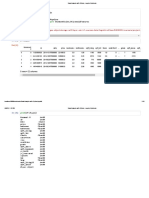
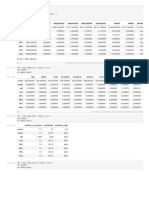
Download as pdf or txt
You might also like
- Linear Regression: Prepared by Muralidharan NDocument34 pagesLinear Regression: Prepared by Muralidharan NZohaib Imam77% (13)
- MBA Starting Salaries - Class DemonstrationDocument26 pagesMBA Starting Salaries - Class DemonstrationSIDDHANT MOHAPATRANo ratings yet
- Unit 9 Simple Linear Regression: StructureDocument22 pagesUnit 9 Simple Linear Regression: Structuresita rautelaNo ratings yet
- M2L2 Producing Reports ExercisesDocument6 pagesM2L2 Producing Reports ExercisesRichard LiuNo ratings yet
- Time Sereis Analysis Using StataDocument26 pagesTime Sereis Analysis Using Statasaeed meo100% (7)
- Bootstrap PowerpointDocument20 pagesBootstrap Powerpointfrancisco1591100% (1)
- House Price PredictionDocument14 pagesHouse Price PredictionVinay KumarNo ratings yet
- Data Analysis With Python - Jupyter NotebookDocument10 pagesData Analysis With Python - Jupyter NotebookNitish RavuvariNo ratings yet
- Untitled 91Document6 pagesUntitled 91Farukh IskalinovNo ratings yet
- Predictive Modelling ProjectDocument28 pagesPredictive Modelling ProjectPARIJAT DEVNo ratings yet
- Project Linear RegressionDocument7 pagesProject Linear RegressionCalo SoftNo ratings yet
- K MedoidsDocument10 pagesK Medoidsprerna sharmaNo ratings yet
- STAT 200 Week 7 Homework ProblemsDocument9 pagesSTAT 200 Week 7 Homework ProblemsOrise L. FelixNo ratings yet
- Data Analitics For Business: Descriptive StatisticsDocument66 pagesData Analitics For Business: Descriptive StatisticsFarah Diba DesrialNo ratings yet
- Housing MainDocument23 pagesHousing Mainhamburgerhenry13No ratings yet
- ML LinearRegressionDocument10 pagesML LinearRegressionHellem BiersackNo ratings yet
- Stat Tables PDFDocument28 pagesStat Tables PDFmsk123123No ratings yet
- Quantitative AnalysisDocument6 pagesQuantitative AnalysisAnkur SinhaNo ratings yet
- DATA SCIENCE IDC 302 End Sem ProjectDocument1 pageDATA SCIENCE IDC 302 End Sem Projectsoniakar3000No ratings yet
- Summer Internship OutlookDocument35 pagesSummer Internship OutlookPiyush KumarNo ratings yet
- Tugas Proyek EVDADocument19 pagesTugas Proyek EVDAhonesty CitraNo ratings yet
- Lec 4 Cost Behavior and EstimationDocument38 pagesLec 4 Cost Behavior and EstimationMochamad PutraNo ratings yet
- Capstone Project SubmissionDocument31 pagesCapstone Project Submissionguruss604684100% (1)
- Plan Presentation UlsavDocument7 pagesPlan Presentation UlsavAswathy GopinathNo ratings yet
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- Final CostDocument14 pagesFinal CostSoumava GhoshNo ratings yet
- Form Harga Barang2Document5 pagesForm Harga Barang2taufikjamal022No ratings yet
- Big Data AssignmentDocument8 pagesBig Data Assignmentshruti aroraNo ratings yet
- CaseStudy Indexes DowJones ShangaiDocument8 pagesCaseStudy Indexes DowJones ShangaimelinaguimaraesNo ratings yet
- Online EndSemExam Stats - 20apr21Document4 pagesOnline EndSemExam Stats - 20apr21Tanuj SinghNo ratings yet
- Total Result 2297200.86 286397.0217Document1,059 pagesTotal Result 2297200.86 286397.0217sahran.hasanNo ratings yet
- BookDocument9 pagesBookURK20CM3005 M CATHRINENo ratings yet
- Statistical TablesDocument28 pagesStatistical TablesHa TongNo ratings yet
- Relatório de VolumeDocument7 pagesRelatório de Volumepjnior123No ratings yet
- Ddco Notes RnsitDocument171 pagesDdco Notes Rnsitgostrider1036No ratings yet
- Marketing Analysis Homework IIDocument15 pagesMarketing Analysis Homework IIapi-620085176No ratings yet
- Nitin SanjDocument21 pagesNitin SanjsanjayfabexportNo ratings yet
- Grade-5-Balete-Rounding Whole NumbersDocument7 pagesGrade-5-Balete-Rounding Whole NumberselizaldeNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- 10th Bipartite Settlement - Bank Officers Revised Pay Scales (Expected) From November 2012Document2 pages10th Bipartite Settlement - Bank Officers Revised Pay Scales (Expected) From November 2012Yogesh Choudhary100% (1)
- #Kelompok #Mustopa 181220060 #Faizal Amir 181220074 #Syahril Arsad 181220044 #Krisdianto 181220058 #Import ModulesDocument3 pages#Kelompok #Mustopa 181220060 #Faizal Amir 181220074 #Syahril Arsad 181220044 #Krisdianto 181220058 #Import ModulesmustopaNo ratings yet
- Solution ExtraDocument9 pagesSolution ExtraAnushka KanaujiaNo ratings yet
- Likert Scales in R - Scale Package Tutorial: ResearchDocument5 pagesLikert Scales in R - Scale Package Tutorial: ResearchAnonymous x1JlRpmvNo ratings yet
- Activity 4Document2 pagesActivity 4Jherald AcopraNo ratings yet
- Activity 4Document2 pagesActivity 4Jherald AcopraNo ratings yet
- Appendix A Statistical Tables andDocument43 pagesAppendix A Statistical Tables andAriaNo ratings yet
- Form Harga BarangDocument5 pagesForm Harga Barangtaufikjamal022No ratings yet
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- Advanced Capital Budgeting 3 HW - q7Document3 pagesAdvanced Capital Budgeting 3 HW - q7sairad1999No ratings yet
- Tugas One WayDocument5 pagesTugas One WaymirantiNo ratings yet
- Question Sheet - Test - FinalDocument49 pagesQuestion Sheet - Test - Finalmayankverma189131No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- Fin 254 Part 3 2Document6 pagesFin 254 Part 3 2wali6965No ratings yet
- Sunil Kumar ChippaDocument5 pagesSunil Kumar Chippainfiniti sloutionsNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Background Check For An ApartmentDocument3 pagesBackground Check For An ApartmentTanya CNo ratings yet
- Forecast May 03Document3 pagesForecast May 03Anonymous geItmk3No ratings yet
- Hydrologi BeacoDocument6 pagesHydrologi BeacoJimson LcNo ratings yet
- Skela 002Document53 pagesSkela 002dusan345No ratings yet
- Spline InterpolationDocument8 pagesSpline Interpolationrod8silvaNo ratings yet
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- Hafsha Lutfia SalsabillaDocument26 pagesHafsha Lutfia Salsabillaseptaayuputri 1509No ratings yet
- Robustness of Logit Analysis: Unobserved Heterogeneity and Misspecified DisturbancesDocument14 pagesRobustness of Logit Analysis: Unobserved Heterogeneity and Misspecified DisturbancesAditya Agung SatrioNo ratings yet
- Difference Between Logit and Probit ModelsDocument7 pagesDifference Between Logit and Probit Modelswinkhaing100% (1)
- Cobb Douglas and Returns To ScaleDocument6 pagesCobb Douglas and Returns To ScalemolnarandrasNo ratings yet
- An Economist Wished To Relate The Speed With Which A Particular Insurance Innovation Is AdoptedDocument2 pagesAn Economist Wished To Relate The Speed With Which A Particular Insurance Innovation Is AdoptedSherlly Cruz IrigoinNo ratings yet
- Homework 1: Is Normally DistributedDocument2 pagesHomework 1: Is Normally DistributedAndres OrtizNo ratings yet
- EC212: Introduction To Econometrics Simple Regression Model (Wooldridge, Ch. 2)Document107 pagesEC212: Introduction To Econometrics Simple Regression Model (Wooldridge, Ch. 2)SHUMING ZHUNo ratings yet
- Non Parametric Density EstimationDocument4 pagesNon Parametric Density Estimationzeze1No ratings yet
- Ahmad LutfiDocument16 pagesAhmad LutfiPejuang SkripsiNo ratings yet
- Rocket Propellant DataDocument12 pagesRocket Propellant DatatsrforfunNo ratings yet
- Regresi OrdinalDocument3 pagesRegresi Ordinalwahyuni salsabilaNo ratings yet
- Estimation 2nd Sem 19-20Document298 pagesEstimation 2nd Sem 19-20ranjitbiswal547No ratings yet
- Estimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseDocument17 pagesEstimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseScience DirectNo ratings yet
- Regression Analysis With ScilabDocument57 pagesRegression Analysis With Scilabwakko29No ratings yet
- Eece 522 Notes - 05 CH - 3bDocument10 pagesEece 522 Notes - 05 CH - 3bkarim2005No ratings yet
- Chapter 08Document66 pagesChapter 08202110782No ratings yet
- The Impact of Development and Government Expenditure For Information and Communication Technology On Indonesian Economic GrowthDocument9 pagesThe Impact of Development and Government Expenditure For Information and Communication Technology On Indonesian Economic GrowthFarhan Anshari ArsyiNo ratings yet
- Tugas Per 12 Rohma Cahya Nopia (2018112020001)Document10 pagesTugas Per 12 Rohma Cahya Nopia (2018112020001)Rohma Cahya NoviaNo ratings yet
- Approved Notification - Assistant Statistical Officer in A.P.Economic and Statistical Subordinate ServiceDocument28 pagesApproved Notification - Assistant Statistical Officer in A.P.Economic and Statistical Subordinate ServiceSAN1258No ratings yet
- Notite Seminar 5Document7 pagesNotite Seminar 5DubstepAxellNo ratings yet
- Annexe 1:: Stat DescriptivesDocument11 pagesAnnexe 1:: Stat DescriptivesdaliNo ratings yet
- Ordinal Logistic ModelDocument32 pagesOrdinal Logistic Modeljiregnataye7No ratings yet
- Dummy VariablesDocument25 pagesDummy VariablesSankalp PurwarNo ratings yet
- Control TheoryDocument387 pagesControl TheoryvondutchlgNo ratings yet
- "Introductory Econometrics", Chapter 8 by Wooldridge: HeteroskedasticityDocument14 pages"Introductory Econometrics", Chapter 8 by Wooldridge: Heteroskedasticityzaheer khanNo ratings yet
- Estimation of ParametersDocument2 pagesEstimation of ParametersAngelie Limbago CagasNo ratings yet