
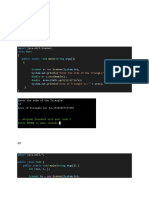
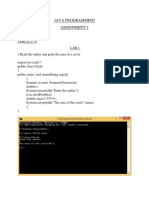
Basic Algorithm Assignment
Basic Algorithm Assignment
You might also like
- TM 11398Document592 pagesTM 11398krill.copco50% (2)
- Lab 5,6,7Document20 pagesLab 5,6,7Huzaifa KhanNo ratings yet
- Productivity Rate (Piping Works)Document21 pagesProductivity Rate (Piping Works)Ahmed Essam TimonNo ratings yet
- What Is RAID Control PDFDocument6 pagesWhat Is RAID Control PDFAhmedNo ratings yet
- Lab File DaaDocument25 pagesLab File Daamahakmahak49793No ratings yet
- KUTTYDocument37 pagesKUTTYrajalakshmishankar4No ratings yet
- Java Interview Programs 2Document10 pagesJava Interview Programs 2prathap7475No ratings yet
- DAA Lab ProgrammesDocument9 pagesDAA Lab ProgrammesBhuvana ThimmiReddyNo ratings yet
- EshanDocument19 pagesEshancebex22655No ratings yet
- Dsa AssignmentDocument37 pagesDsa AssignmentAmarnath Kumar SharmaNo ratings yet
- 18BCE2196 19thfebDocument8 pages18BCE2196 19thfebSaksham GoyalNo ratings yet
- Java Primary CodesDocument17 pagesJava Primary CodesBabai DasNo ratings yet
- Write A Java Program To Print All Real Solutions To The Quadratic EquationDocument30 pagesWrite A Java Program To Print All Real Solutions To The Quadratic EquationNagar Andal KalpanaNo ratings yet
- r16 JavaDocument61 pagesr16 Javajani28cse100% (4)
- AdapdfDocument43 pagesAdapdfMunavvar PopatiyaNo ratings yet
- Java Programs1Document58 pagesJava Programs1Pushpalatha AlavalaNo ratings yet
- NimsabdaDocument36 pagesNimsabdanimanshu harshNo ratings yet
- Tcs Java ProgramsDocument15 pagesTcs Java Programsbhavana TNo ratings yet
- Untitled DocumentDocument33 pagesUntitled Documentmunirajum2622No ratings yet
- Questions: Program For String Reversal Without Using Inbuilt FunctionDocument14 pagesQuestions: Program For String Reversal Without Using Inbuilt FunctionEkta YadavNo ratings yet
- Class10 ProjectDocument36 pagesClass10 ProjectAshish GroverNo ratings yet
- S1-Aman Jain (0311604420)Document87 pagesS1-Aman Jain (0311604420)AMAN JAINNo ratings yet
- Java DA 2Document7 pagesJava DA 2hartz techNo ratings yet
- Java NewDocument16 pagesJava Newvinayaksingh.fakeNo ratings yet
- DaafileDocument40 pagesDaafileSanehNo ratings yet
- LAB 1: Programming in C To Analyse The Complexity of Different ProgramsDocument28 pagesLAB 1: Programming in C To Analyse The Complexity of Different Programsaayutiwari2003No ratings yet
- Java PracticalDocument25 pagesJava PracticalH04Rishi UttamNo ratings yet
- DAA Practical CodeDocument6 pagesDAA Practical Codesakshichaudhari459No ratings yet
- JavaLab PartA&B ManualDocument24 pagesJavaLab PartA&B ManualPreeti SharmaNo ratings yet
- Java Lab Record NewDocument49 pagesJava Lab Record NewA0554No ratings yet
- Core Java QuestionsDocument16 pagesCore Java QuestionsPankaj Bisht100% (1)
- B.SC (Computer SC Ience) Object Oriente D Programming With Java and Data Structures Lab Programs-Data StructuresDocument31 pagesB.SC (Computer SC Ience) Object Oriente D Programming With Java and Data Structures Lab Programs-Data StructuresPrasanth KumarNo ratings yet
- Week 3: Import Java - Util.scanner Public Class Sum - Avg - Array (Public Static Void Main (String Args ) (Document23 pagesWeek 3: Import Java - Util.scanner Public Class Sum - Avg - Array (Public Static Void Main (String Args ) (Bikram DeNo ratings yet
- OOP Lab Record DdvdaDocument95 pagesOOP Lab Record DdvdaDevelop with AcelogicNo ratings yet
- PF A-03-B Amaan AhmadDocument13 pagesPF A-03-B Amaan Ahmadtota10694No ratings yet
- javaLabDocument7 pagesjavaLabDivyanshu KumarNo ratings yet
- Java Lab ManualDocument22 pagesJava Lab ManualABIN GEORGENo ratings yet
- Java DA 2Document7 pagesJava DA 2hartz techNo ratings yet
- Name-Shail Singh Roll - 2170124Document45 pagesName-Shail Singh Roll - 2170124124 SHAIL SINGHNo ratings yet
- 21K-3828 Lab8Document11 pages21K-3828 Lab8zayn khanNo ratings yet
- Java ProgramsDocument26 pagesJava Programschristinamary2607No ratings yet
- Java Programming LabDocument44 pagesJava Programming Labsoundar23No ratings yet
- Akash Kumar Mishra: Program 1Document50 pagesAkash Kumar Mishra: Program 1Sandeep KumarNo ratings yet
- Java Sample ProgramsDocument17 pagesJava Sample ProgramsValerie ValloNo ratings yet
- Lab 5,6,7Document18 pagesLab 5,6,7Huzaifa KhanNo ratings yet
- Lab Manual Java IGNOU Sem 2Document56 pagesLab Manual Java IGNOU Sem 2Vipin KA100% (1)
- Ds CodesDocument13 pagesDs CodesMuhammad Kashif BhattiNo ratings yet
- Asses Ement 3Document32 pagesAsses Ement 3NikhilNo ratings yet
- 22K-4818 - Lab 5Document4 pages22K-4818 - Lab 5k224818No ratings yet
- 22 Feb 18bce2196Document12 pages22 Feb 18bce2196Saksham GoyalNo ratings yet
- DocumentDocument29 pagesDocumentsharmamohit5823No ratings yet
- 036 Rahul Mishra Java File - 1 - 1 - 1Document62 pages036 Rahul Mishra Java File - 1 - 1 - 1036 Pradhuman T17No ratings yet
- Oops Assaigment in JavaDocument5 pagesOops Assaigment in JavaIkrash officialNo ratings yet
- 22K-4818 - Lab 3Document5 pages22K-4818 - Lab 3k224818No ratings yet
- No1-/ Program For Sorting The ArrayDocument24 pagesNo1-/ Program For Sorting The ArrayManoj NaikNo ratings yet
- Key-Test-1 18SC2009 Object Oriented ProgrammingDocument25 pagesKey-Test-1 18SC2009 Object Oriented Programmingpriya uppalaNo ratings yet
- wap To Show The Concept of Function Overridding Class FigureDocument19 pageswap To Show The Concept of Function Overridding Class FigureAnkush VermaNo ratings yet
- Final Assignment Java AkshadDocument41 pagesFinal Assignment Java AkshadAkshad JaiswalNo ratings yet
- Public Class Public Static Void Int New Int If Return For IntDocument18 pagesPublic Class Public Static Void Int New Int If Return For Intshwetha kNo ratings yet
- Java Lap ManualDocument37 pagesJava Lap ManualVishvaNo ratings yet
- Java ProgrammingDocument26 pagesJava Programmingsupriya100% (2)
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Gear Trains: 8.1. Angular Velocity RatioDocument16 pagesGear Trains: 8.1. Angular Velocity RatioaddisudagneNo ratings yet
- Jewellery Shop Design 3dDocument5 pagesJewellery Shop Design 3dTrường Thọ NguyễnNo ratings yet
- Quarter 3 - Las No. 1 (Week 5-7) Active Recreation (Street and Hip-Hop Dances) (Pe10Pf-Iiia-H-39, Pe10Pf-Lllc-H-45)Document11 pagesQuarter 3 - Las No. 1 (Week 5-7) Active Recreation (Street and Hip-Hop Dances) (Pe10Pf-Iiia-H-39, Pe10Pf-Lllc-H-45)hakkensNo ratings yet
- Unit VII Lecture NotesDocument3 pagesUnit VII Lecture NotesSteve Sullivan100% (2)
- BDA 542 V3 - powerCON TRUE 1 TOP - NAC3MX-W-TOPDocument2 pagesBDA 542 V3 - powerCON TRUE 1 TOP - NAC3MX-W-TOPluis manuelNo ratings yet
- (HMI-LP-RT30 + R131-A - User Manual) A06 - ENDocument110 pages(HMI-LP-RT30 + R131-A - User Manual) A06 - ENrehanNo ratings yet
- Case Study of WapdaDocument34 pagesCase Study of WapdaImran Chaudhry100% (1)
- Material Balance PDFDocument31 pagesMaterial Balance PDFApril Joy HaroNo ratings yet
- Business Presentation YAKULTDocument12 pagesBusiness Presentation YAKULTJosuaNo ratings yet
- Air Track Gizmo - ExploreLearningDocument4 pagesAir Track Gizmo - ExploreLearningJeremy Gomez-RojasNo ratings yet
- MG 2 - TEMA 1 Limba EnglezaDocument4 pagesMG 2 - TEMA 1 Limba Englezamimi12345678910No ratings yet
- The Normal DistributionDocument30 pagesThe Normal DistributionJohn Rich CaidicNo ratings yet
- Ag4q-212s KBDocument2 pagesAg4q-212s KBhtek.thunderainNo ratings yet
- Premium HC: 120 Halfcell Monocrystalline High Performance Solar ModuleDocument2 pagesPremium HC: 120 Halfcell Monocrystalline High Performance Solar ModuleMujahed Al-HamatiNo ratings yet
- Visual Storytelling The Digital Video Documentary - Original PDFDocument44 pagesVisual Storytelling The Digital Video Documentary - Original PDFjparanoti100% (1)
- How To Keep Your Brain HealthyDocument3 pagesHow To Keep Your Brain HealthySyahidah IzzatiNo ratings yet
- Fetomaternal Hemorrhage (FMH), An Update Review of LiteratureDocument35 pagesFetomaternal Hemorrhage (FMH), An Update Review of LiteratureEugenia Jeniffer JNo ratings yet
- Uremic EncephalophatyDocument48 pagesUremic EncephalophatySindi LadayaNo ratings yet
- KONAN Emmanuel Sales Technical Engineer 16 Juin 23Document1 pageKONAN Emmanuel Sales Technical Engineer 16 Juin 23EMMANUEL KONANNo ratings yet
- (A) Design - Introduction To Transformer DesignDocument16 pages(A) Design - Introduction To Transformer DesignZineddine BENOUADAHNo ratings yet
- Electronics Cooling: Mechanical Power Engineering DeptDocument22 pagesElectronics Cooling: Mechanical Power Engineering DeptneilNo ratings yet
- 5 25 17 Migraines PowerPointDocument40 pages5 25 17 Migraines PowerPointSaifi AlamNo ratings yet
- 3.1 Clothing Performance Requirements - March 22Document60 pages3.1 Clothing Performance Requirements - March 22Rohan KabirNo ratings yet
- 02 Flyer Beverly LR enDocument2 pages02 Flyer Beverly LR enluisgabrielbuca2246No ratings yet
- Is-Cal01 Design Carbon Accounting On Site Rev.02Document6 pagesIs-Cal01 Design Carbon Accounting On Site Rev.02shoba9945No ratings yet
- Kore Network Device ConfigurationDocument61 pagesKore Network Device ConfigurationEllaziaNo ratings yet
- Therapeutic Diet Manual: DIRECTIVE #4311Document27 pagesTherapeutic Diet Manual: DIRECTIVE #4311DuNo ratings yet























































































Download as pdf or txt
You might also like
- TM 11398Document592 pagesTM 11398krill.copco50% (2)
- Lab 5,6,7Document20 pagesLab 5,6,7Huzaifa KhanNo ratings yet
- Productivity Rate (Piping Works)Document21 pagesProductivity Rate (Piping Works)Ahmed Essam TimonNo ratings yet
- What Is RAID Control PDFDocument6 pagesWhat Is RAID Control PDFAhmedNo ratings yet
- Lab File DaaDocument25 pagesLab File Daamahakmahak49793No ratings yet
- KUTTYDocument37 pagesKUTTYrajalakshmishankar4No ratings yet
- Java Interview Programs 2Document10 pagesJava Interview Programs 2prathap7475No ratings yet
- DAA Lab ProgrammesDocument9 pagesDAA Lab ProgrammesBhuvana ThimmiReddyNo ratings yet
- EshanDocument19 pagesEshancebex22655No ratings yet
- Dsa AssignmentDocument37 pagesDsa AssignmentAmarnath Kumar SharmaNo ratings yet
- 18BCE2196 19thfebDocument8 pages18BCE2196 19thfebSaksham GoyalNo ratings yet
- Java Primary CodesDocument17 pagesJava Primary CodesBabai DasNo ratings yet
- Write A Java Program To Print All Real Solutions To The Quadratic EquationDocument30 pagesWrite A Java Program To Print All Real Solutions To The Quadratic EquationNagar Andal KalpanaNo ratings yet
- r16 JavaDocument61 pagesr16 Javajani28cse100% (4)
- AdapdfDocument43 pagesAdapdfMunavvar PopatiyaNo ratings yet
- Java Programs1Document58 pagesJava Programs1Pushpalatha AlavalaNo ratings yet
- NimsabdaDocument36 pagesNimsabdanimanshu harshNo ratings yet
- Tcs Java ProgramsDocument15 pagesTcs Java Programsbhavana TNo ratings yet
- Untitled DocumentDocument33 pagesUntitled Documentmunirajum2622No ratings yet
- Questions: Program For String Reversal Without Using Inbuilt FunctionDocument14 pagesQuestions: Program For String Reversal Without Using Inbuilt FunctionEkta YadavNo ratings yet
- Class10 ProjectDocument36 pagesClass10 ProjectAshish GroverNo ratings yet
- S1-Aman Jain (0311604420)Document87 pagesS1-Aman Jain (0311604420)AMAN JAINNo ratings yet
- Java DA 2Document7 pagesJava DA 2hartz techNo ratings yet
- Java NewDocument16 pagesJava Newvinayaksingh.fakeNo ratings yet
- DaafileDocument40 pagesDaafileSanehNo ratings yet
- LAB 1: Programming in C To Analyse The Complexity of Different ProgramsDocument28 pagesLAB 1: Programming in C To Analyse The Complexity of Different Programsaayutiwari2003No ratings yet
- Java PracticalDocument25 pagesJava PracticalH04Rishi UttamNo ratings yet
- DAA Practical CodeDocument6 pagesDAA Practical Codesakshichaudhari459No ratings yet
- JavaLab PartA&B ManualDocument24 pagesJavaLab PartA&B ManualPreeti SharmaNo ratings yet
- Java Lab Record NewDocument49 pagesJava Lab Record NewA0554No ratings yet
- Core Java QuestionsDocument16 pagesCore Java QuestionsPankaj Bisht100% (1)
- B.SC (Computer SC Ience) Object Oriente D Programming With Java and Data Structures Lab Programs-Data StructuresDocument31 pagesB.SC (Computer SC Ience) Object Oriente D Programming With Java and Data Structures Lab Programs-Data StructuresPrasanth KumarNo ratings yet
- Week 3: Import Java - Util.scanner Public Class Sum - Avg - Array (Public Static Void Main (String Args ) (Document23 pagesWeek 3: Import Java - Util.scanner Public Class Sum - Avg - Array (Public Static Void Main (String Args ) (Bikram DeNo ratings yet
- OOP Lab Record DdvdaDocument95 pagesOOP Lab Record DdvdaDevelop with AcelogicNo ratings yet
- PF A-03-B Amaan AhmadDocument13 pagesPF A-03-B Amaan Ahmadtota10694No ratings yet
- javaLabDocument7 pagesjavaLabDivyanshu KumarNo ratings yet
- Java Lab ManualDocument22 pagesJava Lab ManualABIN GEORGENo ratings yet
- Java DA 2Document7 pagesJava DA 2hartz techNo ratings yet
- Name-Shail Singh Roll - 2170124Document45 pagesName-Shail Singh Roll - 2170124124 SHAIL SINGHNo ratings yet
- 21K-3828 Lab8Document11 pages21K-3828 Lab8zayn khanNo ratings yet
- Java ProgramsDocument26 pagesJava Programschristinamary2607No ratings yet
- Java Programming LabDocument44 pagesJava Programming Labsoundar23No ratings yet
- Akash Kumar Mishra: Program 1Document50 pagesAkash Kumar Mishra: Program 1Sandeep KumarNo ratings yet
- Java Sample ProgramsDocument17 pagesJava Sample ProgramsValerie ValloNo ratings yet
- Lab 5,6,7Document18 pagesLab 5,6,7Huzaifa KhanNo ratings yet
- Lab Manual Java IGNOU Sem 2Document56 pagesLab Manual Java IGNOU Sem 2Vipin KA100% (1)
- Ds CodesDocument13 pagesDs CodesMuhammad Kashif BhattiNo ratings yet
- Asses Ement 3Document32 pagesAsses Ement 3NikhilNo ratings yet
- 22K-4818 - Lab 5Document4 pages22K-4818 - Lab 5k224818No ratings yet
- 22 Feb 18bce2196Document12 pages22 Feb 18bce2196Saksham GoyalNo ratings yet
- DocumentDocument29 pagesDocumentsharmamohit5823No ratings yet
- 036 Rahul Mishra Java File - 1 - 1 - 1Document62 pages036 Rahul Mishra Java File - 1 - 1 - 1036 Pradhuman T17No ratings yet
- Oops Assaigment in JavaDocument5 pagesOops Assaigment in JavaIkrash officialNo ratings yet
- 22K-4818 - Lab 3Document5 pages22K-4818 - Lab 3k224818No ratings yet
- No1-/ Program For Sorting The ArrayDocument24 pagesNo1-/ Program For Sorting The ArrayManoj NaikNo ratings yet
- Key-Test-1 18SC2009 Object Oriented ProgrammingDocument25 pagesKey-Test-1 18SC2009 Object Oriented Programmingpriya uppalaNo ratings yet
- wap To Show The Concept of Function Overridding Class FigureDocument19 pageswap To Show The Concept of Function Overridding Class FigureAnkush VermaNo ratings yet
- Final Assignment Java AkshadDocument41 pagesFinal Assignment Java AkshadAkshad JaiswalNo ratings yet
- Public Class Public Static Void Int New Int If Return For IntDocument18 pagesPublic Class Public Static Void Int New Int If Return For Intshwetha kNo ratings yet
- Java Lap ManualDocument37 pagesJava Lap ManualVishvaNo ratings yet
- Java ProgrammingDocument26 pagesJava Programmingsupriya100% (2)
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Gear Trains: 8.1. Angular Velocity RatioDocument16 pagesGear Trains: 8.1. Angular Velocity RatioaddisudagneNo ratings yet
- Jewellery Shop Design 3dDocument5 pagesJewellery Shop Design 3dTrường Thọ NguyễnNo ratings yet
- Quarter 3 - Las No. 1 (Week 5-7) Active Recreation (Street and Hip-Hop Dances) (Pe10Pf-Iiia-H-39, Pe10Pf-Lllc-H-45)Document11 pagesQuarter 3 - Las No. 1 (Week 5-7) Active Recreation (Street and Hip-Hop Dances) (Pe10Pf-Iiia-H-39, Pe10Pf-Lllc-H-45)hakkensNo ratings yet
- Unit VII Lecture NotesDocument3 pagesUnit VII Lecture NotesSteve Sullivan100% (2)
- BDA 542 V3 - powerCON TRUE 1 TOP - NAC3MX-W-TOPDocument2 pagesBDA 542 V3 - powerCON TRUE 1 TOP - NAC3MX-W-TOPluis manuelNo ratings yet
- (HMI-LP-RT30 + R131-A - User Manual) A06 - ENDocument110 pages(HMI-LP-RT30 + R131-A - User Manual) A06 - ENrehanNo ratings yet
- Case Study of WapdaDocument34 pagesCase Study of WapdaImran Chaudhry100% (1)
- Material Balance PDFDocument31 pagesMaterial Balance PDFApril Joy HaroNo ratings yet
- Business Presentation YAKULTDocument12 pagesBusiness Presentation YAKULTJosuaNo ratings yet
- Air Track Gizmo - ExploreLearningDocument4 pagesAir Track Gizmo - ExploreLearningJeremy Gomez-RojasNo ratings yet
- MG 2 - TEMA 1 Limba EnglezaDocument4 pagesMG 2 - TEMA 1 Limba Englezamimi12345678910No ratings yet
- The Normal DistributionDocument30 pagesThe Normal DistributionJohn Rich CaidicNo ratings yet
- Ag4q-212s KBDocument2 pagesAg4q-212s KBhtek.thunderainNo ratings yet
- Premium HC: 120 Halfcell Monocrystalline High Performance Solar ModuleDocument2 pagesPremium HC: 120 Halfcell Monocrystalline High Performance Solar ModuleMujahed Al-HamatiNo ratings yet
- Visual Storytelling The Digital Video Documentary - Original PDFDocument44 pagesVisual Storytelling The Digital Video Documentary - Original PDFjparanoti100% (1)
- How To Keep Your Brain HealthyDocument3 pagesHow To Keep Your Brain HealthySyahidah IzzatiNo ratings yet
- Fetomaternal Hemorrhage (FMH), An Update Review of LiteratureDocument35 pagesFetomaternal Hemorrhage (FMH), An Update Review of LiteratureEugenia Jeniffer JNo ratings yet
- Uremic EncephalophatyDocument48 pagesUremic EncephalophatySindi LadayaNo ratings yet
- KONAN Emmanuel Sales Technical Engineer 16 Juin 23Document1 pageKONAN Emmanuel Sales Technical Engineer 16 Juin 23EMMANUEL KONANNo ratings yet
- (A) Design - Introduction To Transformer DesignDocument16 pages(A) Design - Introduction To Transformer DesignZineddine BENOUADAHNo ratings yet
- Electronics Cooling: Mechanical Power Engineering DeptDocument22 pagesElectronics Cooling: Mechanical Power Engineering DeptneilNo ratings yet
- 5 25 17 Migraines PowerPointDocument40 pages5 25 17 Migraines PowerPointSaifi AlamNo ratings yet
- 3.1 Clothing Performance Requirements - March 22Document60 pages3.1 Clothing Performance Requirements - March 22Rohan KabirNo ratings yet
- 02 Flyer Beverly LR enDocument2 pages02 Flyer Beverly LR enluisgabrielbuca2246No ratings yet
- Is-Cal01 Design Carbon Accounting On Site Rev.02Document6 pagesIs-Cal01 Design Carbon Accounting On Site Rev.02shoba9945No ratings yet
- Kore Network Device ConfigurationDocument61 pagesKore Network Device ConfigurationEllaziaNo ratings yet
- Therapeutic Diet Manual: DIRECTIVE #4311Document27 pagesTherapeutic Diet Manual: DIRECTIVE #4311DuNo ratings yet