
Assignment Problem - Gradient Descent
Assignment Problem - Gradient Descent
You might also like
- The Lemegeton - Goetia (Book I)Document50 pagesThe Lemegeton - Goetia (Book I)api-3700162No ratings yet
- Clutch Lab Sheet 2018Document6 pagesClutch Lab Sheet 2018Gabriel VaughnNo ratings yet
- 2 The Crystal Chemistry of ZeolitesDocument48 pages2 The Crystal Chemistry of ZeolitesJohn YuNo ratings yet
- Advanced Trauma Life Support (Atls)Document44 pagesAdvanced Trauma Life Support (Atls)Danar Syahrial PradhiptaNo ratings yet
- Augmented Matrix & Modeling ProblemsDocument14 pagesAugmented Matrix & Modeling ProblemsAwexomeNo ratings yet
- Numerical Linear Algebra With MatlabDocument16 pagesNumerical Linear Algebra With MatlabOSBALDO1205No ratings yet
- 2. Given Information:: 3. Calculate εDocument9 pages2. Given Information:: 3. Calculate εveyeda7265No ratings yet
- Linear RegressionDocument8 pagesLinear RegressionSailla Raghu rajNo ratings yet
- Alevel Support CoordGeoDocument8 pagesAlevel Support CoordGeoxapir83727No ratings yet
- ML AssignmentDocument17 pagesML Assignmentveyeda7265No ratings yet
- EEE 3104labsheet Expt 04Document6 pagesEEE 3104labsheet Expt 04Sunvir Rahaman SumonNo ratings yet
- ADA Practicals - Greedy, Dynamic, GraphDocument11 pagesADA Practicals - Greedy, Dynamic, GraphJaydevNo ratings yet
- Linear Time Invariant Systems: (N), and IsDocument12 pagesLinear Time Invariant Systems: (N), and IsKashif AbbasNo ratings yet
- Phd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)Document12 pagesPhd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)sachin rawatNo ratings yet
- Matrices NotesDocument13 pagesMatrices Notesps3266_753186479No ratings yet
- Error Analysis And: Graph DrawingDocument26 pagesError Analysis And: Graph DrawingNischay KaushikNo ratings yet
- X (X X - . - . - . - . - X) : Neuro-Fuzzy Comp. - Ch. 3 May 24, 2005Document20 pagesX (X X - . - . - . - . - X) : Neuro-Fuzzy Comp. - Ch. 3 May 24, 2005Oluwafemi DagunduroNo ratings yet
- Algebra Linear e CombinatóriaDocument11 pagesAlgebra Linear e CombinatóriaMatheus DomingosNo ratings yet
- Line Circle AlgorithmDocument33 pagesLine Circle Algorithmaerobala16No ratings yet
- Numerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionDocument23 pagesNumerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionMelih TecerNo ratings yet
- Vectors With ClassWiz by M AmmadDocument5 pagesVectors With ClassWiz by M AmmadDaniel LiuNo ratings yet
- Topic 8-Mean Square Estimation-Wiener and Kalman FilteringDocument73 pagesTopic 8-Mean Square Estimation-Wiener and Kalman FilteringHamza MahmoodNo ratings yet
- Linear RegressionDocument16 pagesLinear RegressionAnaswara K UNo ratings yet
- CG Chapter 3Document18 pagesCG Chapter 3rajmaisuria111No ratings yet
- Unit 1 Notes PDFDocument18 pagesUnit 1 Notes PDFCharles GribbenNo ratings yet
- Higher Eng Maths 9th Ed 2021 Solutions ChapterDocument25 pagesHigher Eng Maths 9th Ed 2021 Solutions ChapterAubrey JosephNo ratings yet
- Matlab Code 3Document29 pagesMatlab Code 3kthshlxyzNo ratings yet
- bk9 13Document29 pagesbk9 13Rahique ShuaibNo ratings yet
- Interpolation Methods: Paul BourkeDocument12 pagesInterpolation Methods: Paul BourkeTiểu Minh TháiNo ratings yet
- Linear AlgebraDocument51 pagesLinear AlgebraMuhammad HashirNo ratings yet
- Lecture 11 RegressionDocument53 pagesLecture 11 RegressionKaanNo ratings yet
- Chapter 5. Regression Models: 1 A Simple ModelDocument49 pagesChapter 5. Regression Models: 1 A Simple ModelPiNo ratings yet
- Computer GraphicsDocument263 pagesComputer GraphicsRaj SankeerthNo ratings yet
- Getting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "HelpDocument24 pagesGetting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "Helpsherry mughalNo ratings yet
- Functions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalDocument13 pagesFunctions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalShaikh Usman AiNo ratings yet
- Systems of Linear EquationsDocument26 pagesSystems of Linear EquationsKarylle AquinoNo ratings yet
- R Numeric ProgrammingDocument124 pagesR Numeric Programmingvsuarezf2732100% (1)
- 12s 701 FinalDocument17 pages12s 701 Finallnwwaii1234No ratings yet
- Lab Tutorial 9: Regression Modelling: 9.1 Fitting Linear Models: Linear RegressionDocument4 pagesLab Tutorial 9: Regression Modelling: 9.1 Fitting Linear Models: Linear RegressionPragyan NandaNo ratings yet
- Bagging, BoostingDocument32 pagesBagging, Boostinglassijassi100% (1)
- Functions and ApplicationsDocument30 pagesFunctions and Applicationslala landNo ratings yet
- NSM UNIT IV PPTsDocument27 pagesNSM UNIT IV PPTsRamjan ShidvankarNo ratings yet
- Unit 1 PhysicsDocument7 pagesUnit 1 PhysicsSTEM1 LOPEZNo ratings yet
- Online Quantitative Analysis Assignment HelpDocument6 pagesOnline Quantitative Analysis Assignment HelpStatistics Homework SolverNo ratings yet
- MM HA3 SolutionDocument21 pagesMM HA3 SolutionVojvodaAlbertNo ratings yet
- CGR Unit V INTRODUCTION TO CURVESDocument13 pagesCGR Unit V INTRODUCTION TO CURVESDhanshree GaikwadNo ratings yet
- Bressenham's Algorithm Easily ExplainedDocument18 pagesBressenham's Algorithm Easily ExplainedXenulhassanNo ratings yet
- Assignment 3Document5 pagesAssignment 3ritik12041998No ratings yet
- Lecture 3Document6 pagesLecture 3د. سعد قاسم الاجهزة الطبيةNo ratings yet
- MAT 1332D W12: Midterm Exam Review: Equilibrium Points, Stability, and Phase-Line DiagramsDocument10 pagesMAT 1332D W12: Midterm Exam Review: Equilibrium Points, Stability, and Phase-Line DiagramsAnggraeni DianNo ratings yet
- Systems of Linear EquationsDocument26 pagesSystems of Linear EquationsEli LoneyNo ratings yet
- File 3Document7 pagesFile 3channelakowuah2No ratings yet
- Mws Gen Inp TXT SplineDocument12 pagesMws Gen Inp TXT SplineApuu Na Juak EhNo ratings yet
- HW #2Document7 pagesHW #2sshanbhagNo ratings yet
- Unsymm Bending ExampleDocument5 pagesUnsymm Bending ExampleArifsalimNo ratings yet
- Regression Analysis Tutorial Excel MatlabDocument15 pagesRegression Analysis Tutorial Excel MatlabFAUC)N100% (1)
- Math 254 Final So LsDocument10 pagesMath 254 Final So LsStacey PerezNo ratings yet
- SCILAB Elementary FunctionsDocument25 pagesSCILAB Elementary FunctionsMAnohar KumarNo ratings yet
- E ∠ δ, …, E ∠δ δ, …, δ E, …, E: II. Classical Power System Model For Transient Stability AnalysisDocument6 pagesE ∠ δ, …, E ∠δ δ, …, δ E, …, E: II. Classical Power System Model For Transient Stability AnalysisSyaloom Gorga NapitupuluNo ratings yet
- One-Dimensional Array VariablesDocument34 pagesOne-Dimensional Array VariablesAhmad_Othman3No ratings yet
- System of Linear Equations: Direct & Iterative MethodsDocument36 pagesSystem of Linear Equations: Direct & Iterative MethodsLam WongNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Physics Letters B: Shin'ichi Nojiri, Sergei D. OdintsovDocument7 pagesPhysics Letters B: Shin'ichi Nojiri, Sergei D. OdintsovAdrian MorenoNo ratings yet
- Analysis of Diaphragm WallDocument6 pagesAnalysis of Diaphragm WallSanthosh BabuNo ratings yet
- World's TallestDocument6 pagesWorld's TallestMaryNo ratings yet
- Tagburos FinalDocument46 pagesTagburos FinalZiedwrick Ayson DicarNo ratings yet
- B.ing 2Document3 pagesB.ing 2Dwi purwitasariNo ratings yet
- BBS of All Pier Foundations of MAYARDocument16 pagesBBS of All Pier Foundations of MAYARAmanjot Singh0% (1)
- The Yoga Sutras of PatanjaliDocument23 pagesThe Yoga Sutras of Patanjaliapi-3736105No ratings yet
- Summary Literature Review of Hydration of Cement"Document2 pagesSummary Literature Review of Hydration of Cement"MuhammadZAmjadNo ratings yet
- 2 Changing Our Vision From Material Outlook To Spiritual Outlook PDFDocument4 pages2 Changing Our Vision From Material Outlook To Spiritual Outlook PDFvarun7salunkheNo ratings yet
- M/S. Sri Kanakadurga Tribal Labour Contract Mutually Aided Co-Op Society.Document11 pagesM/S. Sri Kanakadurga Tribal Labour Contract Mutually Aided Co-Op Society.Daneshwer VermaNo ratings yet
- Upstream Innovation (English)Document101 pagesUpstream Innovation (English)Yanxi EvaristoNo ratings yet
- Landfill Project Bratislava SlovakiaDocument286 pagesLandfill Project Bratislava SlovakiaaaNo ratings yet
- Chaotic Dynamics in Planetary Systems 1St Edition Sylvio Ferraz Mello Online Ebook Texxtbook Full Chapter PDFDocument69 pagesChaotic Dynamics in Planetary Systems 1St Edition Sylvio Ferraz Mello Online Ebook Texxtbook Full Chapter PDFhugh.lerma673100% (13)
- Controller BrochureDocument4 pagesController BrochureShomasy Shomasy100% (2)
- Cifra Club - Debbie Gibson - Lost in Your EyesDocument3 pagesCifra Club - Debbie Gibson - Lost in Your Eyesnivaldo de oliveira OliveiraNo ratings yet
- Molecular Biology Sars-Cov-2 (Covid-19) Detection by Qualitative RT-PCRDocument2 pagesMolecular Biology Sars-Cov-2 (Covid-19) Detection by Qualitative RT-PCRAaryan K MNo ratings yet
- Manuel SYL233 700 EDocument2 pagesManuel SYL233 700 ESiddiqui SarfarazNo ratings yet
- Federal Register / Vol. 88, No. 81 / Thursday, April 27, 2023 / Proposed RulesDocument236 pagesFederal Register / Vol. 88, No. 81 / Thursday, April 27, 2023 / Proposed RulesSimon AlvarezNo ratings yet
- Gullixson SermonDocument44 pagesGullixson SermonRock ArtadiNo ratings yet
- Calibracion Motor Aceleracion 320CDocument12 pagesCalibracion Motor Aceleracion 320CJoan CardonaNo ratings yet
- Types of PelvisDocument23 pagesTypes of PelvisChinju Jose SajithNo ratings yet
- Number of Research PapersDocument18 pagesNumber of Research PapersVM SARAVANANo ratings yet
- Tool Life When High Speed Ball Nose End Milling Inconel 718: Adrian Sharman, Richard C. Dewes, David K. AspinwallDocument7 pagesTool Life When High Speed Ball Nose End Milling Inconel 718: Adrian Sharman, Richard C. Dewes, David K. AspinwallKin HamzahNo ratings yet
- 2007 - A Comprehensive and Critical Review of Dental Implant Prognosis in Periodontally Compromised Partially Edentulous PatientsDocument11 pages2007 - A Comprehensive and Critical Review of Dental Implant Prognosis in Periodontally Compromised Partially Edentulous PatientsLenny GrauNo ratings yet
- Mercedes Actros Head FAHES - Vehicle Inspection Result 25-02-24Document1 pageMercedes Actros Head FAHES - Vehicle Inspection Result 25-02-24Sreeja LinNo ratings yet
- E354 PDFDocument21 pagesE354 PDFDinesh TaragiNo ratings yet
- Spirited Away - Film of The Fantastic and Evolving Japanese Folk SymbolsDocument25 pagesSpirited Away - Film of The Fantastic and Evolving Japanese Folk Symbolscv JunksNo ratings yet

























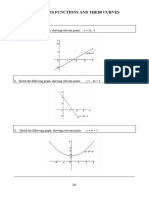
































































Download as pdf or txt
You might also like
- The Lemegeton - Goetia (Book I)Document50 pagesThe Lemegeton - Goetia (Book I)api-3700162No ratings yet
- Clutch Lab Sheet 2018Document6 pagesClutch Lab Sheet 2018Gabriel VaughnNo ratings yet
- 2 The Crystal Chemistry of ZeolitesDocument48 pages2 The Crystal Chemistry of ZeolitesJohn YuNo ratings yet
- Advanced Trauma Life Support (Atls)Document44 pagesAdvanced Trauma Life Support (Atls)Danar Syahrial PradhiptaNo ratings yet
- Augmented Matrix & Modeling ProblemsDocument14 pagesAugmented Matrix & Modeling ProblemsAwexomeNo ratings yet
- Numerical Linear Algebra With MatlabDocument16 pagesNumerical Linear Algebra With MatlabOSBALDO1205No ratings yet
- 2. Given Information:: 3. Calculate εDocument9 pages2. Given Information:: 3. Calculate εveyeda7265No ratings yet
- Linear RegressionDocument8 pagesLinear RegressionSailla Raghu rajNo ratings yet
- Alevel Support CoordGeoDocument8 pagesAlevel Support CoordGeoxapir83727No ratings yet
- ML AssignmentDocument17 pagesML Assignmentveyeda7265No ratings yet
- EEE 3104labsheet Expt 04Document6 pagesEEE 3104labsheet Expt 04Sunvir Rahaman SumonNo ratings yet
- ADA Practicals - Greedy, Dynamic, GraphDocument11 pagesADA Practicals - Greedy, Dynamic, GraphJaydevNo ratings yet
- Linear Time Invariant Systems: (N), and IsDocument12 pagesLinear Time Invariant Systems: (N), and IsKashif AbbasNo ratings yet
- Phd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)Document12 pagesPhd:304 Lab Report Advanced Mathematical Physics: Sachin Singh Rawat 16PH-06 (Department of Physics)sachin rawatNo ratings yet
- Matrices NotesDocument13 pagesMatrices Notesps3266_753186479No ratings yet
- Error Analysis And: Graph DrawingDocument26 pagesError Analysis And: Graph DrawingNischay KaushikNo ratings yet
- X (X X - . - . - . - . - X) : Neuro-Fuzzy Comp. - Ch. 3 May 24, 2005Document20 pagesX (X X - . - . - . - . - X) : Neuro-Fuzzy Comp. - Ch. 3 May 24, 2005Oluwafemi DagunduroNo ratings yet
- Algebra Linear e CombinatóriaDocument11 pagesAlgebra Linear e CombinatóriaMatheus DomingosNo ratings yet
- Line Circle AlgorithmDocument33 pagesLine Circle Algorithmaerobala16No ratings yet
- Numerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionDocument23 pagesNumerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionMelih TecerNo ratings yet
- Vectors With ClassWiz by M AmmadDocument5 pagesVectors With ClassWiz by M AmmadDaniel LiuNo ratings yet
- Topic 8-Mean Square Estimation-Wiener and Kalman FilteringDocument73 pagesTopic 8-Mean Square Estimation-Wiener and Kalman FilteringHamza MahmoodNo ratings yet
- Linear RegressionDocument16 pagesLinear RegressionAnaswara K UNo ratings yet
- CG Chapter 3Document18 pagesCG Chapter 3rajmaisuria111No ratings yet
- Unit 1 Notes PDFDocument18 pagesUnit 1 Notes PDFCharles GribbenNo ratings yet
- Higher Eng Maths 9th Ed 2021 Solutions ChapterDocument25 pagesHigher Eng Maths 9th Ed 2021 Solutions ChapterAubrey JosephNo ratings yet
- Matlab Code 3Document29 pagesMatlab Code 3kthshlxyzNo ratings yet
- bk9 13Document29 pagesbk9 13Rahique ShuaibNo ratings yet
- Interpolation Methods: Paul BourkeDocument12 pagesInterpolation Methods: Paul BourkeTiểu Minh TháiNo ratings yet
- Linear AlgebraDocument51 pagesLinear AlgebraMuhammad HashirNo ratings yet
- Lecture 11 RegressionDocument53 pagesLecture 11 RegressionKaanNo ratings yet
- Chapter 5. Regression Models: 1 A Simple ModelDocument49 pagesChapter 5. Regression Models: 1 A Simple ModelPiNo ratings yet
- Computer GraphicsDocument263 pagesComputer GraphicsRaj SankeerthNo ratings yet
- Getting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "HelpDocument24 pagesGetting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "Helpsherry mughalNo ratings yet
- Functions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalDocument13 pagesFunctions For Calculus Chapter 1-Linear, Quadratic, Polynomial and RationalShaikh Usman AiNo ratings yet
- Systems of Linear EquationsDocument26 pagesSystems of Linear EquationsKarylle AquinoNo ratings yet
- R Numeric ProgrammingDocument124 pagesR Numeric Programmingvsuarezf2732100% (1)
- 12s 701 FinalDocument17 pages12s 701 Finallnwwaii1234No ratings yet
- Lab Tutorial 9: Regression Modelling: 9.1 Fitting Linear Models: Linear RegressionDocument4 pagesLab Tutorial 9: Regression Modelling: 9.1 Fitting Linear Models: Linear RegressionPragyan NandaNo ratings yet
- Bagging, BoostingDocument32 pagesBagging, Boostinglassijassi100% (1)
- Functions and ApplicationsDocument30 pagesFunctions and Applicationslala landNo ratings yet
- NSM UNIT IV PPTsDocument27 pagesNSM UNIT IV PPTsRamjan ShidvankarNo ratings yet
- Unit 1 PhysicsDocument7 pagesUnit 1 PhysicsSTEM1 LOPEZNo ratings yet
- Online Quantitative Analysis Assignment HelpDocument6 pagesOnline Quantitative Analysis Assignment HelpStatistics Homework SolverNo ratings yet
- MM HA3 SolutionDocument21 pagesMM HA3 SolutionVojvodaAlbertNo ratings yet
- CGR Unit V INTRODUCTION TO CURVESDocument13 pagesCGR Unit V INTRODUCTION TO CURVESDhanshree GaikwadNo ratings yet
- Bressenham's Algorithm Easily ExplainedDocument18 pagesBressenham's Algorithm Easily ExplainedXenulhassanNo ratings yet
- Assignment 3Document5 pagesAssignment 3ritik12041998No ratings yet
- Lecture 3Document6 pagesLecture 3د. سعد قاسم الاجهزة الطبيةNo ratings yet
- MAT 1332D W12: Midterm Exam Review: Equilibrium Points, Stability, and Phase-Line DiagramsDocument10 pagesMAT 1332D W12: Midterm Exam Review: Equilibrium Points, Stability, and Phase-Line DiagramsAnggraeni DianNo ratings yet
- Systems of Linear EquationsDocument26 pagesSystems of Linear EquationsEli LoneyNo ratings yet
- File 3Document7 pagesFile 3channelakowuah2No ratings yet
- Mws Gen Inp TXT SplineDocument12 pagesMws Gen Inp TXT SplineApuu Na Juak EhNo ratings yet
- HW #2Document7 pagesHW #2sshanbhagNo ratings yet
- Unsymm Bending ExampleDocument5 pagesUnsymm Bending ExampleArifsalimNo ratings yet
- Regression Analysis Tutorial Excel MatlabDocument15 pagesRegression Analysis Tutorial Excel MatlabFAUC)N100% (1)
- Math 254 Final So LsDocument10 pagesMath 254 Final So LsStacey PerezNo ratings yet
- SCILAB Elementary FunctionsDocument25 pagesSCILAB Elementary FunctionsMAnohar KumarNo ratings yet
- E ∠ δ, …, E ∠δ δ, …, δ E, …, E: II. Classical Power System Model For Transient Stability AnalysisDocument6 pagesE ∠ δ, …, E ∠δ δ, …, δ E, …, E: II. Classical Power System Model For Transient Stability AnalysisSyaloom Gorga NapitupuluNo ratings yet
- One-Dimensional Array VariablesDocument34 pagesOne-Dimensional Array VariablesAhmad_Othman3No ratings yet
- System of Linear Equations: Direct & Iterative MethodsDocument36 pagesSystem of Linear Equations: Direct & Iterative MethodsLam WongNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Physics Letters B: Shin'ichi Nojiri, Sergei D. OdintsovDocument7 pagesPhysics Letters B: Shin'ichi Nojiri, Sergei D. OdintsovAdrian MorenoNo ratings yet
- Analysis of Diaphragm WallDocument6 pagesAnalysis of Diaphragm WallSanthosh BabuNo ratings yet
- World's TallestDocument6 pagesWorld's TallestMaryNo ratings yet
- Tagburos FinalDocument46 pagesTagburos FinalZiedwrick Ayson DicarNo ratings yet
- B.ing 2Document3 pagesB.ing 2Dwi purwitasariNo ratings yet
- BBS of All Pier Foundations of MAYARDocument16 pagesBBS of All Pier Foundations of MAYARAmanjot Singh0% (1)
- The Yoga Sutras of PatanjaliDocument23 pagesThe Yoga Sutras of Patanjaliapi-3736105No ratings yet
- Summary Literature Review of Hydration of Cement"Document2 pagesSummary Literature Review of Hydration of Cement"MuhammadZAmjadNo ratings yet
- 2 Changing Our Vision From Material Outlook To Spiritual Outlook PDFDocument4 pages2 Changing Our Vision From Material Outlook To Spiritual Outlook PDFvarun7salunkheNo ratings yet
- M/S. Sri Kanakadurga Tribal Labour Contract Mutually Aided Co-Op Society.Document11 pagesM/S. Sri Kanakadurga Tribal Labour Contract Mutually Aided Co-Op Society.Daneshwer VermaNo ratings yet
- Upstream Innovation (English)Document101 pagesUpstream Innovation (English)Yanxi EvaristoNo ratings yet
- Landfill Project Bratislava SlovakiaDocument286 pagesLandfill Project Bratislava SlovakiaaaNo ratings yet
- Chaotic Dynamics in Planetary Systems 1St Edition Sylvio Ferraz Mello Online Ebook Texxtbook Full Chapter PDFDocument69 pagesChaotic Dynamics in Planetary Systems 1St Edition Sylvio Ferraz Mello Online Ebook Texxtbook Full Chapter PDFhugh.lerma673100% (13)
- Controller BrochureDocument4 pagesController BrochureShomasy Shomasy100% (2)
- Cifra Club - Debbie Gibson - Lost in Your EyesDocument3 pagesCifra Club - Debbie Gibson - Lost in Your Eyesnivaldo de oliveira OliveiraNo ratings yet
- Molecular Biology Sars-Cov-2 (Covid-19) Detection by Qualitative RT-PCRDocument2 pagesMolecular Biology Sars-Cov-2 (Covid-19) Detection by Qualitative RT-PCRAaryan K MNo ratings yet
- Manuel SYL233 700 EDocument2 pagesManuel SYL233 700 ESiddiqui SarfarazNo ratings yet
- Federal Register / Vol. 88, No. 81 / Thursday, April 27, 2023 / Proposed RulesDocument236 pagesFederal Register / Vol. 88, No. 81 / Thursday, April 27, 2023 / Proposed RulesSimon AlvarezNo ratings yet
- Gullixson SermonDocument44 pagesGullixson SermonRock ArtadiNo ratings yet
- Calibracion Motor Aceleracion 320CDocument12 pagesCalibracion Motor Aceleracion 320CJoan CardonaNo ratings yet
- Types of PelvisDocument23 pagesTypes of PelvisChinju Jose SajithNo ratings yet
- Number of Research PapersDocument18 pagesNumber of Research PapersVM SARAVANANo ratings yet
- Tool Life When High Speed Ball Nose End Milling Inconel 718: Adrian Sharman, Richard C. Dewes, David K. AspinwallDocument7 pagesTool Life When High Speed Ball Nose End Milling Inconel 718: Adrian Sharman, Richard C. Dewes, David K. AspinwallKin HamzahNo ratings yet
- 2007 - A Comprehensive and Critical Review of Dental Implant Prognosis in Periodontally Compromised Partially Edentulous PatientsDocument11 pages2007 - A Comprehensive and Critical Review of Dental Implant Prognosis in Periodontally Compromised Partially Edentulous PatientsLenny GrauNo ratings yet
- Mercedes Actros Head FAHES - Vehicle Inspection Result 25-02-24Document1 pageMercedes Actros Head FAHES - Vehicle Inspection Result 25-02-24Sreeja LinNo ratings yet
- E354 PDFDocument21 pagesE354 PDFDinesh TaragiNo ratings yet
- Spirited Away - Film of The Fantastic and Evolving Japanese Folk SymbolsDocument25 pagesSpirited Away - Film of The Fantastic and Evolving Japanese Folk Symbolscv JunksNo ratings yet