)
- E-Commerce (A Study of FLIPKART and AMAZON)Document43 pagesE-Commerce (A Study of FLIPKART and AMAZON)Md Imtiaz KhanNo ratings yet
- Journal of Mass Spectrometry and Advances in The Clinical LabDocument10 pagesJournal of Mass Spectrometry and Advances in The Clinical LabLenuinsaNo ratings yet
- Students Motivation in Doing ExcellenceDocument42 pagesStudents Motivation in Doing ExcellenceLORENA AMATIAGANo ratings yet
- Impact of New Media On School Going ChildrenDocument30 pagesImpact of New Media On School Going ChildrenShantanu guptaNo ratings yet
- Internship ReportDocument54 pagesInternship ReportMizanur RahamanNo ratings yet
- Community Diagnosis Sample PDFDocument2 pagesCommunity Diagnosis Sample PDFLisaNo ratings yet
- STA301 Quiz-1 by Vu Topper RMDocument76 pagesSTA301 Quiz-1 by Vu Topper RMAmna ArshadNo ratings yet