Download as pdf or txt
You might also like
- LTE ENodeB Security Networking and Data Configuration-20100331-A-1.0Document35 pagesLTE ENodeB Security Networking and Data Configuration-20100331-A-1.0alikaiser88No ratings yet
- Algorithms in C++ - SedgewickDocument2 pagesAlgorithms in C++ - Sedgewickasf23333% (3)
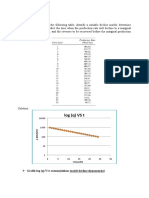
- Problems: Log (Q) VS TDocument8 pagesProblems: Log (Q) VS TDianita ZuamaNo ratings yet
- TP OverviewDocument8 pagesTP OverviewYOUSSEF SIYAHNo ratings yet
- Publications of The Astronomical Society of Australia 1Document8 pagesPublications of The Astronomical Society of Australia 1YOUSSEF SIYAHNo ratings yet
- TP ArticleDocument8 pagesTP ArticleYOUSSEF SIYAHNo ratings yet
- Publications of The Astronomical Society of Australia 1Document8 pagesPublications of The Astronomical Society of Australia 1YOUSSEF SIYAHNo ratings yet
- 1 s2.0 S235291482200065X MainDocument10 pages1 s2.0 S235291482200065X MainDenzo NaldaNo ratings yet
- Ahmad Et Al. - 2023Document19 pagesAhmad Et Al. - 2023apatzNo ratings yet
- Journal Pone 0262448Document25 pagesJournal Pone 0262448vaishnaviNo ratings yet
- Imu100378 PDFDocument13 pagesImu100378 PDFHaneya NaeemNo ratings yet
- Das, Santosh, Pal - 2020Document11 pagesDas, Santosh, Pal - 2020apatzNo ratings yet
- A Review on Deep Learning Techniques for the Diagnosis of Novel Coronavirus (COVID-19)Document22 pagesA Review on Deep Learning Techniques for the Diagnosis of Novel Coronavirus (COVID-19)sametslxxNo ratings yet
- 2004 06912Document9 pages2004 06912Gaurav GaggarNo ratings yet
- Bashar Et Al. - 2021Document18 pagesBashar Et Al. - 2021apatzNo ratings yet
- Informatics in Medicine UnlockedDocument13 pagesInformatics in Medicine UnlockedAckshayaNo ratings yet
- (IJCST-V8I3P13) :pranali Manapure, Kiran Likhar, Hemlata KosareDocument5 pages(IJCST-V8I3P13) :pranali Manapure, Kiran Likhar, Hemlata KosareEighthSenseGroupNo ratings yet
- Prediction of COVID-19 Cases Using CNN With X-Rays: DR D. Haritha N. Swaroop M. MounikaDocument6 pagesPrediction of COVID-19 Cases Using CNN With X-Rays: DR D. Haritha N. Swaroop M. MounikaTanmayi AdhavNo ratings yet
- Biomedical Signal Processing and Control: Prasad Kalane, Sarika Patil, B.P. Patil, Davinder Pal SharmaDocument9 pagesBiomedical Signal Processing and Control: Prasad Kalane, Sarika Patil, B.P. Patil, Davinder Pal SharmaShivam Mani Tripathi x-c 11No ratings yet
- Chowdhury Et Al. - 2020Document12 pagesChowdhury Et Al. - 2020apatzNo ratings yet
- COVID-19 Image Classification Using Deep learning-ScienceDirectDocument34 pagesCOVID-19 Image Classification Using Deep learning-ScienceDirectGaspar PonceNo ratings yet
- A Novel AI-enabled Framework To Diagnose Coronavirus COVID-19 Using Smartphone Embedded Sensors: Design StudyDocument5 pagesA Novel AI-enabled Framework To Diagnose Coronavirus COVID-19 Using Smartphone Embedded Sensors: Design StudyDeepak KumarNo ratings yet
- COVID-19 Cough Classification Using Machine LearniDocument10 pagesCOVID-19 Cough Classification Using Machine Learniสุรกิจ อภิรักษากรNo ratings yet
- Can AI Help in Screening Viral and COVID-19 PneumoniaDocument12 pagesCan AI Help in Screening Viral and COVID-19 PneumoniaMahesa Kurnianti PutriNo ratings yet
- An Efficient Mixture of Deep and Machine Learning Models For COVID-19 and Tuberculosis Detection Using X-Ray Images in Resource Limited SettingsDocument24 pagesAn Efficient Mixture of Deep and Machine Learning Models For COVID-19 and Tuberculosis Detection Using X-Ray Images in Resource Limited Settingsnessus joshua aragonés salazarNo ratings yet
- Research Article Review On Diagnosis of COVID-19 From Chest CT Images Using Artificial IntelligenceDocument10 pagesResearch Article Review On Diagnosis of COVID-19 From Chest CT Images Using Artificial IntelligenceKurama Nine TailsNo ratings yet
- Thangaraj Et Al. - 2023Document14 pagesThangaraj Et Al. - 2023apatzNo ratings yet
- COVID-19 Diagnosis at Early Stage Based On Smartwatches and Machine Learning TechniquesDocument16 pagesCOVID-19 Diagnosis at Early Stage Based On Smartwatches and Machine Learning Techniquesmnabi0332No ratings yet
- Biomedical Engineering Advances: Rumana Islam, Esam Abdel-Raheem, Mohammed TariqueDocument12 pagesBiomedical Engineering Advances: Rumana Islam, Esam Abdel-Raheem, Mohammed TariqueMohammed TariqueNo ratings yet
- Role of Deep Learning ElsevierDocument9 pagesRole of Deep Learning Elseviercsomab4uNo ratings yet
- Monitoring COVID-19 Social Distancing With Person Detection and Tracking Via Fine-Tuned YOLO v3 and Deepsort TechniquesDocument10 pagesMonitoring COVID-19 Social Distancing With Person Detection and Tracking Via Fine-Tuned YOLO v3 and Deepsort Techniques54Tamboli Naila AsifNo ratings yet
- Artificial Intelligence For COVID-19 Detection - A State-Of-The-Art ReviewDocument24 pagesArtificial Intelligence For COVID-19 Detection - A State-Of-The-Art Reviewkhurram shehzadNo ratings yet
- Monitoring COVID-19 Social Distancing With Person PDFDocument10 pagesMonitoring COVID-19 Social Distancing With Person PDFpankaj ambawataNo ratings yet
- Covidscreen: Explainable Deep Learning Framework For Differential Diagnosis of Covid-19 Using Chest X-RaysDocument22 pagesCovidscreen: Explainable Deep Learning Framework For Differential Diagnosis of Covid-19 Using Chest X-RaysKaremNo ratings yet
- COVID-19 Cough Pain Prediction Approaches Using Machine LearningDocument11 pagesCOVID-19 Cough Pain Prediction Approaches Using Machine LearningSsanta SanthosshNo ratings yet
- Trends in Analytical Chemistry: Annasamy Gowri, N. Ashwin Kumar, B.S. Suresh AnandDocument13 pagesTrends in Analytical Chemistry: Annasamy Gowri, N. Ashwin Kumar, B.S. Suresh AnandabdulrazaqNo ratings yet
- COVID-19 Diagnosis Using Cough RecordingsDocument9 pagesCOVID-19 Diagnosis Using Cough RecordingsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Covid - Mtnet: Covid-19 Detection With Multi-Task Deep Learning ApproachesDocument11 pagesCovid - Mtnet: Covid-19 Detection With Multi-Task Deep Learning ApproachesEbrahim Abd El HadyNo ratings yet
- Research Paper 2 ReviewDocument6 pagesResearch Paper 2 ReviewThe Code RunNo ratings yet
- Abstract IntroductionDocument33 pagesAbstract IntroductionRather lubna ShabirNo ratings yet
- Technical Answers For Realworld Problems (ECE3999) : Project Title: Covid-19 Analysis Through Chest X-RaysDocument7 pagesTechnical Answers For Realworld Problems (ECE3999) : Project Title: Covid-19 Analysis Through Chest X-RayscryingdutchmanNo ratings yet
- Classification of COVID 19 Individuals Using Adaptive Neuro Fuzzy Inference SystemDocument15 pagesClassification of COVID 19 Individuals Using Adaptive Neuro Fuzzy Inference Systemosman turanNo ratings yet
- AI4COVID-19: AI Enabled Preliminary Diagnosis For COVID-19 From Cough Samples Via An AppDocument12 pagesAI4COVID-19: AI Enabled Preliminary Diagnosis For COVID-19 From Cough Samples Via An AppVicente CedeñoNo ratings yet
- 1 s2.0 S2352914820302537 MainDocument9 pages1 s2.0 S2352914820302537 MainIshani Vajpayee (P19HSS006)No ratings yet
- Covid - Mtnet: Covid-19 Detection With Multi-Task Deep Learning ApproachesDocument12 pagesCovid - Mtnet: Covid-19 Detection With Multi-Task Deep Learning ApproachesFidel Huanco RamosNo ratings yet
- Brunese Et Al. - 2020Document33 pagesBrunese Et Al. - 2020apatzNo ratings yet
- Containment Plan: Novel Coronavirus Disease 2019 (COVID 19)Document22 pagesContainment Plan: Novel Coronavirus Disease 2019 (COVID 19)Mayank MishraNo ratings yet
- Islam Et Al. - 2023Document18 pagesIslam Et Al. - 2023apatzNo ratings yet
- Pandemic Management For Diseases Similar To COVID-19 Using Deep Learning and 5G CommunicationsDocument6 pagesPandemic Management For Diseases Similar To COVID-19 Using Deep Learning and 5G Communicationsmohammed meladNo ratings yet
- Jurnal Radiologi Sandria Asti Anggita LubisDocument15 pagesJurnal Radiologi Sandria Asti Anggita LubisariesfadhliNo ratings yet
- 1 s2.0 S0924857920301059 MainDocument13 pages1 s2.0 S0924857920301059 MainNini RinNo ratings yet
- Am J Otolaryngol: Vural FidanDocument2 pagesAm J Otolaryngol: Vural FidanDhyo Asy-shidiq HasNo ratings yet
- Journal of Internal Medicine - 2020 - Pascarella - COVID 19 Diagnosis and Management A Comprehensive ReviewDocument15 pagesJournal of Internal Medicine - 2020 - Pascarella - COVID 19 Diagnosis and Management A Comprehensive ReviewOscar Oswaldo SCNo ratings yet
- Shuja2020 Article COVID-19OpenSourceDataSetsACom PDFDocument30 pagesShuja2020 Article COVID-19OpenSourceDataSetsACom PDFSoumya DasNo ratings yet
- Musa Et Al. (2021) - Assessing The Potential Impact of Immunity Waning On The Dynamics of COVID-19 An Endemic Model of COVID-19Document21 pagesMusa Et Al. (2021) - Assessing The Potential Impact of Immunity Waning On The Dynamics of COVID-19 An Endemic Model of COVID-19Cristian Fernando Sanabria BautistaNo ratings yet
- AI4COVID-19: AI Enabled Preliminary Diagnosis For COVID-19 From Cough Samples Via An AppDocument12 pagesAI4COVID-19: AI Enabled Preliminary Diagnosis For COVID-19 From Cough Samples Via An AppSaad ChakkorNo ratings yet
- Ijerph 18 03286 v2Document12 pagesIjerph 18 03286 v2Patel PrathamNo ratings yet
- Joim 13091Document15 pagesJoim 13091sarabisimonaNo ratings yet
- Journal Pre-Proofs: Expert Systems With ApplicationsDocument12 pagesJournal Pre-Proofs: Expert Systems With ApplicationsMi HoangNo ratings yet
- Paper FinalDocument5 pagesPaper FinalAshi GuptaNo ratings yet
- Applsci 12 04825 v2Document23 pagesApplsci 12 04825 v2elkhaoula2009No ratings yet
- Sujet Numero 3Document53 pagesSujet Numero 3naimemed3No ratings yet
- FULLTEXT01Document7 pagesFULLTEXT01YOUSSEF SIYAHNo ratings yet
- TP OverviewDocument8 pagesTP OverviewYOUSSEF SIYAHNo ratings yet
- TP ArticleDocument8 pagesTP ArticleYOUSSEF SIYAHNo ratings yet
- Publications of The Astronomical Society of Australia 1Document8 pagesPublications of The Astronomical Society of Australia 1YOUSSEF SIYAHNo ratings yet
- Publications of The Astronomical Society of Australia 1Document8 pagesPublications of The Astronomical Society of Australia 1YOUSSEF SIYAHNo ratings yet
- BWFF2033 - Topic 5 - Time Value of Money - Part 1Document17 pagesBWFF2033 - Topic 5 - Time Value of Money - Part 1ZiaNaPiramLiNo ratings yet
- One-Port NetworkDocument9 pagesOne-Port NetworkGiwrgosMthNo ratings yet
- FIPS 180-1 - Secure Hash StandardDocument10 pagesFIPS 180-1 - Secure Hash StandardembedhwNo ratings yet
- Lecture 1.2.5 - Relational Model (RM)Document15 pagesLecture 1.2.5 - Relational Model (RM)Annanya JoshiNo ratings yet
- Deep Learning - Lesson PlanDocument5 pagesDeep Learning - Lesson PlanAnonymous xMYE0TiNBcNo ratings yet
- TP - Indd 1 11/1/17 1:59 PMDocument13 pagesTP - Indd 1 11/1/17 1:59 PMG0% (1)
- Write A Program For Error Detecting Code Using CRC-CCITT (16-Bits)Document4 pagesWrite A Program For Error Detecting Code Using CRC-CCITT (16-Bits)study materialNo ratings yet
- 9.08 Variables On Both Sides - WorksheetDocument2 pages9.08 Variables On Both Sides - Worksheetegor.fNo ratings yet
- PID Tutorial: Step Cloop RedDocument8 pagesPID Tutorial: Step Cloop RedTran SangNo ratings yet
- Review Paper On Clustering and Validation TechniquesDocument5 pagesReview Paper On Clustering and Validation TechniquesSarip RahmatNo ratings yet
- ALC Assignment 2019 20Document2 pagesALC Assignment 2019 20deccancollegeNo ratings yet
- PHAS0025 CourseOutlineDocument3 pagesPHAS0025 CourseOutlineo cNo ratings yet
- Summary Business AnalyticsDocument24 pagesSummary Business AnalyticsLUIGIANo ratings yet
- Flannery PDFDocument8 pagesFlannery PDFzoehdiismailNo ratings yet
- Polynomial RegressionDocument6 pagesPolynomial RegressionDeepak kumarNo ratings yet
- QuizzesDocument5 pagesQuizzesWalid BarakatNo ratings yet
- Solutions To Worksheet 1 - Network Diagrams (AON)Document8 pagesSolutions To Worksheet 1 - Network Diagrams (AON)Khathutshelo KharivheNo ratings yet
- 1 5-TutorialforWeek1Document6 pages1 5-TutorialforWeek1rickyNo ratings yet
- Processes of Ideal GasesDocument5 pagesProcesses of Ideal GasesMLNDG boysNo ratings yet
- Data Science ProjectDocument25 pagesData Science ProjectElsa Margarida LoureiroNo ratings yet
- Optimal Control Lecture 28: Indirect Solution MethodsDocument2 pagesOptimal Control Lecture 28: Indirect Solution MethodsAmir ghasemiNo ratings yet
- Coding Interview 6Document677 pagesCoding Interview 6akg299No ratings yet
- dmcs0708 PDFDocument327 pagesdmcs0708 PDFarviandyNo ratings yet
- Addition and Subtraction of MatricesDocument3 pagesAddition and Subtraction of MatricesNia RamNo ratings yet
- Convergence of LMS AlgorithmDocument9 pagesConvergence of LMS AlgorithmsivadanamsNo ratings yet
- EE3331C Feedback Control Systems L5: Feedback Control: Arthur TAYDocument42 pagesEE3331C Feedback Control Systems L5: Feedback Control: Arthur TAYpremsanjith subramaniNo ratings yet
- Chapter#10 (Part#01) SL (K-NN)Document27 pagesChapter#10 (Part#01) SL (K-NN)sajjadimamNo ratings yet