
MODULE 3 - Question &answer-2
MODULE 3 - Question &answer-2
You might also like
- iOS Forensics For InvestigatorsDocument317 pagesiOS Forensics For Investigatorsb-elhadjhotmail.fr100% (2)
- Assignment 03Document9 pagesAssignment 03dilhaniNo ratings yet
- Sports Management System Mini Project - I: Submitted byDocument59 pagesSports Management System Mini Project - I: Submitted by19MSS041 Selva ganapathy KNo ratings yet
- ContentsDocument59 pagesContentsanchalNo ratings yet
- Association Analysis: Unit-VDocument12 pagesAssociation Analysis: Unit-VPradeepkumar 05No ratings yet
- Unit 4 - Association AnalysisDocument12 pagesUnit 4 - Association Analysiseskpg066No ratings yet
- UNIT-5 DWDM (Data Warehousing and Data Mining) Association AnalysisDocument7 pagesUNIT-5 DWDM (Data Warehousing and Data Mining) Association AnalysisVee BeatNo ratings yet
- Unit 4 - Association AnalysisDocument12 pagesUnit 4 - Association AnalysisAnand Kumar BhagatNo ratings yet
- Association RulesDocument48 pagesAssociation RulesDev kartik AgarwalNo ratings yet
- Association Analysis: Basic Concepts and Algorithms: Problem DefinitionDocument15 pagesAssociation Analysis: Basic Concepts and Algorithms: Problem DefinitionGODDU NAVVEN BABUNo ratings yet
- Text Categorization Using Association Rule and Naïve Bayes ClassifierDocument9 pagesText Categorization Using Association Rule and Naïve Bayes ClassifierUnmesh PhalakNo ratings yet
- Unit-5 DWDMDocument7 pagesUnit-5 DWDMsanjayktNo ratings yet
- Unit 2 Question and Answers BdhdnsDocument15 pagesUnit 2 Question and Answers Bdhdnstagullajayanth72No ratings yet
- UNITDocument53 pagesUNITSravani GunnuNo ratings yet
- 08 Association AnalysisDocument63 pages08 Association AnalysisOscar WongNo ratings yet
- Data Mining: Concepts and Techniques: Mining Association Rules in Large DatabasesDocument81 pagesData Mining: Concepts and Techniques: Mining Association Rules in Large DatabasessunnynnusNo ratings yet
- CH - 5Document43 pagesCH - 5PIYUSH MANGILAL SONINo ratings yet
- I. Review Questions Chapter 4: Mining Frequent Patterns, Associations, Ad CorelationsDocument19 pagesI. Review Questions Chapter 4: Mining Frequent Patterns, Associations, Ad CorelationsVivek JDNo ratings yet
- Association Rule: Association Rule Learning Is A Popular and Well Researched Method For DiscoveringDocument10 pagesAssociation Rule: Association Rule Learning Is A Popular and Well Researched Method For DiscoveringsskaleesNo ratings yet
- Experiment No - 08: AIM: Implementation of Association Rule Mining in WEKA. TheoryDocument11 pagesExperiment No - 08: AIM: Implementation of Association Rule Mining in WEKA. TheoryMIHIR PATELNo ratings yet
- CH-4 Mining Association RulesDocument35 pagesCH-4 Mining Association Rulesaddis alemayhuNo ratings yet
- Unit 3 FinalDocument13 pagesUnit 3 FinalSOORAJ CHANDRANNo ratings yet
- Association RuleDocument27 pagesAssociation RulePradeep KeshwaniNo ratings yet
- 06 Association RulesDocument32 pages06 Association RulessamiaNo ratings yet
- Frequent Patterns Are PatternsDocument1 pageFrequent Patterns Are PatternsDeepakNo ratings yet
- Data Mining Question BankDocument3 pagesData Mining Question Bankravi3754100% (1)
- Eliminating Redundant Frequent Pattern S in Non - Taxonomy Data SetsDocument5 pagesEliminating Redundant Frequent Pattern S in Non - Taxonomy Data Setseditor_ijarcsseNo ratings yet
- DWDM Unit-4Document27 pagesDWDM Unit-4Gopl KuppaNo ratings yet
- Association Rules and Market Basket Analysis: Knowledge Discovery & Data MiningDocument64 pagesAssociation Rules and Market Basket Analysis: Knowledge Discovery & Data MiningmorlengNo ratings yet
- Data Mining-Knowledge Presentation 2: Prof. Sin-Min LeeDocument54 pagesData Mining-Knowledge Presentation 2: Prof. Sin-Min LeedilluNo ratings yet
- Data Cube Computation and Data GenerationDocument54 pagesData Cube Computation and Data GenerationYiu Keung LiNo ratings yet
- Data Analytics Unit 4Document22 pagesData Analytics Unit 4Aditi JaiswalNo ratings yet
- A TestDocument7 pagesA TestJimmy HuynhNo ratings yet
- Mining Associans in Large Data Bases (Unit-5)Document12 pagesMining Associans in Large Data Bases (Unit-5)Kushal settulariNo ratings yet
- Assignment ON Data Mining: Submitted by Name: Manjula.TDocument11 pagesAssignment ON Data Mining: Submitted by Name: Manjula.TLõvey Dôvey ÃnanthNo ratings yet
- Apriori AlgorithmDocument19 pagesApriori AlgorithmYara SwaisaNo ratings yet
- Mining Frequent Patterns, Associations, and Correlations: Basic Concepts and MethodsDocument12 pagesMining Frequent Patterns, Associations, and Correlations: Basic Concepts and MethodsHitesh SalujaNo ratings yet
- Chap6 Basic Association Analysis-2016Document32 pagesChap6 Basic Association Analysis-2016Riskaa PriciliaNo ratings yet
- Mining Frequent Itemsets Using Apriori AlgorithmDocument5 pagesMining Frequent Itemsets Using Apriori AlgorithmseventhsensegroupNo ratings yet
- Unit 4 - Data Mining - WWW - Rgpvnotes.inDocument12 pagesUnit 4 - Data Mining - WWW - Rgpvnotes.inVijendra Singh RathoreNo ratings yet
- A New Efficient Matrix Based Frequent Itemset Mining Algorithm With TagsDocument4 pagesA New Efficient Matrix Based Frequent Itemset Mining Algorithm With Tagshnoor6No ratings yet
- Basic Association RulesDocument12 pagesBasic Association Rulesem01803257No ratings yet
- Module 3 DM Notes For 2nd InternalsDocument16 pagesModule 3 DM Notes For 2nd Internalsxekaki3647No ratings yet
- DM Unit-IIDocument80 pagesDM Unit-IILaxmiNo ratings yet
- Interesting Measures For Mining Association Rules: FAST-NUCES, LahoreDocument4 pagesInteresting Measures For Mining Association Rules: FAST-NUCES, LahoreJean SorelNo ratings yet
- Mining Frequent Itemset-Association AnalysisDocument59 pagesMining Frequent Itemset-Association AnalysisSandeep DwivediNo ratings yet
- DWDM Unit 3 PDFDocument16 pagesDWDM Unit 3 PDFindiraNo ratings yet
- Chapter 3Document27 pagesChapter 3Bikila SeketaNo ratings yet
- Efficient Frequent Itemset Mining Mechanism Using Support CountDocument7 pagesEfficient Frequent Itemset Mining Mechanism Using Support CountInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Unit 2Document14 pagesUnit 2Vasudevarao PeyyetiNo ratings yet
- DWM Unit-4Document52 pagesDWM Unit-4divyaneelam175No ratings yet
- Lesson 8 Association RulesDocument58 pagesLesson 8 Association RulesJohn QuiniaNo ratings yet
- Mining: Association RulesDocument54 pagesMining: Association Rulesanon_947471502No ratings yet
- Unit 3 - DM FULLDocument46 pagesUnit 3 - DM FULLmintoNo ratings yet
- Lecture 4 - Wednesday, August 29, 2007: Support (A B) Support (A)Document5 pagesLecture 4 - Wednesday, August 29, 2007: Support (A B) Support (A)avishake_608726049No ratings yet
- Datamining Fifth LectureDocument65 pagesDatamining Fifth LecturepoonamNo ratings yet
- Design and Implementation of Efficient APRIORI AlgorithmDocument4 pagesDesign and Implementation of Efficient APRIORI Algorithmsigma70egNo ratings yet
- Unit - 5 Machine LearningDocument72 pagesUnit - 5 Machine LearningAbhishekNo ratings yet
- DWM Unit 2Document4 pagesDWM Unit 2Vijay KrishNo ratings yet
- The Nuts and Bolts of Proofs: An Introduction to Mathematical ProofsFrom EverandThe Nuts and Bolts of Proofs: An Introduction to Mathematical ProofsRating: 4.5 out of 5 stars4.5/5 (2)
- Module 5Document48 pagesModule 5Vaishnavi G . RaoNo ratings yet
- Module 4 - 1-43Document43 pagesModule 4 - 1-43Vaishnavi G . RaoNo ratings yet
- Module 4Document59 pagesModule 4Vaishnavi G . RaoNo ratings yet
- Module5 QB 1Document21 pagesModule5 QB 1Vaishnavi G . RaoNo ratings yet
- Module4 QB 1Document26 pagesModule4 QB 1Vaishnavi G . RaoNo ratings yet
- Module1-Question Bank With Answers (1) - 2Document23 pagesModule1-Question Bank With Answers (1) - 2Vaishnavi G . RaoNo ratings yet
- DMDW Module-2 Q+A Banks-1Document32 pagesDMDW Module-2 Q+A Banks-1Vaishnavi G . RaoNo ratings yet
- DMDW Module-2 Q+A Banks-Pages-1-13-2Document13 pagesDMDW Module-2 Q+A Banks-Pages-1-13-2Vaishnavi G . RaoNo ratings yet
- Software Testing Lab Manual Final - Updated - 29.4.22Document79 pagesSoftware Testing Lab Manual Final - Updated - 29.4.22Vaishnavi G . RaoNo ratings yet
- MODULE-01Document17 pagesMODULE-01Vaishnavi G . RaoNo ratings yet
- MAD Mod1-5@AzDOCUMENTS - inDocument137 pagesMAD Mod1-5@AzDOCUMENTS - inVaishnavi G . RaoNo ratings yet
- Roadmap 2024 GenaiDocument17 pagesRoadmap 2024 GenaivinusmilesNo ratings yet
- Tugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Document18 pagesTugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Axel UrsiaNo ratings yet
- Data Structures and AlgorithmsDocument41 pagesData Structures and AlgorithmsMatthew TedunjaiyeNo ratings yet
- Nir Index Tables - CSVDocument4 pagesNir Index Tables - CSVPedro PereiraNo ratings yet
- School of Innovative Technologies and Engineering (SITE)Document5 pagesSchool of Innovative Technologies and Engineering (SITE)covaNo ratings yet
- BSIT2E Assignment - Adonis P. SarmientoDocument2 pagesBSIT2E Assignment - Adonis P. SarmientoMark StewartNo ratings yet
- SDE PraritaDocument3 pagesSDE PraritaSrz Creations0% (1)
- Linq PDFDocument17 pagesLinq PDFAbdulla NofalNo ratings yet
- DWDM Lab Manual Final As On 09-04-2021 R18Document88 pagesDWDM Lab Manual Final As On 09-04-2021 R18vishnavi vishuNo ratings yet
- 30k S4hana2022 BPD en XXDocument10 pages30k S4hana2022 BPD en XXRoberto De FlumeriNo ratings yet
- Generate .MDB File For Beam Old EtabsDocument4 pagesGenerate .MDB File For Beam Old EtabsANUJ SHAHNo ratings yet
- Powercenter 8.X New Features: Education ServicesDocument159 pagesPowercenter 8.X New Features: Education Servicessambit76No ratings yet
- Atm System 1Document50 pagesAtm System 1Anjali KumavatNo ratings yet
- SAP BW Modelling, Extraction and ReportingDocument49 pagesSAP BW Modelling, Extraction and ReportingArijit ChandaNo ratings yet
- Udemy, Inc. Is An American Massive Open OnlineDocument39 pagesUdemy, Inc. Is An American Massive Open OnlineSuraj KingNo ratings yet
- SIEM Deck - BlogDocument12 pagesSIEM Deck - BlogKuldeep SuranaNo ratings yet
- Import Sympy as-WPS OfficeDocument2 pagesImport Sympy as-WPS OfficeCaleb KOIDIMANo ratings yet
- Data Engineering With DBT (2023)Document615 pagesData Engineering With DBT (2023)Eduardo LeytonNo ratings yet
- Xii Preboard1 QP Set ADocument10 pagesXii Preboard1 QP Set ARishika VermaNo ratings yet
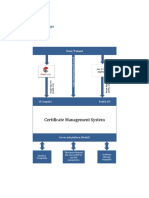
- Certificate ManagerDocument4 pagesCertificate ManagerCWF - AADHYA .ecosecretzNo ratings yet
- PLSQL 4.2 Practice AnswerDocument6 pagesPLSQL 4.2 Practice AnswerRakha FaturahmanNo ratings yet
- Contoh Proposal SkripsiDocument40 pagesContoh Proposal SkripsiOlivia GosandraNo ratings yet
- Archive - Ics.uci - Edu ML Machine Learning Databases Lung Cancer Lung Cancer1Document1 pageArchive - Ics.uci - Edu ML Machine Learning Databases Lung Cancer Lung Cancer1priyankaNo ratings yet
- Charu Jain 925-350-6704 Professional SummaryDocument4 pagesCharu Jain 925-350-6704 Professional SummaryxovoNo ratings yet
- CUCM Datadictionary 861Document945 pagesCUCM Datadictionary 861Amit KumarNo ratings yet
- Bank Statement Template 29Document97 pagesBank Statement Template 29skhushbusahniNo ratings yet
- Aws Reference Architecture Multi Region Cloudfront Api Gateway RaDocument1 pageAws Reference Architecture Multi Region Cloudfront Api Gateway RaCoco LuluNo ratings yet
- ApacheSim Ver 6 - 0 Session A Web Training Notes Rev0Document24 pagesApacheSim Ver 6 - 0 Session A Web Training Notes Rev0cata0407No ratings yet




































































































Download as pdf or txt
You might also like
- iOS Forensics For InvestigatorsDocument317 pagesiOS Forensics For Investigatorsb-elhadjhotmail.fr100% (2)
- Assignment 03Document9 pagesAssignment 03dilhaniNo ratings yet
- Sports Management System Mini Project - I: Submitted byDocument59 pagesSports Management System Mini Project - I: Submitted by19MSS041 Selva ganapathy KNo ratings yet
- ContentsDocument59 pagesContentsanchalNo ratings yet
- Association Analysis: Unit-VDocument12 pagesAssociation Analysis: Unit-VPradeepkumar 05No ratings yet
- Unit 4 - Association AnalysisDocument12 pagesUnit 4 - Association Analysiseskpg066No ratings yet
- UNIT-5 DWDM (Data Warehousing and Data Mining) Association AnalysisDocument7 pagesUNIT-5 DWDM (Data Warehousing and Data Mining) Association AnalysisVee BeatNo ratings yet
- Unit 4 - Association AnalysisDocument12 pagesUnit 4 - Association AnalysisAnand Kumar BhagatNo ratings yet
- Association RulesDocument48 pagesAssociation RulesDev kartik AgarwalNo ratings yet
- Association Analysis: Basic Concepts and Algorithms: Problem DefinitionDocument15 pagesAssociation Analysis: Basic Concepts and Algorithms: Problem DefinitionGODDU NAVVEN BABUNo ratings yet
- Text Categorization Using Association Rule and Naïve Bayes ClassifierDocument9 pagesText Categorization Using Association Rule and Naïve Bayes ClassifierUnmesh PhalakNo ratings yet
- Unit-5 DWDMDocument7 pagesUnit-5 DWDMsanjayktNo ratings yet
- Unit 2 Question and Answers BdhdnsDocument15 pagesUnit 2 Question and Answers Bdhdnstagullajayanth72No ratings yet
- UNITDocument53 pagesUNITSravani GunnuNo ratings yet
- 08 Association AnalysisDocument63 pages08 Association AnalysisOscar WongNo ratings yet
- Data Mining: Concepts and Techniques: Mining Association Rules in Large DatabasesDocument81 pagesData Mining: Concepts and Techniques: Mining Association Rules in Large DatabasessunnynnusNo ratings yet
- CH - 5Document43 pagesCH - 5PIYUSH MANGILAL SONINo ratings yet
- I. Review Questions Chapter 4: Mining Frequent Patterns, Associations, Ad CorelationsDocument19 pagesI. Review Questions Chapter 4: Mining Frequent Patterns, Associations, Ad CorelationsVivek JDNo ratings yet
- Association Rule: Association Rule Learning Is A Popular and Well Researched Method For DiscoveringDocument10 pagesAssociation Rule: Association Rule Learning Is A Popular and Well Researched Method For DiscoveringsskaleesNo ratings yet
- Experiment No - 08: AIM: Implementation of Association Rule Mining in WEKA. TheoryDocument11 pagesExperiment No - 08: AIM: Implementation of Association Rule Mining in WEKA. TheoryMIHIR PATELNo ratings yet
- CH-4 Mining Association RulesDocument35 pagesCH-4 Mining Association Rulesaddis alemayhuNo ratings yet
- Unit 3 FinalDocument13 pagesUnit 3 FinalSOORAJ CHANDRANNo ratings yet
- Association RuleDocument27 pagesAssociation RulePradeep KeshwaniNo ratings yet
- 06 Association RulesDocument32 pages06 Association RulessamiaNo ratings yet
- Frequent Patterns Are PatternsDocument1 pageFrequent Patterns Are PatternsDeepakNo ratings yet
- Data Mining Question BankDocument3 pagesData Mining Question Bankravi3754100% (1)
- Eliminating Redundant Frequent Pattern S in Non - Taxonomy Data SetsDocument5 pagesEliminating Redundant Frequent Pattern S in Non - Taxonomy Data Setseditor_ijarcsseNo ratings yet
- DWDM Unit-4Document27 pagesDWDM Unit-4Gopl KuppaNo ratings yet
- Association Rules and Market Basket Analysis: Knowledge Discovery & Data MiningDocument64 pagesAssociation Rules and Market Basket Analysis: Knowledge Discovery & Data MiningmorlengNo ratings yet
- Data Mining-Knowledge Presentation 2: Prof. Sin-Min LeeDocument54 pagesData Mining-Knowledge Presentation 2: Prof. Sin-Min LeedilluNo ratings yet
- Data Cube Computation and Data GenerationDocument54 pagesData Cube Computation and Data GenerationYiu Keung LiNo ratings yet
- Data Analytics Unit 4Document22 pagesData Analytics Unit 4Aditi JaiswalNo ratings yet
- A TestDocument7 pagesA TestJimmy HuynhNo ratings yet
- Mining Associans in Large Data Bases (Unit-5)Document12 pagesMining Associans in Large Data Bases (Unit-5)Kushal settulariNo ratings yet
- Assignment ON Data Mining: Submitted by Name: Manjula.TDocument11 pagesAssignment ON Data Mining: Submitted by Name: Manjula.TLõvey Dôvey ÃnanthNo ratings yet
- Apriori AlgorithmDocument19 pagesApriori AlgorithmYara SwaisaNo ratings yet
- Mining Frequent Patterns, Associations, and Correlations: Basic Concepts and MethodsDocument12 pagesMining Frequent Patterns, Associations, and Correlations: Basic Concepts and MethodsHitesh SalujaNo ratings yet
- Chap6 Basic Association Analysis-2016Document32 pagesChap6 Basic Association Analysis-2016Riskaa PriciliaNo ratings yet
- Mining Frequent Itemsets Using Apriori AlgorithmDocument5 pagesMining Frequent Itemsets Using Apriori AlgorithmseventhsensegroupNo ratings yet
- Unit 4 - Data Mining - WWW - Rgpvnotes.inDocument12 pagesUnit 4 - Data Mining - WWW - Rgpvnotes.inVijendra Singh RathoreNo ratings yet
- A New Efficient Matrix Based Frequent Itemset Mining Algorithm With TagsDocument4 pagesA New Efficient Matrix Based Frequent Itemset Mining Algorithm With Tagshnoor6No ratings yet
- Basic Association RulesDocument12 pagesBasic Association Rulesem01803257No ratings yet
- Module 3 DM Notes For 2nd InternalsDocument16 pagesModule 3 DM Notes For 2nd Internalsxekaki3647No ratings yet
- DM Unit-IIDocument80 pagesDM Unit-IILaxmiNo ratings yet
- Interesting Measures For Mining Association Rules: FAST-NUCES, LahoreDocument4 pagesInteresting Measures For Mining Association Rules: FAST-NUCES, LahoreJean SorelNo ratings yet
- Mining Frequent Itemset-Association AnalysisDocument59 pagesMining Frequent Itemset-Association AnalysisSandeep DwivediNo ratings yet
- DWDM Unit 3 PDFDocument16 pagesDWDM Unit 3 PDFindiraNo ratings yet
- Chapter 3Document27 pagesChapter 3Bikila SeketaNo ratings yet
- Efficient Frequent Itemset Mining Mechanism Using Support CountDocument7 pagesEfficient Frequent Itemset Mining Mechanism Using Support CountInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Unit 2Document14 pagesUnit 2Vasudevarao PeyyetiNo ratings yet
- DWM Unit-4Document52 pagesDWM Unit-4divyaneelam175No ratings yet
- Lesson 8 Association RulesDocument58 pagesLesson 8 Association RulesJohn QuiniaNo ratings yet
- Mining: Association RulesDocument54 pagesMining: Association Rulesanon_947471502No ratings yet
- Unit 3 - DM FULLDocument46 pagesUnit 3 - DM FULLmintoNo ratings yet
- Lecture 4 - Wednesday, August 29, 2007: Support (A B) Support (A)Document5 pagesLecture 4 - Wednesday, August 29, 2007: Support (A B) Support (A)avishake_608726049No ratings yet
- Datamining Fifth LectureDocument65 pagesDatamining Fifth LecturepoonamNo ratings yet
- Design and Implementation of Efficient APRIORI AlgorithmDocument4 pagesDesign and Implementation of Efficient APRIORI Algorithmsigma70egNo ratings yet
- Unit - 5 Machine LearningDocument72 pagesUnit - 5 Machine LearningAbhishekNo ratings yet
- DWM Unit 2Document4 pagesDWM Unit 2Vijay KrishNo ratings yet
- The Nuts and Bolts of Proofs: An Introduction to Mathematical ProofsFrom EverandThe Nuts and Bolts of Proofs: An Introduction to Mathematical ProofsRating: 4.5 out of 5 stars4.5/5 (2)
- Module 5Document48 pagesModule 5Vaishnavi G . RaoNo ratings yet
- Module 4 - 1-43Document43 pagesModule 4 - 1-43Vaishnavi G . RaoNo ratings yet
- Module 4Document59 pagesModule 4Vaishnavi G . RaoNo ratings yet
- Module5 QB 1Document21 pagesModule5 QB 1Vaishnavi G . RaoNo ratings yet
- Module4 QB 1Document26 pagesModule4 QB 1Vaishnavi G . RaoNo ratings yet
- Module1-Question Bank With Answers (1) - 2Document23 pagesModule1-Question Bank With Answers (1) - 2Vaishnavi G . RaoNo ratings yet
- DMDW Module-2 Q+A Banks-1Document32 pagesDMDW Module-2 Q+A Banks-1Vaishnavi G . RaoNo ratings yet
- DMDW Module-2 Q+A Banks-Pages-1-13-2Document13 pagesDMDW Module-2 Q+A Banks-Pages-1-13-2Vaishnavi G . RaoNo ratings yet
- Software Testing Lab Manual Final - Updated - 29.4.22Document79 pagesSoftware Testing Lab Manual Final - Updated - 29.4.22Vaishnavi G . RaoNo ratings yet
- MODULE-01Document17 pagesMODULE-01Vaishnavi G . RaoNo ratings yet
- MAD Mod1-5@AzDOCUMENTS - inDocument137 pagesMAD Mod1-5@AzDOCUMENTS - inVaishnavi G . RaoNo ratings yet
- Roadmap 2024 GenaiDocument17 pagesRoadmap 2024 GenaivinusmilesNo ratings yet
- Tugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Document18 pagesTugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Axel UrsiaNo ratings yet
- Data Structures and AlgorithmsDocument41 pagesData Structures and AlgorithmsMatthew TedunjaiyeNo ratings yet
- Nir Index Tables - CSVDocument4 pagesNir Index Tables - CSVPedro PereiraNo ratings yet
- School of Innovative Technologies and Engineering (SITE)Document5 pagesSchool of Innovative Technologies and Engineering (SITE)covaNo ratings yet
- BSIT2E Assignment - Adonis P. SarmientoDocument2 pagesBSIT2E Assignment - Adonis P. SarmientoMark StewartNo ratings yet
- SDE PraritaDocument3 pagesSDE PraritaSrz Creations0% (1)
- Linq PDFDocument17 pagesLinq PDFAbdulla NofalNo ratings yet
- DWDM Lab Manual Final As On 09-04-2021 R18Document88 pagesDWDM Lab Manual Final As On 09-04-2021 R18vishnavi vishuNo ratings yet
- 30k S4hana2022 BPD en XXDocument10 pages30k S4hana2022 BPD en XXRoberto De FlumeriNo ratings yet
- Generate .MDB File For Beam Old EtabsDocument4 pagesGenerate .MDB File For Beam Old EtabsANUJ SHAHNo ratings yet
- Powercenter 8.X New Features: Education ServicesDocument159 pagesPowercenter 8.X New Features: Education Servicessambit76No ratings yet
- Atm System 1Document50 pagesAtm System 1Anjali KumavatNo ratings yet
- SAP BW Modelling, Extraction and ReportingDocument49 pagesSAP BW Modelling, Extraction and ReportingArijit ChandaNo ratings yet
- Udemy, Inc. Is An American Massive Open OnlineDocument39 pagesUdemy, Inc. Is An American Massive Open OnlineSuraj KingNo ratings yet
- SIEM Deck - BlogDocument12 pagesSIEM Deck - BlogKuldeep SuranaNo ratings yet
- Import Sympy as-WPS OfficeDocument2 pagesImport Sympy as-WPS OfficeCaleb KOIDIMANo ratings yet
- Data Engineering With DBT (2023)Document615 pagesData Engineering With DBT (2023)Eduardo LeytonNo ratings yet
- Xii Preboard1 QP Set ADocument10 pagesXii Preboard1 QP Set ARishika VermaNo ratings yet
- Certificate ManagerDocument4 pagesCertificate ManagerCWF - AADHYA .ecosecretzNo ratings yet
- PLSQL 4.2 Practice AnswerDocument6 pagesPLSQL 4.2 Practice AnswerRakha FaturahmanNo ratings yet
- Contoh Proposal SkripsiDocument40 pagesContoh Proposal SkripsiOlivia GosandraNo ratings yet
- Archive - Ics.uci - Edu ML Machine Learning Databases Lung Cancer Lung Cancer1Document1 pageArchive - Ics.uci - Edu ML Machine Learning Databases Lung Cancer Lung Cancer1priyankaNo ratings yet
- Charu Jain 925-350-6704 Professional SummaryDocument4 pagesCharu Jain 925-350-6704 Professional SummaryxovoNo ratings yet
- CUCM Datadictionary 861Document945 pagesCUCM Datadictionary 861Amit KumarNo ratings yet
- Bank Statement Template 29Document97 pagesBank Statement Template 29skhushbusahniNo ratings yet
- Aws Reference Architecture Multi Region Cloudfront Api Gateway RaDocument1 pageAws Reference Architecture Multi Region Cloudfront Api Gateway RaCoco LuluNo ratings yet
- ApacheSim Ver 6 - 0 Session A Web Training Notes Rev0Document24 pagesApacheSim Ver 6 - 0 Session A Web Training Notes Rev0cata0407No ratings yet