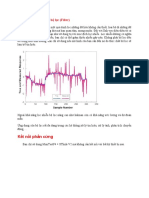
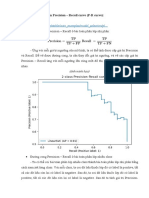
Download as docx, pdf, or txt
You might also like
- BÀI TẬP 10.1 - PhamMinhLong - 19521796Document5 pagesBÀI TẬP 10.1 - PhamMinhLong - 19521796Long PhạmNo ratings yet
- Giới thiệu khái quát về bộ lọcDocument14 pagesGiới thiệu khái quát về bộ lọcTrần LinhNo ratings yet
- Các Bư C CH y DTDocument2 pagesCác Bư C CH y DTGiáp TàiNo ratings yet
- 1.cac Buoc Pre Processing BigDocument21 pages1.cac Buoc Pre Processing BigVinh PhamNo ratings yet
- 1. Mô tả dữ liệu 1.1 Mô tả dữ liệuDocument10 pages1. Mô tả dữ liệu 1.1 Mô tả dữ liệuKhánh LinhNo ratings yet
- Bai Thuc Hanh 2 (Updated)Document6 pagesBai Thuc Hanh 2 (Updated)Cơ Đinh VănNo ratings yet
- Project Nhom5Document15 pagesProject Nhom5TRỌNG NGÔ PHÚNo ratings yet
- Machine Learning - Các PP Đánh Giá ClassifierDocument13 pagesMachine Learning - Các PP Đánh Giá ClassifierHaodttNo ratings yet
- NG D NG Convolutional Neural Network Trong Bài Toán Phân Lo I NHDocument7 pagesNG D NG Convolutional Neural Network Trong Bài Toán Phân Lo I NHlearnit learnitNo ratings yet
- 2 Phuong Phap Thong Ke 1Document71 pages2 Phuong Phap Thong Ke 1Nguyệt MinhNo ratings yet
- BTLXLA nhóm 06 B20DCCN367 Trần Đình KhảiDocument28 pagesBTLXLA nhóm 06 B20DCCN367 Trần Đình KhảiKhải TrầnNo ratings yet
- Project Nhom5Document15 pagesProject Nhom5Quan TrầnNo ratings yet
- TRẦN MINH THƯƠNG - N21DCVT101 - D21CQVT01-N - BUỔI 2Document27 pagesTRẦN MINH THƯƠNG - N21DCVT101 - D21CQVT01-N - BUỔI 2thuongtran20199No ratings yet
- Simple Code Demo FunctionDocument67 pagesSimple Code Demo Functionquanghieu.inamedNo ratings yet
- Đề cương học máyDocument8 pagesĐề cương học máyphamquyet12052002No ratings yet
- 02 LePhuongAnh N19DCCN006 BT - TH.22102022Document8 pages02 LePhuongAnh N19DCCN006 BT - TH.22102022TIKTOK HOTNo ratings yet
- ReportDocument14 pagesReportLinh TrúcNo ratings yet
- PL04 A BiaThuyetMinhDocument8 pagesPL04 A BiaThuyetMinhThiện Quý HồNo ratings yet
- 17. Giảm chiều dữ liệu - Deep AI KhanhBlogDocument2 pages17. Giảm chiều dữ liệu - Deep AI KhanhBlogphanthikieuvy0612No ratings yet
- RPL CollectDocument15 pagesRPL CollectMac HieuNo ratings yet
- Xây Dựng Chương Trình Gợi ý Phim Dựa Vào Tập Dữ Liệu Movie LenDocument9 pagesXây Dựng Chương Trình Gợi ý Phim Dựa Vào Tập Dữ Liệu Movie Lenlearnit learnitNo ratings yet
- HW13 14Document5 pagesHW13 14Quang AnNo ratings yet
- Bài Tập Matlab Matlab Programming: Câu 1: Tính giá trị của biến y = >> exp (1) ^3/14+8*sqrtDocument22 pagesBài Tập Matlab Matlab Programming: Câu 1: Tính giá trị của biến y = >> exp (1) ^3/14+8*sqrtmitulam123trungNo ratings yet
- Chapter 4.1-ID3Document29 pagesChapter 4.1-ID3ha quanNo ratings yet
- Thuyet TrinhDocument4 pagesThuyet TrinhThọ VũNo ratings yet
- 04 - Nhận dạng đối tượngDocument15 pages04 - Nhận dạng đối tượngTài Huỳnh VănNo ratings yet
- Lưu ý: Sinh viên làm bài trực tiếp trên đề, không được sử dụng tài liệuDocument8 pagesLưu ý: Sinh viên làm bài trực tiếp trên đề, không được sử dụng tài liệuAnh QuocNo ratings yet
- LẬP TRÌNH CSDLDocument6 pagesLẬP TRÌNH CSDLNguyên CôngNo ratings yet
- 2 - Phuong Phap Thong KeDocument69 pages2 - Phuong Phap Thong KeTrương Minh TiếnNo ratings yet
- Assignments 2021Document3 pagesAssignments 2021Trần Thị Tuyết Mai - B18DCVT278No ratings yet
- Phan4 - C14 - Thong Ke Va Tong Hop Du LieuDocument31 pagesPhan4 - C14 - Thong Ke Va Tong Hop Du LieuThành Tâm Trần HoàngNo ratings yet
- Phan4 - C14 - Thong Ke Va Tong Hop Du LieuDocument22 pagesPhan4 - C14 - Thong Ke Va Tong Hop Du Lieuphamthikimthuongb1No ratings yet
- 2 - Phuong Phap Thong KeDocument66 pages2 - Phuong Phap Thong KeChúc PhươngNo ratings yet
- Giải thuật di truyền GADocument5 pagesGiải thuật di truyền GAQuang Thien BùiNo ratings yet
- Machine LearningDocument29 pagesMachine LearningNguyễn HoàngNo ratings yet
- 2 - Phuong Phap Thong KeDocument69 pages2 - Phuong Phap Thong Kenguyengiabaomtp4444No ratings yet
- KHDL 2 OrangeDocument15 pagesKHDL 2 OrangeVương LamNo ratings yet
- 668 - Fulltext - 4.ĐTVT - Phuoc - Vuong Quang PhuocDocument12 pages668 - Fulltext - 4.ĐTVT - Phuoc - Vuong Quang Phuoctung phamNo ratings yet
- Hoi Quy Tuyen Tinh Da BienDocument9 pagesHoi Quy Tuyen Tinh Da Bienbaothai1905No ratings yet
- Khdl Phần Lý ThuyếtDocument21 pagesKhdl Phần Lý Thuyếttinhle.31221023009No ratings yet
- PowpointDocument29 pagesPowpointEDM NCSNo ratings yet
- Analog s7 300Document10 pagesAnalog s7 300Nghinh Phong VũNo ratings yet
- 2023.Bài tập Xử lý ảnh - GỬI SVDocument5 pages2023.Bài tập Xử lý ảnh - GỬI SVNhóm 2-Nguyễn Đình TrungNo ratings yet
- Bai 9Document5 pagesBai 9Vu Nguyen Manh HungNo ratings yet
- Bai Thuc Hanh PDFDocument3 pagesBai Thuc Hanh PDFThanh MonNo ratings yet
- Bai Thuc Hanh 4Document6 pagesBai Thuc Hanh 4Tong HuynhNo ratings yet
- Bài Kiểm Tra Matlab 15 - 11Document15 pagesBài Kiểm Tra Matlab 15 - 11nguyenthanhngoc31102003No ratings yet
- Baitap 20521658Document5 pagesBaitap 20521658Nghĩa Trương ĐăngNo ratings yet
- Hihiajdsjag TexDocument5 pagesHihiajdsjag TexLê ThưNo ratings yet
- Canny Edge DetectorDocument35 pagesCanny Edge DetectorNgọc Anh Nguyễn ThịNo ratings yet
- Co So Lap TrinhDocument53 pagesCo So Lap TrinhHuy Tâm NgNo ratings yet
- Nhóm HiDocument31 pagesNhóm HihoangcuongimttNo ratings yet
- MLP301x 1Document8 pagesMLP301x 1đức ngọc trầnNo ratings yet
- Khoá học deep learningDocument78 pagesKhoá học deep learningSơn VũNo ratings yet
- Chuong4 NeuralNetworkDocument50 pagesChuong4 NeuralNetworknguyen namNo ratings yet
- Bao Cao Thuc Hanh 2Document18 pagesBao Cao Thuc Hanh 2Vũ AnNo ratings yet
- How To Use Iterative ImputationDocument3 pagesHow To Use Iterative ImputationVĩnh HưngNo ratings yet
- Huong Dan Hinh Thuc Lam Bai Tap Ket Thuc Hoc Phan hk2 Nam Hoc 2020 2021Document16 pagesHuong Dan Hinh Thuc Lam Bai Tap Ket Thuc Hoc Phan hk2 Nam Hoc 2020 2021Giáp TàiNo ratings yet
- Cách lấy nhiễmDocument4 pagesCách lấy nhiễmGiáp TàiNo ratings yet
- Các Bư C CH y DTDocument2 pagesCác Bư C CH y DTGiáp TàiNo ratings yet
- Văn bản của bài báo-25-1-10-20200715Document7 pagesVăn bản của bài báo-25-1-10-20200715Giáp TàiNo ratings yet