Download as pdf or txt
You might also like
- Influencer List - Media FileDocument31 pagesInfluencer List - Media FileThe Denver postNo ratings yet
- MinutelyDocument1 pageMinutelyAnonymous CDd9eukAxNNo ratings yet
- Tutto Letteratura Italiana - DeAgostini PDFDocument1,058 pagesTutto Letteratura Italiana - DeAgostini PDFDan Fant100% (1)
- Logistic Multiclass ClassificationDocument2 pagesLogistic Multiclass Classificationjaymehta1444No ratings yet
- I Avaliação Parcial - 25.0 PTS - GabaritoDocument9 pagesI Avaliação Parcial - 25.0 PTS - GabaritoPedro CarvalhoNo ratings yet
- Scikit Learn What Were CoveringDocument15 pagesScikit Learn What Were CoveringRaiyan ZannatNo ratings yet
- Content: From Import Import As Import Import Import AsDocument8 pagesContent: From Import Import As Import Import Import Asبشار الحسينNo ratings yet
- Assignment 6.2aDocument4 pagesAssignment 6.2adashNo ratings yet
- 20bce2251 VL2021220503859 Ast03Document6 pages20bce2251 VL2021220503859 Ast03TANMAY MEHROTRANo ratings yet
- 20it113 Logisticregression MLDocument14 pages20it113 Logisticregression ML555 FFNo ratings yet
- Big Data Assignment - 7Document7 pagesBig Data Assignment - 7Rajeev MukheshNo ratings yet
- LogisticregressionDocument5 pagesLogisticregressionpatil samrudhiNo ratings yet
- Image Classification - RithvikDocument20 pagesImage Classification - RithvikKanakamedala Sai Rithvik ee18b051No ratings yet
- Gaussian NBDocument4 pagesGaussian NBnikkigupta13No ratings yet
- ML Shristi FileDocument49 pagesML Shristi FileRAVI PARKASHNo ratings yet
- Python Exam Practice - ExercisesDocument6 pagesPython Exam Practice - ExercisesAriyan JahanyarNo ratings yet
- Import As Import As From Import Import AsDocument2 pagesImport As Import As From Import Import AsHimanshi SharmaNo ratings yet
- Garishav Basra 102103129 2CO5Document8 pagesGarishav Basra 102103129 2CO5dsingh1be21No ratings yet
- ML Lab-Assignment-5Document8 pagesML Lab-Assignment-5Ajeet SinghNo ratings yet
- Practice - DL - Ipynb - ColaboratoryDocument14 pagesPractice - DL - Ipynb - Colaboratorynoorullahmd461No ratings yet
- Fashion MNIST-6Document10 pagesFashion MNIST-6akif barbaros dikmenNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Final CodeDocument16 pagesFinal CodeNaimul Hasan TahsinNo ratings yet
- ML Pca LdaDocument10 pagesML Pca LdarasaramanNo ratings yet
- CSharp-Advanced-Multidimensional-ArraysDocument36 pagesCSharp-Advanced-Multidimensional-ArraysEngin YasharNo ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Import As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import AsDocument8 pagesImport As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import Asvince.lachicaNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionChichi Jnr100% (1)
- Code ExerciseModelSelectionDocument19 pagesCode ExerciseModelSelectionaimen.nsiali100% (1)
- Experiment 8 Heirarchical ClusteringDocument17 pagesExperiment 8 Heirarchical ClusteringYuvraj Singh RathoreNo ratings yet
- PDF To JpegDocument7 pagesPDF To Jpegdarshanram.g9141No ratings yet
- CNN CodeDocument6 pagesCNN CodeSudhanNo ratings yet
- Assignment 6.2bDocument4 pagesAssignment 6.2bdashNo ratings yet
- CodeDocument2 pagesCodeKhandaker Fazla Elahe Sheam 1812561642No ratings yet
- Salary Prediction LinearRegressionDocument7 pagesSalary Prediction LinearRegressionYagnesh Vyas100% (1)
- Image Classification With The MNIST Dataset: ObjectivesDocument21 pagesImage Classification With The MNIST Dataset: ObjectivesPraveen SinghNo ratings yet
- Generate Item Responses in ConquestrDocument5 pagesGenerate Item Responses in ConquestrWowser PlodsNo ratings yet
- Alphabet - Kaggal - Jupyter NotebookDocument6 pagesAlphabet - Kaggal - Jupyter Notebookankitasonawane9988No ratings yet
- Pra 4 NumpyDocument2 pagesPra 4 NumpyheilNo ratings yet
- Pra 4 NumpyDocument2 pagesPra 4 NumpyheilNo ratings yet
- Machine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VDocument3 pagesMachine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VAshish kumar NeelaNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- Tugas Perceptron Dan BP Ann - A - f1d019055 - M. ArfriyandriDocument3 pagesTugas Perceptron Dan BP Ann - A - f1d019055 - M. ArfriyandriM ArfriyandriNo ratings yet
- InitializationDocument16 pagesInitializationlexNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- How To Train A Model With MNIST DatasetDocument7 pagesHow To Train A Model With MNIST DatasetMagdalena FalkowskaNo ratings yet
- AND - Gate - BiasedDocument4 pagesAND - Gate - Biasedmostafa98999No ratings yet
- Linear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsDocument2 pagesLinear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsmansiNo ratings yet
- Neural Networks: From ImportDocument3 pagesNeural Networks: From ImportAnonymous VNu3ODGavNo ratings yet
- DL7 1Document19 pagesDL7 1Sandesh PokhrelNo ratings yet
- CSY3025 Artificial Intelligence Techniques: Deep LearningDocument42 pagesCSY3025 Artificial Intelligence Techniques: Deep LearningSandesh PokhrelNo ratings yet
- Rice Disease Classifier 2Document9 pagesRice Disease Classifier 2harinatha778No ratings yet
- EJ2SEMANA3Document14 pagesEJ2SEMANA3fuck off we need limitsNo ratings yet
- Image ClassificationsDocument4 pagesImage ClassificationsAnvesh SilaganaNo ratings yet
- Iris ClaasificationDocument1 pageIris ClaasificationMohammad Faysal KhanNo ratings yet
- Designing Machine Learning Workflows in Python Chapter1Document32 pagesDesigning Machine Learning Workflows in Python Chapter1FgpeqwNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- P06 The Classification Pipeline AnsDocument16 pagesP06 The Classification Pipeline AnsJayson CarlsenNo ratings yet
- NguyenTrungThinh BT3.3Document5 pagesNguyenTrungThinh BT3.3Nguyen Trung ThinhNo ratings yet
- Model and Apply ModelDocument8 pagesModel and Apply ModelMichael O. AdegbenroNo ratings yet
- Brain Tumor ClassificationDocument12 pagesBrain Tumor ClassificationUltra Bloch100% (1)
- 6 - Train - Test - Split - Ipynb - ColaboratoryDocument5 pages6 - Train - Test - Split - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- 5 - One - Hot - Encoding - Ipynb - ColaboratoryDocument8 pages5 - One - Hot - Encoding - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- 1 - Linear - Regression - Ipynb - ColaboratoryDocument7 pages1 - Linear - Regression - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- 5 Exercise One Hot Encoding - Ipynb - ColaboratoryDocument4 pages5 Exercise One Hot Encoding - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- 2 - Linear - Regression - Multivariate - Ipynb - ColaboratoryDocument4 pages2 - Linear - Regression - Multivariate - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- 2 - Exercise - Answer - Ipynb - ColaboratoryDocument3 pages2 - Exercise - Answer - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Miscellaneous Functions (M Codes)Document2 pagesMiscellaneous Functions (M Codes)Joshua TaylorNo ratings yet
- Digit Frequency HackerRankDocument1 pageDigit Frequency HackerRankManogna MarisettyNo ratings yet
- Detection: R.G. GallagerDocument18 pagesDetection: R.G. GallagerSyed Muhammad Ashfaq AshrafNo ratings yet
- Proposal B2C Travel Booking EngineDocument10 pagesProposal B2C Travel Booking EngineAlphaNo ratings yet
- A 10-Step Cloud Migration ChecklistDocument16 pagesA 10-Step Cloud Migration ChecklistchandraNo ratings yet
- International Journal of Disaster Risk Reduction: SciencedirectDocument26 pagesInternational Journal of Disaster Risk Reduction: SciencedirectNatália SantosNo ratings yet
- Barasoain Memorial Integrated School: School I.D 501231/tel. No. (044) 791-6318Document2 pagesBarasoain Memorial Integrated School: School I.D 501231/tel. No. (044) 791-6318Raymund P. CruzNo ratings yet
- One Minute Academy Student Handbook (English)Document29 pagesOne Minute Academy Student Handbook (English)ayudwinyNo ratings yet
- Vmea 17 Feb Morning EndDocument35 pagesVmea 17 Feb Morning EndKiran NaikNo ratings yet
- DxdiagDocument11 pagesDxdiagSzabo ArnoldNo ratings yet
- Bijoy in Linux PDFDocument9 pagesBijoy in Linux PDFsalimahamedNo ratings yet
- Ac Crane ControlDocument28 pagesAc Crane ControlErc Nunez VNo ratings yet
- Chapter 8 OS SuportDocument32 pagesChapter 8 OS SuportMulyadi YaminNo ratings yet
- NextGen White Paper 4Document12 pagesNextGen White Paper 4tdeviyanNo ratings yet
- Scheduling Proportional ShareDocument11 pagesScheduling Proportional ShareminniNo ratings yet
- CIROS Studio Product Information enDocument14 pagesCIROS Studio Product Information envozoscribdNo ratings yet
- Tecnicas de Extricacion Vehicular Por Holmatro: AdvertisementDocument3 pagesTecnicas de Extricacion Vehicular Por Holmatro: AdvertisementJoel DominiciNo ratings yet
- SHP To: Order No: Location Code: 00213850 4659 W547701: Please Keep This Importan Document For Your RecordsDocument1 pageSHP To: Order No: Location Code: 00213850 4659 W547701: Please Keep This Importan Document For Your RecordsDamien TucsonNo ratings yet
- ShopperNOW Training Manual DownloadDocument18 pagesShopperNOW Training Manual DownloadHardik SoodNo ratings yet
- A Project Report ON "Purchase and Sales Management System"Document41 pagesA Project Report ON "Purchase and Sales Management System"PREETNo ratings yet
- Iib Interview Questions IIDocument3 pagesIib Interview Questions IIAjay Ch100% (1)
- English ThesisDocument2 pagesEnglish ThesisJoy ManatadNo ratings yet
- Lab GuideDocument36 pagesLab GuideAmir HsmNo ratings yet
- CST1340 - Section1GOALs - M00986493 - Amaan KhanDocument9 pagesCST1340 - Section1GOALs - M00986493 - Amaan Khanmohdamaankhan.workNo ratings yet
- Rename The DatabaseDocument2 pagesRename The DatabaseSubramanian KNo ratings yet
- Math 105Document24 pagesMath 105ShailendraPatelNo ratings yet
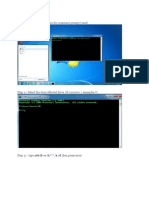
- Step 1:-Windows+ R - Run The Comment Prompt (CMD)Document3 pagesStep 1:-Windows+ R - Run The Comment Prompt (CMD)Debabrata DashNo ratings yet