
Day13 K Means Clustering
Day13 K Means Clustering
You might also like
- 11 Network Analytics - Problem StatementDocument4 pages11 Network Analytics - Problem Statementabhishek kandharkar25% (4)
- Association Rules Problem StatementDocument5 pagesAssociation Rules Problem Statementvinutha50% (2)
- Main KeyDocument4 pagesMain KeykishnaNo ratings yet
- CRISP - ML (Q) - Business UnderstandingDocument17 pagesCRISP - ML (Q) - Business UnderstandingHidayat u PathanNo ratings yet
- 13.exploratory Data AnalysisDocument8 pages13.exploratory Data AnalysisKarthik Peddineni0% (1)
- CRISP - DM - Business UnderstandingDocument17 pagesCRISP - DM - Business UnderstandingRohit PaulNo ratings yet
- Missing ValuesDocument3 pagesMissing ValuesvinuthaNo ratings yet
- Duplication - Typecasting-Problem StatementDocument3 pagesDuplication - Typecasting-Problem Statementvinutha100% (1)
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Business Uderstanding Solved1 - Module 1Document11 pagesBusiness Uderstanding Solved1 - Module 1pooja mukundeNo ratings yet
- Basic Statistics (Module - 3)Document9 pagesBasic Statistics (Module - 3)prudhvi nadimpalliNo ratings yet
- 15 KNN - Problem StatementDocument3 pages15 KNN - Problem Statementabhishek kandharkar0% (2)
- Day10 Mathematical FoundationsDocument4 pagesDay10 Mathematical FoundationskishnaNo ratings yet
- CRISP - ML (Q) - Business UnderstandingDocument13 pagesCRISP - ML (Q) - Business UnderstandingTejas SNo ratings yet
- CRISP ML (Q) Business UnderstandingDocument17 pagesCRISP ML (Q) Business UnderstandingNikesh bobadeNo ratings yet
- Multinomial Problem StatementDocument28 pagesMultinomial Problem StatementMoayadNo ratings yet
- NaiveBayes - Problem StatementDocument5 pagesNaiveBayes - Problem StatementSANKALP ROY0% (1)
- 2a EDADocument11 pages2a EDASUMAN CHAUHANNo ratings yet
- CRISP DM Business Understanding CompletedDocument18 pagesCRISP DM Business Understanding CompletedJaya UjayaNo ratings yet
- Discretization Problem StatementDocument3 pagesDiscretization Problem StatementvinuthaNo ratings yet
- R - AssignmentDocument2 pagesR - AssignmentRavalika PeenamalaNo ratings yet
- CRISP DM Business Understanding - Data ScienceDocument15 pagesCRISP DM Business Understanding - Data ScienceGanesh V GaonkarNo ratings yet
- K-Nearest Neighbors: InstructionsDocument4 pagesK-Nearest Neighbors: Instructionsswapnil karadeNo ratings yet
- Association Rules AnsDocument28 pagesAssociation Rules AnsPriya kambleNo ratings yet
- Preliminaries For Data Analysis: Problem StatementsDocument4 pagesPreliminaries For Data Analysis: Problem StatementsAnakha PrasadNo ratings yet
- CRISP DM Business UnderstandingDocument18 pagesCRISP DM Business UnderstandingRahul SathiyanarayananNo ratings yet
- Statistics and ProbabilityDocument8 pagesStatistics and ProbabilityAlesya alesyaNo ratings yet
- Name: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDADocument13 pagesName: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDAsiti mursyida100% (1)
- Basic Statistics (Module - 3)Document7 pagesBasic Statistics (Module - 3)nehal gundrapallyNo ratings yet
- Assignment Module 1Document3 pagesAssignment Module 1Tejas S100% (1)
- DataPreparation Outlier TreatmentDocument3 pagesDataPreparation Outlier Treatmentonkar diwate100% (1)
- Basic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedDocument3 pagesBasic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedProli PravalikaNo ratings yet
- Assignment 07 AnswersDocument6 pagesAssignment 07 AnswersSamNo ratings yet
- 8.dummy VariablesDocument4 pages8.dummy VariablesSunkari ArikaNo ratings yet
- Module 03 AssignmentDocument13 pagesModule 03 Assignmentsuresh avadutha100% (1)
- Data Assigment 1Document32 pagesData Assigment 1Sukhwinder Kaur100% (2)
- Zero Variance-Problem StatementDocument3 pagesZero Variance-Problem Statementvinutha0% (1)
- Day02-Data Understanding Answer Asit 25082022Document4 pagesDay02-Data Understanding Answer Asit 25082022loveNo ratings yet
- 06.discretization Problem StatementDocument2 pages06.discretization Problem Statementgujan thakur50% (2)
- Assignment Module04 Part1Document5 pagesAssignment Module04 Part1karthik kartiNo ratings yet
- DataPreparation - Outlier - Treatment ASSIGNMENT 1Document7 pagesDataPreparation - Outlier - Treatment ASSIGNMENT 1Hari Machavrapu100% (1)
- Inferential Statistics (AutoRecovered)Document12 pagesInferential Statistics (AutoRecovered)Shariq AnsariNo ratings yet
- Day17 Association RulesDocument4 pagesDay17 Association RulesForeverNo ratings yet
- KNN - Problem Statement ANSWERDocument8 pagesKNN - Problem Statement ANSWERNaga Shiva100% (1)
- OriginalDocument30 pagesOriginalMohanNo ratings yet
- CRISP ML (Q) Business UnderstandingDocument12 pagesCRISP ML (Q) Business UnderstandingTharani vimalaNo ratings yet
- CRISP - ML (Q) - Business Understanding AssignmentDocument11 pagesCRISP - ML (Q) - Business Understanding AssignmentAnakha PrasadNo ratings yet
- Assignment 05 ANSWERSDocument5 pagesAssignment 05 ANSWERSSamNo ratings yet
- Topics: Descriptive Statistics and Probability: Name of Company Measure XDocument4 pagesTopics: Descriptive Statistics and Probability: Name of Company Measure XSimarjeet SinghNo ratings yet
- CRISP DM Business AissgnmentDocument18 pagesCRISP DM Business Aissgnmentharshu rathiNo ratings yet
- Name:Silpa Batch Id: Analysis: WDEO 171220 Topic: Principal ComponentDocument7 pagesName:Silpa Batch Id: Analysis: WDEO 171220 Topic: Principal ComponentSravani Adapa100% (1)
- Hypothesis Testing - Problem StatementDocument4 pagesHypothesis Testing - Problem StatementAlesya alesyaNo ratings yet
- Topic: Dimension Reduction With PCA: InstructionsDocument8 pagesTopic: Dimension Reduction With PCA: InstructionsAlesya alesyaNo ratings yet
- 1b.data UnderstandingDocument4 pages1b.data Understandingmanasa reddyNo ratings yet
- CRISP DM Business UnderstandingDocument17 pagesCRISP DM Business UnderstandingkeerthiNo ratings yet
- 01.CRISP DM Business UnderstandingDocument10 pages01.CRISP DM Business UnderstandingLovleen MissonNo ratings yet
- 7 K-Means ClusteringDocument4 pages7 K-Means ClusteringArvind Kumar Yadav0% (1)
- Day13-K-Means ClusteringDocument10 pagesDay13-K-Means ClusteringSBS MoviesNo ratings yet
- Ensemble ModelsfDocument7 pagesEnsemble ModelsfTejaNo ratings yet
- Day14-PCA - Problem StatementDocument4 pagesDay14-PCA - Problem StatementPriya kamble0% (1)
- Association Rules AnsDocument28 pagesAssociation Rules AnsPriya kambleNo ratings yet
- Day14-PCA - Problem StatementDocument4 pagesDay14-PCA - Problem StatementPriya kamble0% (1)
- Pythonwith Spyder An Experiential Learning PerspectiveDocument230 pagesPythonwith Spyder An Experiential Learning PerspectivePriya kambleNo ratings yet
- Assignment 4 SolutionsDocument2 pagesAssignment 4 SolutionsPriya kambleNo ratings yet
- Difference Between Star Schema and Snowflake SchemaDocument6 pagesDifference Between Star Schema and Snowflake SchemaPriya kambleNo ratings yet
- TransformationsDocument6 pagesTransformationsPriya kambleNo ratings yet
- DatastageDocument50 pagesDatastagePriya kambleNo ratings yet
- Comparison of QlikView, Tableau and Power BIDocument13 pagesComparison of QlikView, Tableau and Power BIPriya kambleNo ratings yet
- Data Warehouse VS Data MiningDocument7 pagesData Warehouse VS Data MiningPriya kambleNo ratings yet
- Assignment 1 (R Programming)Document24 pagesAssignment 1 (R Programming)Priya kambleNo ratings yet
- Interview PreparationDocument2 pagesInterview PreparationPriya kambleNo ratings yet
- Untitled PresentationDocument6 pagesUntitled PresentationPriya kambleNo ratings yet
- Detailed List and Syllabuses of Courses: Syrian Arab Republic Damascus UniversityDocument10 pagesDetailed List and Syllabuses of Courses: Syrian Arab Republic Damascus UniversitySedra MerkhanNo ratings yet
- AI Module 4Document38 pagesAI Module 4FaReeD HamzaNo ratings yet
- Essay - Network and Computer Systems AdministratorsDocument2 pagesEssay - Network and Computer Systems AdministratorsSaejin EnglishNo ratings yet
- Management Support Systems: An OverviewDocument15 pagesManagement Support Systems: An Overviewmohamed hossamNo ratings yet
- Iot 2Document25 pagesIot 2Isha MarlechaNo ratings yet
- Samuel Aby: Mar Dionysius School, India-VolunteerDocument2 pagesSamuel Aby: Mar Dionysius School, India-VolunteerSAM AbyNo ratings yet
- Jumble Coding (56 To 76)Document21 pagesJumble Coding (56 To 76)MAHESH PATLENo ratings yet
- WPR 2 (Shaurya Upadhyay)Document5 pagesWPR 2 (Shaurya Upadhyay)Shaurya UpadhyayNo ratings yet
- New To The Cloud Deck TC1Document45 pagesNew To The Cloud Deck TC1BenjaminNo ratings yet
- Certificate Programme in Machine LearningDocument3 pagesCertificate Programme in Machine Learningektasharma123No ratings yet
- Kelompok-3-3A-SLR-Dwi YuliantoDocument11 pagesKelompok-3-3A-SLR-Dwi YuliantoDwi YuliantoNo ratings yet
- Lec 4Document30 pagesLec 4Getye degeloNo ratings yet
- Saketh ResumeDocument2 pagesSaketh ResumeugiyuNo ratings yet
- Domain 3 QuestionsDocument16 pagesDomain 3 QuestionsRajaram K.VNo ratings yet
- Manual Sim NextDocument16 pagesManual Sim NextMarcelo Gomes PoindksterNo ratings yet
- Hotel Management Case StudyDocument4 pagesHotel Management Case StudyKarmdeepsinh ZalaNo ratings yet
- Arti Ficial Intelligence Adoption in Business-To-Business Marketing: Toward A Conceptual FrameworkDocument20 pagesArti Ficial Intelligence Adoption in Business-To-Business Marketing: Toward A Conceptual Frameworksaba inamdarNo ratings yet
- Study Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft LearnDocument4 pagesStudy Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft Learnnirmalworks93No ratings yet
- Pantech Software - NLP, ML, AI, Android, Big Data, Cloud Computing, NLP ProjectsDocument9 pagesPantech Software - NLP, ML, AI, Android, Big Data, Cloud Computing, NLP ProjectsChandruNo ratings yet
- Python Programming 3 Books in 1Document269 pagesPython Programming 3 Books in 1n7tpubhzx100% (2)
- Decision Tree LearningDocument11 pagesDecision Tree Learningbenjamin212No ratings yet
- Excavating AI, Crawford and PaglenDocument28 pagesExcavating AI, Crawford and PaglenrotemlinialNo ratings yet
- Advanced ComputingDocument528 pagesAdvanced ComputingRahul SarafNo ratings yet
- Tybca Recent Trends in It Chpter 1Document16 pagesTybca Recent Trends in It Chpter 1aishwarya sajiNo ratings yet
- Ayoub Bouyebla: Education Computer SkillsDocument1 pageAyoub Bouyebla: Education Computer SkillsAyoub BouyeblaNo ratings yet
- Moumita Saha: Personal DetailsDocument6 pagesMoumita Saha: Personal DetailsNehaKarunyaNo ratings yet
- HW1 SoluDocument9 pagesHW1 SoluChuang JamesNo ratings yet
- DBMS Basics: Dr. Rajesh ChauhanDocument56 pagesDBMS Basics: Dr. Rajesh Chauhanarti sharmaNo ratings yet
- Data Mining - IMT Nagpur-ManishDocument82 pagesData Mining - IMT Nagpur-ManishSumeet GuptaNo ratings yet
- What Is Supervised Machine LearningDocument3 pagesWhat Is Supervised Machine LearningMuhammad Tehseen QureshiNo ratings yet
















































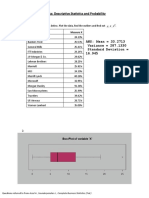


















































Download as docx, pdf, or txt
You might also like
- 11 Network Analytics - Problem StatementDocument4 pages11 Network Analytics - Problem Statementabhishek kandharkar25% (4)
- Association Rules Problem StatementDocument5 pagesAssociation Rules Problem Statementvinutha50% (2)
- Main KeyDocument4 pagesMain KeykishnaNo ratings yet
- CRISP - ML (Q) - Business UnderstandingDocument17 pagesCRISP - ML (Q) - Business UnderstandingHidayat u PathanNo ratings yet
- 13.exploratory Data AnalysisDocument8 pages13.exploratory Data AnalysisKarthik Peddineni0% (1)
- CRISP - DM - Business UnderstandingDocument17 pagesCRISP - DM - Business UnderstandingRohit PaulNo ratings yet
- Missing ValuesDocument3 pagesMissing ValuesvinuthaNo ratings yet
- Duplication - Typecasting-Problem StatementDocument3 pagesDuplication - Typecasting-Problem Statementvinutha100% (1)
- Clustering Documentation R CodeDocument9 pagesClustering Documentation R Codenehal gundrapally100% (1)
- Business Uderstanding Solved1 - Module 1Document11 pagesBusiness Uderstanding Solved1 - Module 1pooja mukundeNo ratings yet
- Basic Statistics (Module - 3)Document9 pagesBasic Statistics (Module - 3)prudhvi nadimpalliNo ratings yet
- 15 KNN - Problem StatementDocument3 pages15 KNN - Problem Statementabhishek kandharkar0% (2)
- Day10 Mathematical FoundationsDocument4 pagesDay10 Mathematical FoundationskishnaNo ratings yet
- CRISP - ML (Q) - Business UnderstandingDocument13 pagesCRISP - ML (Q) - Business UnderstandingTejas SNo ratings yet
- CRISP ML (Q) Business UnderstandingDocument17 pagesCRISP ML (Q) Business UnderstandingNikesh bobadeNo ratings yet
- Multinomial Problem StatementDocument28 pagesMultinomial Problem StatementMoayadNo ratings yet
- NaiveBayes - Problem StatementDocument5 pagesNaiveBayes - Problem StatementSANKALP ROY0% (1)
- 2a EDADocument11 pages2a EDASUMAN CHAUHANNo ratings yet
- CRISP DM Business Understanding CompletedDocument18 pagesCRISP DM Business Understanding CompletedJaya UjayaNo ratings yet
- Discretization Problem StatementDocument3 pagesDiscretization Problem StatementvinuthaNo ratings yet
- R - AssignmentDocument2 pagesR - AssignmentRavalika PeenamalaNo ratings yet
- CRISP DM Business Understanding - Data ScienceDocument15 pagesCRISP DM Business Understanding - Data ScienceGanesh V GaonkarNo ratings yet
- K-Nearest Neighbors: InstructionsDocument4 pagesK-Nearest Neighbors: Instructionsswapnil karadeNo ratings yet
- Association Rules AnsDocument28 pagesAssociation Rules AnsPriya kambleNo ratings yet
- Preliminaries For Data Analysis: Problem StatementsDocument4 pagesPreliminaries For Data Analysis: Problem StatementsAnakha PrasadNo ratings yet
- CRISP DM Business UnderstandingDocument18 pagesCRISP DM Business UnderstandingRahul SathiyanarayananNo ratings yet
- Statistics and ProbabilityDocument8 pagesStatistics and ProbabilityAlesya alesyaNo ratings yet
- Name: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDADocument13 pagesName: Siti Mursyida Abdul Karim (Data Science Program) Topic: Assignment - EDAsiti mursyida100% (1)
- Basic Statistics (Module - 3)Document7 pagesBasic Statistics (Module - 3)nehal gundrapallyNo ratings yet
- Assignment Module 1Document3 pagesAssignment Module 1Tejas S100% (1)
- DataPreparation Outlier TreatmentDocument3 pagesDataPreparation Outlier Treatmentonkar diwate100% (1)
- Basic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedDocument3 pagesBasic Statistics (Module - 4 ( - 1) ) : © 2013 - 2020 360digitmg. All Rights ReservedProli PravalikaNo ratings yet
- Assignment 07 AnswersDocument6 pagesAssignment 07 AnswersSamNo ratings yet
- 8.dummy VariablesDocument4 pages8.dummy VariablesSunkari ArikaNo ratings yet
- Module 03 AssignmentDocument13 pagesModule 03 Assignmentsuresh avadutha100% (1)
- Data Assigment 1Document32 pagesData Assigment 1Sukhwinder Kaur100% (2)
- Zero Variance-Problem StatementDocument3 pagesZero Variance-Problem Statementvinutha0% (1)
- Day02-Data Understanding Answer Asit 25082022Document4 pagesDay02-Data Understanding Answer Asit 25082022loveNo ratings yet
- 06.discretization Problem StatementDocument2 pages06.discretization Problem Statementgujan thakur50% (2)
- Assignment Module04 Part1Document5 pagesAssignment Module04 Part1karthik kartiNo ratings yet
- DataPreparation - Outlier - Treatment ASSIGNMENT 1Document7 pagesDataPreparation - Outlier - Treatment ASSIGNMENT 1Hari Machavrapu100% (1)
- Inferential Statistics (AutoRecovered)Document12 pagesInferential Statistics (AutoRecovered)Shariq AnsariNo ratings yet
- Day17 Association RulesDocument4 pagesDay17 Association RulesForeverNo ratings yet
- KNN - Problem Statement ANSWERDocument8 pagesKNN - Problem Statement ANSWERNaga Shiva100% (1)
- OriginalDocument30 pagesOriginalMohanNo ratings yet
- CRISP ML (Q) Business UnderstandingDocument12 pagesCRISP ML (Q) Business UnderstandingTharani vimalaNo ratings yet
- CRISP - ML (Q) - Business Understanding AssignmentDocument11 pagesCRISP - ML (Q) - Business Understanding AssignmentAnakha PrasadNo ratings yet
- Assignment 05 ANSWERSDocument5 pagesAssignment 05 ANSWERSSamNo ratings yet
- Topics: Descriptive Statistics and Probability: Name of Company Measure XDocument4 pagesTopics: Descriptive Statistics and Probability: Name of Company Measure XSimarjeet SinghNo ratings yet
- CRISP DM Business AissgnmentDocument18 pagesCRISP DM Business Aissgnmentharshu rathiNo ratings yet
- Name:Silpa Batch Id: Analysis: WDEO 171220 Topic: Principal ComponentDocument7 pagesName:Silpa Batch Id: Analysis: WDEO 171220 Topic: Principal ComponentSravani Adapa100% (1)
- Hypothesis Testing - Problem StatementDocument4 pagesHypothesis Testing - Problem StatementAlesya alesyaNo ratings yet
- Topic: Dimension Reduction With PCA: InstructionsDocument8 pagesTopic: Dimension Reduction With PCA: InstructionsAlesya alesyaNo ratings yet
- 1b.data UnderstandingDocument4 pages1b.data Understandingmanasa reddyNo ratings yet
- CRISP DM Business UnderstandingDocument17 pagesCRISP DM Business UnderstandingkeerthiNo ratings yet
- 01.CRISP DM Business UnderstandingDocument10 pages01.CRISP DM Business UnderstandingLovleen MissonNo ratings yet
- 7 K-Means ClusteringDocument4 pages7 K-Means ClusteringArvind Kumar Yadav0% (1)
- Day13-K-Means ClusteringDocument10 pagesDay13-K-Means ClusteringSBS MoviesNo ratings yet
- Ensemble ModelsfDocument7 pagesEnsemble ModelsfTejaNo ratings yet
- Day14-PCA - Problem StatementDocument4 pagesDay14-PCA - Problem StatementPriya kamble0% (1)
- Association Rules AnsDocument28 pagesAssociation Rules AnsPriya kambleNo ratings yet
- Day14-PCA - Problem StatementDocument4 pagesDay14-PCA - Problem StatementPriya kamble0% (1)
- Pythonwith Spyder An Experiential Learning PerspectiveDocument230 pagesPythonwith Spyder An Experiential Learning PerspectivePriya kambleNo ratings yet
- Assignment 4 SolutionsDocument2 pagesAssignment 4 SolutionsPriya kambleNo ratings yet
- Difference Between Star Schema and Snowflake SchemaDocument6 pagesDifference Between Star Schema and Snowflake SchemaPriya kambleNo ratings yet
- TransformationsDocument6 pagesTransformationsPriya kambleNo ratings yet
- DatastageDocument50 pagesDatastagePriya kambleNo ratings yet
- Comparison of QlikView, Tableau and Power BIDocument13 pagesComparison of QlikView, Tableau and Power BIPriya kambleNo ratings yet
- Data Warehouse VS Data MiningDocument7 pagesData Warehouse VS Data MiningPriya kambleNo ratings yet
- Assignment 1 (R Programming)Document24 pagesAssignment 1 (R Programming)Priya kambleNo ratings yet
- Interview PreparationDocument2 pagesInterview PreparationPriya kambleNo ratings yet
- Untitled PresentationDocument6 pagesUntitled PresentationPriya kambleNo ratings yet
- Detailed List and Syllabuses of Courses: Syrian Arab Republic Damascus UniversityDocument10 pagesDetailed List and Syllabuses of Courses: Syrian Arab Republic Damascus UniversitySedra MerkhanNo ratings yet
- AI Module 4Document38 pagesAI Module 4FaReeD HamzaNo ratings yet
- Essay - Network and Computer Systems AdministratorsDocument2 pagesEssay - Network and Computer Systems AdministratorsSaejin EnglishNo ratings yet
- Management Support Systems: An OverviewDocument15 pagesManagement Support Systems: An Overviewmohamed hossamNo ratings yet
- Iot 2Document25 pagesIot 2Isha MarlechaNo ratings yet
- Samuel Aby: Mar Dionysius School, India-VolunteerDocument2 pagesSamuel Aby: Mar Dionysius School, India-VolunteerSAM AbyNo ratings yet
- Jumble Coding (56 To 76)Document21 pagesJumble Coding (56 To 76)MAHESH PATLENo ratings yet
- WPR 2 (Shaurya Upadhyay)Document5 pagesWPR 2 (Shaurya Upadhyay)Shaurya UpadhyayNo ratings yet
- New To The Cloud Deck TC1Document45 pagesNew To The Cloud Deck TC1BenjaminNo ratings yet
- Certificate Programme in Machine LearningDocument3 pagesCertificate Programme in Machine Learningektasharma123No ratings yet
- Kelompok-3-3A-SLR-Dwi YuliantoDocument11 pagesKelompok-3-3A-SLR-Dwi YuliantoDwi YuliantoNo ratings yet
- Lec 4Document30 pagesLec 4Getye degeloNo ratings yet
- Saketh ResumeDocument2 pagesSaketh ResumeugiyuNo ratings yet
- Domain 3 QuestionsDocument16 pagesDomain 3 QuestionsRajaram K.VNo ratings yet
- Manual Sim NextDocument16 pagesManual Sim NextMarcelo Gomes PoindksterNo ratings yet
- Hotel Management Case StudyDocument4 pagesHotel Management Case StudyKarmdeepsinh ZalaNo ratings yet
- Arti Ficial Intelligence Adoption in Business-To-Business Marketing: Toward A Conceptual FrameworkDocument20 pagesArti Ficial Intelligence Adoption in Business-To-Business Marketing: Toward A Conceptual Frameworksaba inamdarNo ratings yet
- Study Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft LearnDocument4 pagesStudy Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft Learnnirmalworks93No ratings yet
- Pantech Software - NLP, ML, AI, Android, Big Data, Cloud Computing, NLP ProjectsDocument9 pagesPantech Software - NLP, ML, AI, Android, Big Data, Cloud Computing, NLP ProjectsChandruNo ratings yet
- Python Programming 3 Books in 1Document269 pagesPython Programming 3 Books in 1n7tpubhzx100% (2)
- Decision Tree LearningDocument11 pagesDecision Tree Learningbenjamin212No ratings yet
- Excavating AI, Crawford and PaglenDocument28 pagesExcavating AI, Crawford and PaglenrotemlinialNo ratings yet
- Advanced ComputingDocument528 pagesAdvanced ComputingRahul SarafNo ratings yet
- Tybca Recent Trends in It Chpter 1Document16 pagesTybca Recent Trends in It Chpter 1aishwarya sajiNo ratings yet
- Ayoub Bouyebla: Education Computer SkillsDocument1 pageAyoub Bouyebla: Education Computer SkillsAyoub BouyeblaNo ratings yet
- Moumita Saha: Personal DetailsDocument6 pagesMoumita Saha: Personal DetailsNehaKarunyaNo ratings yet
- HW1 SoluDocument9 pagesHW1 SoluChuang JamesNo ratings yet
- DBMS Basics: Dr. Rajesh ChauhanDocument56 pagesDBMS Basics: Dr. Rajesh Chauhanarti sharmaNo ratings yet
- Data Mining - IMT Nagpur-ManishDocument82 pagesData Mining - IMT Nagpur-ManishSumeet GuptaNo ratings yet
- What Is Supervised Machine LearningDocument3 pagesWhat Is Supervised Machine LearningMuhammad Tehseen QureshiNo ratings yet