Download as pdf or txt
You might also like
- DP 600Document44 pagesDP 600mirtahmidNo ratings yet
- Laravel Concepts 2023 Part 2 - Martin JooDocument123 pagesLaravel Concepts 2023 Part 2 - Martin Jooahmetaltun100% (1)
- Hair SalonDocument11 pagesHair Salonrishit33% (3)
- Mini Project II Instructions Segmentation and RegressionDocument6 pagesMini Project II Instructions Segmentation and RegressionSyed Anns Ali0% (1)
- SAP Variant Configuration: Your Successful Guide to ModelingFrom EverandSAP Variant Configuration: Your Successful Guide to ModelingRating: 5 out of 5 stars5/5 (2)
- Activate 1 Physics Chapter1 AnswersDocument5 pagesActivate 1 Physics Chapter1 AnswersPapi Parikh100% (1)
- Project On Data Mining: Prepared by Ashish Pavan Kumar K PGP-DSBA at Great LearningDocument50 pagesProject On Data Mining: Prepared by Ashish Pavan Kumar K PGP-DSBA at Great LearningAshish Pavan Kumar KNo ratings yet
- Project QuestionsDocument4 pagesProject Questionsvansh guptaNo ratings yet
- Order Management Setup Steps (Oracle R12)Document82 pagesOrder Management Setup Steps (Oracle R12)hellsailor100% (1)
- Software Testing AssignmentDocument4 pagesSoftware Testing AssignmentGuna Ram0% (1)
- Linux Commands Cheat SheetDocument129 pagesLinux Commands Cheat SheetRakesh RakeeNo ratings yet
- Amit Pradhan CA Exam Amit Pradhan 71310017 282Document10 pagesAmit Pradhan CA Exam Amit Pradhan 71310017 282sonalzNo ratings yet
- Choice Based Conjoint ModelsDocument16 pagesChoice Based Conjoint ModelsTrekpot ComNo ratings yet
- Raghuram Lanka - Raghuram Lanka - Section B - 71310043 - CBA - Exam - 338Document7 pagesRaghuram Lanka - Raghuram Lanka - Section B - 71310043 - CBA - Exam - 338sonalzNo ratings yet
- Pergunta 1: 1 / 1 PontoDocument22 pagesPergunta 1: 1 / 1 PontoBruno CuryNo ratings yet
- Wednesday, June 13, 2012 L&T Infotech Proprietary Page 1 of 4Document4 pagesWednesday, June 13, 2012 L&T Infotech Proprietary Page 1 of 4Hari ReddyNo ratings yet
- Oracle OPM Interview Questions R12Document10 pagesOracle OPM Interview Questions R12Rajesh MkNo ratings yet
- Assignment2-9509Document5 pagesAssignment2-9509ritadhikarycseNo ratings yet
- Interview QuestionsDocument48 pagesInterview QuestionsRam PosamNo ratings yet
- Business ModelingDocument15 pagesBusiness ModelingHUAN NGUYEN KHOANo ratings yet
- Design Concept HandoutDocument12 pagesDesign Concept HandoutsalfahNo ratings yet
- Sap SD Interview Questions With Answers PDFDocument266 pagesSap SD Interview Questions With Answers PDFsapsd1082012No ratings yet
- S. V. Institute of ManagementDocument48 pagesS. V. Institute of ManagementGaurav GagwaniNo ratings yet
- KanagalMukhul Fall2020Document32 pagesKanagalMukhul Fall2020Shiva ShivaNo ratings yet
- Introduction ConjointDocument8 pagesIntroduction ConjointAgus E. WicaksonoNo ratings yet
- Multi-Class Text Classification With Scikit-LearnDocument20 pagesMulti-Class Text Classification With Scikit-LearnmohitNo ratings yet
- Project Data Mining Tanaya LokhandeDocument58 pagesProject Data Mining Tanaya Lokhandetanaya lokhandeNo ratings yet
- Praveen Kumar Praveen 297Document8 pagesPraveen Kumar Praveen 297sonalzNo ratings yet
- Courier Manegment SystemDocument6 pagesCourier Manegment SystemkrawariyaNo ratings yet
- Timeline Required Completing The ProjectDocument10 pagesTimeline Required Completing The ProjectPritesh KumarNo ratings yet
- PL-600 28janDocument20 pagesPL-600 28janAmuthaNo ratings yet
- COMP306 Project V1Document3 pagesCOMP306 Project V1Onur KaplanNo ratings yet
- SFDV2004 - Application Software Development Project SpecificationDocument10 pagesSFDV2004 - Application Software Development Project SpecificationAhmed Al-farsiNo ratings yet
- Machine Learning - Customer Segment Project. Approved by UDACITYDocument19 pagesMachine Learning - Customer Segment Project. Approved by UDACITYCarlos Pimentel100% (1)
- 8 Hybris HMC PCMDocument9 pages8 Hybris HMC PCMravikanchuNo ratings yet
- UuuDocument32 pagesUuulomososNo ratings yet
- A Grocery Shop Owner Wants To Store The Informatio...Document6 pagesA Grocery Shop Owner Wants To Store The Informatio...Tasnim MaishaNo ratings yet
- Bi Certi Bw305Document62 pagesBi Certi Bw305Albert FranquesaNo ratings yet
- Interfaces For Human-Robot Interaction - Project Guidelines: 1. Formulating The ProblemDocument20 pagesInterfaces For Human-Robot Interaction - Project Guidelines: 1. Formulating The ProblemMicsku TomiNo ratings yet
- Chapter 5Document44 pagesChapter 5ptgoel100% (2)
- Assignment Su2023Document4 pagesAssignment Su2023Đức Lê TrungNo ratings yet
- Boutique Management SystemDocument4 pagesBoutique Management SystemPrasanna D100% (1)
- Stock Maintenance SystemDocument17 pagesStock Maintenance SystemBushra AnjumNo ratings yet
- 11 Hybris PersonalizationDocument20 pages11 Hybris PersonalizationravikanchuNo ratings yet
- Variant Configuration: Example ModelDocument11 pagesVariant Configuration: Example ModelLokesh Dora100% (2)
- 6.interview QuestionsDocument59 pages6.interview Questionsr.m.ram234No ratings yet
- Project Report CSE 1209Document14 pagesProject Report CSE 1209rahman2109011No ratings yet
- Project - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Document38 pagesProject - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Ravi KotharuNo ratings yet
- Demand Management DEMANTRA1Document6 pagesDemand Management DEMANTRA1anishokm2992No ratings yet
- Thesis MRPDocument7 pagesThesis MRPSandra Long100% (2)
- Introduction To Variant Configuration With An Example ModelDocument24 pagesIntroduction To Variant Configuration With An Example ModelRahul Jain100% (1)
- Set 6 DoneDocument79 pagesSet 6 DoneNael JeremieNo ratings yet
- Project Report: A Report Submitted ToDocument13 pagesProject Report: A Report Submitted ToPuvvula Bhavya Sri chandNo ratings yet
- Final DMT Report PDFDocument27 pagesFinal DMT Report PDFAnonymous Sqb2WONo ratings yet
- Sap SD Interview Questions With Answers: 1.what Is Transfer Order?Document20 pagesSap SD Interview Questions With Answers: 1.what Is Transfer Order?Lokesh DoraNo ratings yet
- Software Development Life Cycle (SDLC) : Spiral Model/ (Iterative Model)Document2 pagesSoftware Development Life Cycle (SDLC) : Spiral Model/ (Iterative Model)mohanNo ratings yet
- STIKDocument5 pagesSTIKabebawNo ratings yet
- ODI NotesDocument5 pagesODI NotesSonam PatelNo ratings yet
- Complete The Look: Scene-Based Complementary Product RecommendationDocument10 pagesComplete The Look: Scene-Based Complementary Product Recommendationjohn hNo ratings yet
- Finding Similar Fashion Products With Their LinksDocument19 pagesFinding Similar Fashion Products With Their Linksjohn hNo ratings yet
- Simple Post Estimation and Bounding BoxesDocument24 pagesSimple Post Estimation and Bounding Boxesjohn hNo ratings yet
- KeysTracy - Final-Report - FashionImageClassifier v2 For GithubDocument13 pagesKeysTracy - Final-Report - FashionImageClassifier v2 For Githubjohn hNo ratings yet
- 05 MATHS 12th Model Question Paper 2021-22Document12 pages05 MATHS 12th Model Question Paper 2021-22john hNo ratings yet
- 03 Physics 12th Model Question Paper 2021-22Document13 pages03 Physics 12th Model Question Paper 2021-22john hNo ratings yet
- 06 Biology 12th Model Question Paper 2021-22Document9 pages06 Biology 12th Model Question Paper 2021-22john hNo ratings yet
- 04 Chemistry 12th Model Question Paper 2021-22Document12 pages04 Chemistry 12th Model Question Paper 2021-22john hNo ratings yet
- 02 ENGLISH 12th Model Question Paper 2021-22Document8 pages02 ENGLISH 12th Model Question Paper 2021-22john hNo ratings yet
- EN Wind Code - Part2Document7 pagesEN Wind Code - Part2AJBAJB BAJBAJNo ratings yet
- Battery Charger SizingDocument1 pageBattery Charger SizingSenthil RajanNo ratings yet
- Knowledge Versus OpinionDocument20 pagesKnowledge Versus OpinionShumaila HameedNo ratings yet
- Rich Text3Document73 pagesRich Text3Mohit kumarNo ratings yet
- A-Level Paper 1 pp5 MsDocument10 pagesA-Level Paper 1 pp5 MsSyed NafsanNo ratings yet
- Gl90ad PDFDocument2 pagesGl90ad PDFCarlos CornielesNo ratings yet
- Ideal Lift KinematicsDocument16 pagesIdeal Lift KinematicscabekiladNo ratings yet
- Test 4 BPSC Main Exam 2019: Assistant EngineerDocument9 pagesTest 4 BPSC Main Exam 2019: Assistant EngineerAmit KumarNo ratings yet
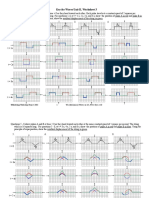
- Key For Waves Unit II, Worksheet 3: ©modeling Workshop Project 2003 1 W2, Mechanical Waves in 1D, WS 3 Key, v3.0Document3 pagesKey For Waves Unit II, Worksheet 3: ©modeling Workshop Project 2003 1 W2, Mechanical Waves in 1D, WS 3 Key, v3.0cmejdi jNo ratings yet
- Aluminum RF Power Splitters Under TestDocument7 pagesAluminum RF Power Splitters Under TesttomasNo ratings yet
- Intro For R For Finance CH 1Document6 pagesIntro For R For Finance CH 1Jose MartinNo ratings yet
- Comp 202Document6 pagesComp 202Anjila KshetriNo ratings yet
- Hydram PDFDocument6 pagesHydram PDFDedi SatriyawanNo ratings yet
- Katalog 2020 ENG Stand 2016 11 01 Final01Document289 pagesKatalog 2020 ENG Stand 2016 11 01 Final01Ramazan ErdinçNo ratings yet
- Distillation PostLabDocument2 pagesDistillation PostLabBrys SyNo ratings yet
- ED Multiple Choice QuestionsDocument7 pagesED Multiple Choice QuestionsLaxmireddy Peram43% (7)
- Sliprings Carbon Brushes Turbo AlternatorsDocument20 pagesSliprings Carbon Brushes Turbo Alternatorsbigsteve9088No ratings yet
- Process Technology Level 2: © University of Teesside 2005Document22 pagesProcess Technology Level 2: © University of Teesside 2005Murad ZareebahNo ratings yet
- Ruby Concurrency ExplainedDocument7 pagesRuby Concurrency ExplainedachhuNo ratings yet
- c3d Content Italy 2017 ItalianDocument128 pagesc3d Content Italy 2017 ItaliancamulNo ratings yet
- Sudipto Mondal Financial Inclusion and Its Determinants in IndiaDocument20 pagesSudipto Mondal Financial Inclusion and Its Determinants in Indiapalvikas616No ratings yet
- 400 Series: Industrial 23.6 KW / 31.6 HP at 2400 RPM 26.1 KW / 35.0 HP at 2600 RPMDocument5 pages400 Series: Industrial 23.6 KW / 31.6 HP at 2400 RPM 26.1 KW / 35.0 HP at 2600 RPMMouh ElobeyNo ratings yet
- Development of Instrumental and Sensory Analytical Methods of Food Obtained by Traditional and Emerging TechnologiesDocument163 pagesDevelopment of Instrumental and Sensory Analytical Methods of Food Obtained by Traditional and Emerging TechnologiescarloarchivioNo ratings yet
- DBMS Viva QuestionsDocument4 pagesDBMS Viva Questionssavitha ramuNo ratings yet
- Comparison of Malware Classification Methods Using Convolutional Neural Network Based On Api Call StreamDocument19 pagesComparison of Malware Classification Methods Using Convolutional Neural Network Based On Api Call StreamAIRCC - IJNSANo ratings yet
- Emcp Ii - O&mDocument12 pagesEmcp Ii - O&mJorge Luis Tanaka ConchaNo ratings yet
- GPS Coordinates From The NMEA 0183 GPRMC StatementDocument8 pagesGPS Coordinates From The NMEA 0183 GPRMC Statementesr106No ratings yet