
Data Science Project VI - Ipynb - Colaboratory
Data Science Project VI - Ipynb - Colaboratory
You might also like
- How To Download Ebook PDF Modern Database Management 13Th Edition by Jeff Hoffer Ebook PDF Docx Kindle Full ChapterDocument36 pagesHow To Download Ebook PDF Modern Database Management 13Th Edition by Jeff Hoffer Ebook PDF Docx Kindle Full Chaptersteve.books604100% (27)
- FINAL VERSION Capstone Mock3 Defense Rating Sheet and GuidelinesDocument6 pagesFINAL VERSION Capstone Mock3 Defense Rating Sheet and GuidelinescylNo ratings yet
- Oracle R12 CE Cash Management New FeaturesDocument22 pagesOracle R12 CE Cash Management New Featuressanjayapps86% (7)
- Computer Lab Management SystemDocument384 pagesComputer Lab Management SystemRishab Mehta70% (10)
- Mall Customer Data Analysis PDFDocument10 pagesMall Customer Data Analysis PDFAyush SharmaNo ratings yet
- Actividad Semana 4 - Jupyter NotebookDocument7 pagesActividad Semana 4 - Jupyter NotebookM. Eugenia Barrios100% (1)
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Train Test SplitDocument4 pagesTrain Test Splitjaymehta1444No ratings yet
- Logistic - Ipynb - ColaboratoryDocument6 pagesLogistic - Ipynb - ColaboratoryAkansha UniyalNo ratings yet
- MLT Exp 09Document3 pagesMLT Exp 09Sec ArcNo ratings yet
- Bitcoin Price Prediction 5 - ColaboratoryDocument5 pagesBitcoin Price Prediction 5 - ColaboratorySisay ADNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- KomiiiiDocument4 pagesKomiiiirinansyahafifarrozakNo ratings yet
- Assignment 3 CustomerDocument3 pagesAssignment 3 CustomerAkshata ChopadeNo ratings yet
- His To GramaDocument10 pagesHis To Gramaalexy molina martinezNo ratings yet
- Sales Prediction Using PythonDocument6 pagesSales Prediction Using PythonSourabh YadavNo ratings yet
- Ids Final SolDocument16 pagesIds Final SolHumayun RazaNo ratings yet
- Facility Design-FinalTerm 2021-2022 2smsDocument6 pagesFacility Design-FinalTerm 2021-2022 2smsREYNALDINo ratings yet
- LogisticDocument5 pagesLogisticavnimote121No ratings yet
- Clustering Algorithms SciKit Learn 1705740354Document22 pagesClustering Algorithms SciKit Learn 1705740354Prasad YarraNo ratings yet
- Probability QuizDocument5 pagesProbability QuizMarco RNo ratings yet
- Practical 1Document10 pagesPractical 122it109No ratings yet
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Final Practical File 2022-23Document87 pagesFinal Practical File 2022-23Kuldeep SinghNo ratings yet
- ITA 04 - Day3 - AnalyticalQues&AnsDocument4 pagesITA 04 - Day3 - AnalyticalQues&AnsMohanapriya KuppanNo ratings yet
- Data Science Practical Book - IpynbDocument21 pagesData Science Practical Book - IpynbTejas TadkaNo ratings yet
- and DATA HOW TO PREPARE FOR COMPUTER SCIENCE Board Exam 2020Document76 pagesand DATA HOW TO PREPARE FOR COMPUTER SCIENCE Board Exam 2020Uttiya SangiriNo ratings yet
- Dsbda 4Document4 pagesDsbda 4Arbaz ShaikhNo ratings yet
- The Option To Expand: Black-Scholes Option Pricing FormulaDocument29 pagesThe Option To Expand: Black-Scholes Option Pricing FormulaSyed Ameer Ali ShahNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- Travelling Salesperson Problem Using Hill Climbing SearchDocument6 pagesTravelling Salesperson Problem Using Hill Climbing SearchVignesh MNo ratings yet
- C13,14 TestDocument5 pagesC13,14 TestPremNo ratings yet
- C13,14 TEST AnswersDocument5 pagesC13,14 TEST AnswersPremNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- 附錄C:函數或方法索引表Document17 pages附錄C:函數或方法索引表林则No ratings yet
- Group Work Assignment Supervised and Unsupervised LearningDocument10 pagesGroup Work Assignment Supervised and Unsupervised LearningDaren WalaceNo ratings yet
- Panda MergedDocument19 pagesPanda Mergedprashanttarbundiya2No ratings yet
- Mnist CNN - Ipynb ColaboratoryDocument5 pagesMnist CNN - Ipynb ColaboratorySai Raj LgtvNo ratings yet
- Assignment5 VidulGargDocument12 pagesAssignment5 VidulGargvidulgarg1524No ratings yet
- Guia de Ejercicios Operaciones Básicas Con Números RacionalesDocument3 pagesGuia de Ejercicios Operaciones Básicas Con Números RacionalesAnonymous XVHziDNo ratings yet
- ..... Estadistica UniminutoDocument4 pages..... Estadistica UniminutoTania JimenezNo ratings yet
- BTVN1 - ColaboratoryDocument4 pagesBTVN1 - ColaboratoryTam Nguyen ThiNo ratings yet
- Matplotlib (1 6)Document12 pagesMatplotlib (1 6)pranjalsingh0808No ratings yet
- Uji Wilcoxon: V Nilai Rangking 18,5 Dan P-Value 0,358Document7 pagesUji Wilcoxon: V Nilai Rangking 18,5 Dan P-Value 0,358Angelaretha KurniawanNo ratings yet
- MAT490 Mathematics WEEK 3Document5 pagesMAT490 Mathematics WEEK 3pro mansaNo ratings yet
- 23MCA1030 - Ensemble - Classifiers - .Ipynb - ColaboratoryDocument11 pages23MCA1030 - Ensemble - Classifiers - .Ipynb - Colaboratoryvinayaksingh.fakeNo ratings yet
- Tipstrik - Id Organic - Positions Id 20221125 2022 11 26T14 - 55 - 49ZDocument2 pagesTipstrik - Id Organic - Positions Id 20221125 2022 11 26T14 - 55 - 49ZNingrum DwiNo ratings yet
- Tarea 4Document6 pagesTarea 4Jonathan JiménezNo ratings yet
- Import As Import As Import As Import As From Import From Import From Import From Import From Import From ImportDocument1 pageImport As Import As Import As Import As From Import From Import From Import From Import From Import From ImportYathreb SamaaliNo ratings yet
- File HandlingDocument13 pagesFile HandlingSandijNo ratings yet
- Dsbda 3Document12 pagesDsbda 3Arbaz ShaikhNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- Descriptive StatDocument2 pagesDescriptive Stataaskhat55No ratings yet
- Pregunta 11 Global SupplyDocument5 pagesPregunta 11 Global SupplyAlexa Victoria FloresNo ratings yet
- Exploratory Data Analysis66Document17 pagesExploratory Data Analysis66Rishi SahuNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- ADS 3.ipynb - ColaboratoryDocument5 pagesADS 3.ipynb - ColaboratoryMahesh BadgujarNo ratings yet
- C19 Test Year 8Document5 pagesC19 Test Year 8PremNo ratings yet
- Container Optimization Model: Define Site Information Define Input Data Generate Model Run SimulationDocument37 pagesContainer Optimization Model: Define Site Information Define Input Data Generate Model Run SimulationNoé Salvador O RuizNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Review Exponents and Scientific NotationDocument4 pagesReview Exponents and Scientific NotationNayem Hossain HemuNo ratings yet
- Modulo 02 - 09: September 28, 2018Document3 pagesModulo 02 - 09: September 28, 2018smithvieiraNo ratings yet
- Advertising Data AnalysisDocument12 pagesAdvertising Data AnalysisVishal SharmaNo ratings yet
- Microsoft Visual Basic Interview Questions: Microsoft VB Certification ReviewFrom EverandMicrosoft Visual Basic Interview Questions: Microsoft VB Certification ReviewNo ratings yet
- How Technology Has Changed The Way We CommunicateDocument1 pageHow Technology Has Changed The Way We CommunicateStefany Margarita Meza MeriñoNo ratings yet
- Amity School of Engineering & Technology: B. Tech. (MAE), V Semester Rdbms Sunil VyasDocument13 pagesAmity School of Engineering & Technology: B. Tech. (MAE), V Semester Rdbms Sunil VyasJose AntonyNo ratings yet
- Dokumentasi SQL Store Procedure MasterDataDocument7 pagesDokumentasi SQL Store Procedure MasterDataayaNo ratings yet
- The Introduction To Private Cloud Using Oracle Exadata and Oracle Database (Okcan Yasin Saygili (Author) )Document123 pagesThe Introduction To Private Cloud Using Oracle Exadata and Oracle Database (Okcan Yasin Saygili (Author) )mghomriNo ratings yet
- OADJS FindingsDocument203 pagesOADJS FindingsMautse Tung MywebsNo ratings yet
- E-Hospital Assignment: Valyandra P (20121030036)Document2 pagesE-Hospital Assignment: Valyandra P (20121030036)hanumzniiNo ratings yet
- Tugas SAD KelompokDocument14 pagesTugas SAD KelompokNaurah Atika DinaNo ratings yet
- Lab Assignment - 3 D.Sai Anirudh 17MIS7072: Grant and Revoke System and Object PrivilegesDocument17 pagesLab Assignment - 3 D.Sai Anirudh 17MIS7072: Grant and Revoke System and Object PrivilegesSai Anirudh DuggineniNo ratings yet
- ICT 122 Questions Bank-1Document60 pagesICT 122 Questions Bank-1areyNo ratings yet
- Zeek Case StudyDocument4 pagesZeek Case StudysuryanshNo ratings yet
- Oracle Rdbms KeypointsDocument1,439 pagesOracle Rdbms Keypointsdeepak1133100% (2)
- Database Fundamentals KeysDocument7 pagesDatabase Fundamentals KeysDave Reyes-TanNo ratings yet
- Access 2007 TutorialDocument45 pagesAccess 2007 TutorialPochetnikNo ratings yet
- E Bw4hana 13.sample - QuestionsDocument5 pagesE Bw4hana 13.sample - QuestionsPrateik NimbalkarNo ratings yet
- Big Data Analytics White PaperDocument38 pagesBig Data Analytics White PaperDaniela StaciNo ratings yet
- Patterns-Based Real-Time Data Warehouse Architecture: Djillali Nora Mohammed Mahieddine Oukid SalyhaDocument5 pagesPatterns-Based Real-Time Data Warehouse Architecture: Djillali Nora Mohammed Mahieddine Oukid SalyhaAminaHodžićNo ratings yet
- Cheat Sheet Seo For Wordpress v2 PDFDocument2 pagesCheat Sheet Seo For Wordpress v2 PDFPreetamSChaudhary0% (1)
- Declaration: I, Don Mathew, Do Hereby Declare That The Project Titled PRE-OWNED VEHICLEDocument99 pagesDeclaration: I, Don Mathew, Do Hereby Declare That The Project Titled PRE-OWNED VEHICLELetson ThomasNo ratings yet
- Two Basic Categories of Computer Memory:: Primary Storage and Secondary StorageDocument7 pagesTwo Basic Categories of Computer Memory:: Primary Storage and Secondary StorageRahul ShrivasNo ratings yet
- DWH MaterialDocument115 pagesDWH Materialkraveendrareddy05No ratings yet
- Chapter 1 Systems, Science, and StudyDocument21 pagesChapter 1 Systems, Science, and Studywahyu eka yurinaNo ratings yet
- Flacăra de Fier de Rebecca Yarros ScanDocument453 pagesFlacăra de Fier de Rebecca Yarros ScanMihaela DenisiaNo ratings yet
- Systems Proposal On Inventory ManagementDocument16 pagesSystems Proposal On Inventory ManagementSiegfred Laborte0% (2)
- Title Making Real-World Evidence RealDocument8 pagesTitle Making Real-World Evidence RealdajcNo ratings yet
- db2 Part Clust 115Document362 pagesdb2 Part Clust 115TrurlScribdNo ratings yet
- Github Com Aman0046 LastMinuteRevision DBMSDocument8 pagesGithub Com Aman0046 LastMinuteRevision DBMSGEN GENTLE INFAMOUSNo ratings yet














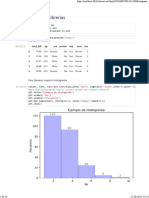


























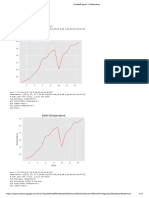















































Download as pdf or txt
You might also like
- How To Download Ebook PDF Modern Database Management 13Th Edition by Jeff Hoffer Ebook PDF Docx Kindle Full ChapterDocument36 pagesHow To Download Ebook PDF Modern Database Management 13Th Edition by Jeff Hoffer Ebook PDF Docx Kindle Full Chaptersteve.books604100% (27)
- FINAL VERSION Capstone Mock3 Defense Rating Sheet and GuidelinesDocument6 pagesFINAL VERSION Capstone Mock3 Defense Rating Sheet and GuidelinescylNo ratings yet
- Oracle R12 CE Cash Management New FeaturesDocument22 pagesOracle R12 CE Cash Management New Featuressanjayapps86% (7)
- Computer Lab Management SystemDocument384 pagesComputer Lab Management SystemRishab Mehta70% (10)
- Mall Customer Data Analysis PDFDocument10 pagesMall Customer Data Analysis PDFAyush SharmaNo ratings yet
- Actividad Semana 4 - Jupyter NotebookDocument7 pagesActividad Semana 4 - Jupyter NotebookM. Eugenia Barrios100% (1)
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Train Test SplitDocument4 pagesTrain Test Splitjaymehta1444No ratings yet
- Logistic - Ipynb - ColaboratoryDocument6 pagesLogistic - Ipynb - ColaboratoryAkansha UniyalNo ratings yet
- MLT Exp 09Document3 pagesMLT Exp 09Sec ArcNo ratings yet
- Bitcoin Price Prediction 5 - ColaboratoryDocument5 pagesBitcoin Price Prediction 5 - ColaboratorySisay ADNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- KomiiiiDocument4 pagesKomiiiirinansyahafifarrozakNo ratings yet
- Assignment 3 CustomerDocument3 pagesAssignment 3 CustomerAkshata ChopadeNo ratings yet
- His To GramaDocument10 pagesHis To Gramaalexy molina martinezNo ratings yet
- Sales Prediction Using PythonDocument6 pagesSales Prediction Using PythonSourabh YadavNo ratings yet
- Ids Final SolDocument16 pagesIds Final SolHumayun RazaNo ratings yet
- Facility Design-FinalTerm 2021-2022 2smsDocument6 pagesFacility Design-FinalTerm 2021-2022 2smsREYNALDINo ratings yet
- LogisticDocument5 pagesLogisticavnimote121No ratings yet
- Clustering Algorithms SciKit Learn 1705740354Document22 pagesClustering Algorithms SciKit Learn 1705740354Prasad YarraNo ratings yet
- Probability QuizDocument5 pagesProbability QuizMarco RNo ratings yet
- Practical 1Document10 pagesPractical 122it109No ratings yet
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Final Practical File 2022-23Document87 pagesFinal Practical File 2022-23Kuldeep SinghNo ratings yet
- ITA 04 - Day3 - AnalyticalQues&AnsDocument4 pagesITA 04 - Day3 - AnalyticalQues&AnsMohanapriya KuppanNo ratings yet
- Data Science Practical Book - IpynbDocument21 pagesData Science Practical Book - IpynbTejas TadkaNo ratings yet
- and DATA HOW TO PREPARE FOR COMPUTER SCIENCE Board Exam 2020Document76 pagesand DATA HOW TO PREPARE FOR COMPUTER SCIENCE Board Exam 2020Uttiya SangiriNo ratings yet
- Dsbda 4Document4 pagesDsbda 4Arbaz ShaikhNo ratings yet
- The Option To Expand: Black-Scholes Option Pricing FormulaDocument29 pagesThe Option To Expand: Black-Scholes Option Pricing FormulaSyed Ameer Ali ShahNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- Travelling Salesperson Problem Using Hill Climbing SearchDocument6 pagesTravelling Salesperson Problem Using Hill Climbing SearchVignesh MNo ratings yet
- C13,14 TestDocument5 pagesC13,14 TestPremNo ratings yet
- C13,14 TEST AnswersDocument5 pagesC13,14 TEST AnswersPremNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- 附錄C:函數或方法索引表Document17 pages附錄C:函數或方法索引表林则No ratings yet
- Group Work Assignment Supervised and Unsupervised LearningDocument10 pagesGroup Work Assignment Supervised and Unsupervised LearningDaren WalaceNo ratings yet
- Panda MergedDocument19 pagesPanda Mergedprashanttarbundiya2No ratings yet
- Mnist CNN - Ipynb ColaboratoryDocument5 pagesMnist CNN - Ipynb ColaboratorySai Raj LgtvNo ratings yet
- Assignment5 VidulGargDocument12 pagesAssignment5 VidulGargvidulgarg1524No ratings yet
- Guia de Ejercicios Operaciones Básicas Con Números RacionalesDocument3 pagesGuia de Ejercicios Operaciones Básicas Con Números RacionalesAnonymous XVHziDNo ratings yet
- ..... Estadistica UniminutoDocument4 pages..... Estadistica UniminutoTania JimenezNo ratings yet
- BTVN1 - ColaboratoryDocument4 pagesBTVN1 - ColaboratoryTam Nguyen ThiNo ratings yet
- Matplotlib (1 6)Document12 pagesMatplotlib (1 6)pranjalsingh0808No ratings yet
- Uji Wilcoxon: V Nilai Rangking 18,5 Dan P-Value 0,358Document7 pagesUji Wilcoxon: V Nilai Rangking 18,5 Dan P-Value 0,358Angelaretha KurniawanNo ratings yet
- MAT490 Mathematics WEEK 3Document5 pagesMAT490 Mathematics WEEK 3pro mansaNo ratings yet
- 23MCA1030 - Ensemble - Classifiers - .Ipynb - ColaboratoryDocument11 pages23MCA1030 - Ensemble - Classifiers - .Ipynb - Colaboratoryvinayaksingh.fakeNo ratings yet
- Tipstrik - Id Organic - Positions Id 20221125 2022 11 26T14 - 55 - 49ZDocument2 pagesTipstrik - Id Organic - Positions Id 20221125 2022 11 26T14 - 55 - 49ZNingrum DwiNo ratings yet
- Tarea 4Document6 pagesTarea 4Jonathan JiménezNo ratings yet
- Import As Import As Import As Import As From Import From Import From Import From Import From Import From ImportDocument1 pageImport As Import As Import As Import As From Import From Import From Import From Import From Import From ImportYathreb SamaaliNo ratings yet
- File HandlingDocument13 pagesFile HandlingSandijNo ratings yet
- Dsbda 3Document12 pagesDsbda 3Arbaz ShaikhNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- Descriptive StatDocument2 pagesDescriptive Stataaskhat55No ratings yet
- Pregunta 11 Global SupplyDocument5 pagesPregunta 11 Global SupplyAlexa Victoria FloresNo ratings yet
- Exploratory Data Analysis66Document17 pagesExploratory Data Analysis66Rishi SahuNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- ADS 3.ipynb - ColaboratoryDocument5 pagesADS 3.ipynb - ColaboratoryMahesh BadgujarNo ratings yet
- C19 Test Year 8Document5 pagesC19 Test Year 8PremNo ratings yet
- Container Optimization Model: Define Site Information Define Input Data Generate Model Run SimulationDocument37 pagesContainer Optimization Model: Define Site Information Define Input Data Generate Model Run SimulationNoé Salvador O RuizNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Review Exponents and Scientific NotationDocument4 pagesReview Exponents and Scientific NotationNayem Hossain HemuNo ratings yet
- Modulo 02 - 09: September 28, 2018Document3 pagesModulo 02 - 09: September 28, 2018smithvieiraNo ratings yet
- Advertising Data AnalysisDocument12 pagesAdvertising Data AnalysisVishal SharmaNo ratings yet
- Microsoft Visual Basic Interview Questions: Microsoft VB Certification ReviewFrom EverandMicrosoft Visual Basic Interview Questions: Microsoft VB Certification ReviewNo ratings yet
- How Technology Has Changed The Way We CommunicateDocument1 pageHow Technology Has Changed The Way We CommunicateStefany Margarita Meza MeriñoNo ratings yet
- Amity School of Engineering & Technology: B. Tech. (MAE), V Semester Rdbms Sunil VyasDocument13 pagesAmity School of Engineering & Technology: B. Tech. (MAE), V Semester Rdbms Sunil VyasJose AntonyNo ratings yet
- Dokumentasi SQL Store Procedure MasterDataDocument7 pagesDokumentasi SQL Store Procedure MasterDataayaNo ratings yet
- The Introduction To Private Cloud Using Oracle Exadata and Oracle Database (Okcan Yasin Saygili (Author) )Document123 pagesThe Introduction To Private Cloud Using Oracle Exadata and Oracle Database (Okcan Yasin Saygili (Author) )mghomriNo ratings yet
- OADJS FindingsDocument203 pagesOADJS FindingsMautse Tung MywebsNo ratings yet
- E-Hospital Assignment: Valyandra P (20121030036)Document2 pagesE-Hospital Assignment: Valyandra P (20121030036)hanumzniiNo ratings yet
- Tugas SAD KelompokDocument14 pagesTugas SAD KelompokNaurah Atika DinaNo ratings yet
- Lab Assignment - 3 D.Sai Anirudh 17MIS7072: Grant and Revoke System and Object PrivilegesDocument17 pagesLab Assignment - 3 D.Sai Anirudh 17MIS7072: Grant and Revoke System and Object PrivilegesSai Anirudh DuggineniNo ratings yet
- ICT 122 Questions Bank-1Document60 pagesICT 122 Questions Bank-1areyNo ratings yet
- Zeek Case StudyDocument4 pagesZeek Case StudysuryanshNo ratings yet
- Oracle Rdbms KeypointsDocument1,439 pagesOracle Rdbms Keypointsdeepak1133100% (2)
- Database Fundamentals KeysDocument7 pagesDatabase Fundamentals KeysDave Reyes-TanNo ratings yet
- Access 2007 TutorialDocument45 pagesAccess 2007 TutorialPochetnikNo ratings yet
- E Bw4hana 13.sample - QuestionsDocument5 pagesE Bw4hana 13.sample - QuestionsPrateik NimbalkarNo ratings yet
- Big Data Analytics White PaperDocument38 pagesBig Data Analytics White PaperDaniela StaciNo ratings yet
- Patterns-Based Real-Time Data Warehouse Architecture: Djillali Nora Mohammed Mahieddine Oukid SalyhaDocument5 pagesPatterns-Based Real-Time Data Warehouse Architecture: Djillali Nora Mohammed Mahieddine Oukid SalyhaAminaHodžićNo ratings yet
- Cheat Sheet Seo For Wordpress v2 PDFDocument2 pagesCheat Sheet Seo For Wordpress v2 PDFPreetamSChaudhary0% (1)
- Declaration: I, Don Mathew, Do Hereby Declare That The Project Titled PRE-OWNED VEHICLEDocument99 pagesDeclaration: I, Don Mathew, Do Hereby Declare That The Project Titled PRE-OWNED VEHICLELetson ThomasNo ratings yet
- Two Basic Categories of Computer Memory:: Primary Storage and Secondary StorageDocument7 pagesTwo Basic Categories of Computer Memory:: Primary Storage and Secondary StorageRahul ShrivasNo ratings yet
- DWH MaterialDocument115 pagesDWH Materialkraveendrareddy05No ratings yet
- Chapter 1 Systems, Science, and StudyDocument21 pagesChapter 1 Systems, Science, and Studywahyu eka yurinaNo ratings yet
- Flacăra de Fier de Rebecca Yarros ScanDocument453 pagesFlacăra de Fier de Rebecca Yarros ScanMihaela DenisiaNo ratings yet
- Systems Proposal On Inventory ManagementDocument16 pagesSystems Proposal On Inventory ManagementSiegfred Laborte0% (2)
- Title Making Real-World Evidence RealDocument8 pagesTitle Making Real-World Evidence RealdajcNo ratings yet
- db2 Part Clust 115Document362 pagesdb2 Part Clust 115TrurlScribdNo ratings yet
- Github Com Aman0046 LastMinuteRevision DBMSDocument8 pagesGithub Com Aman0046 LastMinuteRevision DBMSGEN GENTLE INFAMOUSNo ratings yet