
Thuat Toan CTC
Thuat Toan CTC
You might also like
- Final Project ReportDocument61 pagesFinal Project ReportAtul BhatiaNo ratings yet
- Cloud Computing 101 TutorialDocument203 pagesCloud Computing 101 TutorialYunis Iklil100% (1)
- Load Balancing in Cloud ComputingDocument7 pagesLoad Balancing in Cloud ComputingChandan KumarNo ratings yet
- Ijles V2i6p105 PDFDocument7 pagesIjles V2i6p105 PDFSikkandhar JabbarNo ratings yet
- Proactive Workload Management inDocument11 pagesProactive Workload Management inthebhas1954No ratings yet
- Resource Leasing Cloud Computing Model: A Win-Win Strategy For Resource Owners and Cloud Service ProvidersDocument5 pagesResource Leasing Cloud Computing Model: A Win-Win Strategy For Resource Owners and Cloud Service ProvidersJournal of ComputingNo ratings yet
- Above The Clouds: A Berkeley View of Cloud ComputingDocument23 pagesAbove The Clouds: A Berkeley View of Cloud Computingapi-3931606No ratings yet
- Cloud ComputingDocument6 pagesCloud ComputingmsisipuNo ratings yet
- Job PDFDocument6 pagesJob PDFaswigaNo ratings yet
- Novel Statistical Load Balancing Algorithm For Cloud ComputingDocument10 pagesNovel Statistical Load Balancing Algorithm For Cloud Computingabutalib fadlallahNo ratings yet
- Enhanced Throttled Balancing Algorithm For Cloud ComputingDocument13 pagesEnhanced Throttled Balancing Algorithm For Cloud ComputingAlmazeye MedaNo ratings yet
- Study of Cloud ComputingDocument6 pagesStudy of Cloud ComputingInternational Organization of Scientific Research (IOSR)No ratings yet
- Cloud Computing and Its Key FeaturesDocument13 pagesCloud Computing and Its Key FeaturesMustafiz KhanNo ratings yet
- Cloud Computing Research PaperDocument16 pagesCloud Computing Research PaperRonak ChawlaNo ratings yet
- Litreture ReviewDocument22 pagesLitreture ReviewRamil De SilvaNo ratings yet
- Cloud ComputingDocument12 pagesCloud ComputingmukeshcmNo ratings yet
- Cache Performance Based On Response Time and Cost Effectivein Cloud ComputingDocument10 pagesCache Performance Based On Response Time and Cost Effectivein Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Aloocatin Future ScopeDocument5 pagesAloocatin Future ScopejorisdudaNo ratings yet
- CC Unit 2 Imp QuestionsDocument10 pagesCC Unit 2 Imp QuestionsSahana UrsNo ratings yet
- 2014-You Et Al Hierarchical QueueBased Task SchedulingDocument4 pages2014-You Et Al Hierarchical QueueBased Task SchedulingGonzalo MartinezNo ratings yet
- Abstract FullDocument7 pagesAbstract FullPooja BanNo ratings yet
- Cloud Computing Unit 5Document7 pagesCloud Computing Unit 5kejagoNo ratings yet
- Linear Scheduling Strategy For Resource Allocation in Cloud EnvironmentDocument9 pagesLinear Scheduling Strategy For Resource Allocation in Cloud EnvironmentAnonymous roqsSNZ100% (1)
- Thesis Cloud ComputingDocument14 pagesThesis Cloud Computingbatul_16No ratings yet
- Cloud Computing: Nariman Mirzaei (Nmirzaei@indiana - Edu) Fall 2008Document12 pagesCloud Computing: Nariman Mirzaei (Nmirzaei@indiana - Edu) Fall 2008Anv DeepikaNo ratings yet
- Cloud Architecture: Ournal OF Bject EchnologyDocument10 pagesCloud Architecture: Ournal OF Bject Echnologydayno_majNo ratings yet
- Virtual Machine Migration and Allocation in Cloud Computing: A ReviewDocument4 pagesVirtual Machine Migration and Allocation in Cloud Computing: A ReviewEditor IJTSRDNo ratings yet
- Improving The Performance of Many-Tasks Scientific Computing by Using Data Aware SchedulingDocument13 pagesImproving The Performance of Many-Tasks Scientific Computing by Using Data Aware SchedulingJournal of Computer ApplicationsNo ratings yet
- Cloud Computing RePORTDocument27 pagesCloud Computing RePORTMahesh PandeyNo ratings yet
- Toffetti 2016Document15 pagesToffetti 2016tien nguyenNo ratings yet
- Unit 2 Architecture of Cloud ComputingDocument7 pagesUnit 2 Architecture of Cloud Computingjaysukhv234No ratings yet
- An Enhanced Hyper-Heuristics Task Scheduling in Cloud ComputingDocument6 pagesAn Enhanced Hyper-Heuristics Task Scheduling in Cloud ComputingShrinidhi GowdaNo ratings yet
- An Efficient Improved Weighted Round Robin Load BaDocument8 pagesAn Efficient Improved Weighted Round Robin Load Bamansoor syedNo ratings yet
- A Study of Cloud Computing MethodologyDocument5 pagesA Study of Cloud Computing MethodologyR Dharshini SreeNo ratings yet
- Survey Paper For Maximization of Profit in Cloud ComputingDocument6 pagesSurvey Paper For Maximization of Profit in Cloud ComputingseventhsensegroupNo ratings yet
- Five Characteristics of Cloud ComputingDocument8 pagesFive Characteristics of Cloud ComputingragunathNo ratings yet
- About Cloud ManufaturingDocument22 pagesAbout Cloud ManufaturingThalya RibeiroNo ratings yet
- Unit 1Document37 pagesUnit 1yashika sarodeNo ratings yet
- Improved Virtual Machine Load Balance UsDocument12 pagesImproved Virtual Machine Load Balance UsKemo TufoNo ratings yet
- Unit4 CC Technology and ApplicationsDocument25 pagesUnit4 CC Technology and ApplicationsAyush GuptaNo ratings yet
- 1303 4814Document42 pages1303 4814Usemore100% (1)
- 2Document11 pages2Sourabh porwalNo ratings yet
- Job Scheduling in Cloud Computing: A Review of Selected TechniquesDocument5 pagesJob Scheduling in Cloud Computing: A Review of Selected TechniquesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Cloud Computing: (A Computing Platform For Next-Generation Internet)Document7 pagesCloud Computing: (A Computing Platform For Next-Generation Internet)Srini VasuluNo ratings yet
- 2009 Fifth International Joint Conference On INC, IMS and IDC 2009 Fifth International Joint Conference On INC, IMS and IDCDocument8 pages2009 Fifth International Joint Conference On INC, IMS and IDC 2009 Fifth International Joint Conference On INC, IMS and IDCSmitha VasNo ratings yet
- Resource Management and Scheduling in Cloud EnvironmentDocument8 pagesResource Management and Scheduling in Cloud Environmentvickyvarath100% (1)
- Cloud Computing: A Perspective Study: Received 1 Dec 2008Document10 pagesCloud Computing: A Perspective Study: Received 1 Dec 2008krmrzaNo ratings yet
- Traducción Uncp - Esp UltimoDocument21 pagesTraducción Uncp - Esp UltimoJORGE FRANKLIN GARCIA CUBANo ratings yet
- Topic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BDocument6 pagesTopic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BlailaaabidNo ratings yet
- The Effect of The Resource Consumption Characteristics of Cloud Applications On The Efficiency of Low-Metric Auto Scaling SolutionsDocument9 pagesThe Effect of The Resource Consumption Characteristics of Cloud Applications On The Efficiency of Low-Metric Auto Scaling SolutionsAnonymous roqsSNZNo ratings yet
- FINAL Round Robin 3Document6 pagesFINAL Round Robin 3Aaradhya ShuklaNo ratings yet
- A Study of Infrastructure Clouds: International Journal of Computer Trends and Technology-volume3Issue1 - 2012Document5 pagesA Study of Infrastructure Clouds: International Journal of Computer Trends and Technology-volume3Issue1 - 2012surendiran123No ratings yet
- Related Work 1Document8 pagesRelated Work 1uzma nisarNo ratings yet
- Security Challenges in Cloud Computing: January 2010Document16 pagesSecurity Challenges in Cloud Computing: January 2010kathirdcnNo ratings yet
- Cloud Computing: Ayush Garg 7CS - 17Document22 pagesCloud Computing: Ayush Garg 7CS - 17mridul64No ratings yet
- Cloud Computing: ABSTRACT-Computers Have Become AnDocument5 pagesCloud Computing: ABSTRACT-Computers Have Become AnRavi Shankar JaiswalNo ratings yet
- Cloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707Document31 pagesCloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707divya25sepNo ratings yet
- Challenges of Cloud Compute Load-Balancing AlgorithmsDocument6 pagesChallenges of Cloud Compute Load-Balancing AlgorithmsGopala Krishna SriramNo ratings yet
- Cloud Computing 1Document20 pagesCloud Computing 1Sree LakshmiNo ratings yet
- Free Java Software Developer Resume Word DownloadDocument5 pagesFree Java Software Developer Resume Word DownloadAra Jane RoxasNo ratings yet
- Big Data Analytics For Dynamic Energy Management in Smart GridsDocument9 pagesBig Data Analytics For Dynamic Energy Management in Smart Gridsakshansh chandravanshiNo ratings yet
- 21c Fleet Patching and Provisioning Administrators GuideDocument202 pages21c Fleet Patching and Provisioning Administrators GuidesuhaasNo ratings yet
- Grid vs. Peer-to-Peer: Project Report No. 2Document7 pagesGrid vs. Peer-to-Peer: Project Report No. 2peter55No ratings yet
- CS8791-Cloud Computing UNIT 1 NotesDocument57 pagesCS8791-Cloud Computing UNIT 1 NotesganeshNo ratings yet
- Distributed and Cloud Computing 1st Edition Hwang Solutions ManualDocument14 pagesDistributed and Cloud Computing 1st Edition Hwang Solutions Manualrheumyfernyl35q100% (28)
- nrcs142p2 032035Document10 pagesnrcs142p2 032035Muhammad Abdul FattahNo ratings yet
- Big Data 101 Brief PDFDocument4 pagesBig Data 101 Brief PDFAruna PattamNo ratings yet
- Infor ION Grid Administration GuideDocument89 pagesInfor ION Grid Administration GuideRobin YangNo ratings yet
- Oracle in InsuranceDocument36 pagesOracle in InsuranceVladan DabovicNo ratings yet
- Cloud Computing - CLOUD 2018Document420 pagesCloud Computing - CLOUD 2018gokhan ustaNo ratings yet
- In 100 ApplicationServiceGuide enDocument464 pagesIn 100 ApplicationServiceGuide enSandip ChandaranaNo ratings yet
- Ignite SampleDocument88 pagesIgnite Samplexbsd0% (1)
- Oracle Database 12c Grid Infrastructure Installation GuideDocument248 pagesOracle Database 12c Grid Infrastructure Installation GuideBupBeChanh100% (1)
- Spring Batch DocsDocument137 pagesSpring Batch DocslorellanNo ratings yet
- IT1 ReportingDocument16 pagesIT1 ReportingKarylle SuarezNo ratings yet
- Unlocking Promise Demand SensingDocument20 pagesUnlocking Promise Demand SensingRajvindRathiNo ratings yet
- Taneja Group Evaluating Grid Storage For Enterprise Backup, DR and Archiving NEC HYDRAstor PDFDocument19 pagesTaneja Group Evaluating Grid Storage For Enterprise Backup, DR and Archiving NEC HYDRAstor PDFtelagamsettiNo ratings yet
- Elements of Gloud Computing Security (2016)Document65 pagesElements of Gloud Computing Security (2016)dogevenezianoNo ratings yet
- Alaba Othman Et Al 2017 Internet of Things - Survey PDFDocument19 pagesAlaba Othman Et Al 2017 Internet of Things - Survey PDFLaura Craig100% (1)
- Armor.x.paper - Unk.the Numerical Simulation of Warheads Impact and Blast Phenomena Using Autodyn 2d and Autodyn 3d.grady Hayhurst FairlieDocument12 pagesArmor.x.paper - Unk.the Numerical Simulation of Warheads Impact and Blast Phenomena Using Autodyn 2d and Autodyn 3d.grady Hayhurst Fairliegordon827No ratings yet
- SCOM - Plugin For OEMDocument3 pagesSCOM - Plugin For OEMmjprashanthNo ratings yet
- Openway Riva White PaperDocument8 pagesOpenway Riva White Paperjunaid_libraNo ratings yet
- Introduction To Oracle FormsDocument24 pagesIntroduction To Oracle Formsrevanth191794No ratings yet
- Globl Exchange of Resources FinalDocument20 pagesGlobl Exchange of Resources Finaljaishree jain67% (3)
- Simgrid TutorialDocument142 pagesSimgrid Tutorialroyal1352No ratings yet
- Unit 16assignment 1 CloudDocument55 pagesUnit 16assignment 1 CloudNguyễn Hải Anh100% (1)
- GridDocument51 pagesGridapi-3741442No ratings yet
- Cloud ComputingDocument40 pagesCloud ComputingmeyukiNo ratings yet



































































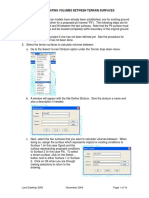






















Download as pdf or txt
You might also like
- Final Project ReportDocument61 pagesFinal Project ReportAtul BhatiaNo ratings yet
- Cloud Computing 101 TutorialDocument203 pagesCloud Computing 101 TutorialYunis Iklil100% (1)
- Load Balancing in Cloud ComputingDocument7 pagesLoad Balancing in Cloud ComputingChandan KumarNo ratings yet
- Ijles V2i6p105 PDFDocument7 pagesIjles V2i6p105 PDFSikkandhar JabbarNo ratings yet
- Proactive Workload Management inDocument11 pagesProactive Workload Management inthebhas1954No ratings yet
- Resource Leasing Cloud Computing Model: A Win-Win Strategy For Resource Owners and Cloud Service ProvidersDocument5 pagesResource Leasing Cloud Computing Model: A Win-Win Strategy For Resource Owners and Cloud Service ProvidersJournal of ComputingNo ratings yet
- Above The Clouds: A Berkeley View of Cloud ComputingDocument23 pagesAbove The Clouds: A Berkeley View of Cloud Computingapi-3931606No ratings yet
- Cloud ComputingDocument6 pagesCloud ComputingmsisipuNo ratings yet
- Job PDFDocument6 pagesJob PDFaswigaNo ratings yet
- Novel Statistical Load Balancing Algorithm For Cloud ComputingDocument10 pagesNovel Statistical Load Balancing Algorithm For Cloud Computingabutalib fadlallahNo ratings yet
- Enhanced Throttled Balancing Algorithm For Cloud ComputingDocument13 pagesEnhanced Throttled Balancing Algorithm For Cloud ComputingAlmazeye MedaNo ratings yet
- Study of Cloud ComputingDocument6 pagesStudy of Cloud ComputingInternational Organization of Scientific Research (IOSR)No ratings yet
- Cloud Computing and Its Key FeaturesDocument13 pagesCloud Computing and Its Key FeaturesMustafiz KhanNo ratings yet
- Cloud Computing Research PaperDocument16 pagesCloud Computing Research PaperRonak ChawlaNo ratings yet
- Litreture ReviewDocument22 pagesLitreture ReviewRamil De SilvaNo ratings yet
- Cloud ComputingDocument12 pagesCloud ComputingmukeshcmNo ratings yet
- Cache Performance Based On Response Time and Cost Effectivein Cloud ComputingDocument10 pagesCache Performance Based On Response Time and Cost Effectivein Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Aloocatin Future ScopeDocument5 pagesAloocatin Future ScopejorisdudaNo ratings yet
- CC Unit 2 Imp QuestionsDocument10 pagesCC Unit 2 Imp QuestionsSahana UrsNo ratings yet
- 2014-You Et Al Hierarchical QueueBased Task SchedulingDocument4 pages2014-You Et Al Hierarchical QueueBased Task SchedulingGonzalo MartinezNo ratings yet
- Abstract FullDocument7 pagesAbstract FullPooja BanNo ratings yet
- Cloud Computing Unit 5Document7 pagesCloud Computing Unit 5kejagoNo ratings yet
- Linear Scheduling Strategy For Resource Allocation in Cloud EnvironmentDocument9 pagesLinear Scheduling Strategy For Resource Allocation in Cloud EnvironmentAnonymous roqsSNZ100% (1)
- Thesis Cloud ComputingDocument14 pagesThesis Cloud Computingbatul_16No ratings yet
- Cloud Computing: Nariman Mirzaei (Nmirzaei@indiana - Edu) Fall 2008Document12 pagesCloud Computing: Nariman Mirzaei (Nmirzaei@indiana - Edu) Fall 2008Anv DeepikaNo ratings yet
- Cloud Architecture: Ournal OF Bject EchnologyDocument10 pagesCloud Architecture: Ournal OF Bject Echnologydayno_majNo ratings yet
- Virtual Machine Migration and Allocation in Cloud Computing: A ReviewDocument4 pagesVirtual Machine Migration and Allocation in Cloud Computing: A ReviewEditor IJTSRDNo ratings yet
- Improving The Performance of Many-Tasks Scientific Computing by Using Data Aware SchedulingDocument13 pagesImproving The Performance of Many-Tasks Scientific Computing by Using Data Aware SchedulingJournal of Computer ApplicationsNo ratings yet
- Cloud Computing RePORTDocument27 pagesCloud Computing RePORTMahesh PandeyNo ratings yet
- Toffetti 2016Document15 pagesToffetti 2016tien nguyenNo ratings yet
- Unit 2 Architecture of Cloud ComputingDocument7 pagesUnit 2 Architecture of Cloud Computingjaysukhv234No ratings yet
- An Enhanced Hyper-Heuristics Task Scheduling in Cloud ComputingDocument6 pagesAn Enhanced Hyper-Heuristics Task Scheduling in Cloud ComputingShrinidhi GowdaNo ratings yet
- An Efficient Improved Weighted Round Robin Load BaDocument8 pagesAn Efficient Improved Weighted Round Robin Load Bamansoor syedNo ratings yet
- A Study of Cloud Computing MethodologyDocument5 pagesA Study of Cloud Computing MethodologyR Dharshini SreeNo ratings yet
- Survey Paper For Maximization of Profit in Cloud ComputingDocument6 pagesSurvey Paper For Maximization of Profit in Cloud ComputingseventhsensegroupNo ratings yet
- Five Characteristics of Cloud ComputingDocument8 pagesFive Characteristics of Cloud ComputingragunathNo ratings yet
- About Cloud ManufaturingDocument22 pagesAbout Cloud ManufaturingThalya RibeiroNo ratings yet
- Unit 1Document37 pagesUnit 1yashika sarodeNo ratings yet
- Improved Virtual Machine Load Balance UsDocument12 pagesImproved Virtual Machine Load Balance UsKemo TufoNo ratings yet
- Unit4 CC Technology and ApplicationsDocument25 pagesUnit4 CC Technology and ApplicationsAyush GuptaNo ratings yet
- 1303 4814Document42 pages1303 4814Usemore100% (1)
- 2Document11 pages2Sourabh porwalNo ratings yet
- Job Scheduling in Cloud Computing: A Review of Selected TechniquesDocument5 pagesJob Scheduling in Cloud Computing: A Review of Selected TechniquesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Cloud Computing: (A Computing Platform For Next-Generation Internet)Document7 pagesCloud Computing: (A Computing Platform For Next-Generation Internet)Srini VasuluNo ratings yet
- 2009 Fifth International Joint Conference On INC, IMS and IDC 2009 Fifth International Joint Conference On INC, IMS and IDCDocument8 pages2009 Fifth International Joint Conference On INC, IMS and IDC 2009 Fifth International Joint Conference On INC, IMS and IDCSmitha VasNo ratings yet
- Resource Management and Scheduling in Cloud EnvironmentDocument8 pagesResource Management and Scheduling in Cloud Environmentvickyvarath100% (1)
- Cloud Computing: A Perspective Study: Received 1 Dec 2008Document10 pagesCloud Computing: A Perspective Study: Received 1 Dec 2008krmrzaNo ratings yet
- Traducción Uncp - Esp UltimoDocument21 pagesTraducción Uncp - Esp UltimoJORGE FRANKLIN GARCIA CUBANo ratings yet
- Topic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BDocument6 pagesTopic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BlailaaabidNo ratings yet
- The Effect of The Resource Consumption Characteristics of Cloud Applications On The Efficiency of Low-Metric Auto Scaling SolutionsDocument9 pagesThe Effect of The Resource Consumption Characteristics of Cloud Applications On The Efficiency of Low-Metric Auto Scaling SolutionsAnonymous roqsSNZNo ratings yet
- FINAL Round Robin 3Document6 pagesFINAL Round Robin 3Aaradhya ShuklaNo ratings yet
- A Study of Infrastructure Clouds: International Journal of Computer Trends and Technology-volume3Issue1 - 2012Document5 pagesA Study of Infrastructure Clouds: International Journal of Computer Trends and Technology-volume3Issue1 - 2012surendiran123No ratings yet
- Related Work 1Document8 pagesRelated Work 1uzma nisarNo ratings yet
- Security Challenges in Cloud Computing: January 2010Document16 pagesSecurity Challenges in Cloud Computing: January 2010kathirdcnNo ratings yet
- Cloud Computing: Ayush Garg 7CS - 17Document22 pagesCloud Computing: Ayush Garg 7CS - 17mridul64No ratings yet
- Cloud Computing: ABSTRACT-Computers Have Become AnDocument5 pagesCloud Computing: ABSTRACT-Computers Have Become AnRavi Shankar JaiswalNo ratings yet
- Cloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707Document31 pagesCloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707divya25sepNo ratings yet
- Challenges of Cloud Compute Load-Balancing AlgorithmsDocument6 pagesChallenges of Cloud Compute Load-Balancing AlgorithmsGopala Krishna SriramNo ratings yet
- Cloud Computing 1Document20 pagesCloud Computing 1Sree LakshmiNo ratings yet
- Free Java Software Developer Resume Word DownloadDocument5 pagesFree Java Software Developer Resume Word DownloadAra Jane RoxasNo ratings yet
- Big Data Analytics For Dynamic Energy Management in Smart GridsDocument9 pagesBig Data Analytics For Dynamic Energy Management in Smart Gridsakshansh chandravanshiNo ratings yet
- 21c Fleet Patching and Provisioning Administrators GuideDocument202 pages21c Fleet Patching and Provisioning Administrators GuidesuhaasNo ratings yet
- Grid vs. Peer-to-Peer: Project Report No. 2Document7 pagesGrid vs. Peer-to-Peer: Project Report No. 2peter55No ratings yet
- CS8791-Cloud Computing UNIT 1 NotesDocument57 pagesCS8791-Cloud Computing UNIT 1 NotesganeshNo ratings yet
- Distributed and Cloud Computing 1st Edition Hwang Solutions ManualDocument14 pagesDistributed and Cloud Computing 1st Edition Hwang Solutions Manualrheumyfernyl35q100% (28)
- nrcs142p2 032035Document10 pagesnrcs142p2 032035Muhammad Abdul FattahNo ratings yet
- Big Data 101 Brief PDFDocument4 pagesBig Data 101 Brief PDFAruna PattamNo ratings yet
- Infor ION Grid Administration GuideDocument89 pagesInfor ION Grid Administration GuideRobin YangNo ratings yet
- Oracle in InsuranceDocument36 pagesOracle in InsuranceVladan DabovicNo ratings yet
- Cloud Computing - CLOUD 2018Document420 pagesCloud Computing - CLOUD 2018gokhan ustaNo ratings yet
- In 100 ApplicationServiceGuide enDocument464 pagesIn 100 ApplicationServiceGuide enSandip ChandaranaNo ratings yet
- Ignite SampleDocument88 pagesIgnite Samplexbsd0% (1)
- Oracle Database 12c Grid Infrastructure Installation GuideDocument248 pagesOracle Database 12c Grid Infrastructure Installation GuideBupBeChanh100% (1)
- Spring Batch DocsDocument137 pagesSpring Batch DocslorellanNo ratings yet
- IT1 ReportingDocument16 pagesIT1 ReportingKarylle SuarezNo ratings yet
- Unlocking Promise Demand SensingDocument20 pagesUnlocking Promise Demand SensingRajvindRathiNo ratings yet
- Taneja Group Evaluating Grid Storage For Enterprise Backup, DR and Archiving NEC HYDRAstor PDFDocument19 pagesTaneja Group Evaluating Grid Storage For Enterprise Backup, DR and Archiving NEC HYDRAstor PDFtelagamsettiNo ratings yet
- Elements of Gloud Computing Security (2016)Document65 pagesElements of Gloud Computing Security (2016)dogevenezianoNo ratings yet
- Alaba Othman Et Al 2017 Internet of Things - Survey PDFDocument19 pagesAlaba Othman Et Al 2017 Internet of Things - Survey PDFLaura Craig100% (1)
- Armor.x.paper - Unk.the Numerical Simulation of Warheads Impact and Blast Phenomena Using Autodyn 2d and Autodyn 3d.grady Hayhurst FairlieDocument12 pagesArmor.x.paper - Unk.the Numerical Simulation of Warheads Impact and Blast Phenomena Using Autodyn 2d and Autodyn 3d.grady Hayhurst Fairliegordon827No ratings yet
- SCOM - Plugin For OEMDocument3 pagesSCOM - Plugin For OEMmjprashanthNo ratings yet
- Openway Riva White PaperDocument8 pagesOpenway Riva White Paperjunaid_libraNo ratings yet
- Introduction To Oracle FormsDocument24 pagesIntroduction To Oracle Formsrevanth191794No ratings yet
- Globl Exchange of Resources FinalDocument20 pagesGlobl Exchange of Resources Finaljaishree jain67% (3)
- Simgrid TutorialDocument142 pagesSimgrid Tutorialroyal1352No ratings yet
- Unit 16assignment 1 CloudDocument55 pagesUnit 16assignment 1 CloudNguyễn Hải Anh100% (1)
- GridDocument51 pagesGridapi-3741442No ratings yet
- Cloud ComputingDocument40 pagesCloud ComputingmeyukiNo ratings yet