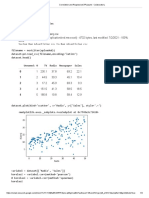
Download as pdf or txt
You might also like
- FrescoDocument17 pagesFrescovinay100% (2)
- Machine Learning Cheat Sheet ??? - ?Document231 pagesMachine Learning Cheat Sheet ??? - ?Mahesh GullaNo ratings yet
- Designing Machine Learning Workflows in Python Chapter2Document39 pagesDesigning Machine Learning Workflows in Python Chapter2FgpeqwNo ratings yet
- Correlation and Regression (TP)Document4 pagesCorrelation and Regression (TP)Hiimay ChannelNo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- ML FileDocument37 pagesML File25532aayushi.2020No ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- 06 SeabornDocument13 pages06 SeabornAnonymous 001No ratings yet
- EDA Lab ManualDocument93 pagesEDA Lab ManualYash Rox100% (2)
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- AI-MAJOR-AUGUST - Aryal AshishDocument16 pagesAI-MAJOR-AUGUST - Aryal AshishAshish AryalNo ratings yet
- Artificial Intelligence (18Csc305J) Lab: EXPERIMENT 13: Implementation of NLP ProblemDocument9 pagesArtificial Intelligence (18Csc305J) Lab: EXPERIMENT 13: Implementation of NLP ProblemSAILASHREE PANDAB (RA1911032010030)No ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- AI ManualDocument69 pagesAI ManualDev SejvaniNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- 2020-21 XIIInfo - Pract.S.E.155Document11 pages2020-21 XIIInfo - Pract.S.E.155Haresh NathaniNo ratings yet
- ML 4 To 9 KeyurDocument21 pagesML 4 To 9 Keyurjay limbadNo ratings yet
- TYCS PracticalDocument26 pagesTYCS Practicallatestfullmovies74No ratings yet
- Urmi ML Practical FileDocument37 pagesUrmi ML Practical Filebekar kaNo ratings yet
- Expt - No.2. RUSHYADocument3 pagesExpt - No.2. RUSHYApareshpawar1902No ratings yet
- Simple Linear RegressionDocument4 pagesSimple Linear Regressionjaymehta1444No ratings yet
- 1.diagnosis Using MLDocument69 pages1.diagnosis Using MLChoral WealthNo ratings yet
- Aviral DTDocument36 pagesAviral DTAman Pratap SinghNo ratings yet
- Solutions ModernstatisticsDocument144 pagesSolutions ModernstatisticsdivyanshNo ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- Final Practical File 2022-23Document87 pagesFinal Practical File 2022-23Kuldeep SinghNo ratings yet
- Industrial Statistics - A Computer Based Approach With PythonDocument140 pagesIndustrial Statistics - A Computer Based Approach With PythonhtapiaqNo ratings yet
- Funciones para PythonDocument33 pagesFunciones para PythonEduardo Páez DíazNo ratings yet
- Content From Jose Portilla's Udemy Course Learning Python For Data Analysis and Visualization Notes by Michael Brothers, Available OnDocument13 pagesContent From Jose Portilla's Udemy Course Learning Python For Data Analysis and Visualization Notes by Michael Brothers, Available Onsam egoroffNo ratings yet
- What Is PCA: When Should You Use PCA?Document21 pagesWhat Is PCA: When Should You Use PCA?sailushaNo ratings yet
- CSE 3024: Web Mining: Lab Assessment - 3Document13 pagesCSE 3024: Web Mining: Lab Assessment - 3Nikitha ReddyNo ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- ML Activity KalyanDocument21 pagesML Activity Kalyanaishwarya kalyanNo ratings yet
- 178 DLDocument31 pages178 DLNidhiNo ratings yet
- ML Lab RecordsDocument101 pagesML Lab RecordsSreesha ChakrabortyNo ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- Data Science LibrariesDocument4 pagesData Science Librariesayushyadav73095No ratings yet
- Implementation of Time Series ForecastingDocument12 pagesImplementation of Time Series ForecastingSoba CNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Practical File PythonDocument25 pagesPractical File Pythonkaizenpro01No ratings yet
- 1 An Introduction To Machine Learning With Scikit LearnDocument2 pages1 An Introduction To Machine Learning With Scikit Learnkehinde.ogunleye007No ratings yet
- Pattern RecognitionDocument26 pagesPattern RecognitionAryan AttriNo ratings yet
- Week1-SPT2 Descriptive StatisticsDocument8 pagesWeek1-SPT2 Descriptive StatisticsRamiz JavedNo ratings yet
- Preprocessing ch.1Document24 pagesPreprocessing ch.1oml78531No ratings yet
- Practical File: Deep LearningDocument33 pagesPractical File: Deep LearningGAMING WITH DEAD PANNo ratings yet
- Machine Learning PractDocument7 pagesMachine Learning PractSunil ShedgeNo ratings yet
- Stats Practical WJCDocument23 pagesStats Practical WJCBhuvanesh SriniNo ratings yet
- Pattern Report FinalDocument10 pagesPattern Report FinalMD Rubel AminNo ratings yet
- Financial Data Analysis InpythonDocument1 pageFinancial Data Analysis InpythonpranavshreniNo ratings yet
- Ad3411 Data Science and Analytics LaboratoryDocument24 pagesAd3411 Data Science and Analytics LaboratoryMohamed Shajid N100% (7)
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHANo ratings yet
- CD 601 Lab ManualDocument61 pagesCD 601 Lab ManualSatya Prakash SoniNo ratings yet
- Tensor Flow and Keras Sample ProgramsDocument22 pagesTensor Flow and Keras Sample Programsvinothkumar0743No ratings yet
- Digits Recognition DatasetDocument4 pagesDigits Recognition DatasetJoe1No ratings yet
- Untitled DocumentDocument19 pagesUntitled Documents14utkarsh2111019No ratings yet
- 6PAM1052 Stats PracticalDocument25 pages6PAM1052 Stats PracticalBhuvanesh SriniNo ratings yet
- ML Practical 205160694034Document33 pagesML Practical 20516069403409Samrat Bikram ShahNo ratings yet
- FDP Indoglobal Group of Colleges: 27 April To 1 May R Programming Language Assignment SubmissionDocument12 pagesFDP Indoglobal Group of Colleges: 27 April To 1 May R Programming Language Assignment Submissionoptimistic_harishNo ratings yet
- 0Document343 pages0Artem Sergeevich AkopyanNo ratings yet
- IR - 754 All PracticalDocument21 pagesIR - 754 All Practical754Durgesh VishwakarmaNo ratings yet
- Developing An Improved Approach To Solving A New Gas Lift Optimization ProblemDocument25 pagesDeveloping An Improved Approach To Solving A New Gas Lift Optimization ProblemZaur YarehmedovNo ratings yet
- EUC1502 Module2 Machine LearningDocument32 pagesEUC1502 Module2 Machine LearningРадомир МутабџијаNo ratings yet
- Unit 4Document108 pagesUnit 4mjyothsnagoudNo ratings yet
- Data AnalyticsDocument134 pagesData AnalyticsMOHANRAJ.GNo ratings yet
- The Strength of Corporate Culture and The Reliability of Firm PerformanceDocument22 pagesThe Strength of Corporate Culture and The Reliability of Firm PerformanceLilis Ayu HandayaniNo ratings yet
- Question 1 BDocument6 pagesQuestion 1 Bsathvika pingaliNo ratings yet
- Exploratory Data Analysis and Crime Prevention Using Machine Learning The Case of GhanaDocument10 pagesExploratory Data Analysis and Crime Prevention Using Machine Learning The Case of GhanaInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Laptop Price PredictionDocument25 pagesLaptop Price Predictionvtu19362No ratings yet
- Lecture #2: Prediction, K-Nearest Neighbors: CS 109A, STAT 121A, AC 209A: Data ScienceDocument28 pagesLecture #2: Prediction, K-Nearest Neighbors: CS 109A, STAT 121A, AC 209A: Data ScienceLeonardo Lujan GonzalezNo ratings yet
- AttachmentDocument307 pagesAttachmentAbi DemNo ratings yet
- Thesis Sales ForcastingDocument43 pagesThesis Sales ForcastingHainsley EdwardsNo ratings yet
- Chapter 3Document58 pagesChapter 3david AbotsitseNo ratings yet
- Practice Questions 1Document2 pagesPractice Questions 1Superset NotificationsNo ratings yet
- Curvas de Crecimiento MicrobianoDocument30 pagesCurvas de Crecimiento Microbianoluis villamarinNo ratings yet
- COMP1801 - Copy 1Document18 pagesCOMP1801 - Copy 1SujiKrishnanNo ratings yet
- Coefficient of Variation (Meaning and InterpretationDocument10 pagesCoefficient of Variation (Meaning and Interpretationwawan GunawanNo ratings yet
- 1 Lecture 3: Optimization and Linear RegressionDocument27 pages1 Lecture 3: Optimization and Linear RegressionJeremy WangNo ratings yet
- Research Ii: Whole Brain Learning System Outcome-Based EducationDocument16 pagesResearch Ii: Whole Brain Learning System Outcome-Based EducationRachel Yam 3nidadNo ratings yet
- BUSINESS STATISTICS: Simple Linear Regression and CorrelationDocument55 pagesBUSINESS STATISTICS: Simple Linear Regression and CorrelationLaurence Rue AudineNo ratings yet
- Weatherwax Epstein Hastie Solution ManualDocument147 pagesWeatherwax Epstein Hastie Solution ManualRudrani AngiraNo ratings yet
- MFM 5053 Chapter 1Document26 pagesMFM 5053 Chapter 1NivanthaNo ratings yet
- Prediction of Cardiovascular Disease Using Hybrid Machine Learning AlgorithmsDocument9 pagesPrediction of Cardiovascular Disease Using Hybrid Machine Learning Algorithmsewuiplkw phuvdjNo ratings yet
- PHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckDocument20 pagesPHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckKarim BekhtiarNo ratings yet
- Chapter 6 Solutions Solution Manual Introductory Econometrics For FinanceDocument11 pagesChapter 6 Solutions Solution Manual Introductory Econometrics For FinanceNazim Uddin MahmudNo ratings yet
- Data Science and Machine Learning A Survey On The Future Revenue Predictions and The Amount of Product SalesDocument8 pagesData Science and Machine Learning A Survey On The Future Revenue Predictions and The Amount of Product SalesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Loss Functions - An Algorithm-Wise Comprehensive SummaryDocument5 pagesLoss Functions - An Algorithm-Wise Comprehensive Summarychidiebere onwuchekwaNo ratings yet
- FEM 3004 - Lab 8 - 24.12.20Document35 pagesFEM 3004 - Lab 8 - 24.12.20AINA NADHIRAH BINTI A ROZEY / UPMNo ratings yet
- Unit Iv Design of ExperimentsDocument34 pagesUnit Iv Design of ExperimentsMathioli Senthil0% (1)
- 23-04-2021-1619173506-8-Ijamss-6. Ijamss - Discrete Alpha Power Inverse Lomax Distribution With Application of Covid-19 DataDocument12 pages23-04-2021-1619173506-8-Ijamss-6. Ijamss - Discrete Alpha Power Inverse Lomax Distribution With Application of Covid-19 Dataiaset123No ratings yet