
Data Warehouse Architucture
Data Warehouse Architucture
You might also like
- API Reference - OpenAI APIDocument46 pagesAPI Reference - OpenAI APIscribdNo ratings yet
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"From EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Rating: 3 out of 5 stars3/5 (1)
- Activate and Connect Fubo TV On Fire Stick TVDocument4 pagesActivate and Connect Fubo TV On Fire Stick TVBaron SilvaNo ratings yet
- Short Quiz 1 6Document5 pagesShort Quiz 1 6Arabella MagallanesNo ratings yet
- Data Warehouse ConceptsDocument11 pagesData Warehouse ConceptsShailendra Shakya100% (1)
- Data Warehousing AssignmentDocument9 pagesData Warehousing AssignmentRushil Nagwan100% (2)
- Unit1 (DW&DM)Document30 pagesUnit1 (DW&DM)Mrudul BhattNo ratings yet
- 5-7-2010 Components of A Data Warehouse: Overall ArchitectureDocument4 pages5-7-2010 Components of A Data Warehouse: Overall ArchitectureRamakrishnan Harihara VenkatasubramaniaNo ratings yet
- Unit I Data WarehousingDocument10 pagesUnit I Data WarehousingAjit RautNo ratings yet
- DATA Ware House & Mining NOTESDocument31 pagesDATA Ware House & Mining NOTESABHISHEK KUMAR SAH100% (1)
- Arpit Garg 00913302717 SLS 6Document5 pagesArpit Garg 00913302717 SLS 6Subject LearningNo ratings yet
- Mid Syllabus DWHDocument25 pagesMid Syllabus DWHShamila SaleemNo ratings yet
- Data Warehouse ArchitectureDocument8 pagesData Warehouse Architecturerishabh28072002No ratings yet
- CH 2 Introduction To Data WarehousingDocument31 pagesCH 2 Introduction To Data WarehousingsrjaswarNo ratings yet
- 2 Data Warehousing Components L3 L4 L5Document26 pages2 Data Warehousing Components L3 L4 L5MANOJ KUMAWATNo ratings yet
- Data Warehouse Week 1Document78 pagesData Warehouse Week 1bsit fall20No ratings yet
- Assignment 1Document15 pagesAssignment 1Dhruvil ShahNo ratings yet
- DWDM Notes - FinalDocument46 pagesDWDM Notes - Finalharshtyagi2212No ratings yet
- Data Warehousing Components - L3 - L4 - L5Document26 pagesData Warehousing Components - L3 - L4 - L5Deepika GargNo ratings yet
- Data Warehouse and Data Mining NotesDocument31 pagesData Warehouse and Data Mining NotesSamrat SaxenaNo ratings yet
- Data Mining & HousingDocument13 pagesData Mining & Housingpankaj2908No ratings yet
- Difference Between Data Warehousing and Data Mining: Data Warehouse Architecture Three-Tier Data Warehouse ArchitectureDocument10 pagesDifference Between Data Warehousing and Data Mining: Data Warehouse Architecture Three-Tier Data Warehouse ArchitecturepriyaNo ratings yet
- Unit-2: Multi-Dimensional Data Model?Document21 pagesUnit-2: Multi-Dimensional Data Model?efwewefNo ratings yet
- Data Ware Housing1Document18 pagesData Ware Housing1Toaster97No ratings yet
- Data WarehousingDocument16 pagesData WarehousingRaman SinghNo ratings yet
- Data Warehouse Architechture-LayersDocument21 pagesData Warehouse Architechture-LayersAdil Bin KhalidNo ratings yet
- Basic Elements of Data Warehouse ArchitectureDocument3 pagesBasic Elements of Data Warehouse ArchitectureNiharikaPendem100% (1)
- Assignment 2Document6 pagesAssignment 2Aditya BossNo ratings yet
- Unit 3 NotesDocument20 pagesUnit 3 NotesRajkumar DharmarajNo ratings yet
- Overview of Data Warehousing: AIM: - To Learn Architectural Framework For Data Warehousing TheoryDocument10 pagesOverview of Data Warehousing: AIM: - To Learn Architectural Framework For Data Warehousing TheoryJahnvi DoshiNo ratings yet
- Data Warehousing Is The Coordinated, Architected, and Periodic Copying of Data FromDocument33 pagesData Warehousing Is The Coordinated, Architected, and Periodic Copying of Data Fromss1226No ratings yet
- 12 01 09 10 32 12 1287 Sindhujam PDFDocument23 pages12 01 09 10 32 12 1287 Sindhujam PDFPrasad DhanikondaNo ratings yet
- UNIT-1 (RIT-062) : Data WarehousingDocument34 pagesUNIT-1 (RIT-062) : Data WarehousingNikhil GuptaNo ratings yet
- T2 Architecture of Data WarehousingDocument9 pagesT2 Architecture of Data Warehousingorion werrtyNo ratings yet
- DM - MOD - 2 Part - IDocument19 pagesDM - MOD - 2 Part - IsandrarajuofficialNo ratings yet
- Warehouse CompleteDocument6 pagesWarehouse CompletegurugabruNo ratings yet
- What Is Data Warehouse?: DefinationDocument17 pagesWhat Is Data Warehouse?: Definationapi-26830587No ratings yet
- Approach, or A Combination of BothDocument12 pagesApproach, or A Combination of BothNeha KhanNo ratings yet
- Paper Presentation: Data Ware Housing AND Data MiningDocument10 pagesPaper Presentation: Data Ware Housing AND Data Miningapi-19799369No ratings yet
- DWDMDocument40 pagesDWDMAkash RavichandranNo ratings yet
- Ism Second ModuleDocument73 pagesIsm Second ModuleABOOBAKKERNo ratings yet
- 3 Marks 1.what Is Data Warehouse?: o o o o oDocument13 pages3 Marks 1.what Is Data Warehouse?: o o o o oNimithaNo ratings yet
- Block - 3 Unit-1 Object Oriented DatabaseDocument16 pagesBlock - 3 Unit-1 Object Oriented DatabasepriyaNo ratings yet
- Data Mining and Data Warehouse BYDocument12 pagesData Mining and Data Warehouse BYapi-19799369100% (1)
- Unit 1Document26 pagesUnit 1SanthoshNo ratings yet
- Data Warehouse-Ccs341 MaterialDocument58 pagesData Warehouse-Ccs341 Materialragavaharish463No ratings yet
- Data Warehousing ComponentsDocument5 pagesData Warehousing ComponentsVaishu SriniNo ratings yet
- Informatica and Datawarehouse PDFDocument156 pagesInformatica and Datawarehouse PDFsmruti_2012No ratings yet
- Data Warehouse Power Point PresentationDocument18 pagesData Warehouse Power Point PresentationMohammed KemalNo ratings yet
- AD Theory 3Document14 pagesAD Theory 3AARUSH SABOONo ratings yet
- Data Warehousing and Data Mining Bhoj Reddy Engineering College For WomenDocument11 pagesData Warehousing and Data Mining Bhoj Reddy Engineering College For WomenPriyanka MedipalliNo ratings yet
- Unit IDocument33 pagesUnit IAkash RavichandranNo ratings yet
- Data WarehousingDocument7 pagesData WarehousingLawal Mobolaji MNo ratings yet
- DW Architecture & DataFlowDocument24 pagesDW Architecture & DataFlowGeetkiran KaurNo ratings yet
- INFORMATION MANAGEMENT Unit 3 NEWDocument61 pagesINFORMATION MANAGEMENT Unit 3 NEWThirumal Azhagan100% (1)
- Ccs341-Dw-Int I Key-Set Ii - ArDocument14 pagesCcs341-Dw-Int I Key-Set Ii - ArNISHANTH MNo ratings yet
- CS2032 Data Warehousing and Data Mining PPT Unit IDocument88 pagesCS2032 Data Warehousing and Data Mining PPT Unit IvdsrihariNo ratings yet
- Data WarehousingDocument7 pagesData WarehousingSajakul SornNo ratings yet
- Data Warehousing and On-Line Analytical ProcessingDocument40 pagesData Warehousing and On-Line Analytical ProcessingChitransh NamanNo ratings yet
- Data Lake: Strategies and Best Practices for Storing, Managing, and Analyzing Big DataFrom EverandData Lake: Strategies and Best Practices for Storing, Managing, and Analyzing Big DataNo ratings yet
- Polycom HDX Configuration Guide: How To Configure A Polycom HDX To Work With 8x8 ServiceDocument11 pagesPolycom HDX Configuration Guide: How To Configure A Polycom HDX To Work With 8x8 ServicetheanhcbNo ratings yet
- Lecture 10Document39 pagesLecture 10FatimaNo ratings yet
- 18cs53 Dbms Module 5Document25 pages18cs53 Dbms Module 5kishor gowdaNo ratings yet
- RSSI (Received Signal Strength Indicator)Document4 pagesRSSI (Received Signal Strength Indicator)Dr. Md. Salah Uddin YusufNo ratings yet
- Student Attendance Monitoring System C1Document5 pagesStudent Attendance Monitoring System C1Sherynhell Ann PeralesNo ratings yet
- TutorialDocument118 pagesTutorialalimnh2003No ratings yet
- Lec6 Fork ExecDocument17 pagesLec6 Fork Execsamson oinoNo ratings yet
- Latex Quick ReferenceDocument1 pageLatex Quick ReferenceIgor JuricNo ratings yet
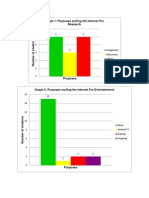
- Graph 1: Purposes Surfing The Internet For ResearchDocument2 pagesGraph 1: Purposes Surfing The Internet For ResearchNana KawaiiNo ratings yet
- STS FatDocument35 pagesSTS Fatharsh chauhanNo ratings yet
- Unit - 3 8255: (Programmable Peripheral Interface)Document7 pagesUnit - 3 8255: (Programmable Peripheral Interface)Praveen SinghNo ratings yet
- Advanced Post-Processing With The FEMAP API: Patrick Kriengsiri, Femap DevelopmentDocument78 pagesAdvanced Post-Processing With The FEMAP API: Patrick Kriengsiri, Femap DevelopmentSabanSaulicNo ratings yet
- CENELEC GridProfileDocument4 pagesCENELEC GridProfileMartin LeonardNo ratings yet
- T Issa - CCV2010 - Paper PDFDocument7 pagesT Issa - CCV2010 - Paper PDFProcurement LNSP LabNo ratings yet
- CS - Revision Through Question - GATE - 2020Document117 pagesCS - Revision Through Question - GATE - 2020Abhishek Dabar100% (2)
- Activation Process of ONU in EPON/GPON/XG-PON/NG-PON2 Networks.Document18 pagesActivation Process of ONU in EPON/GPON/XG-PON/NG-PON2 Networks.trucoNo ratings yet
- DS Orientation SheetDocument1 pageDS Orientation SheetSamNo ratings yet
- Kp0003299 Avm Dart OverviewDocument51 pagesKp0003299 Avm Dart OverviewManoj MahajanNo ratings yet
- Inventory System Thesis Vb6Document5 pagesInventory System Thesis Vb6afjrooeyv100% (2)
- Unit - 1 QB AnswersDocument15 pagesUnit - 1 QB Answers20CSE312 BHANU PRAKASHNo ratings yet
- Bike Parking Project (Coding)Document6 pagesBike Parking Project (Coding)Information 4UNo ratings yet
- Sparsh Attendance Management SystemDocument2 pagesSparsh Attendance Management SystemSparsh TechnologiesNo ratings yet
- General Wireless Design Considerations 1 PDFDocument0 pagesGeneral Wireless Design Considerations 1 PDFDurga TejaNo ratings yet
- Chapter 02 - 800xa SystemDocument35 pagesChapter 02 - 800xa Systemธรรมรักษ์ โทนาอรรถNo ratings yet
- Thesis Title PageDocument10 pagesThesis Title PageIlyasoft KP PeshawarNo ratings yet
- Multiple Choice Questions Chapter 1Document4 pagesMultiple Choice Questions Chapter 1Xyza Faye Regalado50% (2)
- DP WLAN 15041 DriversDocument3,571 pagesDP WLAN 15041 DriversJuan Carlos Gonzalez LNo ratings yet

























































































Download as pdf or txt
You might also like
- API Reference - OpenAI APIDocument46 pagesAPI Reference - OpenAI APIscribdNo ratings yet
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"From EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Rating: 3 out of 5 stars3/5 (1)
- Activate and Connect Fubo TV On Fire Stick TVDocument4 pagesActivate and Connect Fubo TV On Fire Stick TVBaron SilvaNo ratings yet
- Short Quiz 1 6Document5 pagesShort Quiz 1 6Arabella MagallanesNo ratings yet
- Data Warehouse ConceptsDocument11 pagesData Warehouse ConceptsShailendra Shakya100% (1)
- Data Warehousing AssignmentDocument9 pagesData Warehousing AssignmentRushil Nagwan100% (2)
- Unit1 (DW&DM)Document30 pagesUnit1 (DW&DM)Mrudul BhattNo ratings yet
- 5-7-2010 Components of A Data Warehouse: Overall ArchitectureDocument4 pages5-7-2010 Components of A Data Warehouse: Overall ArchitectureRamakrishnan Harihara VenkatasubramaniaNo ratings yet
- Unit I Data WarehousingDocument10 pagesUnit I Data WarehousingAjit RautNo ratings yet
- DATA Ware House & Mining NOTESDocument31 pagesDATA Ware House & Mining NOTESABHISHEK KUMAR SAH100% (1)
- Arpit Garg 00913302717 SLS 6Document5 pagesArpit Garg 00913302717 SLS 6Subject LearningNo ratings yet
- Mid Syllabus DWHDocument25 pagesMid Syllabus DWHShamila SaleemNo ratings yet
- Data Warehouse ArchitectureDocument8 pagesData Warehouse Architecturerishabh28072002No ratings yet
- CH 2 Introduction To Data WarehousingDocument31 pagesCH 2 Introduction To Data WarehousingsrjaswarNo ratings yet
- 2 Data Warehousing Components L3 L4 L5Document26 pages2 Data Warehousing Components L3 L4 L5MANOJ KUMAWATNo ratings yet
- Data Warehouse Week 1Document78 pagesData Warehouse Week 1bsit fall20No ratings yet
- Assignment 1Document15 pagesAssignment 1Dhruvil ShahNo ratings yet
- DWDM Notes - FinalDocument46 pagesDWDM Notes - Finalharshtyagi2212No ratings yet
- Data Warehousing Components - L3 - L4 - L5Document26 pagesData Warehousing Components - L3 - L4 - L5Deepika GargNo ratings yet
- Data Warehouse and Data Mining NotesDocument31 pagesData Warehouse and Data Mining NotesSamrat SaxenaNo ratings yet
- Data Mining & HousingDocument13 pagesData Mining & Housingpankaj2908No ratings yet
- Difference Between Data Warehousing and Data Mining: Data Warehouse Architecture Three-Tier Data Warehouse ArchitectureDocument10 pagesDifference Between Data Warehousing and Data Mining: Data Warehouse Architecture Three-Tier Data Warehouse ArchitecturepriyaNo ratings yet
- Unit-2: Multi-Dimensional Data Model?Document21 pagesUnit-2: Multi-Dimensional Data Model?efwewefNo ratings yet
- Data Ware Housing1Document18 pagesData Ware Housing1Toaster97No ratings yet
- Data WarehousingDocument16 pagesData WarehousingRaman SinghNo ratings yet
- Data Warehouse Architechture-LayersDocument21 pagesData Warehouse Architechture-LayersAdil Bin KhalidNo ratings yet
- Basic Elements of Data Warehouse ArchitectureDocument3 pagesBasic Elements of Data Warehouse ArchitectureNiharikaPendem100% (1)
- Assignment 2Document6 pagesAssignment 2Aditya BossNo ratings yet
- Unit 3 NotesDocument20 pagesUnit 3 NotesRajkumar DharmarajNo ratings yet
- Overview of Data Warehousing: AIM: - To Learn Architectural Framework For Data Warehousing TheoryDocument10 pagesOverview of Data Warehousing: AIM: - To Learn Architectural Framework For Data Warehousing TheoryJahnvi DoshiNo ratings yet
- Data Warehousing Is The Coordinated, Architected, and Periodic Copying of Data FromDocument33 pagesData Warehousing Is The Coordinated, Architected, and Periodic Copying of Data Fromss1226No ratings yet
- 12 01 09 10 32 12 1287 Sindhujam PDFDocument23 pages12 01 09 10 32 12 1287 Sindhujam PDFPrasad DhanikondaNo ratings yet
- UNIT-1 (RIT-062) : Data WarehousingDocument34 pagesUNIT-1 (RIT-062) : Data WarehousingNikhil GuptaNo ratings yet
- T2 Architecture of Data WarehousingDocument9 pagesT2 Architecture of Data Warehousingorion werrtyNo ratings yet
- DM - MOD - 2 Part - IDocument19 pagesDM - MOD - 2 Part - IsandrarajuofficialNo ratings yet
- Warehouse CompleteDocument6 pagesWarehouse CompletegurugabruNo ratings yet
- What Is Data Warehouse?: DefinationDocument17 pagesWhat Is Data Warehouse?: Definationapi-26830587No ratings yet
- Approach, or A Combination of BothDocument12 pagesApproach, or A Combination of BothNeha KhanNo ratings yet
- Paper Presentation: Data Ware Housing AND Data MiningDocument10 pagesPaper Presentation: Data Ware Housing AND Data Miningapi-19799369No ratings yet
- DWDMDocument40 pagesDWDMAkash RavichandranNo ratings yet
- Ism Second ModuleDocument73 pagesIsm Second ModuleABOOBAKKERNo ratings yet
- 3 Marks 1.what Is Data Warehouse?: o o o o oDocument13 pages3 Marks 1.what Is Data Warehouse?: o o o o oNimithaNo ratings yet
- Block - 3 Unit-1 Object Oriented DatabaseDocument16 pagesBlock - 3 Unit-1 Object Oriented DatabasepriyaNo ratings yet
- Data Mining and Data Warehouse BYDocument12 pagesData Mining and Data Warehouse BYapi-19799369100% (1)
- Unit 1Document26 pagesUnit 1SanthoshNo ratings yet
- Data Warehouse-Ccs341 MaterialDocument58 pagesData Warehouse-Ccs341 Materialragavaharish463No ratings yet
- Data Warehousing ComponentsDocument5 pagesData Warehousing ComponentsVaishu SriniNo ratings yet
- Informatica and Datawarehouse PDFDocument156 pagesInformatica and Datawarehouse PDFsmruti_2012No ratings yet
- Data Warehouse Power Point PresentationDocument18 pagesData Warehouse Power Point PresentationMohammed KemalNo ratings yet
- AD Theory 3Document14 pagesAD Theory 3AARUSH SABOONo ratings yet
- Data Warehousing and Data Mining Bhoj Reddy Engineering College For WomenDocument11 pagesData Warehousing and Data Mining Bhoj Reddy Engineering College For WomenPriyanka MedipalliNo ratings yet
- Unit IDocument33 pagesUnit IAkash RavichandranNo ratings yet
- Data WarehousingDocument7 pagesData WarehousingLawal Mobolaji MNo ratings yet
- DW Architecture & DataFlowDocument24 pagesDW Architecture & DataFlowGeetkiran KaurNo ratings yet
- INFORMATION MANAGEMENT Unit 3 NEWDocument61 pagesINFORMATION MANAGEMENT Unit 3 NEWThirumal Azhagan100% (1)
- Ccs341-Dw-Int I Key-Set Ii - ArDocument14 pagesCcs341-Dw-Int I Key-Set Ii - ArNISHANTH MNo ratings yet
- CS2032 Data Warehousing and Data Mining PPT Unit IDocument88 pagesCS2032 Data Warehousing and Data Mining PPT Unit IvdsrihariNo ratings yet
- Data WarehousingDocument7 pagesData WarehousingSajakul SornNo ratings yet
- Data Warehousing and On-Line Analytical ProcessingDocument40 pagesData Warehousing and On-Line Analytical ProcessingChitransh NamanNo ratings yet
- Data Lake: Strategies and Best Practices for Storing, Managing, and Analyzing Big DataFrom EverandData Lake: Strategies and Best Practices for Storing, Managing, and Analyzing Big DataNo ratings yet
- Polycom HDX Configuration Guide: How To Configure A Polycom HDX To Work With 8x8 ServiceDocument11 pagesPolycom HDX Configuration Guide: How To Configure A Polycom HDX To Work With 8x8 ServicetheanhcbNo ratings yet
- Lecture 10Document39 pagesLecture 10FatimaNo ratings yet
- 18cs53 Dbms Module 5Document25 pages18cs53 Dbms Module 5kishor gowdaNo ratings yet
- RSSI (Received Signal Strength Indicator)Document4 pagesRSSI (Received Signal Strength Indicator)Dr. Md. Salah Uddin YusufNo ratings yet
- Student Attendance Monitoring System C1Document5 pagesStudent Attendance Monitoring System C1Sherynhell Ann PeralesNo ratings yet
- TutorialDocument118 pagesTutorialalimnh2003No ratings yet
- Lec6 Fork ExecDocument17 pagesLec6 Fork Execsamson oinoNo ratings yet
- Latex Quick ReferenceDocument1 pageLatex Quick ReferenceIgor JuricNo ratings yet
- Graph 1: Purposes Surfing The Internet For ResearchDocument2 pagesGraph 1: Purposes Surfing The Internet For ResearchNana KawaiiNo ratings yet
- STS FatDocument35 pagesSTS Fatharsh chauhanNo ratings yet
- Unit - 3 8255: (Programmable Peripheral Interface)Document7 pagesUnit - 3 8255: (Programmable Peripheral Interface)Praveen SinghNo ratings yet
- Advanced Post-Processing With The FEMAP API: Patrick Kriengsiri, Femap DevelopmentDocument78 pagesAdvanced Post-Processing With The FEMAP API: Patrick Kriengsiri, Femap DevelopmentSabanSaulicNo ratings yet
- CENELEC GridProfileDocument4 pagesCENELEC GridProfileMartin LeonardNo ratings yet
- T Issa - CCV2010 - Paper PDFDocument7 pagesT Issa - CCV2010 - Paper PDFProcurement LNSP LabNo ratings yet
- CS - Revision Through Question - GATE - 2020Document117 pagesCS - Revision Through Question - GATE - 2020Abhishek Dabar100% (2)
- Activation Process of ONU in EPON/GPON/XG-PON/NG-PON2 Networks.Document18 pagesActivation Process of ONU in EPON/GPON/XG-PON/NG-PON2 Networks.trucoNo ratings yet
- DS Orientation SheetDocument1 pageDS Orientation SheetSamNo ratings yet
- Kp0003299 Avm Dart OverviewDocument51 pagesKp0003299 Avm Dart OverviewManoj MahajanNo ratings yet
- Inventory System Thesis Vb6Document5 pagesInventory System Thesis Vb6afjrooeyv100% (2)
- Unit - 1 QB AnswersDocument15 pagesUnit - 1 QB Answers20CSE312 BHANU PRAKASHNo ratings yet
- Bike Parking Project (Coding)Document6 pagesBike Parking Project (Coding)Information 4UNo ratings yet
- Sparsh Attendance Management SystemDocument2 pagesSparsh Attendance Management SystemSparsh TechnologiesNo ratings yet
- General Wireless Design Considerations 1 PDFDocument0 pagesGeneral Wireless Design Considerations 1 PDFDurga TejaNo ratings yet
- Chapter 02 - 800xa SystemDocument35 pagesChapter 02 - 800xa Systemธรรมรักษ์ โทนาอรรถNo ratings yet
- Thesis Title PageDocument10 pagesThesis Title PageIlyasoft KP PeshawarNo ratings yet
- Multiple Choice Questions Chapter 1Document4 pagesMultiple Choice Questions Chapter 1Xyza Faye Regalado50% (2)
- DP WLAN 15041 DriversDocument3,571 pagesDP WLAN 15041 DriversJuan Carlos Gonzalez LNo ratings yet