Download as pdf or txt
You might also like
- Tutorial Chapter 4 MemoDocument30 pagesTutorial Chapter 4 Memou20417242No ratings yet
- 03 MLE MAP NBayes-1-21-2015Document40 pages03 MLE MAP NBayes-1-21-2015Muhammad MurtazaNo ratings yet
- Week 3 Homework Suggested SolutionDocument27 pagesWeek 3 Homework Suggested SolutionMr. JarmenNo ratings yet
- Practice Problems (Chapter 12) Kinetics - KEY-1Document5 pagesPractice Problems (Chapter 12) Kinetics - KEY-1SamweliNo ratings yet
- The Binomial Distribution: Univariate DistributionsDocument11 pagesThe Binomial Distribution: Univariate Distributionsbig clapNo ratings yet
- Rating Curve.K. LututDocument28 pagesRating Curve.K. LututdizuNo ratings yet
- Extraction Part 1Document39 pagesExtraction Part 1Akanksha GuptaNo ratings yet
- PHYS3200YDocument4 pagesPHYS3200YyemmanurvishnuNo ratings yet
- Lec 04Document50 pagesLec 04Ibraheim ZidanNo ratings yet
- Tutorial 8 Markov Analysis SolutionDocument5 pagesTutorial 8 Markov Analysis SolutionJum Sheng ChongNo ratings yet
- Influence Lines For BeamsDocument22 pagesInfluence Lines For BeamsErnest BautistaNo ratings yet
- Mechanics of Materials 9th Edition Hibbeler Solutions ManualDocument35 pagesMechanics of Materials 9th Edition Hibbeler Solutions Manualronbowmantdd2bh100% (29)
- Dwnload Full Mechanics of Materials 9th Edition Hibbeler Solutions Manual PDFDocument35 pagesDwnload Full Mechanics of Materials 9th Edition Hibbeler Solutions Manual PDFjerrybriggs7d5t0v100% (9)
- IE 325 HW 4 SolutionsDocument8 pagesIE 325 HW 4 SolutionsOsman ŞentürkNo ratings yet
- 38 - Matrix True FalseDocument4 pages38 - Matrix True FalseShawn Joshua YapNo ratings yet
- Chemical Equilibrium - Tutorial-Answersv1Document14 pagesChemical Equilibrium - Tutorial-Answersv1Farah AinaNo ratings yet
- SHEET (4) : Ain Sham University Faculty of Engineering Structural Eng. Dept. 2 Year Civil 2020-2021 NDDocument4 pagesSHEET (4) : Ain Sham University Faculty of Engineering Structural Eng. Dept. 2 Year Civil 2020-2021 NDstrand strandNo ratings yet
- Contoh Analisis Struktur Balok Bidang:: Matriks Kekakuan Elemen AB (K) AB (Lokal) LDocument15 pagesContoh Analisis Struktur Balok Bidang:: Matriks Kekakuan Elemen AB (K) AB (Lokal) Ldiarto trisnoyuwonoNo ratings yet
- EE539 DesignOfElectricalMachines Project1 Spring2021 v2Document2 pagesEE539 DesignOfElectricalMachines Project1 Spring2021 v2Zhenyu HuoNo ratings yet
- Metodos NumericosejDocument6 pagesMetodos NumericosejLuis CastilloNo ratings yet
- Iodine LabDocument4 pagesIodine LabHuang ViviNo ratings yet
- Damping and Forced Oscillations Resonance ProblemsDocument18 pagesDamping and Forced Oscillations Resonance ProblemsGiuseppe BrandiNo ratings yet
- Hydraulics CE-331Document12 pagesHydraulics CE-331Mahmoud I. MahmoudNo ratings yet
- BaruDocument5 pagesBaruNur MauliskaNo ratings yet
- Nonparametric RegressionDocument24 pagesNonparametric RegressionSNo ratings yet
- Hruzovak,+Menezes EditedDocument13 pagesHruzovak,+Menezes EditedDoha AdelNo ratings yet
- 11 Boolean Algebra and Logic CircuitsDocument10 pages11 Boolean Algebra and Logic CircuitsIan BagunasNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document8 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Dimas bayuzahwaNo ratings yet
- Comparators: Unit-3 Combinational LogicDocument14 pagesComparators: Unit-3 Combinational LogicVenkatesh MunagalaNo ratings yet
- Bus Bar Voltage Drop Calculation: ABC Sub Panel No Line Length (MT) Power Line Current (Amp) Location SR - No Bus Bar NoDocument6 pagesBus Bar Voltage Drop Calculation: ABC Sub Panel No Line Length (MT) Power Line Current (Amp) Location SR - No Bus Bar NoMoazam AliNo ratings yet
- Adjacency PDFDocument5 pagesAdjacency PDFFernando Nicolas Ureta GodoyNo ratings yet
- Busbar Size Calculation 22-8-12Document6 pagesBusbar Size Calculation 22-8-12Francis TomyNo ratings yet
- Tercero A QuímicaDocument17 pagesTercero A Químicakatherine pintado sahuangaNo ratings yet
- Multivariable Control Systems EE640: Assignment-5Document3 pagesMultivariable Control Systems EE640: Assignment-5sandeepNo ratings yet
- BusbarSizecalculation28 5 11Document6 pagesBusbarSizecalculation28 5 11Ahmed SayedNo ratings yet
- Langmuir Isotherm DevelopmentDocument16 pagesLangmuir Isotherm DevelopmentbarlosNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)thibinNo ratings yet
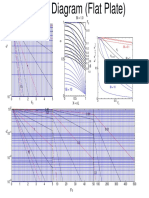
- Heisler Diagram (Flat Plate)Document4 pagesHeisler Diagram (Flat Plate)Ram SinghNo ratings yet
- Figure 7Document2 pagesFigure 7api-3750666No ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Satya Narayana BandaruNo ratings yet
- Busbar Size Calculation 22 8 12Document6 pagesBusbar Size Calculation 22 8 12koyangi jagiyaNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Henry BarriosNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)shoaibNo ratings yet
- Busbar Size CalculationDocument6 pagesBusbar Size Calculationmohammed hassan abdulaleemNo ratings yet
- Busbar-Size CalculationDocument6 pagesBusbar-Size Calculationredulajaypee15No ratings yet
- Basic Input & AnalysisDocument3 pagesBasic Input & AnalysisNikhil PoriyaNo ratings yet
- Results:: A) Experimental Shear CentreDocument4 pagesResults:: A) Experimental Shear Centrekaram bawadiNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)kisan singhNo ratings yet
- Bus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)Document6 pagesBus Bar Voltage Drop Calculation: Bus Bar No SR - No Location Sub Panel No Power Line Length (MT) Line Current (Amp)MANIKANDA100% (1)
- Image - 2023 11 16 - 11 31 10Document2 pagesImage - 2023 11 16 - 11 31 10navid kamravaNo ratings yet
- Machine Learning 10-601, 10-301: TodayDocument44 pagesMachine Learning 10-601, 10-301: TodaySasanka Sekhar SahuNo ratings yet
- Cross-Section Strength of Columns - Design Booklet - Appendix CDocument27 pagesCross-Section Strength of Columns - Design Booklet - Appendix CTrevor LingNo ratings yet
- Spring 2 Spring 1Document4 pagesSpring 2 Spring 1Russel Dule CawaNo ratings yet
- Headworks Counterfort Wall 8mDocument19 pagesHeadworks Counterfort Wall 8mBishal PokharelNo ratings yet
- Example 10.1: A B A BDocument1 pageExample 10.1: A B A BEmerson Chen FuNo ratings yet
- Lecture 9 Activity Furqan Farooq - 18292Document10 pagesLecture 9 Activity Furqan Farooq - 18292Furqan Farooq VadhariaNo ratings yet
- Wall 3333Document1 pageWall 3333mohamedashry993No ratings yet
- Digital AdesDocument17 pagesDigital AdesPraveen KishanNo ratings yet
- The Determination of The Composition of Complex Ions in Solution by A Spectrophotometric MethodDocument5 pagesThe Determination of The Composition of Complex Ions in Solution by A Spectrophotometric MethodA/P SUPAYA SHALININo ratings yet
- Standard-Slope Integration: A New Approach to Numerical IntegrationFrom EverandStandard-Slope Integration: A New Approach to Numerical IntegrationNo ratings yet
- Midterm 2002Document10 pagesMidterm 2002Muhammad MurtazaNo ratings yet
- Midterm 2006Document11 pagesMidterm 2006Muhammad MurtazaNo ratings yet
- Midterm 2010 FDocument15 pagesMidterm 2010 FMuhammad MurtazaNo ratings yet
- Midterm 2004Document11 pagesMidterm 2004Muhammad MurtazaNo ratings yet
- Midterm 2001Document10 pagesMidterm 2001Muhammad MurtazaNo ratings yet
- Midterm SolDocument23 pagesMidterm SolMuhammad MurtazaNo ratings yet
- Midterm 2007 SDocument16 pagesMidterm 2007 SMuhammad MurtazaNo ratings yet
- Midterm2005sp SolutionDocument14 pagesMidterm2005sp SolutionMuhammad MurtazaNo ratings yet
- Midterm SolutionsDocument8 pagesMidterm SolutionsMuhammad MurtazaNo ratings yet
- Joint Mle MapDocument15 pagesJoint Mle MapMuhammad MurtazaNo ratings yet
- Mid ExampleDocument5 pagesMid ExampleMuhammad MurtazaNo ratings yet
- Midexample SolutionsDocument7 pagesMidexample SolutionsMuhammad MurtazaNo ratings yet
- Midterm 2003Document11 pagesMidterm 2003Muhammad MurtazaNo ratings yet
- Final 2006Document15 pagesFinal 2006Muhammad MurtazaNo ratings yet
- Homework 5Document4 pagesHomework 5Muhammad MurtazaNo ratings yet
- Homework 3Document4 pagesHomework 3Muhammad MurtazaNo ratings yet
- Homework 6Document5 pagesHomework 6Muhammad MurtazaNo ratings yet
- Homework 1Document7 pagesHomework 1Muhammad MurtazaNo ratings yet
- Homework 4Document3 pagesHomework 4Muhammad MurtazaNo ratings yet
- Final 2003Document18 pagesFinal 2003Muhammad MurtazaNo ratings yet
- Final 2008 FDocument18 pagesFinal 2008 FMuhammad MurtazaNo ratings yet
- Final 2007 SDocument14 pagesFinal 2007 SMuhammad MurtazaNo ratings yet
- 07 GenDiscr2 2-4-2015Document37 pages07 GenDiscr2 2-4-2015Muhammad MurtazaNo ratings yet
- Homework 2Document4 pagesHomework 2Muhammad MurtazaNo ratings yet
- Final 2002Document18 pagesFinal 2002Muhammad MurtazaNo ratings yet
- 03 MLE MAP NBayes-1-21-2015Document40 pages03 MLE MAP NBayes-1-21-2015Muhammad MurtazaNo ratings yet
- Econometrics AssignmentDocument3 pagesEconometrics AssignmentEliyas Temesgen100% (1)
- Exponential DistributionDocument9 pagesExponential DistributionNeelarka RoyNo ratings yet
- Chapter 4 Expectation, Moments and Moment Generating FunctionsDocument81 pagesChapter 4 Expectation, Moments and Moment Generating FunctionsRylde BolivarNo ratings yet
- Alhar Coba Sendiri 14 Jul 20.14Document21 pagesAlhar Coba Sendiri 14 Jul 20.14Kelvin RamadhanNo ratings yet
- OpenStax Statistics CH04 LectureSlides - IsuDocument48 pagesOpenStax Statistics CH04 LectureSlides - IsuAtiwag, Micha T.No ratings yet
- Multivariate Laplace DistributionDocument3 pagesMultivariate Laplace Distributionanthony777No ratings yet
- Generalized Linear Models: FX Axb C DX Axb C DXDocument11 pagesGeneralized Linear Models: FX Axb C DX Axb C DXAishat OmotolaNo ratings yet
- Day 02-Random Variable and Probability - Part (I)Document34 pagesDay 02-Random Variable and Probability - Part (I)Sparsh VijayvargiaNo ratings yet
- Chapter 5 L10-13Document122 pagesChapter 5 L10-13مصطفى عبدالرحمن جبارNo ratings yet
- Doane5 AppendixA AllTablesExamDocument19 pagesDoane5 AppendixA AllTablesExamHandisNo ratings yet
- Week 3Document22 pagesWeek 3LUISA CARESSE FLAVIANO BRITANICONo ratings yet
- Copulas and Machine Learning PDFDocument104 pagesCopulas and Machine Learning PDFkarim kaifNo ratings yet
- Percentileand TDistributionDocument35 pagesPercentileand TDistributionRhea Rose AlmoguezNo ratings yet
- Assignment 1Document2 pagesAssignment 1CONTACTS CONTACTSNo ratings yet
- Assignments 2015 PDFDocument6 pagesAssignments 2015 PDFAbraham SauvingnonNo ratings yet
- MAS Chap3Document24 pagesMAS Chap3KhangNo ratings yet
- Sample Mean R.V. ̅ : Bern/binDocument1 pageSample Mean R.V. ̅ : Bern/binAmelieNo ratings yet
- ES209 IntroductionDocument17 pagesES209 IntroductionfritzramirezcanawayNo ratings yet
- Sta5 PrevDocument6 pagesSta5 PrevMuhammad Sadman Sakib khan100% (1)
- Practical - Week - 04.2 - Solution - ManualDocument10 pagesPractical - Week - 04.2 - Solution - Manualaman guptaNo ratings yet
- احصاء مرحلة 2جز2 الاحتمالياتDocument16 pagesاحصاء مرحلة 2جز2 الاحتمالياتalhaswbalshkhsy969No ratings yet
- CS2 CMP Upgrade 2022Document128 pagesCS2 CMP Upgrade 2022ChahelNo ratings yet
- Formula Sheet For Final - ExamDocument1 pageFormula Sheet For Final - ExamIsabel EirasNo ratings yet
- Distributions ZoomDocument82 pagesDistributions Zoomvinhtran23042004No ratings yet
- Lesson 2: Finding The Mean and Variance of A Discrete Random VariableDocument9 pagesLesson 2: Finding The Mean and Variance of A Discrete Random VariableB - Clores, Mark RyanNo ratings yet
- Bbs14ege ch05 Discrete Probability DistributionsDocument37 pagesBbs14ege ch05 Discrete Probability DistributionsMickeyNo ratings yet
- MATH 121 (Chapter 6) - Normal DistributionDocument31 pagesMATH 121 (Chapter 6) - Normal DistributionpotsuNo ratings yet
- (Download PDF) First Course in Probability 10th Edition Ross Solutions Manual Full ChapterDocument46 pages(Download PDF) First Course in Probability 10th Edition Ross Solutions Manual Full Chaptermunzirmeffo100% (8)
- Fundamentals of Probability, Random Processes and StatisticsDocument38 pagesFundamentals of Probability, Random Processes and Statisticsab cNo ratings yet