
Credit Risk Modelling
Credit Risk Modelling
You might also like
- EXL Acquisition Scorecard Reject Inference MethodologiesDocument13 pagesEXL Acquisition Scorecard Reject Inference MethodologiesTathagata MaityNo ratings yet
- Comparison of Modeling Methods For Loss Given DefaultDocument14 pagesComparison of Modeling Methods For Loss Given DefaultAnnNo ratings yet
- Ifrs 9 Ecl Template General ApproachDocument2 pagesIfrs 9 Ecl Template General ApproachTousief NaqviNo ratings yet
- Topquants: Modelling Liquidity Risk: Mortgage ExampleDocument22 pagesTopquants: Modelling Liquidity Risk: Mortgage ExampleAlberto EstanesNo ratings yet
- Guide To ACF PACF PlotsDocument6 pagesGuide To ACF PACF Plotsajax_telamonioNo ratings yet
- Credit Risk Modelling - A PrimerDocument42 pagesCredit Risk Modelling - A PrimersatishdwnldNo ratings yet
- Market Risk Questions PDFDocument16 pagesMarket Risk Questions PDFbabubhagoud1983No ratings yet
- ML SasDocument17 pagesML SasmartdiazNo ratings yet
- MASH Multiple Regression RDocument5 pagesMASH Multiple Regression Rsheilaabad8766No ratings yet
- Credit Risk Estimation TechniquesDocument31 pagesCredit Risk Estimation TechniquesHanumantha Rao Turlapati0% (1)
- Using Logistic Regression Predict Credit DefaultDocument6 pagesUsing Logistic Regression Predict Credit DefaultSneha SinghNo ratings yet
- Modelling Credit RiskDocument27 pagesModelling Credit RiskPuneet SawhneyNo ratings yet
- Forecasting Default With The KMV-Merton ModelDocument35 pagesForecasting Default With The KMV-Merton ModelEdgardo Garcia MartinezNo ratings yet
- Credit Risk ModellingDocument28 pagesCredit Risk ModellingAnjali VermaNo ratings yet
- Bank Stress Testing A Stochastic Simulation FramewDocument51 pagesBank Stress Testing A Stochastic Simulation FramewmehNo ratings yet
- Credit Risk Mgmt. at ICICIDocument60 pagesCredit Risk Mgmt. at ICICIRikesh Daliya100% (1)
- Using SAS For Effective Credit Risk ManagementDocument10 pagesUsing SAS For Effective Credit Risk ManagementaminiotisNo ratings yet
- Credit Risk Analysis Applying Logistic Regression, Neural Networks and Genetic Algorithms ModelsDocument12 pagesCredit Risk Analysis Applying Logistic Regression, Neural Networks and Genetic Algorithms ModelsIJAERS JOURNALNo ratings yet
- Credit Risk Modeling New - New1Document41 pagesCredit Risk Modeling New - New1aminat oseniNo ratings yet
- Value at RiskDocument4 pagesValue at RiskShubham PariharNo ratings yet
- Calculation of Expected and Unexpected Losses in Operational RiskDocument10 pagesCalculation of Expected and Unexpected Losses in Operational RiskJabberwockkidNo ratings yet
- Merton PD ModelDocument6 pagesMerton PD Modelapi-223061586No ratings yet
- Credit Risk CalculatorDocument4 pagesCredit Risk CalculatorarsinhaNo ratings yet
- Presentation On Value at RiskDocument22 pagesPresentation On Value at RiskRomaMakhijaNo ratings yet
- Standardized Approach For Counterparty Credit RiskDocument2 pagesStandardized Approach For Counterparty Credit RiskjalutukNo ratings yet
- Expected Shortfall - An Alternative Risk Measure To Value-At-RiskDocument14 pagesExpected Shortfall - An Alternative Risk Measure To Value-At-Risksirj0_hnNo ratings yet
- Logistic RegressionDocument24 pagesLogistic RegressionVeerpal KhairaNo ratings yet
- Credit Risk Modeling in Python Chapter4Document35 pagesCredit Risk Modeling in Python Chapter4FgpeqwNo ratings yet
- Basel Implementation Issues PDFDocument16 pagesBasel Implementation Issues PDFOsama AzNo ratings yet
- Risk Management: Basel Committee On Banking Supervision (BCBS)Document25 pagesRisk Management: Basel Committee On Banking Supervision (BCBS)Shirsendu Bikash DasNo ratings yet
- Asset and Liability ManagementDocument17 pagesAsset and Liability ManagementkavyapbNo ratings yet
- Enterprise Credit Risk Evaluation Based On Neural Network AlgorithmDocument8 pagesEnterprise Credit Risk Evaluation Based On Neural Network AlgorithmJorge Luis SorianoNo ratings yet
- CH 5 MARKET RISK - VaRDocument29 pagesCH 5 MARKET RISK - VaRAisyah Vira AmandaNo ratings yet
- Credit Scoring ModelDocument26 pagesCredit Scoring ModelHumayun SabirNo ratings yet
- Credit Risk S3Document47 pagesCredit Risk S3tanmaymehta24No ratings yet
- Model Management Guidance PDFDocument70 pagesModel Management Guidance PDFChen CharlesNo ratings yet
- 1.overview of Basel-I, II III GuidelinesDocument55 pages1.overview of Basel-I, II III Guidelinessathish kumarNo ratings yet
- Predictive Modeling: Project Documentation Team 10Document16 pagesPredictive Modeling: Project Documentation Team 10Eka PonkratovaNo ratings yet
- The Basel II IRB Approach For Credit PortfoliosDocument30 pagesThe Basel II IRB Approach For Credit PortfolioscriscincaNo ratings yet
- Consumer Credit Risk Machine LearningDocument56 pagesConsumer Credit Risk Machine LearningmnbvqwertyNo ratings yet
- Neural Network in Financial AnalysisDocument33 pagesNeural Network in Financial Analysisnp_nikhilNo ratings yet
- Prediction of Company Bankruptcy: Amlan NagDocument16 pagesPrediction of Company Bankruptcy: Amlan NagExpress Business Services100% (2)
- Stress Testing of Banks An IntroductionDocument14 pagesStress Testing of Banks An IntroductionRegards MDNo ratings yet
- Credit Risk ModelingDocument4 pagesCredit Risk ModelingmohamedciaNo ratings yet
- Regression Logistic 4Document51 pagesRegression Logistic 4TofikNo ratings yet
- Introduction To Basel Iii: Implications and ConsequencesDocument26 pagesIntroduction To Basel Iii: Implications and ConsequencesAakashNo ratings yet
- Curves Coefficients Cutoffs@measurments Sensitivity SpecificityDocument66 pagesCurves Coefficients Cutoffs@measurments Sensitivity SpecificityVenkata Nelluri PmpNo ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- Financial Risk Analysis: Great Learning PGPBABI 2017Document25 pagesFinancial Risk Analysis: Great Learning PGPBABI 2017AbhishekNo ratings yet
- Valuaton and Risk Models - Questions and AnswersDocument335 pagesValuaton and Risk Models - Questions and Answerssneha prakash100% (1)
- Fixed Income Securities: Bond Basics: CRICOS Code 00025BDocument43 pagesFixed Income Securities: Bond Basics: CRICOS Code 00025BNurhastuty WardhanyNo ratings yet
- Credit Risk ModelingDocument213 pagesCredit Risk Modelinghsk1No ratings yet
- Introduction To Value-at-Risk PDFDocument10 pagesIntroduction To Value-at-Risk PDFHasan SadozyeNo ratings yet
- Bias and Variance in Machine Learning - JavatpointDocument6 pagesBias and Variance in Machine Learning - JavatpointFriendlyarmMini100% (2)
- Explainable Ai in Credit Risk ManagementDocument16 pagesExplainable Ai in Credit Risk ManagementElvan ChangNo ratings yet
- Core Risks in BankingDocument52 pagesCore Risks in BankingSoloymanNo ratings yet
- CMA FRTB Banks Regulatory Capital Calculations Just Got More Complicated AgainDocument18 pagesCMA FRTB Banks Regulatory Capital Calculations Just Got More Complicated AgainDependra KhatiNo ratings yet
- The Basel Ii "Use Test" - a Retail Credit Approach: Developing and Implementing Effective Retail Credit Risk Strategies Using Basel IiFrom EverandThe Basel Ii "Use Test" - a Retail Credit Approach: Developing and Implementing Effective Retail Credit Risk Strategies Using Basel IiNo ratings yet
- Demand Forecasting On Colour Television Industry - by VASIM S. SHAIKHDocument9 pagesDemand Forecasting On Colour Television Industry - by VASIM S. SHAIKHvasims7162No ratings yet
- Hypothesis Testing : Z-Test, T-Test, F-TestDocument42 pagesHypothesis Testing : Z-Test, T-Test, F-TestViren TrivediNo ratings yet
- SWE622 Lecture 3 ClassificationDocument57 pagesSWE622 Lecture 3 ClassificationLamiaNo ratings yet
- Co5 - Hypothesis Testing (One Sample)Document88 pagesCo5 - Hypothesis Testing (One Sample)RFSNo ratings yet
- One-Way Repeated Measures ANOVA Test ExampleDocument9 pagesOne-Way Repeated Measures ANOVA Test ExampleFranzon MelecioNo ratings yet
- Factor Analysis: Nazia Qayyum SAP ID 48541Document34 pagesFactor Analysis: Nazia Qayyum SAP ID 48541Academic Committe100% (1)
- Prediction Is A Key Task of StatisticsDocument18 pagesPrediction Is A Key Task of StatisticsadmirodebritoNo ratings yet
- Regression Analysis For Cost ModellingDocument25 pagesRegression Analysis For Cost ModellingChivantha SamarajiwaNo ratings yet
- Quality Certificate For Low Range Alkalinity Chemkey - Revision 2Document1 pageQuality Certificate For Low Range Alkalinity Chemkey - Revision 2cristi5cNo ratings yet
- 2019 3 Ked KtekDocument2 pages2019 3 Ked KtekMelody OngNo ratings yet
- STQS4113 Set1 Sem 1 2020/2021: Discriminant Analysis in Banking DataDocument12 pagesSTQS4113 Set1 Sem 1 2020/2021: Discriminant Analysis in Banking DataNorylyn Ebid CabanitNo ratings yet
- Civil and Environmental Engineering Reports: Hedonic Pricing Model For Real Property Valuation Via Gis - A ReviewDocument14 pagesCivil and Environmental Engineering Reports: Hedonic Pricing Model For Real Property Valuation Via Gis - A ReviewFehim SeidNo ratings yet
- Lecture Notes 20 AslDocument3 pagesLecture Notes 20 AslJamiraNo ratings yet
- January 2017 QPDocument15 pagesJanuary 2017 QPAFRAH ANEESNo ratings yet
- Syllabus: Department of Mechanical EngineeringDocument2 pagesSyllabus: Department of Mechanical EngineeringChhagan kharolNo ratings yet
- Operations Management: William J. StevensonDocument36 pagesOperations Management: William J. Stevensonshivakumar N67% (3)
- LO3 - TASK 2&3: Statistics and Financial DecisionsDocument10 pagesLO3 - TASK 2&3: Statistics and Financial DecisionsOmar El-TalNo ratings yet
- Feb 17, 2019 MMW SCC Handout Least Squares LineDocument4 pagesFeb 17, 2019 MMW SCC Handout Least Squares LineRey Marion CabagNo ratings yet
- 5 Types Regression in 45 Lines of CodeDocument43 pages5 Types Regression in 45 Lines of CodeTeto Schedule100% (1)
- MS29P TutorialQuestionsForecastingDocument3 pagesMS29P TutorialQuestionsForecastingSolar ProNo ratings yet
- Ch04 ClassProblemsDocument11 pagesCh04 ClassProblemsPrecious Dayanan IINo ratings yet
- Final Exam - ISE 2019Document11 pagesFinal Exam - ISE 2019Dương Nguyễn Tùng PhươngNo ratings yet
- Assignment-2 - JawabanDocument5 pagesAssignment-2 - Jawabanhemarubini96No ratings yet
- Noc20-Cs28 Week 07 Assignment 02Document6 pagesNoc20-Cs28 Week 07 Assignment 02Praveen Urs RNo ratings yet
- Analisis Tingkat Suku Bunga Deposito Berjangka Dan Minat Nasabah Terhadap Jumlah Dana Deposito BerjangkaDocument10 pagesAnalisis Tingkat Suku Bunga Deposito Berjangka Dan Minat Nasabah Terhadap Jumlah Dana Deposito BerjangkaAni SusantiNo ratings yet
- Chapter 11 Factorial ANOVADocument32 pagesChapter 11 Factorial ANOVALis GuziNo ratings yet
- Parametric and Non Parametric TestsDocument37 pagesParametric and Non Parametric TestsManoj KumarNo ratings yet
- Internals AnswersDocument53 pagesInternals AnswersHarish KumarNo ratings yet
- MODULE 27 Two Sample T-Tests When Variances Unequal 19 July 05Document15 pagesMODULE 27 Two Sample T-Tests When Variances Unequal 19 July 05jainaastha28_1951858No ratings yet














































































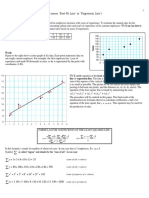











Download as pdf or txt
You might also like
- EXL Acquisition Scorecard Reject Inference MethodologiesDocument13 pagesEXL Acquisition Scorecard Reject Inference MethodologiesTathagata MaityNo ratings yet
- Comparison of Modeling Methods For Loss Given DefaultDocument14 pagesComparison of Modeling Methods For Loss Given DefaultAnnNo ratings yet
- Ifrs 9 Ecl Template General ApproachDocument2 pagesIfrs 9 Ecl Template General ApproachTousief NaqviNo ratings yet
- Topquants: Modelling Liquidity Risk: Mortgage ExampleDocument22 pagesTopquants: Modelling Liquidity Risk: Mortgage ExampleAlberto EstanesNo ratings yet
- Guide To ACF PACF PlotsDocument6 pagesGuide To ACF PACF Plotsajax_telamonioNo ratings yet
- Credit Risk Modelling - A PrimerDocument42 pagesCredit Risk Modelling - A PrimersatishdwnldNo ratings yet
- Market Risk Questions PDFDocument16 pagesMarket Risk Questions PDFbabubhagoud1983No ratings yet
- ML SasDocument17 pagesML SasmartdiazNo ratings yet
- MASH Multiple Regression RDocument5 pagesMASH Multiple Regression Rsheilaabad8766No ratings yet
- Credit Risk Estimation TechniquesDocument31 pagesCredit Risk Estimation TechniquesHanumantha Rao Turlapati0% (1)
- Using Logistic Regression Predict Credit DefaultDocument6 pagesUsing Logistic Regression Predict Credit DefaultSneha SinghNo ratings yet
- Modelling Credit RiskDocument27 pagesModelling Credit RiskPuneet SawhneyNo ratings yet
- Forecasting Default With The KMV-Merton ModelDocument35 pagesForecasting Default With The KMV-Merton ModelEdgardo Garcia MartinezNo ratings yet
- Credit Risk ModellingDocument28 pagesCredit Risk ModellingAnjali VermaNo ratings yet
- Bank Stress Testing A Stochastic Simulation FramewDocument51 pagesBank Stress Testing A Stochastic Simulation FramewmehNo ratings yet
- Credit Risk Mgmt. at ICICIDocument60 pagesCredit Risk Mgmt. at ICICIRikesh Daliya100% (1)
- Using SAS For Effective Credit Risk ManagementDocument10 pagesUsing SAS For Effective Credit Risk ManagementaminiotisNo ratings yet
- Credit Risk Analysis Applying Logistic Regression, Neural Networks and Genetic Algorithms ModelsDocument12 pagesCredit Risk Analysis Applying Logistic Regression, Neural Networks and Genetic Algorithms ModelsIJAERS JOURNALNo ratings yet
- Credit Risk Modeling New - New1Document41 pagesCredit Risk Modeling New - New1aminat oseniNo ratings yet
- Value at RiskDocument4 pagesValue at RiskShubham PariharNo ratings yet
- Calculation of Expected and Unexpected Losses in Operational RiskDocument10 pagesCalculation of Expected and Unexpected Losses in Operational RiskJabberwockkidNo ratings yet
- Merton PD ModelDocument6 pagesMerton PD Modelapi-223061586No ratings yet
- Credit Risk CalculatorDocument4 pagesCredit Risk CalculatorarsinhaNo ratings yet
- Presentation On Value at RiskDocument22 pagesPresentation On Value at RiskRomaMakhijaNo ratings yet
- Standardized Approach For Counterparty Credit RiskDocument2 pagesStandardized Approach For Counterparty Credit RiskjalutukNo ratings yet
- Expected Shortfall - An Alternative Risk Measure To Value-At-RiskDocument14 pagesExpected Shortfall - An Alternative Risk Measure To Value-At-Risksirj0_hnNo ratings yet
- Logistic RegressionDocument24 pagesLogistic RegressionVeerpal KhairaNo ratings yet
- Credit Risk Modeling in Python Chapter4Document35 pagesCredit Risk Modeling in Python Chapter4FgpeqwNo ratings yet
- Basel Implementation Issues PDFDocument16 pagesBasel Implementation Issues PDFOsama AzNo ratings yet
- Risk Management: Basel Committee On Banking Supervision (BCBS)Document25 pagesRisk Management: Basel Committee On Banking Supervision (BCBS)Shirsendu Bikash DasNo ratings yet
- Asset and Liability ManagementDocument17 pagesAsset and Liability ManagementkavyapbNo ratings yet
- Enterprise Credit Risk Evaluation Based On Neural Network AlgorithmDocument8 pagesEnterprise Credit Risk Evaluation Based On Neural Network AlgorithmJorge Luis SorianoNo ratings yet
- CH 5 MARKET RISK - VaRDocument29 pagesCH 5 MARKET RISK - VaRAisyah Vira AmandaNo ratings yet
- Credit Scoring ModelDocument26 pagesCredit Scoring ModelHumayun SabirNo ratings yet
- Credit Risk S3Document47 pagesCredit Risk S3tanmaymehta24No ratings yet
- Model Management Guidance PDFDocument70 pagesModel Management Guidance PDFChen CharlesNo ratings yet
- 1.overview of Basel-I, II III GuidelinesDocument55 pages1.overview of Basel-I, II III Guidelinessathish kumarNo ratings yet
- Predictive Modeling: Project Documentation Team 10Document16 pagesPredictive Modeling: Project Documentation Team 10Eka PonkratovaNo ratings yet
- The Basel II IRB Approach For Credit PortfoliosDocument30 pagesThe Basel II IRB Approach For Credit PortfolioscriscincaNo ratings yet
- Consumer Credit Risk Machine LearningDocument56 pagesConsumer Credit Risk Machine LearningmnbvqwertyNo ratings yet
- Neural Network in Financial AnalysisDocument33 pagesNeural Network in Financial Analysisnp_nikhilNo ratings yet
- Prediction of Company Bankruptcy: Amlan NagDocument16 pagesPrediction of Company Bankruptcy: Amlan NagExpress Business Services100% (2)
- Stress Testing of Banks An IntroductionDocument14 pagesStress Testing of Banks An IntroductionRegards MDNo ratings yet
- Credit Risk ModelingDocument4 pagesCredit Risk ModelingmohamedciaNo ratings yet
- Regression Logistic 4Document51 pagesRegression Logistic 4TofikNo ratings yet
- Introduction To Basel Iii: Implications and ConsequencesDocument26 pagesIntroduction To Basel Iii: Implications and ConsequencesAakashNo ratings yet
- Curves Coefficients Cutoffs@measurments Sensitivity SpecificityDocument66 pagesCurves Coefficients Cutoffs@measurments Sensitivity SpecificityVenkata Nelluri PmpNo ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- Financial Risk Analysis: Great Learning PGPBABI 2017Document25 pagesFinancial Risk Analysis: Great Learning PGPBABI 2017AbhishekNo ratings yet
- Valuaton and Risk Models - Questions and AnswersDocument335 pagesValuaton and Risk Models - Questions and Answerssneha prakash100% (1)
- Fixed Income Securities: Bond Basics: CRICOS Code 00025BDocument43 pagesFixed Income Securities: Bond Basics: CRICOS Code 00025BNurhastuty WardhanyNo ratings yet
- Credit Risk ModelingDocument213 pagesCredit Risk Modelinghsk1No ratings yet
- Introduction To Value-at-Risk PDFDocument10 pagesIntroduction To Value-at-Risk PDFHasan SadozyeNo ratings yet
- Bias and Variance in Machine Learning - JavatpointDocument6 pagesBias and Variance in Machine Learning - JavatpointFriendlyarmMini100% (2)
- Explainable Ai in Credit Risk ManagementDocument16 pagesExplainable Ai in Credit Risk ManagementElvan ChangNo ratings yet
- Core Risks in BankingDocument52 pagesCore Risks in BankingSoloymanNo ratings yet
- CMA FRTB Banks Regulatory Capital Calculations Just Got More Complicated AgainDocument18 pagesCMA FRTB Banks Regulatory Capital Calculations Just Got More Complicated AgainDependra KhatiNo ratings yet
- The Basel Ii "Use Test" - a Retail Credit Approach: Developing and Implementing Effective Retail Credit Risk Strategies Using Basel IiFrom EverandThe Basel Ii "Use Test" - a Retail Credit Approach: Developing and Implementing Effective Retail Credit Risk Strategies Using Basel IiNo ratings yet
- Demand Forecasting On Colour Television Industry - by VASIM S. SHAIKHDocument9 pagesDemand Forecasting On Colour Television Industry - by VASIM S. SHAIKHvasims7162No ratings yet
- Hypothesis Testing : Z-Test, T-Test, F-TestDocument42 pagesHypothesis Testing : Z-Test, T-Test, F-TestViren TrivediNo ratings yet
- SWE622 Lecture 3 ClassificationDocument57 pagesSWE622 Lecture 3 ClassificationLamiaNo ratings yet
- Co5 - Hypothesis Testing (One Sample)Document88 pagesCo5 - Hypothesis Testing (One Sample)RFSNo ratings yet
- One-Way Repeated Measures ANOVA Test ExampleDocument9 pagesOne-Way Repeated Measures ANOVA Test ExampleFranzon MelecioNo ratings yet
- Factor Analysis: Nazia Qayyum SAP ID 48541Document34 pagesFactor Analysis: Nazia Qayyum SAP ID 48541Academic Committe100% (1)
- Prediction Is A Key Task of StatisticsDocument18 pagesPrediction Is A Key Task of StatisticsadmirodebritoNo ratings yet
- Regression Analysis For Cost ModellingDocument25 pagesRegression Analysis For Cost ModellingChivantha SamarajiwaNo ratings yet
- Quality Certificate For Low Range Alkalinity Chemkey - Revision 2Document1 pageQuality Certificate For Low Range Alkalinity Chemkey - Revision 2cristi5cNo ratings yet
- 2019 3 Ked KtekDocument2 pages2019 3 Ked KtekMelody OngNo ratings yet
- STQS4113 Set1 Sem 1 2020/2021: Discriminant Analysis in Banking DataDocument12 pagesSTQS4113 Set1 Sem 1 2020/2021: Discriminant Analysis in Banking DataNorylyn Ebid CabanitNo ratings yet
- Civil and Environmental Engineering Reports: Hedonic Pricing Model For Real Property Valuation Via Gis - A ReviewDocument14 pagesCivil and Environmental Engineering Reports: Hedonic Pricing Model For Real Property Valuation Via Gis - A ReviewFehim SeidNo ratings yet
- Lecture Notes 20 AslDocument3 pagesLecture Notes 20 AslJamiraNo ratings yet
- January 2017 QPDocument15 pagesJanuary 2017 QPAFRAH ANEESNo ratings yet
- Syllabus: Department of Mechanical EngineeringDocument2 pagesSyllabus: Department of Mechanical EngineeringChhagan kharolNo ratings yet
- Operations Management: William J. StevensonDocument36 pagesOperations Management: William J. Stevensonshivakumar N67% (3)
- LO3 - TASK 2&3: Statistics and Financial DecisionsDocument10 pagesLO3 - TASK 2&3: Statistics and Financial DecisionsOmar El-TalNo ratings yet
- Feb 17, 2019 MMW SCC Handout Least Squares LineDocument4 pagesFeb 17, 2019 MMW SCC Handout Least Squares LineRey Marion CabagNo ratings yet
- 5 Types Regression in 45 Lines of CodeDocument43 pages5 Types Regression in 45 Lines of CodeTeto Schedule100% (1)
- MS29P TutorialQuestionsForecastingDocument3 pagesMS29P TutorialQuestionsForecastingSolar ProNo ratings yet
- Ch04 ClassProblemsDocument11 pagesCh04 ClassProblemsPrecious Dayanan IINo ratings yet
- Final Exam - ISE 2019Document11 pagesFinal Exam - ISE 2019Dương Nguyễn Tùng PhươngNo ratings yet
- Assignment-2 - JawabanDocument5 pagesAssignment-2 - Jawabanhemarubini96No ratings yet
- Noc20-Cs28 Week 07 Assignment 02Document6 pagesNoc20-Cs28 Week 07 Assignment 02Praveen Urs RNo ratings yet
- Analisis Tingkat Suku Bunga Deposito Berjangka Dan Minat Nasabah Terhadap Jumlah Dana Deposito BerjangkaDocument10 pagesAnalisis Tingkat Suku Bunga Deposito Berjangka Dan Minat Nasabah Terhadap Jumlah Dana Deposito BerjangkaAni SusantiNo ratings yet
- Chapter 11 Factorial ANOVADocument32 pagesChapter 11 Factorial ANOVALis GuziNo ratings yet
- Parametric and Non Parametric TestsDocument37 pagesParametric and Non Parametric TestsManoj KumarNo ratings yet
- Internals AnswersDocument53 pagesInternals AnswersHarish KumarNo ratings yet
- MODULE 27 Two Sample T-Tests When Variances Unequal 19 July 05Document15 pagesMODULE 27 Two Sample T-Tests When Variances Unequal 19 July 05jainaastha28_1951858No ratings yet