Download as pdf or txt
You might also like
- Paper 1Document6 pagesPaper 1vivek2mbNo ratings yet
- An Infrastructure For Dynamic Resource Scheduling and Virtual Machine Based Prediction in The CloudDocument5 pagesAn Infrastructure For Dynamic Resource Scheduling and Virtual Machine Based Prediction in The CloudKarthikaMurugesanNo ratings yet
- Threshold Based VM Placement Technique For Load Balanced Resource Provisioning Using Priority Scheme in Cloud ComputingDocument18 pagesThreshold Based VM Placement Technique For Load Balanced Resource Provisioning Using Priority Scheme in Cloud ComputingAIRCC - IJCNCNo ratings yet
- Modify Load Balancing in Cloud Database EnvironmentDocument6 pagesModify Load Balancing in Cloud Database EnvironmentAaditya SijariyaNo ratings yet
- Load Balancing Algorithms With The Application of Machine Learning - A ReviewDocument14 pagesLoad Balancing Algorithms With The Application of Machine Learning - A ReviewRajesh PandeyNo ratings yet
- Base Paper - PDCDocument14 pagesBase Paper - PDCAshvath NarayananNo ratings yet
- Load Balancing in Cloud Computing A Load Aware Matrix ApproachDocument6 pagesLoad Balancing in Cloud Computing A Load Aware Matrix ApproachAkshay ChouguleNo ratings yet
- International Refereed Journal of Engineering and Science (IRJES)Document6 pagesInternational Refereed Journal of Engineering and Science (IRJES)www.irjes.comNo ratings yet
- A Survey On Resource Allocation and Task Scheduling Algorithms in Cloud EnvironmentDocument7 pagesA Survey On Resource Allocation and Task Scheduling Algorithms in Cloud EnvironmentDeep PNo ratings yet
- Scheduling Virtual Machines For Load Balancing in Cloud Computing PlatformDocument5 pagesScheduling Virtual Machines For Load Balancing in Cloud Computing PlatformSupreeth SuhasNo ratings yet
- Resource Management and Scheduling in Cloud EnvironmentDocument8 pagesResource Management and Scheduling in Cloud Environmentvickyvarath100% (1)
- 2019 Taxanomy ClassificationDocument24 pages2019 Taxanomy ClassificationPradheeba Smirithi PNo ratings yet
- Research Paper CCDocument12 pagesResearch Paper CCsheraz mehmoodNo ratings yet
- Research On Cloud Computing Resources Provisioning Based On Reinforcement LearningDocument16 pagesResearch On Cloud Computing Resources Provisioning Based On Reinforcement LearningAnuj Pratap SinghNo ratings yet
- A Proactive Approach For Resource Provisioning in Cloud ComputingDocument10 pagesA Proactive Approach For Resource Provisioning in Cloud ComputingM.Satyendra kumarNo ratings yet
- Novel Statistical Load Balancing Algorithm For Cloud ComputingDocument10 pagesNovel Statistical Load Balancing Algorithm For Cloud Computingabutalib fadlallahNo ratings yet
- Task Partitioning Scheduling Algorithms For Heterogeneous Multi-Cloud EnvironmentDocument21 pagesTask Partitioning Scheduling Algorithms For Heterogeneous Multi-Cloud Environmentsohan pandeNo ratings yet
- Internet Technology Letters - 2020 - G - Efficient Task Optimization Algorithm For Green Computing in CloudDocument6 pagesInternet Technology Letters - 2020 - G - Efficient Task Optimization Algorithm For Green Computing in Cloudakshat patelNo ratings yet
- Evaluation of Auto Scaling and Load Balancing Features in CloudDocument4 pagesEvaluation of Auto Scaling and Load Balancing Features in CloudjosinonNo ratings yet
- An Efficient Improved Weighted Round Robin Load BaDocument8 pagesAn Efficient Improved Weighted Round Robin Load Bamansoor syedNo ratings yet
- Framework For Dynamic Resource Allocation and Efficient Scheduling Strategies To Enable Cloud For HPC PlatformsDocument3 pagesFramework For Dynamic Resource Allocation and Efficient Scheduling Strategies To Enable Cloud For HPC PlatformsKisan TavhareNo ratings yet
- 127 PDFDocument5 pages127 PDFInternational Journal of Scientific Research in Science, Engineering and Technology ( IJSRSET )No ratings yet
- Fog AlgorithmDocument15 pagesFog AlgorithmMuhammadNo ratings yet
- Cache Performance Based On Response Time and Cost Effectivein Cloud ComputingDocument10 pagesCache Performance Based On Response Time and Cost Effectivein Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Opr 044 DBDocument3 pagesOpr 044 DBSharath ShaanNo ratings yet
- Cloud Hpdc2009Document10 pagesCloud Hpdc2009Lee Zhong De RolleiNo ratings yet
- Paper 1Document9 pagesPaper 1PROJECT POINTNo ratings yet
- Cloud Computing Benchmarking: A Survey: 2 BackgroundDocument6 pagesCloud Computing Benchmarking: A Survey: 2 BackgroundDelphiNo ratings yet
- Linear Scheduling Strategy For Resource Allocation in Cloud EnvironmentDocument9 pagesLinear Scheduling Strategy For Resource Allocation in Cloud EnvironmentAnonymous roqsSNZ100% (1)
- A Novel Approach For Load Balancing in Cloud Computing by HARA AlgorithmDocument3 pagesA Novel Approach For Load Balancing in Cloud Computing by HARA AlgorithmerpublicationNo ratings yet
- Cloud Resource AllocationDocument4 pagesCloud Resource Allocationnidee_nishokNo ratings yet
- Job PDFDocument6 pagesJob PDFaswigaNo ratings yet
- Management of Data Intensive Application Workflow in Cloud ComputingDocument4 pagesManagement of Data Intensive Application Workflow in Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Enhanced Throttled Balancing Algorithm For Cloud ComputingDocument13 pagesEnhanced Throttled Balancing Algorithm For Cloud ComputingAlmazeye MedaNo ratings yet
- Energy - Optimized Virtual Machine Scheduling Schemes in Cloud EnvironmentDocument5 pagesEnergy - Optimized Virtual Machine Scheduling Schemes in Cloud EnvironmentDrGhanshyam ParmarNo ratings yet
- Aloocatin Future ScopeDocument5 pagesAloocatin Future ScopejorisdudaNo ratings yet
- The International Journal of Science & Technoledge: Proactive Scheduling in Cloud ComputingDocument6 pagesThe International Journal of Science & Technoledge: Proactive Scheduling in Cloud ComputingIr Solly Aryza MengNo ratings yet
- CHASE: Component High Availability-Aware Scheduler in Cloud Computing EnvironmentDocument8 pagesCHASE: Component High Availability-Aware Scheduler in Cloud Computing EnvironmentGabriel OvandoNo ratings yet
- Toka 2021Document15 pagesToka 2021jorwekar7No ratings yet
- Machine Learning Based Workload Prediction in Cloud ComputingDocument9 pagesMachine Learning Based Workload Prediction in Cloud Computinggabriel.matos1201No ratings yet
- Load Balancing in Cloud ComputingDocument7 pagesLoad Balancing in Cloud ComputingChandan KumarNo ratings yet
- Building Efficient Resource Management Systems in The Cloud: Opportunities and ChallengesDocument16 pagesBuilding Efficient Resource Management Systems in The Cloud: Opportunities and ChallengesAlexking1985No ratings yet
- Performance Analysis of CBLB Algorithm in Simulation and Real Cloud EnvironmentDocument12 pagesPerformance Analysis of CBLB Algorithm in Simulation and Real Cloud Environmentabutalib fadlallahNo ratings yet
- S.S. Manvi, G. Krishna Shyam / Journal of Network and Computer Applications ( ) - 6Document1 pageS.S. Manvi, G. Krishna Shyam / Journal of Network and Computer Applications ( ) - 6cuong.ta14584No ratings yet
- Study On Behaviour of Nano ConcreteDocument6 pagesStudy On Behaviour of Nano ConcreteInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Resource Monitoring in Cloud Computing: Akshay MehtaDocument3 pagesResource Monitoring in Cloud Computing: Akshay Mehtaakshay mehtaNo ratings yet
- Virtual Machine Provisioning Based On Analytical Performance and Qos in Cloud Computing EnvironmentsDocument10 pagesVirtual Machine Provisioning Based On Analytical Performance and Qos in Cloud Computing EnvironmentsjasonwNo ratings yet
- J. Parallel Distrib. Comput.: Jiayin Li Meikang Qiu Zhong Ming Gang Quan Xiao Qin Zonghua GuDocument12 pagesJ. Parallel Distrib. Comput.: Jiayin Li Meikang Qiu Zhong Ming Gang Quan Xiao Qin Zonghua GusasidharchennamsettyNo ratings yet
- The-Impact-On-Load-balancing-In-Cloud-Computing 2020Document5 pagesThe-Impact-On-Load-balancing-In-Cloud-Computing 2020Nikola JovanovicNo ratings yet
- Deepti Project ReportDocument63 pagesDeepti Project ReportTaslim AlamNo ratings yet
- Dynamic Resource Allocation Scheme in Cloud Computing: SciencedirectDocument7 pagesDynamic Resource Allocation Scheme in Cloud Computing: SciencedirectKrishna Kumar VelappanNo ratings yet
- Energy Efficient Resource Allocation in Cloud EnviDocument13 pagesEnergy Efficient Resource Allocation in Cloud EnviRABINA BAGGANo ratings yet
- International Journal of Engineering Research and DevelopmentDocument4 pagesInternational Journal of Engineering Research and DevelopmentIJERDNo ratings yet
- (IJCST-V1I2P6) : K K Shahabanath, T Sreekesh NamboodiriDocument4 pages(IJCST-V1I2P6) : K K Shahabanath, T Sreekesh NamboodiriIJETA - EighthSenseGroupNo ratings yet
- Unit IvDocument20 pagesUnit Ivrachananandhan3007No ratings yet
- Cloud ComputingDocument6 pagesCloud ComputingmsisipuNo ratings yet
- A New Load Balancing Technique For Virtual Machine Cloud Computing EnvironmentDocument4 pagesA New Load Balancing Technique For Virtual Machine Cloud Computing EnvironmentUmer WaqarNo ratings yet
- Hummaida 2016Document16 pagesHummaida 2016Olfa Souki Ep ChebilNo ratings yet
- (IJCST-V10I1P9) :mr. Monilal SDocument4 pages(IJCST-V10I1P9) :mr. Monilal SEighthSenseGroupNo ratings yet
- Model-Driven Online Capacity Management for Component-Based Software SystemsFrom EverandModel-Driven Online Capacity Management for Component-Based Software SystemsNo ratings yet
- C10 Remote Control Via Apple Ipad - Huawei WiFi Adapter - enDocument20 pagesC10 Remote Control Via Apple Ipad - Huawei WiFi Adapter - enVolodymyr TarnavskyyNo ratings yet
- C Tadm51 731Document4 pagesC Tadm51 731we003820% (5)
- Avionics Full-Duplex Switched Ethernet: HistoryDocument6 pagesAvionics Full-Duplex Switched Ethernet: Historyvijaykumar ponugotiNo ratings yet
- Password Protection Using PIC Microcontroller - The Engineering ProjectsDocument10 pagesPassword Protection Using PIC Microcontroller - The Engineering ProjectsTeo JavaNo ratings yet
- Project Report Arithmetic Logic Unit (ALU)Document71 pagesProject Report Arithmetic Logic Unit (ALU)Hemant Sharma100% (1)
- Advanced Training On s7 400 PLC & Drive s120Document3 pagesAdvanced Training On s7 400 PLC & Drive s120stlsclNo ratings yet
- Chapter Five Database Recovery TechniquesDocument33 pagesChapter Five Database Recovery TechniquesHayimanot YirgaNo ratings yet
- PACiSGTW NRJED112382ENDocument2 pagesPACiSGTW NRJED112382ENlucasNo ratings yet
- PowerSuite-Help 2v1b Rus PDFDocument154 pagesPowerSuite-Help 2v1b Rus PDFBossNo ratings yet
- Final Review 09Document21 pagesFinal Review 09qwerty17327No ratings yet
- Cloudstack Installation PDFDocument160 pagesCloudstack Installation PDFdhany PNo ratings yet
- Huawei Bm622m&Bm623m&Bm626e&Bm636e Upgrade GuideDocument37 pagesHuawei Bm622m&Bm623m&Bm626e&Bm636e Upgrade GuideRigorMortizNo ratings yet
- Clustering DocumentationDocument15 pagesClustering DocumentationNazifa KazimiNo ratings yet
- ACID PropertiesDocument7 pagesACID PropertiesMir ArifaNo ratings yet
- Casio Te-2200Document2 pagesCasio Te-2200nemo_tikNo ratings yet
- Java ThreadsDocument81 pagesJava ThreadsharinaathanNo ratings yet
- Blog: What Are All These X11, X13, X15 Algorithms Made Of?: X11 X12 X13 X14 X15 X17Document2 pagesBlog: What Are All These X11, X13, X15 Algorithms Made Of?: X11 X12 X13 X14 X15 X17NiksenBinSyafeiNo ratings yet
- FTP Server in LinuxDocument22 pagesFTP Server in Linuxmuitnep4100% (1)
- LPC84 XDocument100 pagesLPC84 XMauricio ScalerandiNo ratings yet
- Manual PacDrive C400Document8 pagesManual PacDrive C400Ulises PereiraNo ratings yet
- MCQ D.E ECE Vipin Uppal PDFDocument21 pagesMCQ D.E ECE Vipin Uppal PDFarpitrockNo ratings yet
- VLSM Addressing: Problem 1Document9 pagesVLSM Addressing: Problem 1ABDUL HADI KHANNo ratings yet
- L-2.1.2 Memory Allocation TechniquesDocument15 pagesL-2.1.2 Memory Allocation TechniquesAbhishek ChoudharyNo ratings yet
- Unpacking For Dummies CompressedDocument78 pagesUnpacking For Dummies CompressedrobertNo ratings yet
- Operating Systems: Assignment 1: System Calls and SchedulingDocument6 pagesOperating Systems: Assignment 1: System Calls and SchedulingNatalie AhmadNo ratings yet
- Financial Management Application Copy Utility v1 5Document24 pagesFinancial Management Application Copy Utility v1 5praswerNo ratings yet
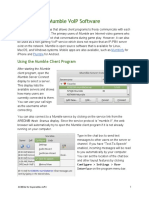
- Mumble Voip Software: Using The Mumble Client ProgramDocument3 pagesMumble Voip Software: Using The Mumble Client Programdočasná emailová adresaNo ratings yet
- LogDocument90 pagesLogNikolche MitrikjevskiNo ratings yet
- PRO40 Server Monitoring 01july2015Document61 pagesPRO40 Server Monitoring 01july2015samelkaddNo ratings yet
- 01 Huawei FusionAccess Desktop Solution OverviewDocument36 pages01 Huawei FusionAccess Desktop Solution OverviewriyasathsafranNo ratings yet